mybatis 版本:v3.3.0
文章目录
- 执行流程
- MapperProxyFactory
- MapperProxy
- MapperMethod
- execute
- convertArgsToSqlCommandParam
- ResultHandler
- SqlSession
- Executor(执行器)
- StatementHandler(声明处理器)
- ParameterHandler(参数处理器)
- ResultSetHandler(结果集处理器)
- getRowValue
- storeObject
- 动态sql
- 缓存
- 插件
- 嵌套查询
- resultSets
执行流程
MapperProxyFactory
众所周知,mapper在运行时会被代理,所以先看看mapper接口是如何被代理的。
SqlSession.getMapper -> Configuration.getMapper -> MapperRegistry.getMapper


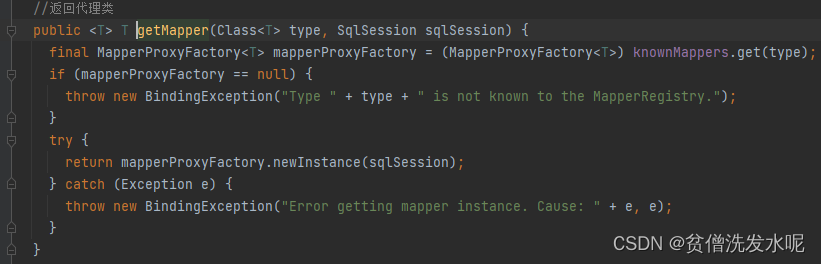
这里有个细节,MapperRegistry会先从自身的knownMappers缓存中去拿,如果没有才创建代理类。所以只要使用的是同一个MapperRegistry对象,那么Mapper接口将会共用Mapper代理类对象。
继续往下跟进,发现MapperProxyFactory中使用jdk代理创建了一个MapperProxy代理对象。
MapperProxy
接着来看 MapperProxy是的代理逻辑——invoke方法。
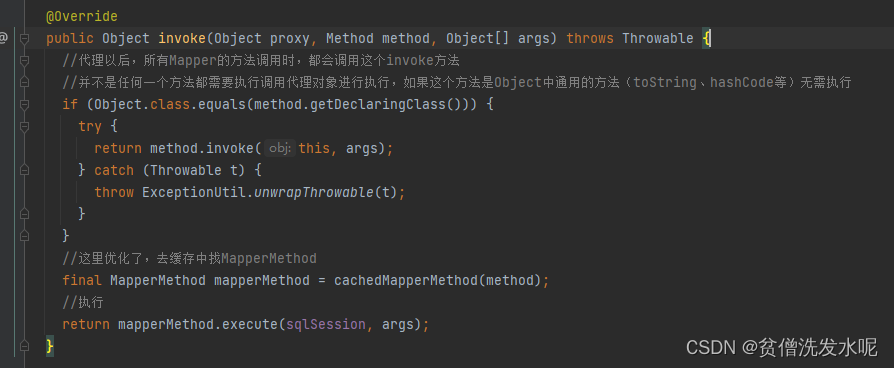
从代理逻辑中可以看出,不会代理Object中的方法。并且实际执行逻辑给到了MapperMethod,同时获取MapperMethod也用到了缓存的设计。
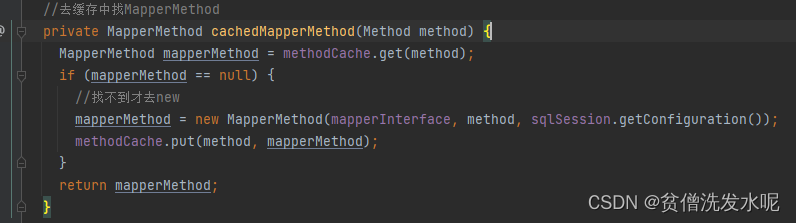
MapperMethod
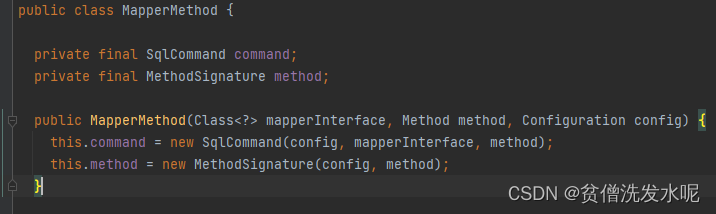
MapperMethod在变量上只有两个成员变量。可以粗俗这么理解:MapperMethod = sql语句 + 方法描述
execute
现在来看看,他是怎么执行的。
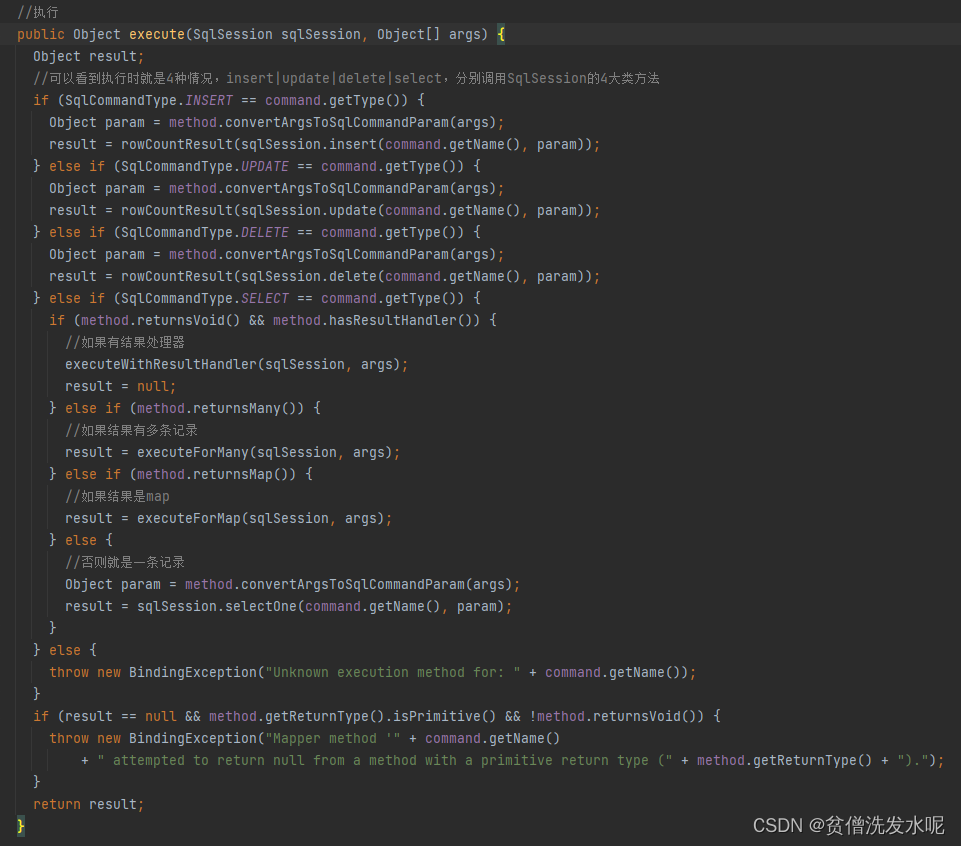
在MapperMethod中,虽然对增删改查都做了各自的操作,但最终都通过SqlSession去操作数据库。
INSERT -> sqlSession.insert
UPDATE -> sqlSession.update
DELETE -> sqlSession.delete
比较复杂一点的就是SELECT
如果方法没有返回值且有自定义resultHandler,则执行executeWithResultHandler -> sqlSession.select
如果方法返回多条记录,则执行executeForMany -> sqlSession.selectList
如果方法返回一个Map,则执行executeForMap -> sqlSession.selectMap
否则 -> sqlSession.selectOne
convertArgsToSqlCommandParam
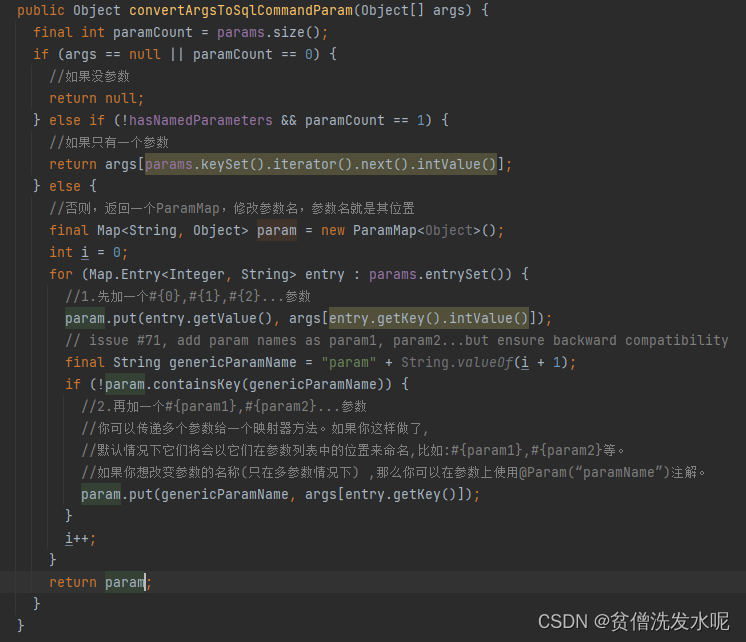
根据方法传递参数,构建sql参数。除没有参数返回null和只有一个参数返回其本身外,其余情况都是返回一个map。这里同时也解释了sql中支持#{param1},#{param2},#{param3}…写法的原因。
ResultHandler
回到刚刚的execute代码中关于executeWithResultHandler的判断。

