马尔科夫链
-
总体思想: 过去的所有信息都被保存在了现在的状态中,只使用现在状态就能预测到之后的状态,换句话说就是某个时刻的状态转移概率只依赖于它的前一个状态。
-
公式化表达:P(xt+1∣xt,xt−1,...,x1,x0)=P(xt+1∣xt)P(x_{t+1}|x_t,x_{t-1},...,x_1,x_0)=P(x_{t+1}|x_t)P(xt+1∣xt,xt−1,...,x1,x0)=P(xt+1∣xt)
-
举例:
-
股市涨跌:当前股市的涨、跌、平的状态概率分别为[0.3,0.4,0.3],当前股市的涨、跌、平的状态概率分别为[0.3,0.4,0.3],且转移概率矩阵为:
[0.9,0.075,0.0250.15,0.5,0.050.25,0.25,0.5](1)\left[\begin{matrix} 0.9,&0.075,&0.025\\ 0.15,&0.5,&0.05 \tag{1}\\ 0.25,&0.25,&0.5 \end{matrix}\right] 0.9,0.15,0.25,0.075,0.5,0.25,0.0250.050.5(1)
比如第二行第三列的0.05表示今天跌,明天平的概率。根绝上面的状态转移方程和今天的故事概率,可以依次得到后面每一轮涨、跌、平的概率:
[0.405,0.4175,0.1775]→[0.4715,0.49875,0.11975]→...→[0.625,0.315,0.0625][0.405,0.4175,0.1775]\rightarrow[0.4715,0.49875,0.11975]\rightarrow...\rightarrow[0.625,0.315,0.0625][0.405,0.4175,0.1775]→[0.4715,0.49875,0.11975]→...→[0.625,0.315,0.0625]
并且轮数在尽可能大的时候(60轮),那么状态概率就一直保持在[0.625,0.315,0.0625][0.625,0.315,0.0625][0.625,0.315,0.0625],这也是马尔科夫链的状态转移稳定性。
-
放回袋中的取球问题:当前取球颜色的概率只与上次取完后的结果有关。
-
高斯分布的可加性
两个独立高斯分布相加仍然是高斯分布,且相加后的高斯分布均值为原两个高斯分布均值之和,方差为原方差之和:
N(x1;μ1,σ12)+N(x2;μ2,σ22)=N(x1+x2;μ1+μ2,σ12+σ22)(2)\mathcal N(x_1;\mu_1,\sigma_1^2)+\mathcal N(x_2;\mu_2,\sigma_2^2)=\mathcal N(x_1+x_2;\mu_1+\mu_2,\sigma_1^2+\sigma_2^2) \tag{2} N(x1;μ1,σ12)+N(x2;μ2,σ22)=N(x1+x2;μ1+μ2,σ12+σ22)(2)
AE和VAE
-
AE(AutoEncoder)
- 基本概念: 输入的图片数据X经过Encoder后会得到一个比较确切的latent code Z(对这个latent code无其他约束),这个Z通过Decoder重建出图像X’,损失函数就是X和X’的重建MSE损失值。
- 用处: 数据去噪、数据降维(配合适当的维度和稀疏约束,自编码器可以学习到比PCA等技术更有意思的数据投影)
-
