原标题:语音识别错误太多?高科技巨头们偏偏“不信邪”
撰文:Jing Cao、Dina Bass
要让我们能够自然地与智能设备进行对话,语音识别技术还必须大幅改进
有一位用户在亚马逊的网站上写道:“我对她又爱又恨”

亚马逊公司(Amazon)的Echo让每个家庭都拥有一个人工智能助手的承诺不再空洞。拥有这款语音激活式设备(因为是女性声音,被俗称为Alexa)的用户很容易为“她”的魅力所折服:Alexa能够打优步(Uber)专车、订购比萨饼、检查10年级孩子的数学作业,不一而足。亚马逊公司称,每天有超过5000人对Alexa示爱。
与此同时,Alexa的拥趸们也都知道的一点是:你需要极为缓慢清晰地说出自己的指令,否则她的答复很可能是“抱歉,我无法回答这个问题。”有一位用户在亚马逊的网站上写道:“我对她又爱又恨。”但这位用户仍然给了Alexa五星好评。“你很快就会学会以她能够理解的方式向她说话,就像是与一个让人无可奈何的懵懂小孩对话一样。”
过去几年里,语音识别技术取得了长足进步。但这些进步仍不足以让这项技术在人类的日常生活中普及开来,进而开启人机互动的新时代,让我们与汽车、洗衣机、电视机等各类设备展开语音沟通。尽管语音识别技术取得了种种进步,但多数人仍习惯于滑动、轻敲、点击等手势操作。在可预见的未来,这种现状恐怕难以改变。
拦路虎
