文章目录
- 序言
- Encoder-Decoder
- 模型原理
- 应用范围
- 局限性
- 注意力机制(Attention)
- 模型原理
- 原理图示
- 自注意力 (self-attention)
- 原理介绍
- 图示讲解
- keras代码简单实现
- 多头attention(Multi-head attention)
- attention优缺点
- 位置嵌入(Position Embedding)
序言
机器翻译是指使用机器将一种语言自动翻译成另外一种语言的技术,传统的机器翻译一般是采取基于规则或者基于词组统计规律的方法。与传统方法不同的是,神经网络机器翻译(NMT)将源语言的句子向量化,再生成另一种语言的译文。
Encoder-Decoder
模型原理
Encoder-Decoder模型是神经网络进行机器翻译的基本方法,一般也称为Seq2Seq。联想到循环神经网络(RNN)和长短期记忆网络(LSTM),LSTM是RNN的改进版。RNN结构有1 VS N,N VS 1,N VS N结构。通常机器翻译遇到的大部分问题是序列是不等长的(源语言和目标语言的句子网网没有相同的长度)
Encoder-Decoder模型可以有效地建模输入序列和输出序列不等长的问题。具体来说,它会用一个Encoder将输入序列编码为一个上下文向量 c c c, 再使用Decoder对 c c c进行解码,将之变为输出序列。

为了方便阐述,在选取 Encoder 和 Decoder 时都假设其为 RNN。在 RNN 中,当前时刻隐藏状态 h t h_t ht 是由上一时刻的隐藏状态 h t − 1 h_{t−1} ht−1 和当前时刻的输入 x t x_t xt 决定的,如下所示:
h t = f ( h t − 1 , x t ) h_t=f(h_{t−1},x_t) ht=f(ht−1,xt)
在编码阶段,获得各个时刻的隐藏层状态后,通过把这些隐藏层的状态进行汇总,可以生成最后的语义编码向量 c c c ,如下所示,其中 q q q 表示某种非线性神经网络,此处表示多层 RNN 。
c = q ( h 1 , h 2 , ⋯ , h T x ) c=q(h_1,h_2,⋯,h_{T_x}) c=q(h1,h2,⋯,hTx)
在一些应用中,也可以直接将最后的隐藏层编码状态作为最终的语义编码 C,即满足:
c = q ( h 1 , h 2 , ⋯ , h T x ) = h T x c=q(h_1,h_2,⋯,h_{T_x})=h_{T_x} c=q(h1,h2,⋯,hTx)=hTx
在解码阶段,需要根据给定的语义向量 c c c和之前已经生成的输出序列 y 1 , y 2 , ⋯ , y t − 1 y_1,y_2,⋯,y_{t−1} y1,y2,⋯,yt−1 来预测下一个输出的单词 y t y_t yt,即满足如下公式:
y t = a r g m a x P ( y t ) = ∏ t = 1 T p ( y t ∣ y 1 , y 2 , ⋯ , y t − 1 , c ) y_t=argmax P(y_t)=∏_{t=1}^Tp(y_t|y_1,y_2,⋯,y_{t−1},c) yt=argmaxP(yt)=t=1∏Tp(yt∣y1,y2,⋯,yt−1,c)
由于我们此处使用的 Decoder 是 RNN ,所以当前状态的输出只与上一状态和当前的输入相关,所以可以简写成如下形式:
y t = g ( y t − 1 , s t − 1 , c ) y_t=g(y_{t−1},s_{t−1},c) yt=g(yt−1,st−1,c)
s t − 1 s_{t−1} st−1 表示 Decoder 中 RNN 神经元的隐藏层状态, y t − 1 y_{t−1} yt−1 表示前一时刻的输出, c c c代表的是编码后的语义向量,而 g ( ⋅ ) g(⋅) g(⋅) 则是一个非线性的多层神经网络,可以输出 y t y_t yt 的概率,一般情况下是由多层 RNN 和 softmax 层组成。
应用范围
由于这种Encoder-Decoder结构输入输出的序列是可以任意长度,所以应用范围广泛,例如:
- 机器翻译:机器翻译是最经典的应用,事实上这一结构是在机器翻译领域最先提出的
- 文本摘要:输入是一段文本序列,输出是这段文本序列的摘要序列
- 阅读理解:将输入的文章和问题分别编码,再对其进行解码得到问题的答案
- 语音识别:输入是语音信号序列,输出是文字序列
局限性
Encoder-Decoder 框架虽然应用广泛,但是其存在的局限性也比较大。其最大的局限性就是 Encoder 和 Decoder 之间只通过一个固定长度的语义向量 c c c 来唯一联系。也就是说,Encoder 必须要将输入的整个序列的信息都压缩进一个固定长度的向量中,存在两个弊端:一是语义向量 c c c 可能无法完全表示整个序列的信息;二是先输入到网络的内容携带的信息会被后输入的信息覆盖掉,输入的序列越长,该现象就越严重。这两个弊端使得 Decoder 在解码时一开始就无法获得输入序列最够多的信息,因此导致解码的精确度不够准确。
注意力机制(Attention)
模型原理
Attention机制的本质来自于人类视觉注意力机制。人们在看东西的时候一般不会从到头看到尾全部都看,往往只会根据需求观察注意特定的一部分。
简单来说,就是一种权重参数的分配机制,目标是协助模型捕捉重要信息。具体一点就是,给定一组<key,value>,以及一个目标(查询)向量query,attention机制就是通过计算query与每一组key的相似性,得到每个key的权重系数,再通过对value加权求和,得到最终attention数值。

