科二挂了,六级过了,真是大喜大悲的一天啊,下午躺了一下午。
这次写的是用python来做微信账单分析,以我七月份的消费为例,进行分析。
最终达到的效果如下,为了避免泄露博主隐私,消费记录进行了打码

这里是用python进行分析,配合使用pyecahrts进行分析
微信账单是从微信钱包里导出来的,微信——>支付——>钱包——>账单,导出来的文件是csv格式,以下是部分的截图。
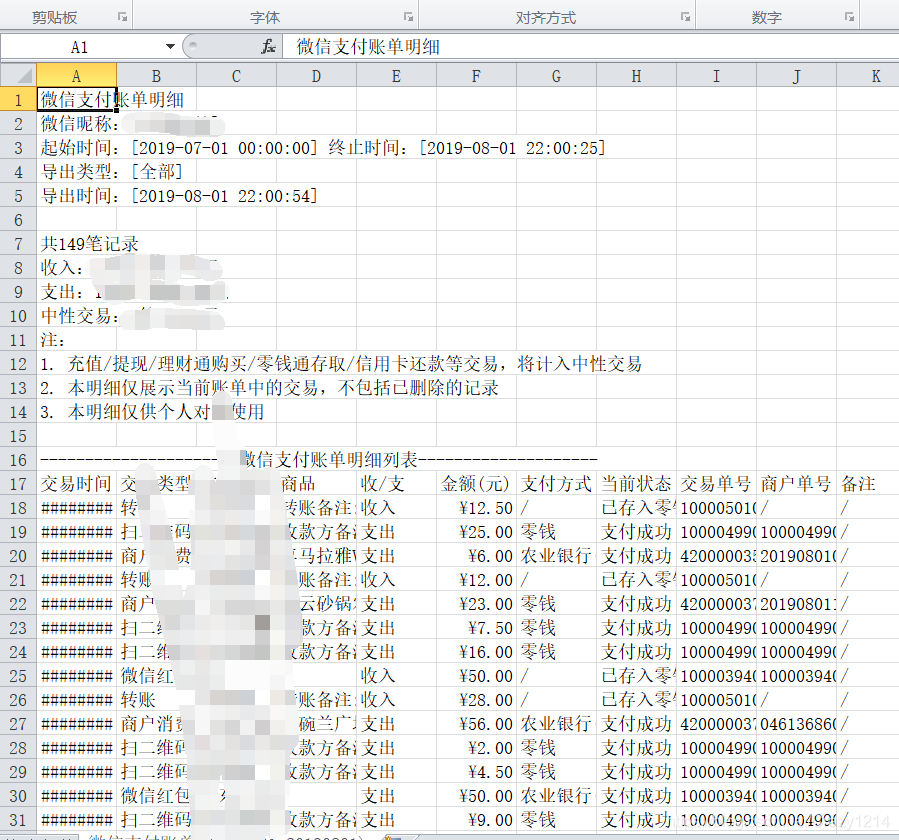
导入文件,这里写了一个读取的函数,分析上表,我们可以看到实际数据是从第18行进行记录的,因此这里我们写一个count,当count到达17以后,就进行下一步的处理。
#coding:utf8
import csv
def read_csv(filename):csv_file = csv.reader(open(filename,encoding='UTF-8'))count=0for line in csv_file: #数据类型是列表if count >=17:#print(line[0]) #从17行开始,为主要的内容savedata(line)count+=1
上面的savedata函数是用来分类数据,将其分为“收入”,“支出”,同时这里新建几个全局变量,用来记录分类的结果,并用于之后的分析
#声明全局变量
#支出记录
paymentlist=[]
#收入记录
incomelist=[]
#支出多少笔数据
paymentnum=0
pay=0
#收入多少笔数据
incomenum=0
income=0
def savedata(line):global paymentnumglobal incomenumprint(line[4])if line[4]=='支出':paymentlist.append(line)paymentnum+=1else:incomelist.append(line)incomenum+=1
以下是收入、支出各自求和的函数,我们分析这个钱,前面有个符号,这是我们不用的,因此是从第1个字符进行读取,且需要转换为浮点型,之前是字符串型。

#收入求和
def getPayMentlist():all=0for item in paymentlist:# print(float(item[5][1:]))all=all+float(item[5][1:])print(all)return all
#支出求和
def getIncomelist():all=0for item in incomelist:# print(float(item[5][1:]))all=all+float(item[5][1:])print(all)return all
以下的函数做到了各个商铺的消费、支出分类,以及最大消费的识别,使用的是字典,同样定义了一个全局变量。
#支出明细归纳汇总
dict1={}
def getPayment_listDetail():for item2 in paymentlist:x=dict1.get(item2[2])if x ==None:#如果没有这个key,就对字典进行赋值dict1[item2[2]]=float(item2[5][1:])else:#字典中有key对应的value,取出value+现在的值dict1[item2[2]]=dict1[item2[2]]+float(item2[5][1:])max=0maxtitle=""for i in dict1:print(i+':',dict1[i])temp=dict1[i]if max<temp:max=tempmaxtitle=iprint("最大的消费记录:{},{}".format(maxtitle,max))
主函数的执行
read_csv("微信支付账单(20190701-20190801).csv") #加载主要数据
print("支出笔数:{}".format(paymentnum))
print("收入笔数:{}".format(incomenum))
getPayMentlist()
getIncomelist()
getPayment_listDetail()
下面就是pyecahrts的使用,这个安装自行百度,这里可视化的是前10个的数据,没有按照消费的大小进行。
from pyecharts import Pie
#list是转换为列表
attr = list(dict1.keys())[:10]
v1 = list(dict1.values())[:10]
pie = Pie("饼图示例")
pie.add("",attr,v1,is_label_show=True)
pie.render("七月份消费记录.html")
至此,完成。