那么拦路虎究竟是什么呢?首先,在一定程度上,支撑语音识别技术的人工智能仍有改进空间。此外,数据的严重匮乏也是一大问题,具体而言就是人类语音音频数据的匮乏。人们通常会在程序往往无法辨识的嘈杂环境中以不同语言、不同口音和不同方言说话,而在这方面的数据积累还远远不够。
因此,亚马逊、苹果公司(Apple)、微软公司(Microsoft)和中国的百度都已经开始在世界范围内广泛收集海量的人类语音数据。微软在全球许多城市设立了模拟公寓,以录制志愿者在家居环境中的对话内容。亚马逊每小时都会将Alexa收到的海量语音询问记录上传到一个庞大的数据库中。百度也在中国各地收集方言数据。然后它们会利用这些数据教电脑如何解析、理解及响应不同的语音指令和语音询问。

语音助理对比
真正的挑战在于如何设法获取现实世界中自然状态下的真实对话记录。百度旗下位于加利福尼亚州森尼韦尔市的人工智能实验室负责人亚当•科茨(Adam Coates)称,即使95%的精确度也不够。
“我们的目标是将错误率降低到1%。”他说,“只有达到那样的水平,人们才会真正相信机器能够理解我们的话。那将改变一切。”
不久以前,语音识别技术还非常原始。2006年,在面向满满一礼堂的分析师和投资者进行的演示中,微软在Windows上运行的早期版本语音识别技术甚至将“妈妈”(Mom)听成了“阿姨”(Aunt)。而5年前苹果公司的Siri首次亮相时,这款个人助理的出错也备受嘲讽,因为它经常给出不正确的答案或是听不清问题。在被问及吉莉恩•安德森(Gillian Anderson)是不是英国人时,Siri竟然给出了一份英国餐馆的列表。微软现在表示,该公司的语音引擎准确率已经堪比甚至超越专业速录员。Siri赢得了人们的勉强认可,Alexa更是让我们窥见了未来的诱人前景。