VAE(Variational AutoEncoder)
-
区别于AE: 相比于AE,VAE更倾向于数据生成。只要训练好了Decoder,我们就可以从latent space的某一个标准正态分布采样latent code作为解码器Decoder的输入,来生成类似的、但是但不完全相同于训练数据的新数据,也许是我们从来没见过的数据,作用类似GAN
-
重点: 在训练过程中,就像AE一样输入数据x被输入到Encoder输入通过一系列层(由超参数控制)来减少其维度,以获得压缩的latent code z。但是Encoder并不是直接输出latent code z,而是输出每个潜在变量的平均值和标准差,注意这里说的是每个!即对于每一个输入样本x我们都期望其经过encoder得到的latent code也是一个正态分布中采样得到的,那么对于k个样本x就有k个正态分布,然后就有k个分别从这k个正态分布中采样得到的latent code用于输入到decoder中重建原输入x。而为了得到这k个正太分布我们就需要有k组均值和方差。
Latent code的方差不能为 0,因为我们还想要给模型一些训练难度。如果方差为 0,模型永远只需要学习高斯分布的均值,这样就丢失了随机性,VAE就变成AE了……**这就是为什么VAE要在AE前面加一个Variational:我们希望方差能够持续存在,从而带来噪声!**那如何解决这个问题呢?不仅需要保证有方差,还要让所有 P(Z∣X)P(Z|X)P(Z∣X) 趋于标准正态分布 N(0,I)\mathcal N(0,\Iota)N(0,I)。
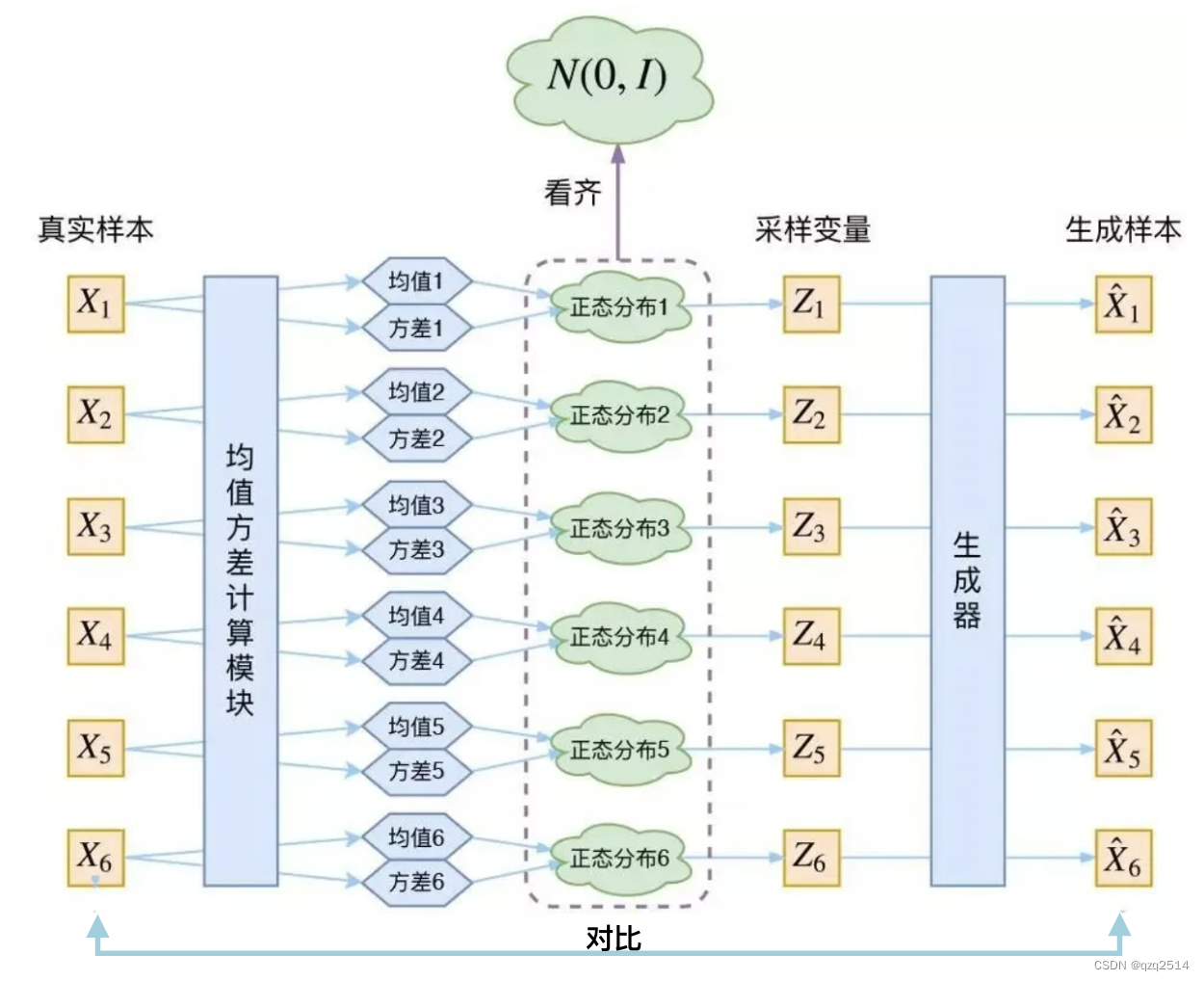
VAE框架(原图来自HeptaAI.zhihu) -
- 损失函数: 除了和AE中的重构MSE损失之外,VAE还有一个相似度损失,即latent space与标准高斯(零均值和单位方差)之间的KL散度
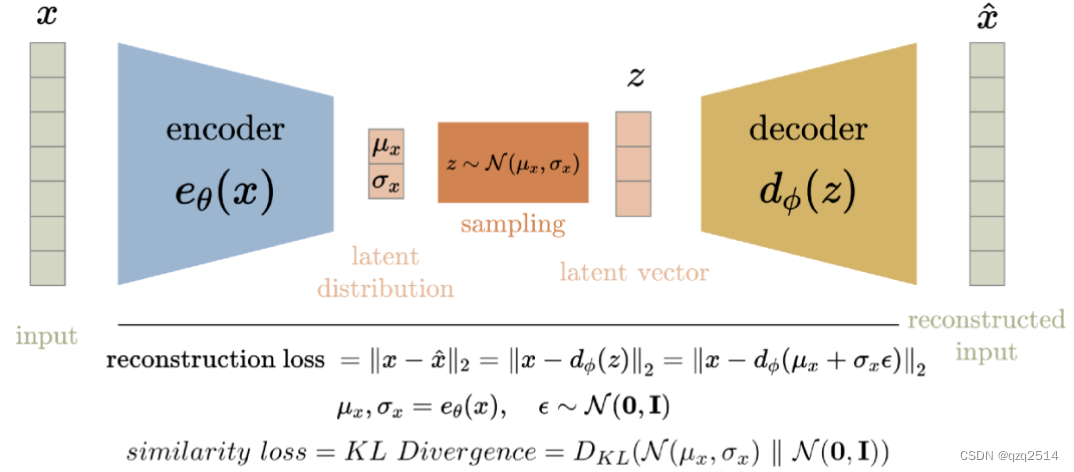
VAE损失计算(原图来自数据派THU)
参考:
- 如何通俗理解扩散模型?
- 深度学习《再探AE和VAE的区别》
- AutoEncoder (AE) 和 Variational AutoEncoder (VAE) 的详细介绍和对比
重参数技巧
如果我们需要从某个随机分布(如高斯噪声)中采样一个样本,这个过程是不可微的也无法进行反向传播,此时我们可以通过重采参数技巧使其可微。比如我们想要从一个普通高斯分布z∼N(z;μ,σ2)z\sim\mathcal N(z;\mu,\sigma^2)z∼N(z;μ,σ2)中采样一个zzz,那么我们就可以额外引入一个服从于标准高斯分布的独立随机变量ϵ∼N(0,1)\epsilon\sim\mathcal N(0,1)ϵ∼N(0,1),然后对这个随机变量缩放或偏移以接近原始待采样的分布,这个缩放和偏移的过程就是重参数的主要公式:
z=μ+σ⋅ϵ,其中 ϵ∼N(0,I)(3)z=\mu+\sigma\cdot\epsilon,\text{ } 其中\text{ }\epsilon\sim\mathcal N(0,\Iota) \tag{3} z=μ+σ⋅ϵ, 其中 ϵ∼N(0,I)(3)
即对一个标准高斯分布按照指定的标准差和均值进行缩放、偏移,就能获得符合原高斯分布N(z;μ,σ2I)\mathcal N(z;\mu,\sigma^2\Iota)N(z;μ,σ2I)的采样结果。
