总结今年来的几个轻量化模型:SqueezeNet、Xception、MobileNet、ShuffleNet
下面给出时间轴:
- 2016.02 伯克利&斯坦福提出 SqueezeNet
- 2016.10 google提出 Xception
- 2017.04 google提出 MobileNet
- 2017.07 face++提出 ShuffleNet
其次,说一下模型轻量化的一些方法:
- 卷积核分解:使用1xN和NX1卷积核代替NXN卷积核;
- 使用深度压缩deep compression方法:网络剪枝、量化、哈弗曼编码;
- 奇异值分解;
- 硬件加速器;
- 低精度浮点数保存;
小模型的好处有哪些:
- 在分布式训练中,与服务器通信需求小;
- 参数少,从云端下载模型的数据量小;
- 更适合在FPGA等内存首先的嵌入式、移动端设备上部署;
1、SqueezeNet
地址链接:https://arxiv.org/pdf/1602.07360.pdf
1.1 核心思想
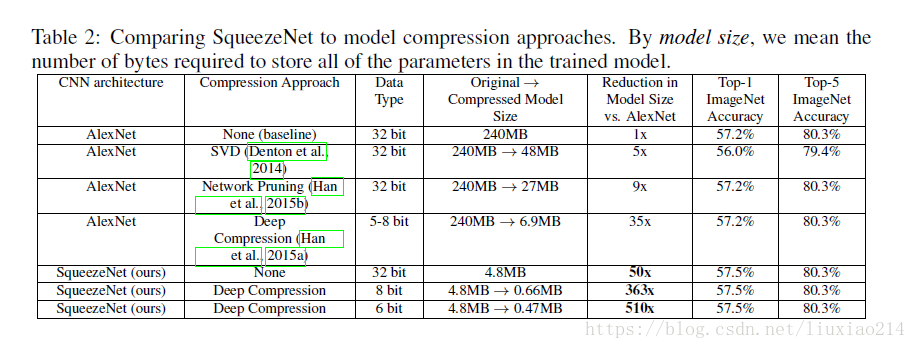
在ImageNet上实现了与Alexnet相似的效果,参数只有其1/50, 模型是0.5MB,占其1/510。
SqueezeNet核心内容有以下几点:
- 使用1x1卷积核代替3x3卷积核,减少参数量;
- 通过squeeze layer限制通道数量,减少参数量;
- 借鉴inception思想,将1x1和3x3卷积后结果进行concat;为了使其feature map的size相同,3x3卷积核进行了padding;
- 减少池化层,并将池化操作延后,给卷积层带来更大的激活层,保留更多地信息,提高准确率;