神经网络技术
这种进步在很大程度上归功于神经网络技术(一种大体基于人脑式架构的人工智能)的发展。神经网络无需明确的程序指令便可自学各种内容,但通常需要具有丰富广度而多元性的数据支撑。语音识别引擎处理的数据越多,就越善于理解不同的语音,也就更接近在众多语言和情景中实现自然对话的最终目标。
因此,各大科技巨头在全球各地争相采集海量语音数据。“我们系统获得的数据越多,表现就越好。”百度首席科学家吴恩达(Andrew Ng)说,“也正因如此,语音识别是一项资本密集型业务。没有多少组织拥有这么多的数据。”
收集数据
高科技行业从上世纪90年代开始重视语音识别技术,当时微软等公司依靠的都是来自Linguistics Data Consortium等研究机构提供的公共数据。总部位于宾夕法尼亚大学(University of Pennsylvania)的Linguistics Data Consortium是一家语音和文本数据库机构,在美国政府的支持下于1992年成立。后来,科技公司开始自行收集语音数据,其中一些是志愿者上门朗读各种内容的录音。如今,随着语音控制软件的普及度逐步提高,科技公司也通过自己的产品和服务收集大量数据。

当你让自己的手机搜索信息、播放歌曲或导航路径时,你的声音有可能正被某家公司录制下来。(苹果、谷歌、微软和亚马逊均强调,它们会将用户数据进行匿名化处理,以保护客户隐私。)当你向Alexa询问天气和最近的橄榄球赛比分时,智能设备便会利用你说话的内容改进其理解自然语言的能力(尽管在你呼唤Alexa的名字之前,“她”不会倾听你的对话。)“从设计角度看,你使用得越多,Alexa就会变得越聪明。”Alexa资深首席科学家尼科•斯特罗姆(Nikko Strom)说。
其中的一项关键挑战是让语音识别技术熟悉不同的语言、口音和方言。也许这一点在中国最为重要。为了收集中国各地的方言数据,百度在2016年春节期间启动了一项营销计划,推出方言保护计划。该公司向用户承诺,如果他们为该计划做出贡献,今后便可使用自己的方言与百度展开互动。短短两周内,该公司就录制了超过1000小时的方言语音数据。很多人完全免费提供这些数据,因为他们都对自己的方言感到自豪。该计划让一位四川中学教师激动万分——他让全班同学用四川话录制了1000多首古诗。
另一项挑战是让语音识别技术在嘈杂的环境(比如酒吧和体育场等喧闹的环境)中识别语音指令。微软也在Xbox上预装了一款名为Voice Studio的应用,专门收集人们在玩游戏或看电影时的对话信息。为了吸引用户贡献自己在玩游戏过程中的对话内容,该公司为参与用户提供了各种各样的奖励,包括点卡和游戏角色的数字装扮。该项目在巴西大获成功,微软在当地的分公司还在Xbox主页上着重推广了这款应用。他们随后利用这些数据开发了巴西葡萄牙语版的Cortana语音助手,并于2016年早些时候发布。