积分、求和、期望的关系
- 离散随机变量的期望:将该离散随机变量的每个观测值f(x)f(x)f(x)乘以各自的出现的概率p(x)p(x)p(x),最后求和就得到期望:
Ep(x)[f(x)]=E[f(x)]=∑ip(xi)f(xi),且概率总和∑ip(xi)=1(4)E_{p(x)}[f(x)]=E[f(x)]=\sum_{i}p(x_i)f(x_i),且概率总和\sum_{i}p(x_i)=1 \tag{4} Ep(x)[f(x)]=E[f(x)]=i∑p(xi)f(xi),且概率总和i∑p(xi)=1(4)
举一个掷骰子的例子,6个面每个面的向上的概率是16\frac1661,那么其向上的点数值的期望就是:
1×16+2×16+3×16+4×16+5×16+6×16=3.5(5)1\times\frac16+2\times\frac16+3\times\frac16+4\times\frac16+5\times\frac16+6\times\frac16=3.5 \tag{5} 1×61+2×61+3×61+4×61+5×61+6×61=3.5(5)
- 一个连续随机变量将它的概率密度p(x)p(x)p(x)和观测值f(x)f(x)f(x)的相乘,再把这个随机变量所有取值都算上后做定积分,就能得到这个随机变量的期望值:
Ep(x)[f(x)]=E[f(x)]=∫p(x)f(x)dx,且概率密度总积分∫p(x)dx=∫xp(x)=1(6)E_{p(x)}[f(x)]=E[f(x)]=\int p(x)f(x)dx,且概率密度总积分\int p(x) dx=\int_{x}p(x)=1 \tag{6} Ep(x)[f(x)]=E[f(x)]=∫p(x)f(x)dx,且概率密度总积分∫p(x)dx=∫xp(x)=1(6)
条件概率、边缘概率、联合概率
- 联合概率:多个条件同时成立的概率,记作P(A,B)P(A, B)P(A,B)
- 边缘概率:与联合概率相对应,记作P(A)或P(B),在不考虑其他白能量取值的情况下其中某个单个随机变量有关的概率。
- 条件概率:在事件B发生的前提下事件A发生的概率,记作P(A∣B)P(A|B)P(A∣B)
边缘、联合概率的关系:P(A)=∑iP(A,Bi)或P(A)=∫BP(A,B)边缘、联合、条件概率的关系:P(A∣B)=P(A,B)P(B)\begin{align} 边缘、联合概率的关系: P(A)&=\sum_iP(A,B_i)或P(A)=\int_BP(A,B) \tag{7} \\ 边缘、联合、条件概率的关系:P(A|B)&=\frac{P(A,B)}{P(B)} \tag{8} \end{align} 边缘、联合概率的关系:P(A)边缘、联合、条件概率的关系:P(A∣B)=i∑P(A,Bi)或P(A)=∫BP(A,B)=P(B)P(A,B)(7)(8)
- 全概率:某一个单独事件发生概率等于这个事件在其他完备事件的条件概率之和:
P(A)=∑iP(A∣Bi)P(Bi)(9)P(A)=\sum_iP(A|B_i)P(Bi) \tag{9} P(A)=i∑P(A∣Bi)P(Bi)(9)
其实就是公式(7)的P(A,Bi)P(A,B_i)P(A,Bi)利用公式(8)进行展开
贝叶斯公式
贝叶斯公式由条件概率公式可以进一步推导得到:
P(A∣B)=P(A,B)P(B)=P(B∣A)P(A)P(B)P(A∣B,C)=P(B∣A,C)P(A∣C)P(B∣C)\begin{align} P(A|B)&=\frac{P(A,B)}{P(B)}=P(B|A)\frac{P(A)}{P(B)} \tag{10-1}\\ P(A|B,C)&=P(B|A,C)\frac{P(A|C)}{P(B|C)} \tag{10-2} \end{align} P(A∣B)P(A∣B,C)=P(B)P(A,B)=P(B∣A)P(B)P(A)=P(B∣A,C)P(B∣C)P(A∣C)(10-1)(10-2)
其中P(A∣B,C)P(A|B,C)P(A∣B,C)表示在时间B和C同发生时,事件A发生的概率。
此外针对公式10-2有一些衍生的公式如下:
P(A∣B,C)=P(A,B,C)P(B,C)=P(B∣A,C)∗P(A∣C)∗P(C)P(B∣C)∗P(C)=P(B∣A,C)P(A∣C)P(B∣C)\begin{align} P(A|B,C)&=\frac{P(A,B,C)}{P(B,C)} \notag{ } \\ &= \frac{P(B|A,C)*P(A|C)*P(C)}{P(B|C)*P(C)} \tag{11} \\ &=P(B|A,C)\frac{P(A|C)}{P(B|C)} \notag{} \\ \end{align} P(A∣B,C)=P(B,C)P(A,B,C)=P(B∣C)∗P(C)P(B∣A,C)∗P(A∣C)∗P(C)=P(B∣A,C)P(B∣C)P(A∣C)(11)
此外对于公式(11)的第一步的分子分母同时除以P(C)P(C)P(C)有:
P(A∣B,C)=P(A,B,C)/P(C)P(B,C)/P(C)=P(A,B∣C)P(B∣C)\begin{align} P(A|B,C)&=\frac{P(A,B,C)/P(C)}{P(B,C)/P(C)} \notag{} \\ &=\frac{P(A,B|C)}{P(B|C)} \tag{12} \end{align} P(A∣B,C)=P(B,C)/P(C)P(A,B,C)/P(C)=P(B∣C)P(A,B∣C)(12)
其中P(A,B∣C)P(A,B|C)P(A,B∣C)表示在事件C发生时,事件A和事件B同时发生发生的概率。
最大似然估计(MLE)
最大似然估计是被使用最为广泛一种参数估计方法,其核心思想就是:那么既然事情已经发生了,为什么不让这个出现的结果的可能性最大呢?。在深度学习中通俗来讲就是利用已知的样本信息(比如我们的训练数据集),去反推最有可能“完美”生成这批样本的模型的参数值,其满足的一个前提就是样本独立同分布。
这个参考文献中举了一个“袋中摸球”的例子很形象讲的很精彩,此外再完全引用其中的一段话:
" 对于函数P(x∣θ)P(x|\theta)P(x∣θ)输入有两个:xxx表示某一个具体的数据/样本;θ\thetaθ表示模型的参数。
- 如果θ\thetaθ是已知确定的,xxx是变量,这个函数叫做概率函数(probability function),它描述在模型时对于不同的样本点x,其出现概率是多少。
- 如果xxx是已知确定的,θ\thetaθ是变量,这个函数叫做似然函数(likelihood function), 它描述对于不同的模型参数,出现x这个样本点的概率是多少。"