在上述的模型中,Encoder-Decoder 框架将输入 X X X 都编码转化为语义表示 c c c,这就导致翻译出来的序列的每一个字都是同权地考虑了输入中的所有的词。例如输入的英文句子是:Tom chase Jerry,目标的翻译结果是:汤姆追逐杰瑞。在未考虑注意力机制的模型当中,模型认为 汤姆 这个词的翻译受到 Tom,chase 和 Jerry 这三个词的同权重的影响。但是实际上显然不应该是这样处理的,汤姆 这个词应该受到输入的 Tom 这个词的影响最大,而其它输入的词的影响则应该是非常小的。显然,在未考虑注意力机制的 Encoder-Decoder 模型中,这种不同输入的重要程度并没有体现处理,一般称这样的模型为 分心模型。
而带有 Attention 机制的 Encoder-Decoder 模型则是要从序列中学习到每一个元素的重要程度,然后按重要程度将元素合并。因此,注意力机制可以看作是 Encoder 和 Decoder 之间的接口,它向 Decoder 提供来自每个 Encoder 隐藏状态的信息。通过该设置,模型能够选择性地关注输入序列的有用部分,从而学习它们之间的“对齐”(对齐是指将原文的片段与其对应的译文片段进行匹配)。这就表明,在 Encoder 将输入的序列元素进行编码时,得到的不在是一个固定的语义编码 c c c ,而是存在多个语义编码,且不同的语义编码由不同的序列元素以不同的权重参数组合而成。一个简单地体现 Attention 机制运行的示意图如下:

