Sqoop
Sqoop 架构解析
概述
Sqoop是Hadoop和关系数据库服务器之间传送数据的一种工具。它是用来从关系数据库如:MySQL,Oracle到Hadoop的HDFS,并从Hadoop的文件系统导出数据到关系数据库。
传统的应用管理系统,也就是与关系型数据库的使用RDBMS应用程序的交互,是产生大数据的来源之一。这样大的数据,由关系数据库生成的,存储在关系数据库结构关系数据库服务器。
当大数据存储器和分析器,如MapReduce, Hive, HBase, Cassandra, Pig等,Hadoop的生态系统等应运而生图片,它们需要一个工具来用的导入和导出的大数据驻留在其中的关系型数据库服务器进行交互。在这里,Sqoop占据着Hadoop生态系统提供关系数据库服务器和Hadoop HDFS之间的可行的互动。
Sqoop:“SQL 到 Hadoop 和 Hadoop 到SQL”
Sqoop(发音:skup)是一款开源的工具,主要用于在Hadoop(Hive)与传统的数据库(mysql、postgresql…)间进行数据的传递,可以将一个关系型数据库(例如 : MySQL ,Oracle ,Postgres等)中的数据导进到Hadoop的HDFS中,也可以将HDFS的数据导进到关系型数据库中。
下图描述了Sqoop的工作流程。
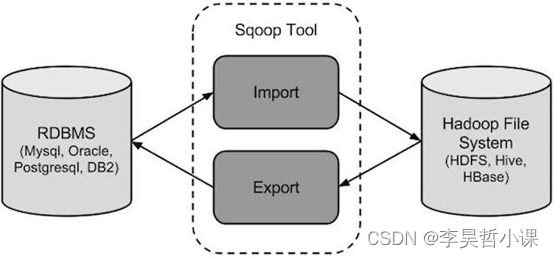
Sqoop导入
导入工具从RDBMS到HDFS导入单个表。表中的每一行被视为HDFS的记录。所有记录被存储在文本文件的文本数据或者在Avro和序列文件的二进制数据。
Sqoop导出
导出工具从HDFS导出一组文件到一个RDBMS。作为输入到Sqoop文件包含记录,这被称为在表中的行。那些被读取并解析成一组记录和分隔使用用户指定的分隔符。
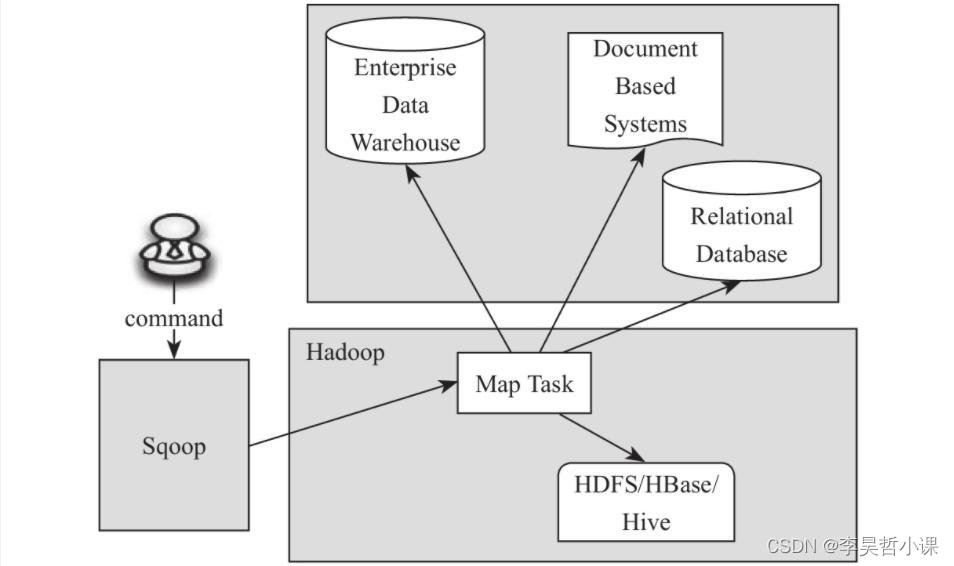
sqoop1与sqoop2对比
两代之间是两个完全不同的版本,不兼容
sqoop1:1.4.x
sqoop2:1.99.x
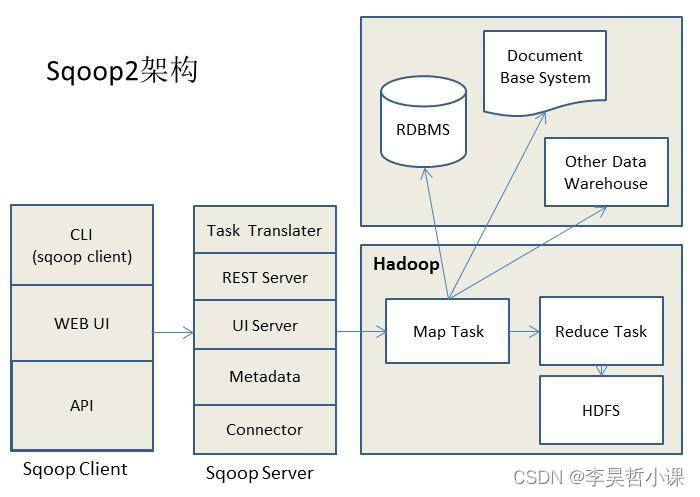
sqoop2比sqoop1的改进
(1) 引入sqoop server,集中化管理connector等
(2) 多种访问方式:CLI,Web UI,REST API
(3) 引入基于角色 的安全机制

Sqoop1
Sqoop2
Sqoop1简单教程
wget http://archive.apache.org/dist/sqoop/1.4.7/sqoop-1.4.7.bin__hadoop-2.6.0.tar.gz
tar -zxvf sqoop-1.4.7.bin__hadoop-2.6.0.tar.gz
mv sqoop-1.4.7.bin__hadoop-2.6.0 sqoop-1
vim /etc/profile
export HCAT_HOME=/opt/soft/hive3/hcatalog
export SQOOP_HOME=/opt/soft/sqoop-1export PATH=$PATH:$HCAT_HOME/bin:$SQOOP_HOME/bin
cd sqoop-1/conf/
cp sqoop-env-template.sh sqoop-env.sh
vim sqoop-env.sh
export HADOOP_COMMON_HOME=/opt/soft/hadoop3
export HADOOP_MAPRED_HOME=/opt/soft/hadoop3
export HIVE_HOME=/opt/soft/hive3
export ZOOKEEPER_HOME=/opt/soft/zookeeper
export ZOOCFGDIR=/opt/soft/zookeeper/conf
# 上传
commons-lang-2.6.jar
hive-common-3.1.3.jar
mysql-connector-j-8.0.33.jar
protobuf-java-3.22.2.jar
# 到lib目录
使用Sqoop简单教程如下:
# 使用help 指令: sqoop help
# 查看指定MySQL8数据库涉及的库
sqoop list-databases --username root --password 'Lihaozhe!!@@1122' --connect jdbc:mysql://spark03:3306?characterEncoding=UTF-8
# 查看指定MySQL8数据库涉及的表
sqoop list-tables --username root --password 'Lihaozhe!!@@1122' --connect jdbc:mysql://spark03:3306/hive?characterEncoding=UTF-8
# MySQL 8 指定数据库中的表导入Hive中
sqoop import --connect jdbc:mysql://spark03:3306/quiz?characterEncoding=UTF-8 \
--username root --password 'Lihaozhe!!@@1122' --table region \
-m 1 \
--hive-import --create-hive-table --hive-table region# MySQL 8 指定数据库中的表导入Hive指定数据库中
sqoop import --connect jdbc:mysql://spark03:3306/quiz?characterEncoding=UTF-8 \
--username root --password 'Lihaozhe!!@@1122' --table region \
-m 1 \
--hive-import --create-hive-table --hive-table lihaozhe.region# MySQL 8 指定数据库中的表导入Hive指定数据库中
sqoop import --connect jdbc:mysql://spark03:3306/quiz?characterEncoding=UTF-8 \
--username root --password 'Lihaozhe!!@@1122' --table region \
-m 1 \
--hive-database lihaozhe \
--hive-import --create-hive-table --hive-table region \
--fields-terminated-by ','# Hive 指定数据库中的表导出 MySQL 8指定数据库中
sqoop export \
-Dsqoop.export.records.per.statement=10 \
-Dmapreduce.job.max.split.locations=2000 \
--connect jdbc:mysql:///quiz?characterEncoding=UTF-8 \
--username root \
--password 'Lihaozhe!!@@1122' \
--table person \
--columns id_card,real_name,mobile \
--update-mode allowinsert \
--batch \
--hcatalog-database lihaozhe \
--hcatalog-table partition_2 \
--hcatalog-partition-keys province_code \
--hcatalog-partition-values 22 \
--m 1 sqoop export \
-Dsqoop.export.records.per.statement=10 \
--connect jdbc:mysql:///quiz?characterEncoding=UTF-8 \
--username root \
--password 'Lihaozhe!!@@1122' \
--table category \
--update-mode allowinsert \
--batch \
--hcatalog-database lihaozhe \
--hcatalog-table category \
--m 1
导入:sqoop import --connect jdbc:mysql://ip:3306/databasename #指定JDBC的URL 其中database指的是(Mysql或者Oracle)中的数据库名--table tablename #要读取数据库database中的表名 --username root #用户名 --password 123456 #密码 --target-dir /path #指的是HDFS中导入表的存放目录(注意:是目录)--fields-terminated-by '\t' #设定导入数据后每个字段的分隔符,默认;分隔--lines-terminated-by '\n' #设定导入数据后每行的分隔符--m 1 #并发的map数量1,如果不设置默认启动4个map task执行数据导入,则需要指定一个列来作为划分map task任务的依据-- where ’查询条件‘ #导入查询出来的内容,表的子集--incremental append #增量导入--check-column:column_id #指定增量导入时的参考列--last-value:num #上一次导入column_id的最后一个值--null-string ‘’ #导入的字段为空时,用指定的字符进行替换以上导入到hdfs中--hive-import #导入到hive--hive-overwrite #可以多次写入--hive-database databasename #创建数据库,如果数据库不存在的必须写,默认存放在default中--create-hive-table #sqoop默认自动创建hive表--delete-target-dir #删除中间结果数据目录--hive-table tablename #创建表名4. 导入所有的表放到hdfs中:sqoop import-all-tables --connect jdbc:mysql://ip:3306/库名 --username 用户名 --password 密码 --target-dir 导入存放的目录5. 