Multi-scale_Guided_Image_and_Video_Fusion 多尺度引导图像与视频融合
- MGFF
- 引入
- 原始方法GF
- GFF的两个主要问题。
- MGFF引出
- 综述GF 和 多尺度引导图像分解
- GF综述
- 多尺度引导的图像分解和重建过程
- 提出的方法
- 多尺度引导图像分解
- 多尺度引导图像融合
- VSD 视觉显著性检测
- 权重图计算
- 细节层融合
- 基础层融合
- 融合图像重建
- 实验和结果
- 图像
- 定性分析(视觉观察)
- 定量分析
- run time
- 视频(只考虑6个随机帧)
- 图像和视频对比度增强
- 主要贡献
- others:
MGFF
引入
多尺度引导图像与视频融合:一种快速有效的方法
这些单独捕获的图像可能提供冗余和互补的信息。为了更好地理解场景,这些图像的信息应该通过消除冗余信息来组合成一幅图像。例如,由于景深的限制,可见相机不能同时对焦一个场景中的多个对象。场景中的特定对象需要一个接一个地聚焦和捕捉。这些捕获的图像可能在一个区域提供独特的信息,而在另一个区域提供冗余的信息。很难从这些单独的图像中得到一个场景的全貌。因此,需要从这些图像中生成一张能够提供所有聚焦区域的图像。
但是,在军事和导航等监控应用中,需要日夜监控周围环境。在这里,红外或热成像相机可以根据温度变化提供低能见度场景的信息。然而,无论是可见光(VI)图像还是红外(IR)图像都不足以提供关于场景的所有信息。因此,需要将两幅图像中所需的场景细节整合到一张图像中。
原始方法GF
最初,Li et al.[24]提出了一种基于GF的融合算法,本文将其称为引导滤波融合(guided filter fusion, GFF)。在GFF方法中,基于平均滤波器将源图像分解为基层和细节层。然后,利用拉普拉斯算子和高斯算子计算显著性映射和相应的初始权值映射。接下来,使用GF对初始权值图进行细化,得到对应于每个基础层和细节层的最终权值图。最后,基础层和细节层与这些权重相结合。在许多图像融合应用中,该方法比现有的基于多尺度分解的融合方法表现出了更好的性能。但它也存在一定的局限性,各种新的融合算法都解决了这些问题。
GFF的两个主要问题。
首先,在GFF中,拉普拉斯算子生成的显著性映射并不保留图像的所有特征
此外,GFF没有充分利用多尺度分解的优势。
- 为了解决这些问题,他们提出了一种基于加权最小二乘滤波、相位一致性和GF的融合算法[12]。这种方法与GFF框架类似,但有一些不同之处。在多尺度分解模式下,用加权最小二乘滤波器代替平均滤波器,用相位同余代替拉普拉斯和高斯算子。
- 将定性和定量结果与GFF等方法进行比较,但未进行运行时比较。此外,该方法仅在可见光和红外图像数据集上进行了测试。
Jameel等人[17-19]提出了一系列基于GF的图像融合算法。在[17]中,他们开发了一种基于线性最小平方误差估计和改进的权值映射策略的医学图像融合算法,以解决GFF的各种局限性。GFF中的高斯滤波器不能去除Rician噪声。在GFF中,当两个权值相等时,二进制赋值可能会丢弃一个值的影响。
在[18]中,提出了另一种多焦点图像的算法,利用平移不变小波变换(SIWT)和GF消除噪声影响。在这里,没有在GFF中使用平均滤波器,而是考虑使用SIWT进行多尺度分解,而其余步骤与GFF类似。
在[19]中,利用基于焦点信息的权值映射,提出了一种针对多焦点图像的替代算法
Javed等人[20]提出了一种利用分形维数和GF进行MRI和CT图像融合的新方法。这些论文中采用的方法类似于GFF框架,通过修改一些组件来提高性能。在[33]中,Singh等人提出了一种基于GF和金字塔分解的图像融合算法。这种方法与当时最先进的融合算法完全不同。这里只讨论了多次曝光图像的融合问题。Pritika et al.[31]提出了一种医学图像融合方法,该方法使用多层融合规则,利用多尺度引导图像分解。Zhou等人[44]开发了一种基于多尺度引导图像分解的图像融合方法,融合了红外和可见光图像。与GFF方法相比,它的计算成本较高。
除了GFF和GFS之外,其他方法依赖于应用程序。所有基于GF的融合方法都依赖于其他工具和技术来实现显著性图的提取或权值图的构建。它们中的大多数计算开销很大,并且运行时比较没有给予适当的优先级。此外,它们都没有在视频数据集上进行测试。
MGFF引出
针对现有基于GF的图像融合方法存在的不足,利用多尺度引导图像分解和基于自显著性提取过程构建权值映射的优点,提出了一种简单但计算效率高的融合算法——多尺度引导滤波融合(multi-scale guided filtering -based fusion, MGF)。本文提出的MGF受[4]的启发,利用GF在多尺度图像分解和结构传递方面的优势,将有用的源图像信息很好地结合到融合图像中,从而开发出一种新的视觉显著性提取和权值图构建过程。多尺度图像分解适用于表示和处理不同尺度下的图像特征。该算法使GF具有结构传输特性,可以将一个源图像的结构传输到另一个源图像中。基于细节层信息的视觉显著性检测(Visual saliency detection, VSD)过程可以识别出重要的源图像信息。基于视觉显著性的权值图构建过程能够逐像素集成互补信息。因此,该方法能够在每个尺度上将像素级互补源图像信息转化为融合图像。
主要贡献:
-
提出了一种基于GF的VSD算法,用于从视觉上不同的图像中提取显著性信息。
-
针对图像融合的各种应用,提出了一种基于GF的通用图像融合算法。
-
一个单一的多尺度GF就足以提取图像的视觉显著性并进行图像融合。因此,大大降低了算法的复杂度。然而,现有的基于gf的融合方法使用单独的工具或技术进行特征提取(边缘和显著性信息)和融合。
-
对50个图像数据集以及静态和动态视频数据集进行了广泛的仿真。
-
提出了合适的图像和视频增强算法,进一步增强融合结果的视觉内容。
综述GF 和 多尺度引导图像分解
GF综述