科技公司还在为特定的场景设计语音识别系统。例如,微软一直在测试一项机场语音识别技术,可以在不受持续的机场航班广播干扰的情况下回答旅行者的问题。该公司的语音识别技术还被用于麦当劳(McDonald)汽车穿梭餐厅的自动点餐系统。这套系统可以忽略嘈杂的汽车音响、孩子们的尖叫声和各种各样的口头感叹词,成功从中提取出复杂的指令,甚至连调味品也不会错过。亚马逊也正在汽车上展开测试,希望Alexa能克服道路上的各种噪音,在车窗开着的情况下也表现良好。
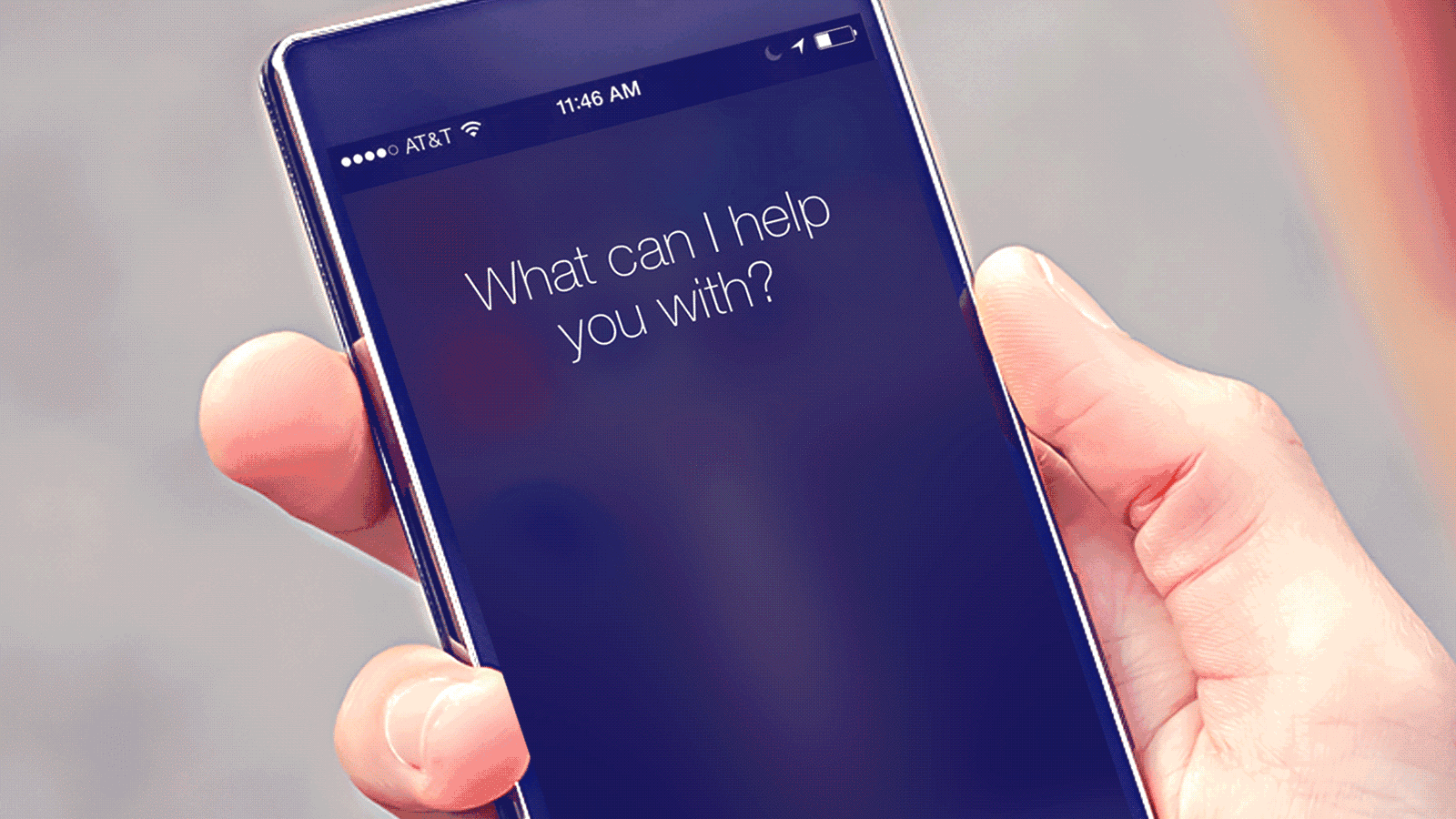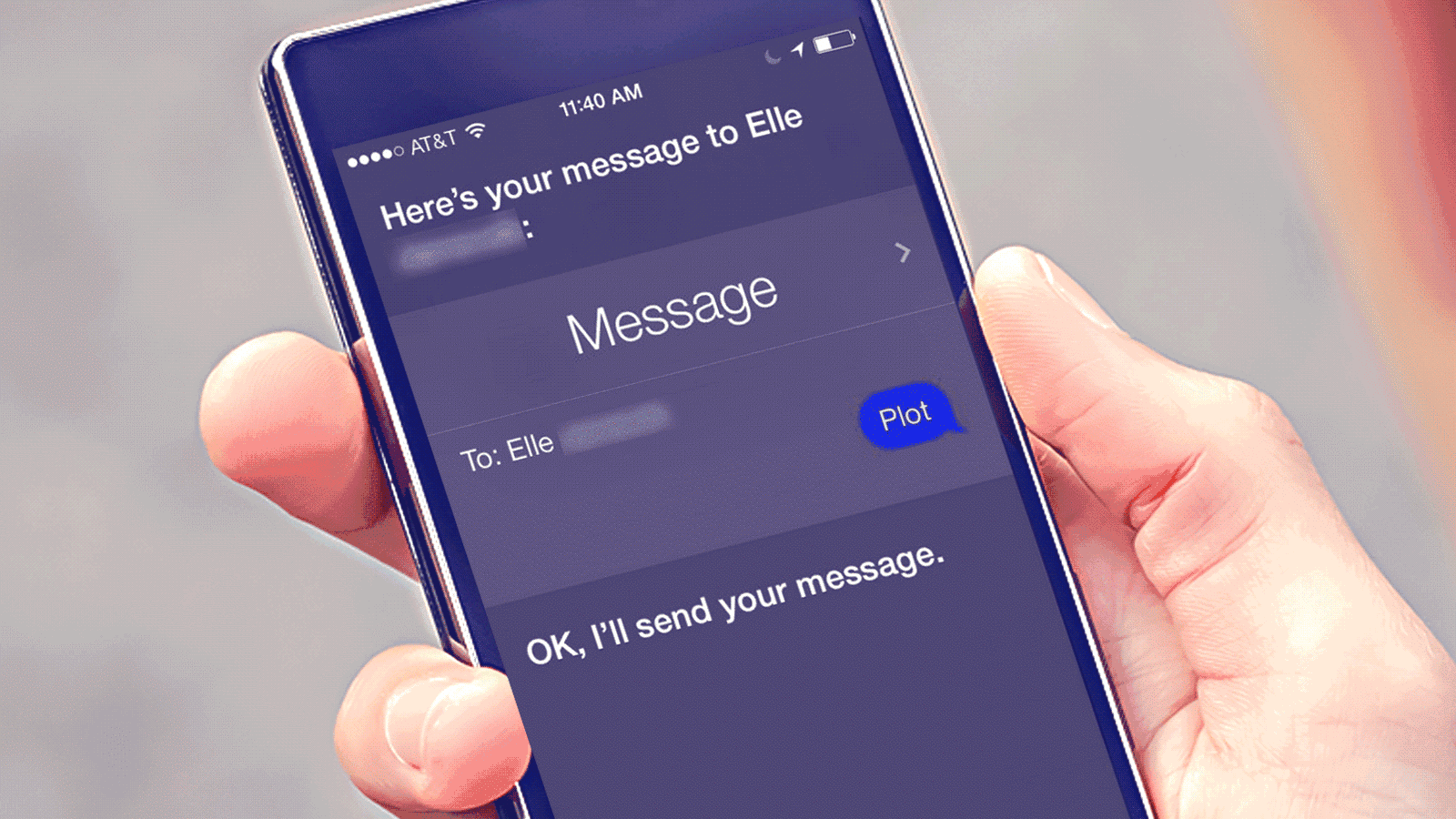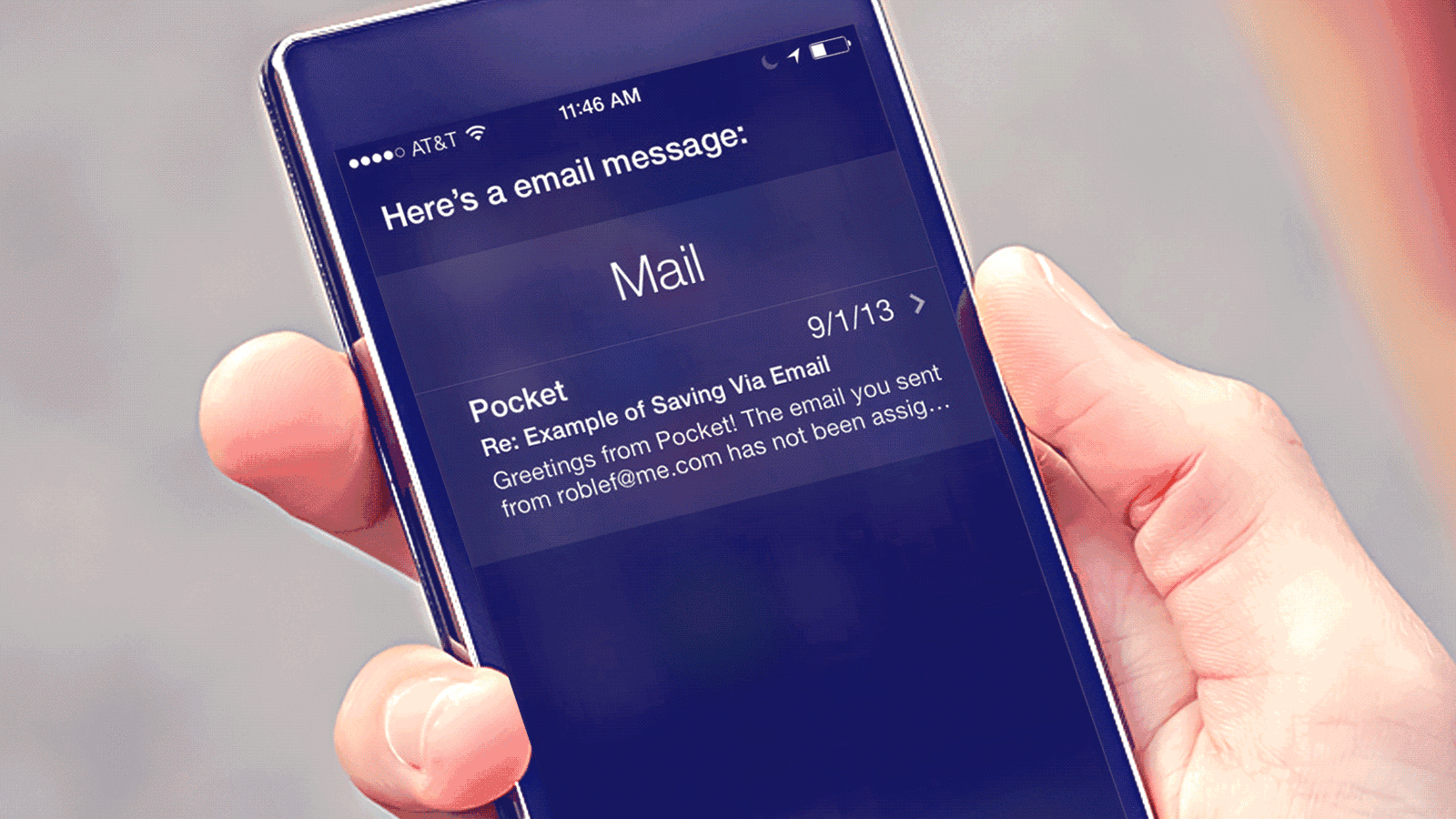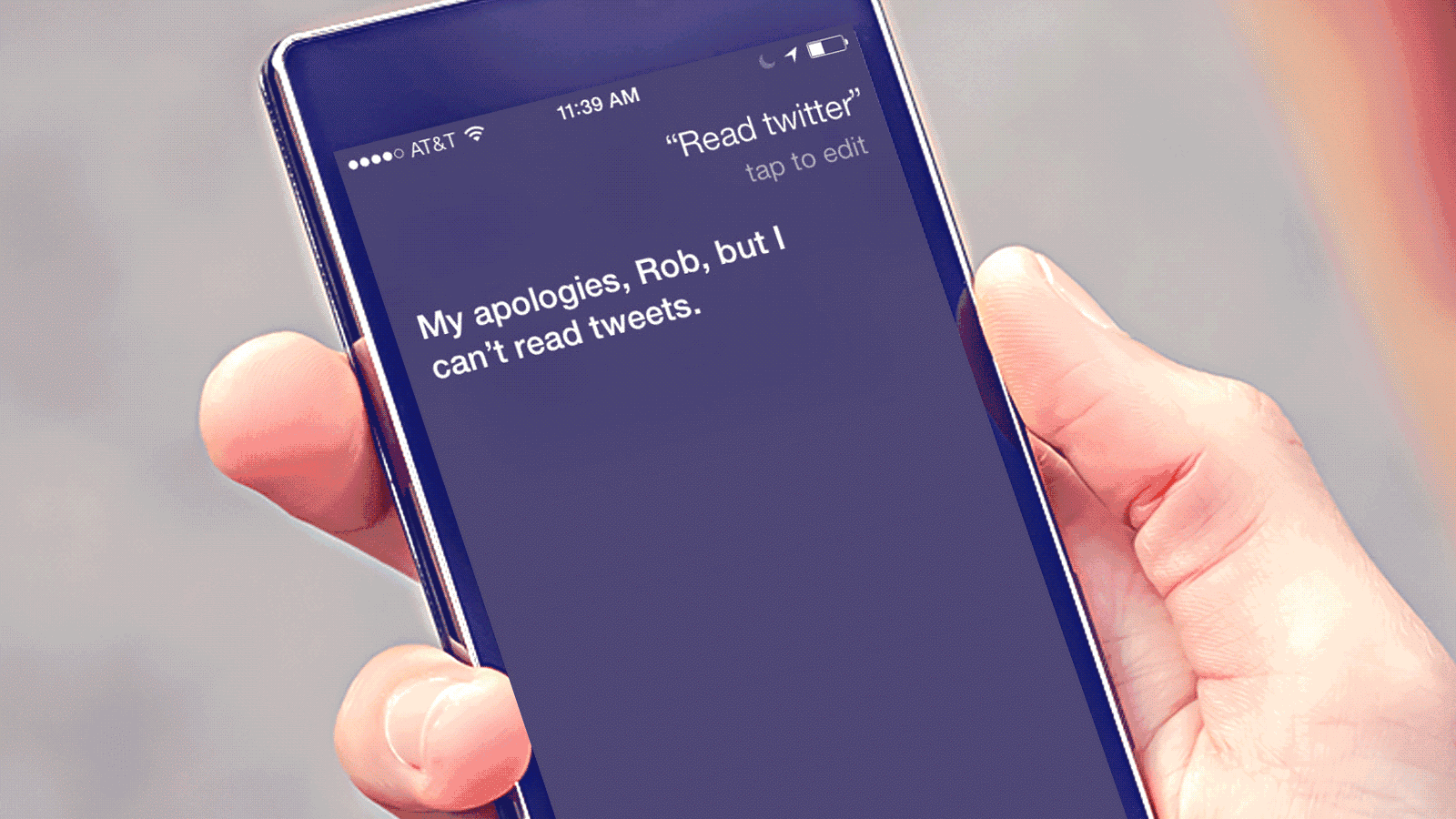
苹果Siri技术展示
尽管各大企业在全球争相收集数据,它们也都在想办法用较少的数据实现更好的语音识别效果。在微软从事了20多年语音识别技术开发工作的首席语音科学家黄学东称,正在麦当劳测试的语音识别技术比那些数据使用多很多的系统还要精确。“虽然数据使用量不是最大的,仍然可以实现技术突破。”