在深度学习中我们通常是样本xxx已知去计算未知的模型参数θ\thetaθ,即P(x∣θ)P(x|\theta)P(x∣θ)变成了一个似然函数,最大似然估计就是要求得参数θ\thetaθ使得该似然函数的值最大。
所以最大似然估计的函数表达式也很简单,就是最大化下面的函数:
Eq(x)log(p(x∣θ))(13)E_{q(x)}\log(p(x|\theta)) \tag{13} Eq(x)log(p(x∣θ))(13)
再举一个平时我自己用的一个例子:
对于深度学习中的分类问题,假定y=fθ(x)y=f_\theta(x)y=fθ(x)即样本x经过参数为θ\thetaθ的网络fθf_\thetafθ后输出的类别概率分布为yyy,如果类别数是n,则y是一个长度为n的概率分布,其中元素yjy^jyj表示预测为第j类的概率,样本的GT我们规定为是一个长度为n的one-hot向量y~j\widetilde y^jyj,那么我们最好的网络肯定是希望预测的概率yiy^iyi和真实的标签y~i\widetilde y^iyi是近乎相同的(),那么可以将这种相似性写成如下形式:
P(y~∣θ)=∏j=1n(yj)y~j(14)P(\widetilde y|\theta)=\prod_{j=1}^n(y^j)^{\widetilde y^j} \tag{14} P(y∣θ)=j=1∏n(yj)yj(14)
通俗点理解就是希望在y~\widetilde yy中为1的位置yyy也为1;在y~\widetilde yy中为0的位置yyy也为0,对上式左右取log得:
logP(y~∣θ)=∑j=1ny~j⋅log(yj)(15)\log P(\widetilde y|\theta)=\sum_{j=1}^n\widetilde y^j\cdot \log(y^j) \tag{15} logP(y∣θ)=j=1∑nyj⋅log(yj)(15)
可以发现上面其实就是计算两个离散分布y~\tilde yy~和yyy的交叉熵的负数,最大化上面的结果就等于最小化这两个分布的交叉熵。而交叉熵其实这也就是分类任务中普遍常用的损失函数。
拓展:最大后验概率估计(MAP)
相比较于最大似然估计,最大后验概率估计是最大化p(x∣θ)p(θ)p(x|\theta) p(\theta)p(x∣θ)p(θ),即最合适的θ\thetaθ不仅仅让似然函数p(x∣θ)p(x|\theta)p(x∣θ)最大,也要让p(θ)p(\theta)p(θ)尽量大,因为根据贝叶斯公式有:p(θ∣x)=p(x∣θ)p(θ)p(x)p(\theta|x)=\frac{p(x|\theta)p(\theta)}{p(x)}p(θ∣x)=p(x)p(x∣θ)p(θ),因为p(x)p(x)p(x)是真实数据分布,所以最大后验估计优化的上式分子最大值,其实也就是整体p(θ∣x)p(\theta|x)p(θ∣x)的最大,即后验证概率,这也就是"最大后验概率估计"的名字由来。 参考文献讲的很好。
最大似然估计(MLE)和最大后验概率估计(MAP)的区别在于:MAP就是多个作为因子的先验概率p(θ)p(\theta)p(θ)。或者也可以反过来认为MLE是把先验概率p(θ)p(\theta)p(θ)认为等于1,即认为θ\thetaθ是均匀分布。
变分下限(Variational Lower Bound)
变分下限(VLB)也叫evidence lower bound (ELBO).