导出(目标表必须在mysql数据库中已经建好,数据存放在hdfs中):sqoop export--connect jdbs:mysql://ip:3600/库名 #指定JDBC的URL 其中database指的是(Mysql或者Oracle)中的数据库名--username用户名 #数据库的用户名--password密码 #数据库的密码--table表名 #需要导入到数据库中的表名--export-dir导入数据的名称 #hdfs上的数据文件--fields-terminated-by ‘\t’ #HDFS中被导出的文件字段之间的分隔符--lines-terminated-by '\n' #设定导入数据后每行的分隔符--m 1 #并发的map数量1,如果不设置默认启动4个map task执行数据导入,则需要指定一个列来作为划分map task任务的依据--incremental append #增量导入--check-column:column_id #指定增量导入时的参考列--last-value:num #上一次导入column_id的最后一个值--null-string ‘’ #导出的字段为空时,用指定的字符进行替换6. 创建和维护sqoop作业:sqoop作业创建并保存导入和导出命令。A.创建作业:sqoop job --create作业名 -- import --connect jdbc:mysql://ip:3306/数据库 --username 用户名 --table 表名 --password 密码 --m 1 --target-dir 存放目录注意加粗的地方是有空格的B. 验证作业(显示已经保存的作业):sqoop job --listC. 显示作业详细信息:sqoop job --show作业名称D.删除作业:sqoop job --delete作业名E. 执行作业:sqoop job --exec作业7. eval:它允许用户针对各自的数据库服务器执行用户定义的查询,并在控制台中预览结果,可以使用期望导入结果数据。A.选择查询:sqoop eval -connect jdbc:mysql://ip:3306/数据库 --username 用户名 --password 密码 --query ”select * from emp limit 1“
- FLume
- Gobblin
- DataX
sqoop import \
--connect jdbc:mysql:///quiz?characterEncoding=UTF-8 \
--username root \
--password 'Lihaozhe!!@@1122' \
--table region \
--delete-target-dir \
--input-fields-terminated-by ',' \
--input-lines-terminated-by '\n' \
--m 1 \
--target-dir /sqoopresult
将hive计算结果保存到hdfs上
insert overwrite directory '/root/sort-result' row format delimited fields terminated by ','lines terminated by '\n'stored as textfileselect t2.category_id,t2.sku_id from (select sku.category_id,t1.sku_id,rank() over (partition by sku.category_id order by t1.total_sku_num desc ) rankingfrom(select sku_id,sum(sku_num) as total_sku_num from order_detail group by sku_id) t1left join sku on t1.sku_id = sku.sku_id) t2 where t2.ranking < 4;
insert overwrite directory '/root/sort-result' row format delimited fields terminated by ','lines terminated by '\n'stored as textfileselect id_card,real_name,mobile from partition_2;
将hdfs数据导出到MySQL数据表中
sqoop export \
--connect jdbc:mysql:///quiz?characterEncoding=UTF-8 \
--username root \
--password 'Lihaozhe!!@@1122' \
--table result \
--m 1 \
--export-dir /root/sort-result/
sqoop export \
--connect jdbc:mysql:///quiz?characterEncoding=UTF-8 \
--username root \
--password 'Lihaozhe!!@@1122' \
--table person \
--m 1 \
--export-dir /root/sort-result