- 使用全局平均池化代替全连接层;
上述1-3是通过fire module实现的,fire module主要分为两部分,如下图所示
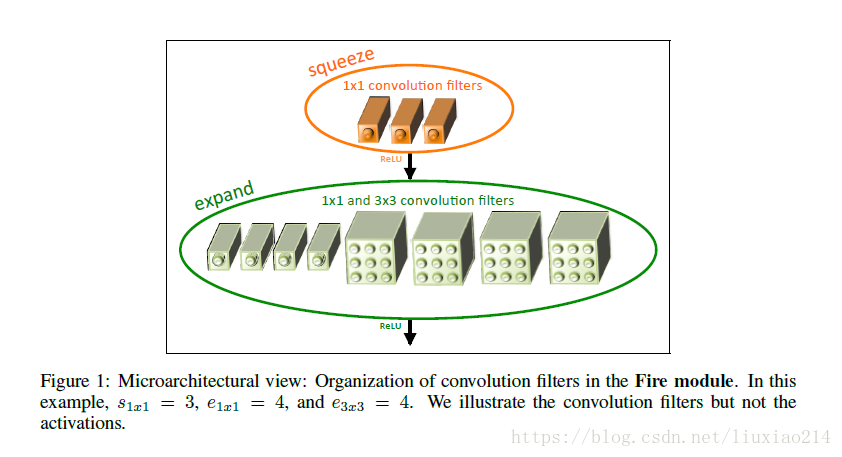
- squeeze:1x1卷积核,参数s_1x1表示卷积核数量
- expand:1x1卷积核和3x3卷积核,参数e_1x1和e_3x3分别表示两种卷积核的数量
该模块一共三参数s_1x1、e_1x1、e_3x3,关系保持s_1x1< e_1x1+e_3x3
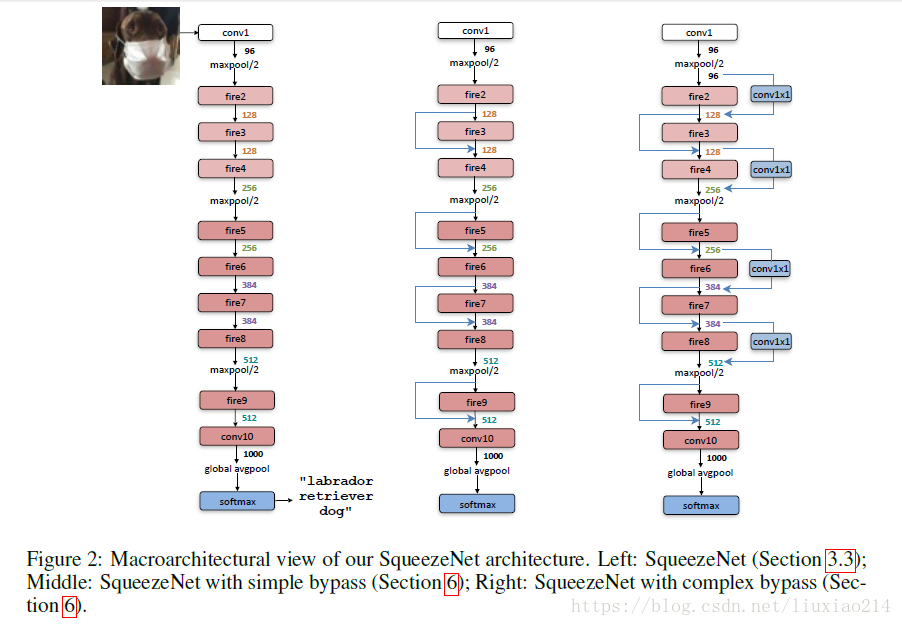
1.2 网络结构
1.3 实验结果
实验结果表示模型小,且准确率不降,反而有点提高;
参考链接:
1、https://blog.csdn.net/csdnldp/article/details/78648543
2、https://blog.csdn.net/u011995719/article/details/78908755
2、Xception
地址链接:https://arxiv.org/abs/1610.02357
2.1 核心思想
虽然本文中方法可以降低参数量,但是论文加宽了网络结构,因此这篇论文不在于压缩模型,旨在于提高性能,与同等参数量的inception v3相比,效果更好。
首先是inception v3的一系列延伸,见下图:
1、版本1:最初的inception v3
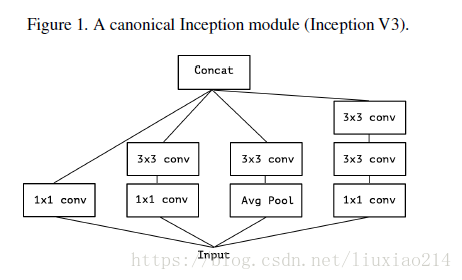
2、版本2:对1进行简化
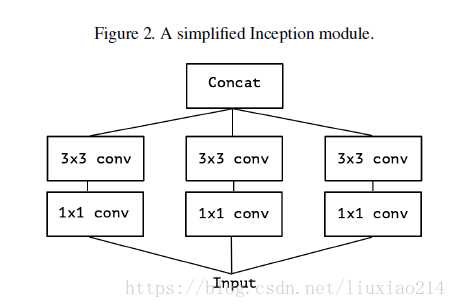
3、版本3:对2简化,可以先使用一个统一的1x1卷积核,然后每个3x3卷积核的输入只是1x1卷积后的feature map的一部分。本图中是1/3;
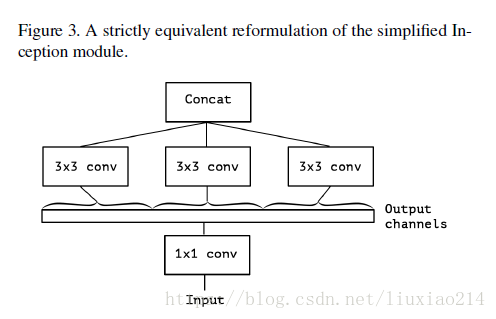
4、版本4:在3的基础上进一步延伸,将1x1卷积后的所有feature map按通道全部划分,每一个通道对应一个3x3卷积,即3x3卷积核的数量就是1x1卷积后feature map的通道数。
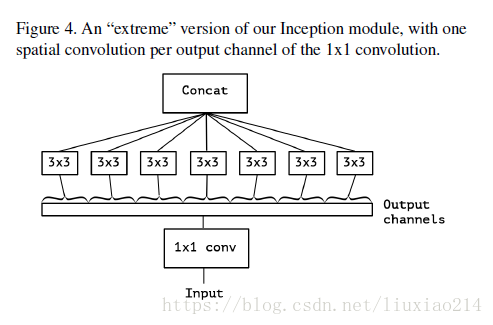
然后在xception中,主要采用depthwise separable convolution思想(这个后面在mobile net中详细解释,好奇怪,明明是mobile net后出现的,反正都是一家的,估计公布先后的问题吧。)
首先xception类似于图4,但是区别有两点:
1、xception中没有relu激活函数;
2、图4是先1x1卷积,后通道分离;xception是先进行通道分离,即depthwise separable convolution,然后再进行1x1卷积。
此外,进行残差连接时,不再是concat,而是采用加法操作。
2.2 网络结构

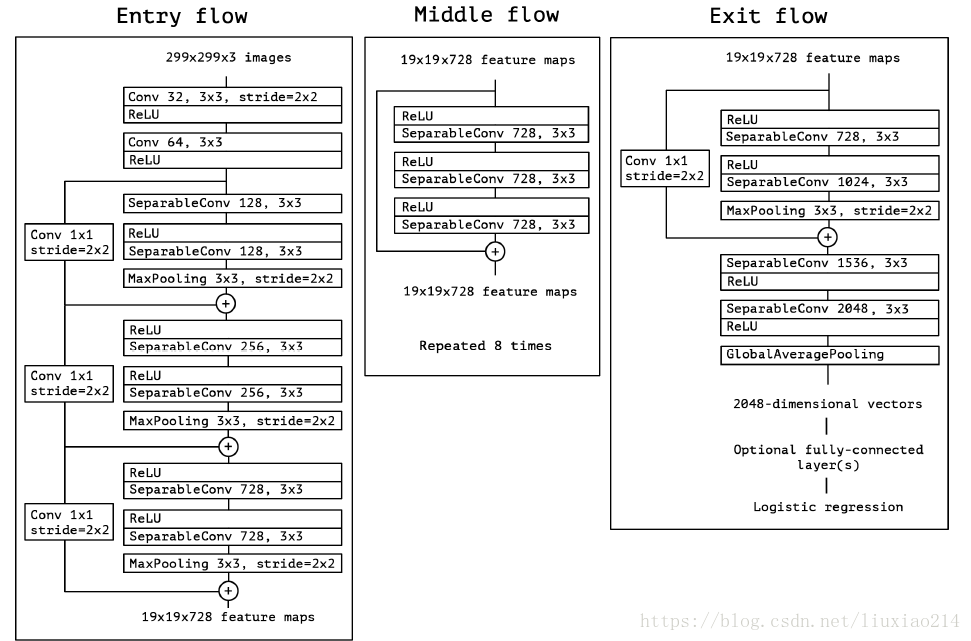
2.3 实验结果
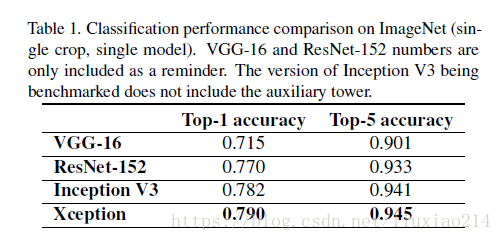
参考链接:
1、https://blog.csdn.net/u014380165/article/details/75142710