在最大似然估计中,有时候难以直接计算并最大化似然函数p(x∣θ)p(x|\theta)p(x∣θ)–也可以写成pθ(x)p_\theta(x)pθ(x)那么如果我们可以知道他的一个下界,那么最大化他的一个下界,也就可以保证原始的似然函数p(x∣θ)p(x|\theta)p(x∣θ)尽可能大。这里我们要引入另一个分布q(z)q(z)q(z),我们可以理解为xxx和zzz分别是VAE中的观测值(原始数据)和隐变量,两者的关系为我们将隐变量zzz输入到一个decoder中得到结果xxx,其中隐变量zzz一般我们可以规定其从高斯分布中采样而来,即q(x)q(x)q(x)可以假定为一个高斯分布,现在我们从两个角度求原似然函数p(x∣θ)p(x|\theta)p(x∣θ)的下界,其中p(x∣θ)p(x|\theta)p(x∣θ)均简写为p(x)p(x)p(x)。
-
琴生不等式:
logp(x)=log∫zp(x,z)=log∫zp(x,z)q(z)q(z)=log(Eq(z)p(x,z)q(z))≥Eq(z)logp(x,z)q(z)=Eq(z)logp(x,z)−Eq(z)logq(z)=Eq(z)logp(x,z)+H(q)=VLB\begin{align} \log p(x)&=\log \int_z p(x,z) \tag{全概率公式} \\ &=\log\int_zp(x,z)\frac{q(z)}{q(z)} \notag{} \\ &=\log(E_{q(z)}\frac{p(x,z)}{q(z)}) \tag{积分求和变期望} \\ &\geq E_{q(z)}\log\frac{p(x,z)}{q(z)} \tag{\textcolor{red}{琴生不等式}} \\ &=E_{q(z)}\log p(x,z)-E_{q(z)}\log q(z) \notag{}\\ &=E_{q(z)}\log p(x,z)+H(q) \tag{熵的公式}\\ &=VLB \tag{16} \end{align} logp(x)=log∫zp(x,z)=log∫zp(x,z)q(z)q(z)=log(Eq(z)q(z)p(x,z))≥Eq(z)logq(z)p(x,z)=Eq(z)logp(x,z)−Eq(z)logq(z)=Eq(z)logp(x,z)+H(q)=VLB(全概率公式)(积分求和变期望)(琴生不等式)(熵的公式)(16) -
KL散度:
logp(x)=logp(x)∫zq(z)=∫zq(z)logp(x)=∫zq(z)logp(x,z)p(z∣x)=∫zq(z)logp(x,z)q(z)q(z)p(z∣x)=∫zq(z)logp(x,z)−∫zq(z)logq(z)+∫zq(z)logq(z)p(z∣x)=Eq(z)logp(x,z)−Eq(z)logq(z)+Eq(z)logq(z)p(z∣x)=Eq(z)logp(x,z)+H(q)+KL(q(z)∣∣p(z∣x))≥Eq(z)logp(x,z)+H(q)=VLB\begin{align} \log p(x)&=\log p(x)\int_z q(z) \tag{概率密度积分$\int_z q(z)=1$} \\ &=\int_z q(z)\log p(x) \notag{} \\ &=\int_z q(z)\log \frac{p(x,z)}{p(z|x)} \notag{} \\ &=\int_z \textcolor{red}{q(z)}\log \frac{p(x,z)\textcolor{red}{q(z)}}{q(z)\textcolor{red}{p(z|x)}} \tag{同乘$q(z)$} \\ &=\int_z q(z)\log p(x,z)-\int_z q(z)\log q(z)+\int_z \textcolor{red}{q(z)\log\frac{q(z)}{p(z|x)}} \notag{} \\ &=E_{q(z)}\log p(x,z)-E_{q(z)}\log q(z)+E_{q(z)}\log\frac{q(z)}{p(z|x)} \notag{}\\ &=E_{q(z)}\log p(x,z)+H(q)+KL(q(z)||p(z|x)) \notag{}\\ &\geq E_{q(z)}\log p(x,z)+H(q) \tag{\textcolor{red}{KL散度的非负性}} \\ &=VLB \tag{17} \end{align} logp(x)=logp(x)∫zq(z)=∫zq(z)logp(x)=∫zq(z)logp(z∣x)p(x,z)=∫zq(z)logq(z)p(z∣x)p(x,z)q(z)=∫zq(z)logp(x,z)−∫zq(z)logq(z)+∫zq(z)logp(z∣x)q(z)=Eq(z)logp(x,z)−Eq(z)logq(z)+Eq(z)logp(z∣x)q(z)=Eq(z)logp(x,z)+H(q)+KL(q(z)∣∣p(z∣x))≥Eq(z)logp(x,z)+H(q)=VLB(概率密度积分∫zq(z)=1)(同乘q(z))(KL散度的非负性)(17)
琴生不等式
凸函数f(x)f(x)f(x)满足对于任意点集xi{x_i}xi有:
离散型表示:∑iλif(xi)≥f(∑iλixi)概率论中表示:E[f(x)]≥f(E(x))连续性表示:∫f(x)λ(x)dx≥f(∫xλ(x)dx),其中λ(x)为概率密度\begin{align} 离散型表示: \sum_i\lambda_if(x_i)&\geq f(\sum_i\lambda_ix_i) \tag{18-1}\\ 概率论中表示: E[f(x)]&\geq f(E(x)) \tag{18-2}\\ 连续性表示: \int f(x)\lambda(x)dx &\geq f(\int x\lambda(x)dx) ,其中\lambda(x)为概率密度 \tag{18-3} \end{align} 离散型表示:i∑λif(xi)概率论中表示:E[f(x)]连续性表示:∫f(x)λ(x)dx≥f(i∑λixi)≥f(E(x))≥f(∫xλ(x)dx),其中λ(x)为概率密度(18-1)(18-2)(18-3)
而凸函数的定义也很简单,其实就是向下凸的函数,常见的凸函数有log(x)、x2\log(x)、x^2log(x)、x2等
换句话说就是:函数值的加权和≥\geq≥加权和的函数值
KL散度计算
KL散度又称相对熵,用于描述两个概率分布PPP和QQQ的差异性
-
一般分布的KL散度求解:
DKL(P∣∣Q)=∑P(x)logP(x)Q(x)=−∑P(x)logQ(x)+∑P(x)log(P(x))=H(P,Q)−H(P)\begin{align} D_{KL}(P||Q)&=\sum P(x)\log\frac{P(x)}{Q(x)} \notag{}\\ &=-\sum P(x)\log{Q(x)}+\sum P(x)\log(P(x)) \notag{}\\ &=H(P,Q)-H(P)\tag{19} \end{align} DKL(P∣∣Q)=∑P(x)logQ(x)P(x)=−∑P(x)logQ(x)+∑P(x)log(P(x))=H(P,Q)−H(P)(19)
可以看到最终KL散度其实可以转化成交叉熵H(P,Q)H(P,Q)H(P,Q)和熵H(P)H(P)H(P)的差,且KL散度有两个重要性质:- 非对称性:DKL(P∣∣Q)≠DKL(Q∣∣P)D_{KL}(P||Q)\neq D_{KL}(Q||P)DKL(P∣∣Q)=DKL(Q∣∣P)
- 非负性:DKL(P∣∣Q)≥0D_{KL}(P||Q)\geq0DKL(P∣∣Q)≥0,仅在P=QP=QP=Q时取0
