大家好,我是微学AI,今天给大家介绍一下人工智能中(Pytorch)框架下模型训练效果的提升方法。随着深度学习技术的快速发展,越来越多的应用场景需要建立复杂的、高精度的深度学习模型。为了实现这些目标,必须采用一系列复杂的技术来提高训练效果。
一、为什么要研究模型训练效果的提升方法
在过去,训练一个深度神经网络往往需要大量的时间和计算资源,而且结果也可能不如人意。但是随着新的技术被引入,训练深度学习模型的效率和准确度都得到了极大的提升。
例如,学习率调整法,动态调整学习率,应用在训练过程中,通过降低学习率来让模型更好地收敛。Batch Normalization技术能够使神经网络中的每一层都具有相似的分布,从而加速收敛和提高训练准确性;Dropout 技术可以防止过拟合,从而提高模型的泛化能力;数据增强技术可以增加训练样本数量并提高模型的泛化性能;迁移学习可以通过利用已有的模型或预训练的模型来解决新问题,从而节省训练时间并更快地达到较高的准确性。
同时,随着深度学习应用的广泛普及和深度学习模型的复杂化,提高训练效果的重要性也越来越凸显。训练效果好的模型可以更准确地预测未知数据,更好地满足实际应用需求。因此,应用复杂技术来提高训练效果已成为深度学习领域的研究热点,同时也是实现深度学习应用的必要手段。
二、模型训练效果的提升方法具体案例
在训练深度学习模型过程中,复杂技术可以应用于提高训练效果,下面我将举几个案例:学习率调整、批量归一化、权重正则化、梯度剪裁。
1. 学习率调整:
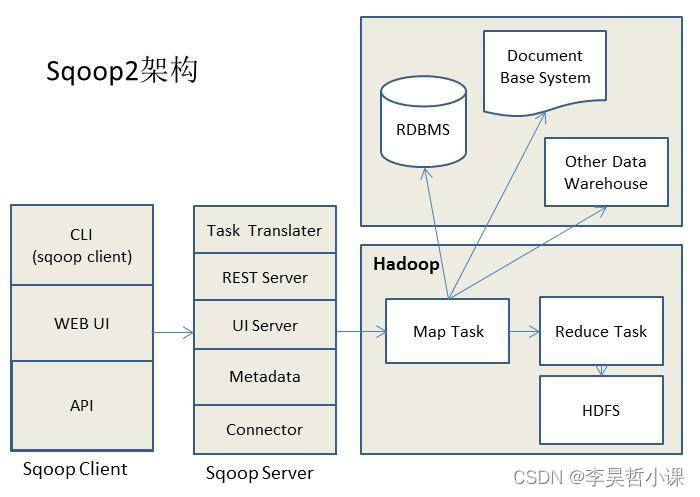
动态调整学习率,应用在训练过程中,通过降低学习率来让模型更好地收敛。以PyTorch框架为例
import torch
import torch.optim as optim
from torchvision import datasets, transforms# 数据加载
train_dataset = datasets.MNIST(root=‘./data’, train=True, transform=transforms.ToTensor())train_loader = torch.utils.data.DataLoader(dataset=train_dataset, batch_size=batch_size, shuffle=True)# 定义模型
model = torch.nn.Sequential(torch.nn.Linear(784, 1000),torch.nn.ReLU(),torch.nn.Linear(1000, 10),torch.nn.Softmax(dim=1),
)
optimizer = torch.optim.SGD(model.parameters(), lr=0.001)
scheduler = torch.optim.lr_scheduler.StepLR(optimizer, step_size=30, gamma=0.1)# 训练
for epoch in range(epochs):for batch_idx, (data, target) in enumerate(train_loader):data = data.view(-1, 2828)optimizer.zero_grad()output = model(data)loss = torch.nn.functional.cross_entropy(output, target)loss.backward()optimizer.step()# 调整学习率scheduler.step()
2. 批量归一化(Batch Normalization):
在每一层之间添加一个 batch normalization 层,将输入进行标准化(归一化)处理,有助于加速训练速度。
import torch# 定义模型并添加批量归一化层,这里以两层线性层为例
model = torch.nn.Sequential(torch.nn.Linear(784, 1000),torch.nn.BatchNorm1d(1000),torch.nn.ReLU(),torch.nn.Linear(1000, 10),torch.nn.Softmax(dim=1),
)3. 权重正则化:
常见的有 L1 和 L2 正则化,帮助限制模型参数的范数(和 LASSO/Ridge 最小二乘回归类似)。可以有效限制模型复杂度,以减小过拟合的风险。
import torch.optim as optim
from torch.utils.data import Dataset, DataLoader# 定义模型
model = torch.nn.Sequential(torch.nn.Linear(784, 1000),torch.nn.ReLU(),torch.nn.Linear(1000, 10),torch.nn.Softmax(dim=1),
)# 模型的参数
parameters = model.parameters()# 设置优化器并添加L2正则化
optimizer = optim.SGD(parameters, lr=0.001, weight_decay=1e-5)
4. 梯度剪裁:
在训练过程中,梯度可能会变得很大,这可能导致梯度爆炸的问题。梯度剪裁可以避免梯度过大。
import torch
import torch.optim as optim
from torch.utils.data import Dataset, DataLoader
from torchvision import datasets, transformstrain_dataset = datasets.MNIST(root=‘./data’, train=True, transform=transforms.ToTensor())train_loader = torch.utils.data.DataLoader(dataset=train_dataset, batch_size=batch_size, shuffle=True)model = torch.nn.Sequential(torch.nn.Linear(784, 1000),torch.nn.ReLU(),torch.nn.Linear(1000, 10),torch.nn.Softmax(dim=1),
)
optimizer = optim.SGD(model.parameters(), lr=0.001)# 训练循环
for epoch in range(epochs):for batch_idx, (data, target) in enumerate(train_loader):data = data.view(-1, 2828)optimizer.zero_grad()output = model(data)loss = torch.nn.functional.cross_entropy(output, target)loss.backward()# 梯度剪裁torch.nn.utils.clip_grad_norm_(model.parameters(), max_norm=1)optimizer.step()我举了以上神经网络训练过程中一些运用技巧,可以应用在模型训练过程中提高训练效果。更多内容希望大家持续关注。