在 Attention 机制下,语义编码 c c c 就不在是输入序列 X X X 的直接编码了,而是各个元素按其重要程度加权求和得到的,即:
c i = ∑ j = 0 T x a i j f ( x j ) c_i=∑_{j=0}^{T_x}a_{ij}f(x_j) ci=j=0∑Txaijf(xj)
参数 i i i 表示时刻, j j j 表示序列中的第 j j j 个元素, T x T_x Tx 表示序列的长度, f ( ⋅ ) f(⋅) f(⋅) 表示对元素 x j x_j xj 的编码。 a i j a_{ij} aij 可以看作是一个概率,反映了元素 h j h_j hj 对 c i c_i ci 的重要性,可以使用 softmax 来表示:
a i j = e x p ( e i j ) ∑ k = 1 T x e x p ( e i k ) a_{ij}=\dfrac{exp(e_{ij})}{∑^{T_x}_{k=1}exp(e_{ik})} aij=∑k=1Txexp(eik)exp(eij)
这里 e i j e_{ij} eij 正是反映了待编码的元素和其它元素之间的匹配度,当匹配度越高时,说明该元素对其的影响越大,则 a i j a_{ij} aij 的值也就越大。
通常attention计算 e i j e_{ij} eij有如下几种实现方式:
-
多层感知机:
a ( q , k ) = w 2 T t a n h ( W 1 [ q ; k ] ) a(q,k) = w_2^Ttanh(W_1[q;k]) a(q,k)=w2Ttanh(W1[q;k])
该方法主要是将Q,K拼接,然后一起通过一个激活函数为 t a n h tanh tanh的全连接层,再跟权重矩阵做乘积,在数据量够大的情况下,该方法一般来说效果都不错。 -
Dot Product / scaled-dot Product:
a ( q , k ) = q T k a(q,k) = q^T k a(q,k)=qTk
该方法适用于query与key维度相同情景,通过q转置后与k点积。在权重值过大的情况下,可以将数据标准化,即scaled-dot Product -
Bilinear
a ( q , k ) = q T W k a(q,k) = q^T W k a(q,k)=qTWk
通过一个权重矩阵直接建立query与key的关系,权重矩阵可以随机初始化也可以使用预设的。 -
cosine相似度
s i m i l a r i t y ( q , k i ) = q ⋅ k i ∣ ∣ q ∣ ∣ ⋅ ∣ ∣ k i ∣ ∣ similarity(q,k_i) = \dfrac{q \cdot k_i}{||q|| \cdot||k_i||} similarity(q,ki)=∣∣q∣∣⋅∣∣ki∣∣q⋅ki
至此,关于注意力模型,只剩最后一个问题:这些权重 a i j a_{ij} aij是怎么来的?
事实上, a i j a_{ij} aij同样是模型自动学出来的,它实际和Decoder的第 i − 1 i-1 i−1阶段的隐状态、Encoder的第 j j j个阶段的隐状态有关。
原理图示
注意力机制可以看作是神经网络架构中的一层神经网络,注意力层的实现可以分为 6 个步骤。
Step 0:准备隐藏状态
首先准备第一个 Decoder 的隐藏层状态(红色)和所有可用的 Encoder 隐藏层状态(绿色)。在示例中,有 4 个 Encoder 隐藏状态和 1 个 Decoder 隐藏状态。

Step 1:得到每一个 Encoder 隐藏状态的得分
分值(score)由 score 函数来获得,最简单的方法是直接用 Decoder 隐藏状态和 Encoder 中的每一个隐藏状态进行点积。

Step 2:将所有得分送入 softmax 层
该部分实质上就是对得到的所有分值进行归一化,这样 softmax 之后得到的所有分数相加为 1。而且能够使得原本分值越高的隐藏状态,其对应的概率也越大,从而抑制那些无效或者噪音信息。

通过 softmax 层后,可以得到一组新的隐藏层状态分数,其计算方法即为 a i j = e x p ( e i j ) ∑ k = 1 T x e x p ( e i k ) a_{ij}=\dfrac{exp(e_{ij})}{∑^{T_x}_{k=1}exp(e_{ik})} aij=∑k=1Txexp(eik)exp(eij)注意,此处得到的分值应该是浮点数,但是由于无限接近于 0 和 1,所以做了近似。
Step 3:用每个 Encoder 的隐藏状态乘以 softmax 之后的得分
通过将每个编码器的隐藏状态与其softmax之后的分数(标量)相乘,我们得到 对齐向量 或标注向量。这正是对齐产生的机制。

加权求和之后可以得到新的一组与 Encoder 隐藏层状态对应的新向量,假设之后第二个隐藏状态的分值为 1 ,而其它的为0,所以得到的新向量也只有第二个向量有效。
Step 4:将所有对齐的向量进行累加
对对齐向量进行求和,生成 上下文向量 。上下文向量是前一步的对齐向量的聚合信息。