谷歌大体信奉“少即是多”的理念,它采用了一种零敲碎打的方法——利用难以辨别的声音单元来构建文字和短语。借助其语音识别系统,谷歌希望通过一项改变来解决各种不同的问题。谷歌拼接了数以万计的、时长通常仅有2至5秒的语音片段,以形成数据集。该公司研究员弗朗索瓦•博费(Françoise Beaufays)称,这一过程所需的计算资源更少,更容易测试和调整。百度也在开发更加高效的算法。根据其算法,语音识别系统只需学习一种语言便可简化另外12种语言的学习难度。百度首席科学家吴恩达称,在学习只有数万人而非数百万人掌握的小语种时,这种算法显得尤为重要——因为很难针对这样的语言收集到庞大规模的数据。
但被问及何时才能通过自然语言与数字助理顺畅交流时,就连吴恩达这样的科学家也显得有些愁眉苦脸。没有人知道确切答案。即便对这一领域最高水平的科学家而言,神经网络技术仍然有很多谜团有待解开。有很多工作只能通过不断试错来改进;没有人能确定某项技术调整可能产生什么样的后果。根据现有的技术和方法,摸索过程很可能要耗费数年时间。吴恩达、黄学冬和博费等科学家都表示,人们永远无法得知何时能实现突破,让Alexa和Siri像真正的人类那样对话。
编辑:李辰旭稼、刘馨蔚
翻译:徐子轩
◆◆◆ ◆◆
回复你感兴趣的关键词
立即获得关于TA的更多信息!
送书福利丨特朗普的世界观丨实体书店丨沃尔玛犯罪丨
粉丝造星丨许小年丨Hello World丨红色电话亭丨离奇谋杀案丨
......
韩国检方就“干政门”再发逮捕令
韩国最差的日子还在后头 |视频
尽在《商业周刊/中文版》App
长按识别二维码,速速下载吧!返回搜狐,查看更多
责任编辑: