前奏
es的chinese、english、standard等分词器对中文分词十分不友好,几乎都是逐字分词,对英文分词比较友好。
在kibana的dev tools中测试分词:
POST /_analyze
{"analyzer": "standard","text": "你太棒了golang"
}
- POST:请求方式
- /_analyze:请求路径,此处省略了
http://127.0.0.1:9200,由kibana自行补全 - 请求参数,json格式
- analyzer:分词器类型,默认为standard分词器
- text:将要分词的内容
{"tokens" : [{"token" : "你","start_offset" : 0,"end_offset" : 1,"type" : "<IDEOGRAPHIC>","position" : 0},{"token" : "太","start_offset" : 1,"end_offset" : 2,"type" : "<IDEOGRAPHIC>","position" : 1},{"token" : "棒","start_offset" : 2,"end_offset" : 3,"type" : "<IDEOGRAPHIC>","position" : 2},{"token" : "了","start_offset" : 3,"end_offset" : 4,"type" : "<IDEOGRAPHIC>","position" : 3},{"token" : "golang","start_offset" : 4,"end_offset" : 10,"type" : "<ALPHANUM>","position" : 4}]
}
ik分词器
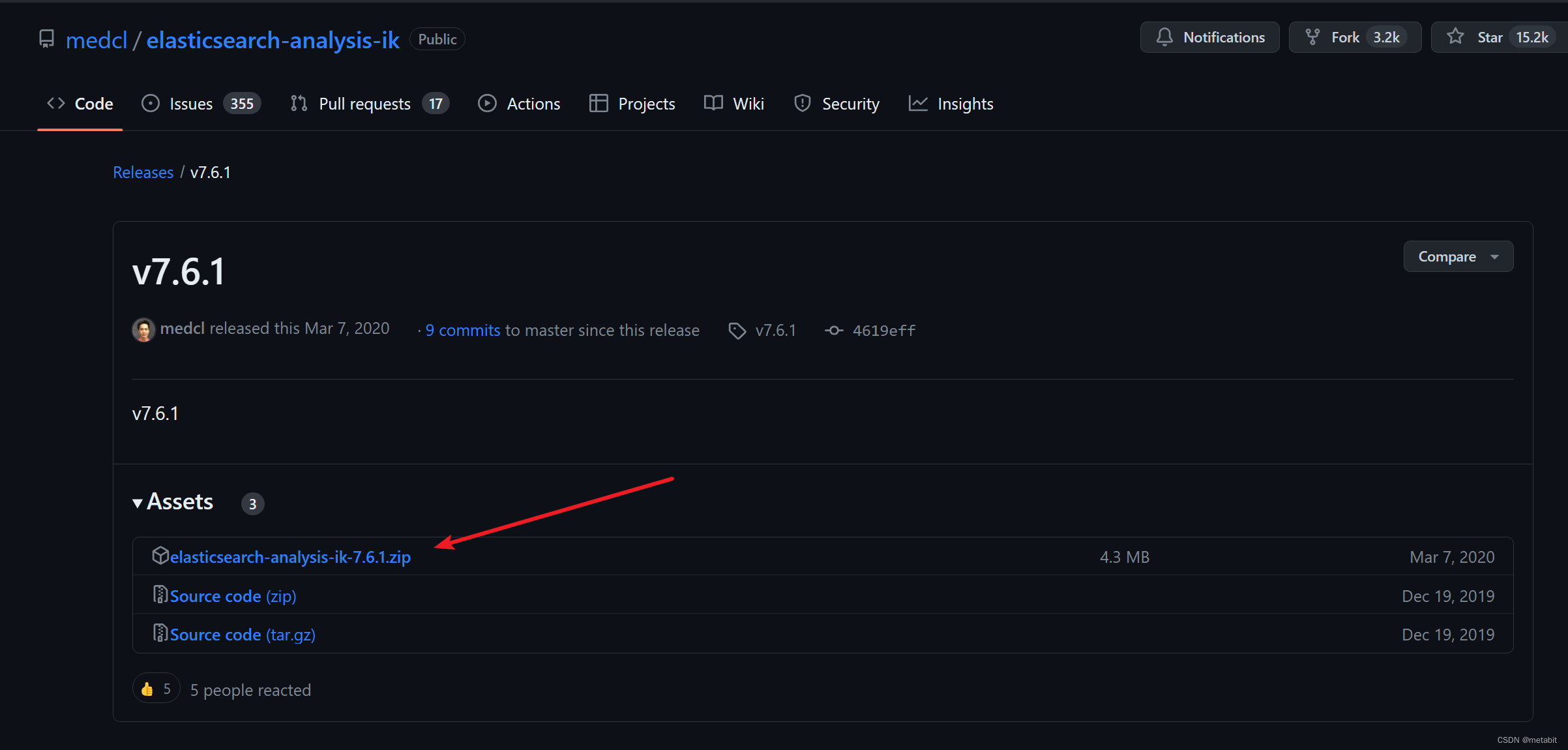
此处引入ik分词器,其下载地址为:https://github.com/medcl/elasticsearch-analysis-ik/releases/tag/v7.6.1
选择如下压缩包下载即可
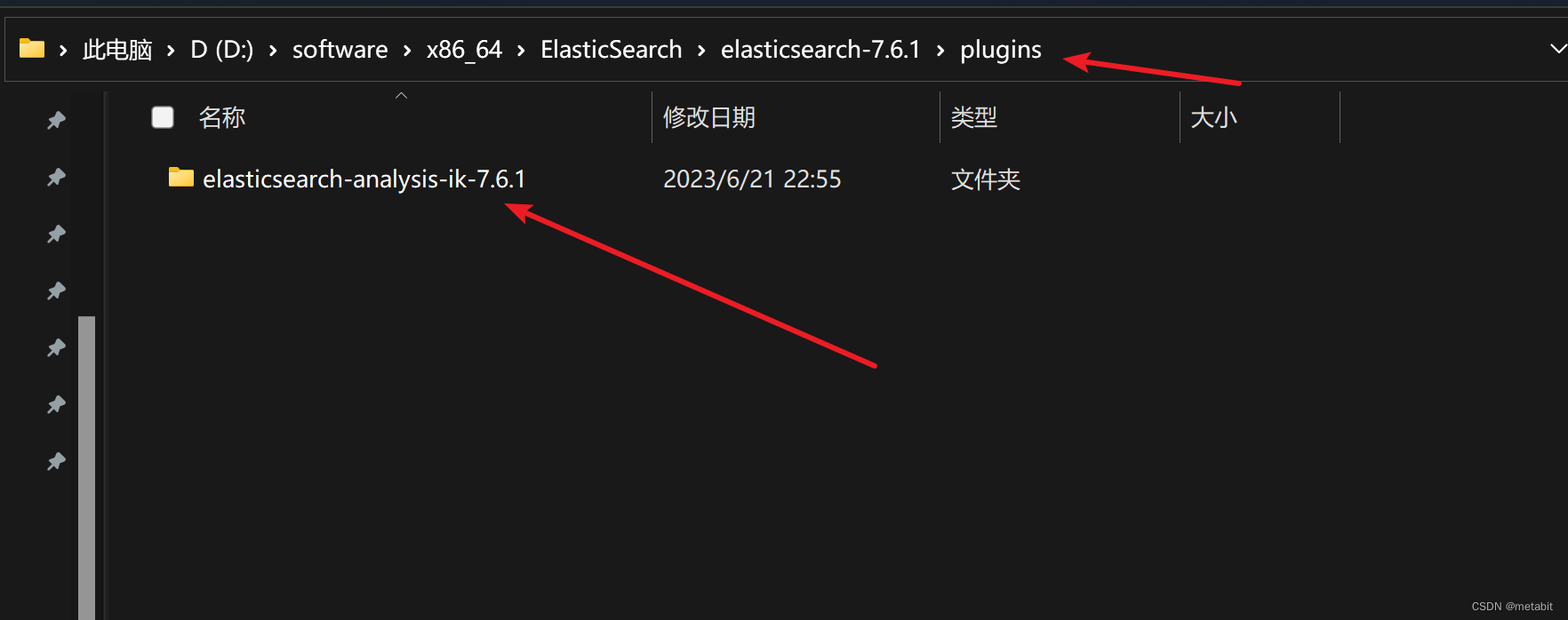
将该压缩包解压到ES安装目录的plugins文件夹
重启ES后,在Kibana中指定分词策略
ik分词器有两种模式
- ik_smart:最少切分,粒度始终,切分后占用内存少
- ik_max_word:最细切分,精细化切分,占用内存多
二者在选取时需要关注分词场景及内存规划
ik_smart切分效果:
POST /_analyze
{"analyzer": "ik_smart","text": "你太棒了golang"
}{"tokens" : [{"token" : "你","start_offset" : 0,"end_offset" : 1,"type" : "CN_CHAR","position" : 0},{"token" : "太棒了","start_offset" : 1,"end_offset" : 4,"type" : "CN_WORD","position" : 1},{"token" : "golang","start_offset" : 4,"end_offset" : 10,"type" : "ENGLISH","position" : 2}]
}
ik_max_word切分效果:
POST /_analyze
{"analyzer": "ik_max_word","text": "你太棒了golang"