2、https://www.baidu.com/link?url=ERPMsc_io0x0usMhZdLD5POp-4p3dHyNtg4z92eeNsIpzxbKJMtmEH39A5op8p2XiQ4CWDPMu03Ygbrs8GAOAK&wd=&eqid=e517c5270000c4ed000000035b7a2a44
3、MobileNet
地址链接:https://arxiv.org/pdf/1704.04861.pdf
3.1 核心思想
主要是两个策略:
- 采用depthwise separable convolution,就是分离卷积核;
- 设置宽度因子width multipler和分辨率因子resolution multiplier;
3.1.1 depthwise separable convolution
假设上一层得到的feature map的size为D_K * D_K * M,本层的卷积核大小为D_K * D_K,卷积核个数为M。
1、首先介绍传统卷积核的操作方式,如下图。
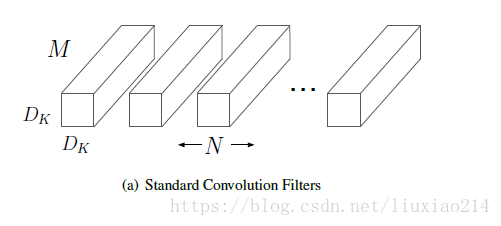
卷积核D_K * D_K需要在feature map的每个通道上进行D_K * D_K次卷积,然后一共M个卷积核,因此计算量为:
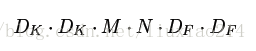
2、介绍depthwise separable convolution,如下图

将卷积核进行拆解,分为两步,首先用M个D_K * D_K卷积核在feature map进行卷积,计算量为
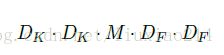
然后再使用N个1 * 1 * M卷积核在前面得到的结果上进行feature map,计算量为:
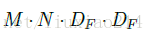
所以,进行分解后的总计算量为:
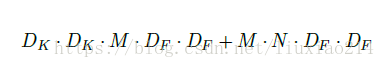
3、计算量比较
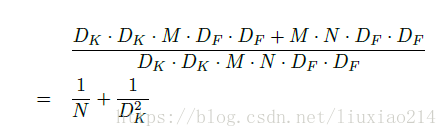
可以看到,随着卷积核个数的增加,即通道数变多,feature map的大小,传统方式的计算量比分解要大得多。
3.1.2 宽度因子和分辨率因子
怎么才能使网络进一步压缩呢?可以进一步减少feature map的通道数和size,通过宽度因子减少通道数,分辨率因子减少size。
1、宽度因子α
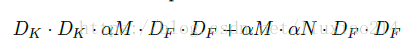
2、分辨率因子β

两个参数都属于(0,1]之间,当为1时则是标准mobileNet。
3.2 网络结构
3.2.1 基本结构块

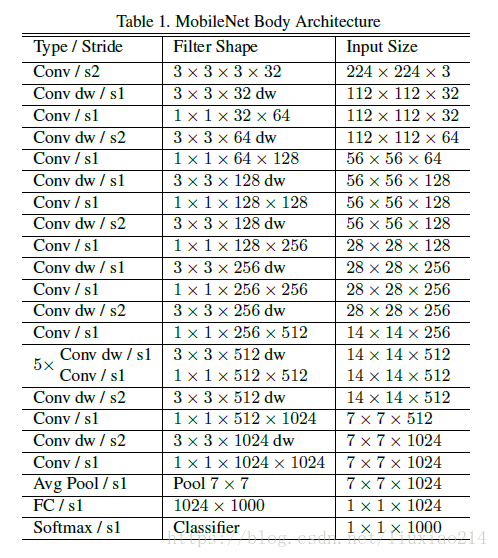
3.2.2 网络结构
3.2.3 训练细节
1、使用RMSprop优化器;
2、未做大量数据增强,因为参数量小过拟合不严重;
3、采用了随机图像裁剪输入;
4、使用较小的weight decay,或者不使用;
3.3 实验结果
给出几个基本的实验比较结果。
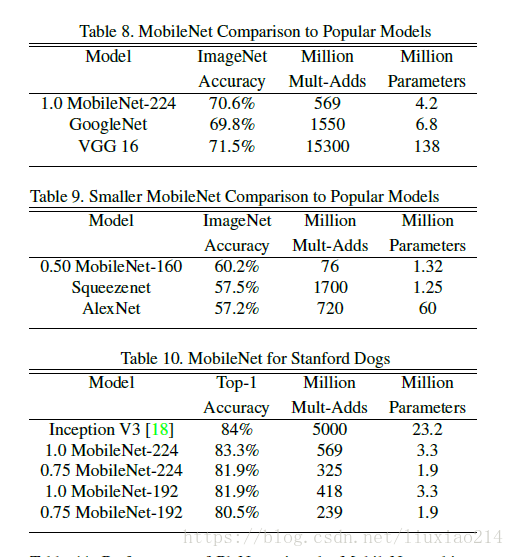
参考链接:
1、https://blog.csdn.net/t800ghb/article/details/78879612
2、https://blog.csdn.net/wfei101/article/details/78310226