拓展: JS散度
正是由于KL散度的不对称性问题使得在某些训练过程中可能存在一些问题,为了解决这个问题则在KL散度基础上引入了JS散度,假定M=12(P+Q)M=\frac12(P+Q)M=21(P+Q),则JS散度可以表示为:
JDS(P∣∣Q)=12KL(P∣∣M)+12KL(Q∣∣M)=12∑p(x)log(p(x)p(x)+q(x))+12∑q(x)log(q(x)p(x)+q(x))+log2\begin{align} JDS(P||Q)&=\frac12KL(P||M)+\frac12KL(Q||M) \notag{}\\ &=\frac12\sum p(x)\log\Big(\frac{p(x)}{p(x)+q(x)}\Big)+\frac12\sum q(x)\log\Big(\frac{q(x)}{p(x)+q(x)}\Big)+\log2 \tag{20} \end{align} JDS(P∣∣Q)=21KL(P∣∣M)+21KL(Q∣∣M)=21∑p(x)log(p(x)+q(x)p(x))+21∑q(x)log(p(x)+q(x)q(x))+log2(20)
参考文献中的一段内容: JS散度是对称的,其取值是 0 到 1 之间。如果两个分布 P和Q 离得很远,完全没有重叠的时候,那么KL散度值是没有意义的,而公式(11)中JS散度值两个∑\sum∑是0,所以总体JS散度是一个常数(log2),这在学习算法中是比较致命的,这就意味这这一点的梯度为 0,梯度消失了。
证明P、Q不重叠时JS散度其实也很简单,就是因为不重叠,所以任意一个x,p(x)p(x)p(x)和q(x)q(x)q(x)中至少有一个为0,再计算公式(11)就很容易得到两个∑\sum∑都是0,最后JS散度就变成了常数log2.
思考:为什么会出现两个分部没有重叠的现象?
真实数据的分布其实是高维空间下的一个低维流行(可以类比想象成立体3维空间里的一个2维平面,而真实情况下可能空间维度),我们的数据没有"撑满"整个空间,这就导致很难重合。原始GAN的损失函数的最终优化目标就是优化真实数据分布和生成数据分布的JS散度,所以GAN有时候可能会出现训练崩塌的情况。
高斯分布的KL散度的快速求解
对于特殊的分布-高斯分布,我们可以直接通过其均值和方差快速求解KL散度:
KaTeX parse error: Multiple \tag
上面分别表示一元高斯分布和多元高斯分布的KL散度直接求解,其中det(A)det(A)det(A)和tr(A)tr(A)tr(A)分别表示矩阵的模和迹。
参考链接
重积分下的Fubini定理
富比尼定理提供了逐次积分的方法计算双重积分的条件。不但可以用逐次积分计算双重积分,而且在交换逐次积分的顺序时,保证了积分结果不会变
- 如果:f(x,y)=h(x)g(x),则∫Ah(x)dx⋅∫Bg(y)dy=∫A×Bd(x,y)如果:f(x,y)=h(x)g(x),则\int_Ah(x)dx\cdot\int_Bg(y)dy=\int_{A\times B}d(x,y)如果:f(x,y)=h(x)g(x),则∫Ah(x)dx⋅∫Bg(y)dy=∫A×Bd(x,y)
- ∫A[∫Bf(x,y)dy]dx=∫B[∫Af(x,y)dx]dy=∫A×Bf(x,y)d(x,y)\int_A\Big[\int_Bf(x,y)dy\Big]dx=\int_B\Big[\int_Af(x,y)dx\Big]dy=\int_{A\times B}f(x,y)d(x,y)∫A[∫Bf(x,y)dy]dx=∫B[∫Af(x,y)dx]dy=∫A×Bf(x,y)d(x,y)
![[ 数据结构 -- 手撕排序算法第七篇 ] 归并排序](https://img-blog.csdnimg.cn/c0621bb74ad3488b8cb8ac9b0a8d9311.png)