得到最终的编码后的向量来作为 Decoder 的输入。
Step 5:把上下文向量送到 Decoder 中
通过将上下文向量和 Decoder 的上一个隐藏状态一起送入当前的隐藏状态,从而得到解码后的输出。
最终得到完整的注意力层结构如下图所示:

自注意力 (self-attention)
原理介绍
自注意力可以提取句子自身词间依赖,比如常用短语、代词指代的事物等。或者说, 这层帮助编码器在对每个单词编码时关注输入句子的其他单词。
在self-attention中,每个单词有3个不同的向量,它们分别是Query向量( Q Q Q),Key向量( K K K)和Value向量( V V V),长度均是64。它们是通过3个不同的权值矩阵由嵌入向量 X X X乘以三个不同的权值矩阵 W Q W_Q WQ, W K W_K WK, W V W_V WV得到,其中三个矩阵的尺寸也是相同的。均是 512 ∗ 64 512 * 64 512∗64。(Transformer中使用的词嵌入的维度为 d m o d e l = 512 d_{model}=512 dmodel=512。)
slef: 自己和自己计算相似度函数,然后进一步进行关注.
计算整个过程可以分成7步:
- 输入单词转化成嵌入向量;
- 根据嵌入向量得到 q , k , v q,k,v q,k,v三个向量;
- 为每个向量计算自注意力得分,分数决定当我们在某个位置对单词进行编码时,要在输入句子的其他部分上投入多少注意力: s c o r e = q ⋅ k score = q \cdot k score=q⋅k;
- 为了梯度的稳定,对计算的分数进行 Scale,即除以 d k \sqrt {d_k} dk,原因是如果点乘结果过大,使得经过 softmax 之后的梯度很小,不利于反向传播
- 对score施以softmax激活函数,归一化;
- softmax乘Value值 v v v (每个单词的value),得到加权的每个输入向量的评分 v v v;
- 相加之后得到最终的输出结果 z z z : z = ∑ v z = \sum{v} z=∑v 。

图示讲解
Step 0: 准备输入
词向量化的3个向量

Step 1: 初始化权重
每个输入必须具有三个表示形式(请参见下图)。这些表示称为key(橙色),`query(红色)和value(紫色), 稍后我们将看到value的维度也就是输出的维度。

为了获得这些表示,将每个输入(绿色)乘以一组用于key的权重,另一组用于query的权重和一组value的权重。在我们的示例中,我们如下初始化三组权重。
Note:
在神经网络的设置中,这些权重通常是很小的数,使用适当的随机分布(如高斯,Xavie 和 Kaiming 分布)随机初始化。初始化在训练之前完成一次。
Step 2: 计算输入的注意力得分(attention scores)
为了获得注意力分数,我们首先在输入1的query(红色)与所有key(橙色)(包括其自身)之间取点积。

注意,在这里我们仅使用输入1的query。稍后,我们将对其他查询重复相同的步骤。区别于attention中decoder的隐藏层。
Step 3: 计算softmax