3、https://blog.csdn.net/u014380165/article/details/72938047
4、ShuffleNet
地址链接:https://arxiv.org/pdf/1707.01083.pdf
4.1 核心思想
核心思想有两点:
- 借鉴resnext分组卷积思想,但不同的是采用1x1卷积核;
- 进行通道清洗,加强通道间的信息流通,提高信息表示能力。
此外本篇论文中也采取了mobilenet的depthwise separasable convolution的方式。
4.1.1 逐点群卷积pointwise group convolution
这个就是采用resnext的思想,将通道分组,每组分别进行卷积操作,然后再把结果进行concat。但是不同于resnext的是,shufflenet采用的是1x1卷积核。
4.1.2 通道清洗channel shuffle
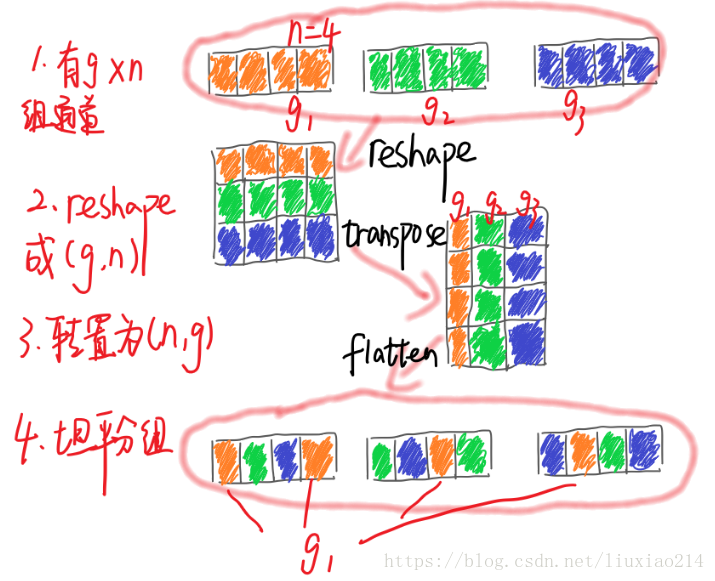
什么是通道shuffle,就是在分组卷积后得到的feature map不直接进行concat,先将每组feature map按通道打乱,重新concat,如下图所示:
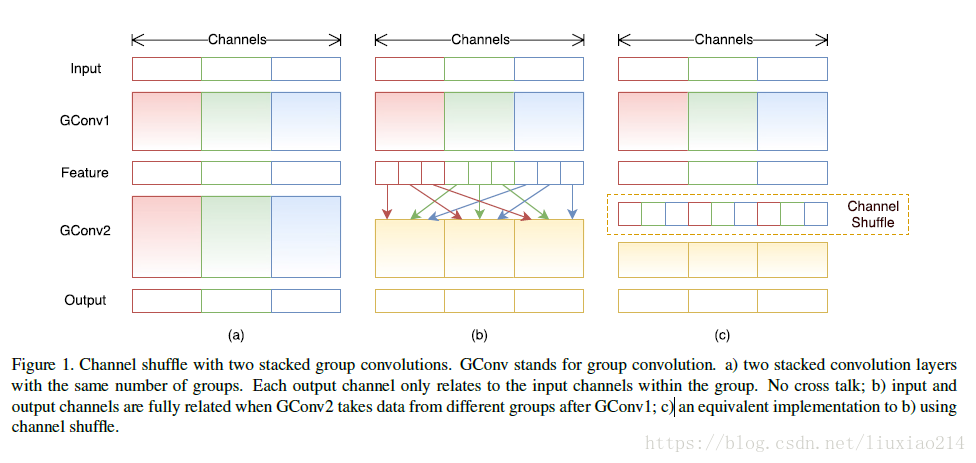
如何进行shuffle,这里参考链接,
对于一个卷积层分为g组,
- 卷积后一共得到g×n个输出通道的feature map;
- 将feature map 进行 reshape为(g,n);
- 进行转置为(n,g);
- 对转置结果flatten,再分回g组作为下一层的输入。