}{"tokens" : [{"token" : "你","start_offset" : 0,"end_offset" : 1,"type" : "CN_CHAR","position" : 0},{"token" : "太棒了","start_offset" : 1,"end_offset" : 4,"type" : "CN_WORD","position" : 1},{"token" : "太棒","start_offset" : 1,"end_offset" : 3,"type" : "CN_WORD","position" : 2},{"token" : "了","start_offset" : 3,"end_offset" : 4,"type" : "CN_CHAR","position" : 3},{"token" : "golang","start_offset" : 4,"end_offset" : 10,"type" : "ENGLISH","position" : 4}]
}
ik分词器,拓展词库,停用词库
要拓展ik分词器的词库,只需要修改一个ik分词器目录中的config目录中的IKAnalyzer.cfg.xml文件
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE properties SYSTEM "http://java.sun.com/dtd/properties.dtd">
<properties><comment>IK Analyzer 扩展配置</comment><!--用户可以在这里配置自己的扩展字典 --><entry key="ext_dict"></entry><!--用户可以在这里配置自己的扩展停止词字典--><entry key="ext_stopwords"></entry><!--用户可以在这里配置远程扩展字典 --><!-- <entry key="remote_ext_dict">words_location</entry> --><!--用户可以在这里配置远程扩展停止词字典--><!-- <entry key="remote_ext_stopwords">words_location</entry> -->
</properties>
在标签内加入文件路径
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE properties SYSTEM "http://java.sun.com/dtd/properties.dtd">
<properties><comment>IK Analyzer 扩展配置</comment><!--用户可以在这里配置自己的扩展字典 --><entry key="ext_dict">ext.dic</entry><!--用户可以在这里配置自己的扩展停止词字典--><entry key="ext_stopwords">stopword.dic</entry><!--用户可以在这里配置远程扩展字典 --><!-- <entry key="remote_ext_dict">words_location</entry> --><!--用户可以在这里配置远程扩展停止词字典--><!-- <entry key="remote_ext_stopwords">words_location</entry> -->
</properties>
同时建立ext.dic文件及stopword.dic文件,将词汇按行写入文件中,重启es即可生效。
- ext.dic是扩展词列表
- stopword.dic是停用(禁用)词列表