Step 4: 将attention scores乘以value,对加权后的value求和以得到输出

Step 5: 对输入2重复步骤

keras代码简单实现
class SelfAttention(nn.Module):def __init__(self, hidden_size, num_attention_heads, dropout_prob):"""假设 hidden_size = 128, num_attention_heads = 8, dropout_prob = 0.2即隐层维度为128,注意力头设置为8个"""super(SelfAttention, self).__init__()if hidden_size % num_attention_heads != 0: # 整除raise ValueError("The hidden size (%d) is not a multiple of the number of attention ""heads (%d)" % (hidden_size, num_attention_heads))# 参数定义self.num_attention_heads = num_attention_headsself.attention_head_size = int(hidden_size / num_attention_heads) # 16 每个注意力头的维度self.all_head_size = int(self.num_attention_heads * self.attention_head_size)# all_head_size = 128 即等于hidden_size, 一般自注意力输入输出前后维度不变# query, key, value 的线性变换(上述公式2)self.query = nn.Linear(hidden_size, self.all_head_size) # 128, 128self.key = nn.Linear(hidden_size, self.all_head_size)self.value = nn.Linear(hidden_size, self.all_head_size)# dropoutself.dropout = nn.Dropout(dropout_prob)def transpose_for_scores(self, x):# INPUT: x'shape = [bs, seqlen, hid_size] 假设hid_size=128new_x_shape = x.size()[:-1] + (self.num_attention_heads, self.attention_head_size) # [bs, seqlen, 8, 16]x = x.view(*new_x_shape) # return x.permute(0, 2, 1, 3) # [bs, 8, seqlen, 16]def forward(self, hidden_states, attention_mask):# eg: attention_mask = torch.LongTensor([[1, 1, 1], [1, 1, 0]]) shape=[bs, seqlen]attention_mask = attention_mask.unsqueeze(1).unsqueeze(2) # [bs, 1, 1, seqlen] 增加维度attention_mask = (1.0 - attention_mask) * -10000.0 # padding的token置为-10000,exp(-1w)=0# 线性变换mixed_query_layer = self.query(hidden_states) # [bs, seqlen, hid_size]mixed_key_layer = self.key(hidden_states) # [bs, seqlen, hid_size]mixed_value_layer = self.value(hidden_states) # [bs, seqlen, hid_size]query_layer = self.transpose_for_scores(mixed_query_layer) # [bs, 8, seqlen, 16]key_layer = self.transpose_for_scores(mixed_key_layer)value_layer = self.transpose_for_scores(mixed_value_layer) # [bs, 8, seqlen, 16]# Take the dot product between "query" and "key" to get the raw attention scores.# 计算query与title之间的点积注意力分数,还不是权重(个人认为权重应该是和为1的概率分布)attention_scores = torch.matmul(query_layer, key_layer.transpose(-1, -2))# [bs, 8, seqlen, 16]*[bs, 8, 16, seqlen] ==> [bs, 8, seqlen, seqlen]attention_scores = attention_scores / math.sqrt(self.attention_head_size) # [bs, 8, seqlen, seqlen]# 除以根号注意力头的数量,可看原论文公式,防止分数过大,过大会导致softmax之后非0即1attention_scores = attention_scores + attention_mask# 加上mask,将padding所在的表示直接-10000# 将注意力转化为概率分布,即注意力权重attention_probs = nn.Softmax(dim=-1)(attention_scores) # [bs, 8, seqlen, seqlen]# This