设I和G分别表示输入图像和制导图像。邻域大小r,调节参数ε。参数r和ε控制边缘保持过程。
IG=GF(I,G,r,ε)。
GF通过考虑像素邻域的统计特性来进行平滑。它像线性时不变(LTI)滤波器一样计算输出。但是,它使用另一个图像作为指导目的。这个附加的图像可以是输入或它的翻译版本。你也可以为这个目的选择一个完全不同的图像。
与其他边缘保持滤波器一样,GF也可以在分解过程中保持边缘信息,这有助于避免出现振铃伪影。(这个特性使得GF在各种应用程序中很有用,比如着色、上采样和图像抠图。)
除了边缘保持性外,GF还具有结构转移性。如果制导图像与输入图像相同,则进行边缘保持平滑,但结构行为保持不变。**另一方面,当制导图像与输入图像不同时,平滑过程由制导图像的结构来调节。**如图1a(左侧)所示,如果输入信号和制导信号都是高斯信号,则合成信号也是高斯信号。相反,在图1a(右侧)中,如果制导信号(sinc函数)与输入信号(高斯)不同,则制导信号的结构控制或指导输入信号的平滑过程。从这幅图中,我们可以清楚地注意到sinc函数的旁瓣被转移到了高斯函数上。同样的过程也可以观察到图1b使用步进和正弦信号。[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Aofh6y7V-1648563075558)(D:\dddpersonal_file\fdu\曦源计划\文献阅读\MGFF&GAN\QQ截图20220307103817.png)]
从这个例子可以得出结论,当我们在图像上应用GF时,边缘结构可以被转移。多尺度分解可以在不同的分辨率上表示边缘信息。同时使用GF可以在不同尺度上传递边缘结构。融合算法的主要要求是将一幅图像的信息转换为另一幅图像。综上所述,运行在结构转移模式下的多尺度GF可以在不同分辨率下支持该方法,从而提高了性能。
多尺度引导的图像分解和重建过程
使用GF可以进行多尺度分解。同样,我们也可以在不丢失信息的情况下重建图像.
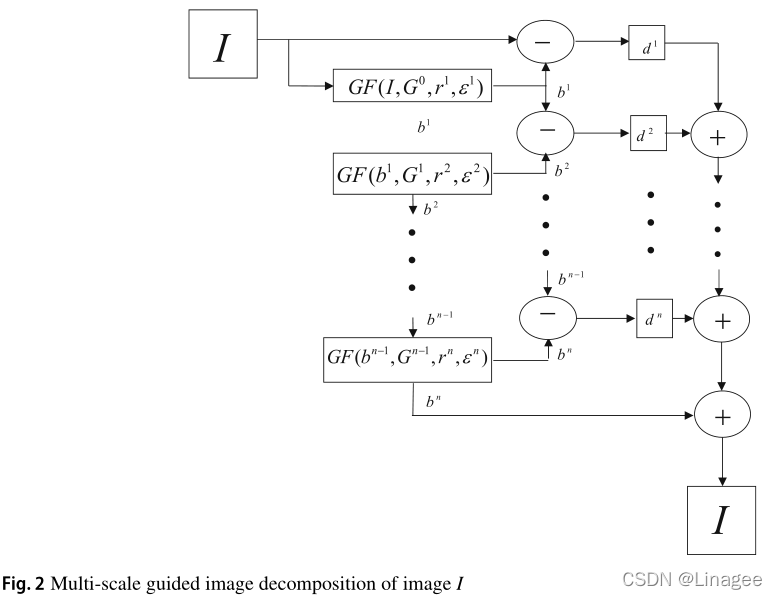

假设bn−1 Gn−1为(n−1)层的基础层和制导图像,rn为εn为第n层的邻域大小和调节参数,则将Gn−1作为制导图像,对bn−1进行导引图像滤波,即可得到基础层bn。细节图像dn可以通过取之前的基础层bn−1和当前的基础层bn的差值来计算。参数rn, εn将根据应用要求考虑。
GF为引导滤波,b0 为源图像,第n层的基础图像是上一层n-1层图像进行引导滤波得到的,第n层的细节图像是就是 第n-1层的基础图像与第n层的基础图像的差。那么,由各层和细节层和最后一层的基础层,就可以恢复出原图像:
重建:
多尺度分解的过程:

提出的方法
本文提出的MGF方法涉及的重要步骤总结如下:
A.利用GF对源图像进行多尺度分解。
B.生成显著性图。
C.计算对应细节层的权重图。
D.使用权重图结合细节层。
E.生成最终融合图像。

多尺度引导图像分解
像素级共配准源图像I1(x, y)和I2(x, y),我们使用GF对I1和I2进行多尺度分解,得到基础层B11B21,细节层D11D21

(4)

I2是I1的制导图,I2的结构信息对I1进行平滑
I1是I2的制导图,I1的结构信息对I2进行平滑
(5)

这些细节层提供了视觉上重要的源图像信息,进一步有助于提取视觉显著性和权重图的构建。

多尺度引导图像融合

VSD 视觉显著性检测
一种新的视觉显著检测多尺度处理方法的多尺度VSD过程来实现图像融合。该算法可以从视觉上不同的图像中提取出整个场景的显著性图。在实际图像融合中,并没有使用到该参数,实际计算时使用每一层的细节层用作权重计算,但是作者将它作为一个对比项。
具体步骤:
1 使用(4)和(5)将源图像分解为基础层(Bk1, Bk2)和细节层(Dk1, Dk2)。
2 通过取细节层Dk1和Dk2的大小来计算视觉显著性Sk1和Sk2

3 通过平均Sk1和Sk2,找到与源图像对应的视觉显著性S1和S2

4 将整个场景的最终视觉显著性确定为S1和S2像素级的最大值

本文提出的VSD可以结合两幅不同图像的视觉显著性,提取出整个场景的视觉显著性。
值得注意的是,显著性映射S1, S2, S在本文提出的MGF方法中没有使用。因为在融合过程中,我们的目标是使用由特定比例的显著性信息发展而来的权重图来组合每个比例的细节图像。因此,如图4和算法3所示,我们利用局部显著性映射Sk1, Sk2来合并每k级的细节图像信息。这些显著性在每个尺度上提取重要信息。然而,如图5和算法4所示,使用本文提出的VSD算法可以从视觉上不同的图像中提取出整个场景的显著性图。此外,这种比例特定的显著性信息在构建权重图的融合目的是有用的。

权重图计算
作者在计算细节层的融合权重时,使用的是每一层的细节图,将每一层的细节图像进行融合。即直接从细节层开发显著性图。由于采用了这种方法,大大降低了算法的计算复杂度。权值映射是通过对显著性映射进行标准化来设计的。

这种基于显著性信息的互补权值图构建过程可以自动整合每个像素点的细节层信息。
细节层融合


该融合细节图像DF提供了融合图像的大部分视觉信息。
基础层融合

BF提供融合后图像的对比度。
融合图像重建
融合后的图像由底层BF和细节层DF结合得到。
F=BF+DF.
除了灰度图像外,本文提出的MGF算法也应用于彩色图像,分别在红色、绿色和蓝色通道上实现。最后将这些通道连接起来,得到融合后的彩色图像。
实验和结果
在图像和视频上进行了大量的仿真。
首先,我们讨论了为此使用的实验设置。
然后,基于结果,我们提出了视觉质量,融合指标和运行时间的分析。
最后,我们对融合后的图像和视频进行了进一步的增强,以获得更好的视觉质量。
我们在提出的MGF中没有包含这种对比度增强的概念,以提供与其他融合方法的公平比较。
图像
定性分析(视觉观察)
融合范围很广:
多重曝光(8个数据集)、医学成像(8个数据集)、遥感(10个数据集)、多焦点(11个数据集)和视觉监测(13个VI-IR数据集)。
MGF能够在一幅图像中生成所有适当暴露的区域,而不引入视觉伪影和颜色畸变。
与GFF和GFS相比,MGF在视觉上产生了更集中的区域,具有更好的对比度和边缘信息。
相比之下,MGF方法能够将MRI和CT信息整合在一张图像中,具有更多的细节和更少的伪影。
MGF的纹理、边缘和源图像颜色信息保存得更好,也更清晰。
定量分析


run time
多重曝光的例子里,GFF、GFS和MGF的运行时间分别为0.8836、5.795和0.4822 s。

视频(只考虑6个随机帧)
MGF方法能够整合所有的战场和人员信息,且融合伪影较少。
只有目标在移动:

目标和摄像头都在移动:

有效融合,且更少伪影。
图像和视频对比度增强
CLAHE是图像和视频增强的最佳选择,CLAHE的MGF方法对图像和视频都有较好的视觉质量。

主要贡献
提出了一种新的基于引导滤波的视觉显著检测算法,用于从视觉不同的图像中提取显著性信息.提出了一种新的VSD算法。该算法可以从单个源图像中提取出整个场景的视觉显著性。
提出了一种快速、高效、通用的图像与视频融合方法。 针对图像融合的各种应用,提出了一种基于引导滤波的通用图像融合算法;
该方法利用细节层信息进行显著性提取和权值图构建,一个单一的多尺度引导滤波既可以提取视觉显著性,又可以进行图像融合。因此,大大降低了算法的复杂度。
然而,现有的基于引导滤波的融合方法使用不同的工具或技术进行特征提取(边缘和显著性信息)和融合;
MGF方法在多尺度分解模式下只需要GF,易于实现。然而,现有的基于GF的融合方法可能需要其他工具,如滤波器或转换技术。
。然而,目前基于gf的方法依赖于其他技术,如显著性检测或边缘提取技术来构建权值图。
在50个图像数据集、静态数据集和动态视频数据集上进行了广泛的模拟,结果表明,该方法快速、高效。
提出了合适的图像和视频增强算法,进一步增强了融合结果的视觉内容。
*而且作者提到该算法的应用场景不仅仅限制于在可见光与红外图像的融合,也可以用在其他图像融合上面*,所以应用面是很广的。
others:
原文献为:《Multi-scale Guided Imageand Video Fusion : A Fast
and Efficient Approach》
你可以在这个地址看到该文献和资源:
https://link.springer.com/article/10.1007/s00034-019-01131-z