4.2 网络结构
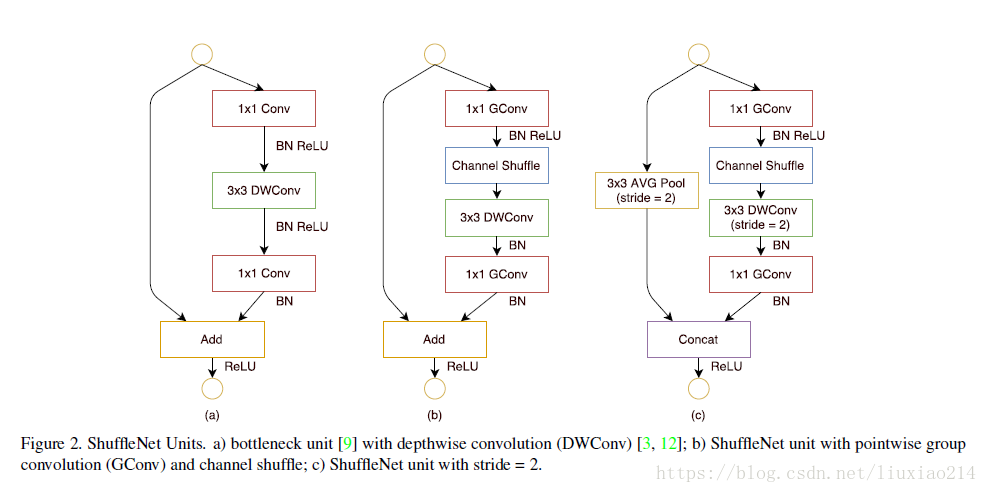
4.2.1 shuffle unit
下图中,a是标准的残差结构,不过是3x3卷积核使用了mobilenet中的depthwise convolution操作;
b是在a的基础上加了本文的通道shuffle操作,先对1x1卷积进行分组卷积操作,然后进行channel shuffle;
c是在旁路加了一步长为2的3x3的平均池化,并将前两者残差相加的操作改为了通道concat,增加了通道数量。
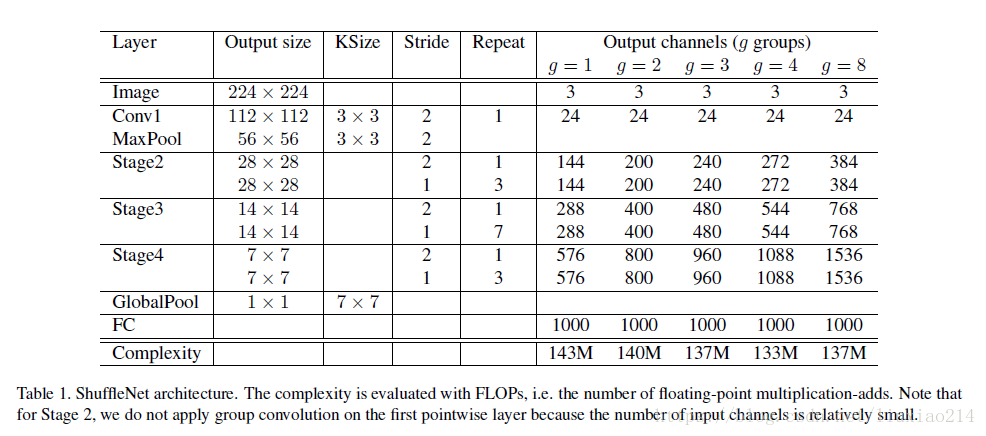
4.2.2 网络结构
4.3 实验结果
1、评估逐点组卷积:分组的效果均比没有分组的效果好,但是某些模型随着组数增加,性能有下降,这就是通道间失去联系带来的问题;
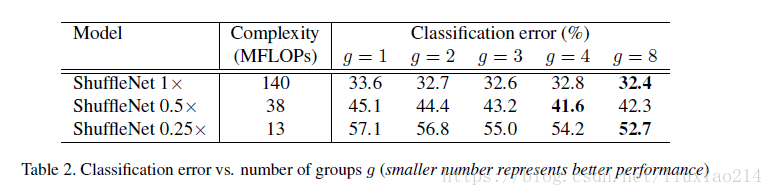
2、评估channel shuffle,shuffle会比没有shuffle效果好,而且对于组数越大,效果越好,说明了shuffle的重要性,也说明了上图中组数增加性能下降的问题。
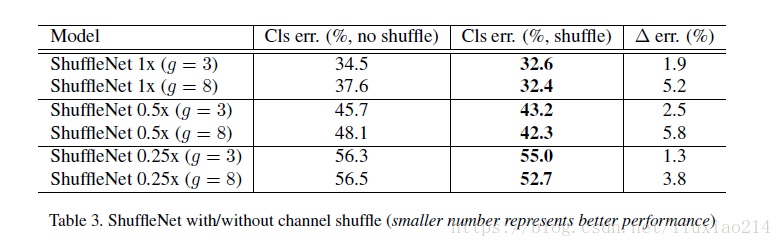
3、与mobilenet的比较
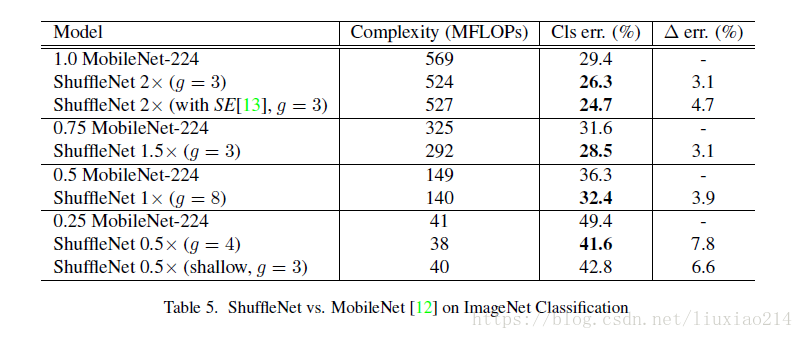
参考链接:
1、https://blog.csdn.net/u011974639/article/details/79200559
2、https://blog.csdn.net/u014380165/article/details/75137111