is actually dropping out entire tokens to attend to, which might# seem a bit unusual, but is taken from the original Transformer paper.attention_probs = self.dropout(attention_probs)# 矩阵相乘,[bs, 8, seqlen, seqlen]*[bs, 8, seqlen, 16] = [bs, 8, seqlen, 16]context_layer = torch.matmul(attention_probs, value_layer) # [bs, 8, seqlen, 16]context_layer = context_layer.permute(0, 2, 1, 3).contiguous() # [bs, seqlen, 8, 16]new_context_layer_shape = context_layer.size()[:-2] + (self.all_head_size,) # [bs, seqlen, 128]context_layer = context_layer.view(*new_context_layer_shape)return context_layer # [bs, seqlen, 128] 得到输出
多头attention(Multi-head attention)
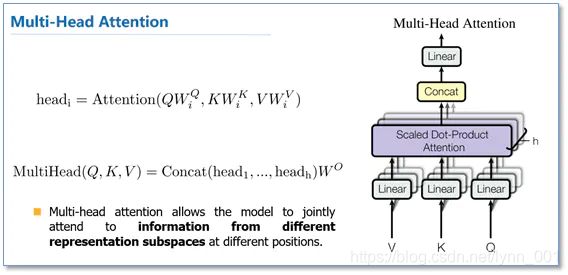
多头attention(Multi-head attention)结构如上图,Query,Key,Value首先进过一个线性变换,然后输入到放缩点积attention,注意这里要做h次,也就是所谓的多头,每一次算一个头,头之间参数不共享,每次Q,K,V进行线性变换的参数是不一样的。然后将h次的放缩点积attention结果进行拼接,再进行一次线性变换得到的值作为多头attention的结果。
可以看到,google提出来的多头attention的不同之处在于进行了h次计算而不仅仅算一次,论文中说到这样的好处是可以允许模型在不同的表示子空间里学习到相关的信息。
attention优缺点
优点
- 一步到位的全局联系捕捉
attention机制可以灵活的捕捉全局和局部的联系,而且是一步到位的。另一方面从attention函数就可以看出来,它先是进行序列的每一个元素与其他元素的对比,在这个过程中每一个元素间的距离都是一,因此它比时间序列RNNs的一步步递推得到长期依赖关系好的多,越长的序列RNNs捕捉长期依赖关系就越弱。 - 并行计算减少模型训练时间
Attention机制每一步计算不依赖于上一步的计算结果,因此可以和CNN一样并行处理。但是CNN也只是每次捕捉局部信息,通过层叠来获取全局的联系增强视野。 - 模型复杂度小,参数少
模型复杂度是与CNN和RNN同条件下相比较的。
缺点
缺点很明显,attention机制不是一个"distance-aware"的,它不能捕捉语序顺序(这里是语序哦,就是元素的顺序)。这在NLP中是比较糟糕的,自然语言的语序是包含太多的信息。如果确实了这方面的信息,结果往往会是打折扣的。说到底,attention机制就是一个精致的"词袋"模型。以就有了 position-embedding(位置向量)的概念。
位置嵌入(Position Embedding)
上述模型并不能学习序列的顺序。换句话说,如果将 K,V 按行打乱顺序(相当于句子中的词序打乱),那么 Attention 的结果还是一样的。学习不到顺序信息,那么效果将会大打折扣(比如机器翻译中,有可能只把每个词都翻译出来了,但是不能组织成合理的句子)。这就引出了位置向量(Position Embedding)。
将每个位置编号,然后每个编号对应一个向量,通过结合位置向量和词向量,就给每个词都引入了一定的位置信息,这样 Attention 就可以分辨出不同位置的词了,进而学习位置信息了。
Google直接给出了位置向量构造公式:
{ P E 2 i ( p ) = s i n ( p / 1000 0 2 i / d p o s ) P E 2 i + 1 ( p ) = c o s ( p / 1000 0 2 i / d p o s ) \left\{ \begin{aligned} PE_{2i}(p) =sin(p/10000^{2i/d_{pos}}) \\ PE_{2i+1}(p) = cos(p/10000^{2i/d_{pos}}) \end{aligned} \right. {PE2i(p)=sin(p/100002i/dpos)PE2i+1(p)=cos(p/100002i/dpos)
这里的意思是将 i d id id 为 p p p的位置映射为一个 d p o s d_{pos} dpos维的位置向量,这个向量的第 i i i个元素的数值就是 P E i ( p ) PE_i(p) PEi(p)。
位置向量是绝对位置信息,相对位置信息也很重要。Google 选择前述的位置向量公式的一个重要原因如下:由于我们有 s i n ( α + β ) = s i n α ⋅ c o s β + c o s α ⋅ s i n β sin(α+β)=sinα·cosβ+cosα·sinβ sin(α+β)=sinα⋅cosβ+cosα⋅sinβ以及 c o s ( α + β ) = c o s α ⋅ c o s β − s i n α ⋅ s i n β cos(α+β)=cosα·cosβ−sinα·sinβ cos(α+β)=cosα⋅cosβ−sinα⋅sinβ,这表明位置 p + k p+k p+k 的向量可以表示成位置 p 、 k p、k p、k 的向量的线性变换,这提供了表达相对位置信息的可能性。
结合位置向量和词向量有几个可选方案,可以把它们拼接起来作为一个新向量,也可以把位置向量定义为跟词向量一样大小,然后两者加起来。