反正我看到这里是觉得挺奇怪的,为什么自定义resultHandler不能有返回值?
我个人认为(欢迎评论区探讨),关键在于resultHandler的设计。
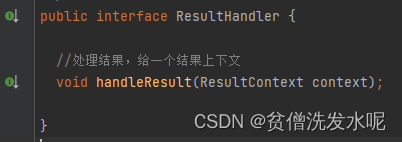
实际上,resultHandler接口中只有一个方法就是handlerResult,并且这个方法还没有返回值。
意思就是说,我现在已经把查询结果给到handler了,剩下的事情我就不管了,结果要怎么处理那是handler自己的事情。就算我后面想要获取handler处理后的结果也得看handler愿不愿意给我(有没有给我提供方法)。
而mybatis为了提高开发效率,只是对返回值是list和map做了扩展,额外提供了sqlSession.selectList,sqlSession.selectMap用于这两种场景(sqlSession.selectOne实际上只是selectList后返回第一个元素)使得mapper可以返回这两种类型。
目前mybatis提供的resultHandler实现有两种:DefaultResultHandler和DefaultMapResultHandler,分别用于处理返回类型是list和map的映射。

对于返回值是list的情况,可以说是天然支持的,因为从数据库中查询出来的结果就是一个list,所以Executor默认就会使用DefaultResultHandler返回list。
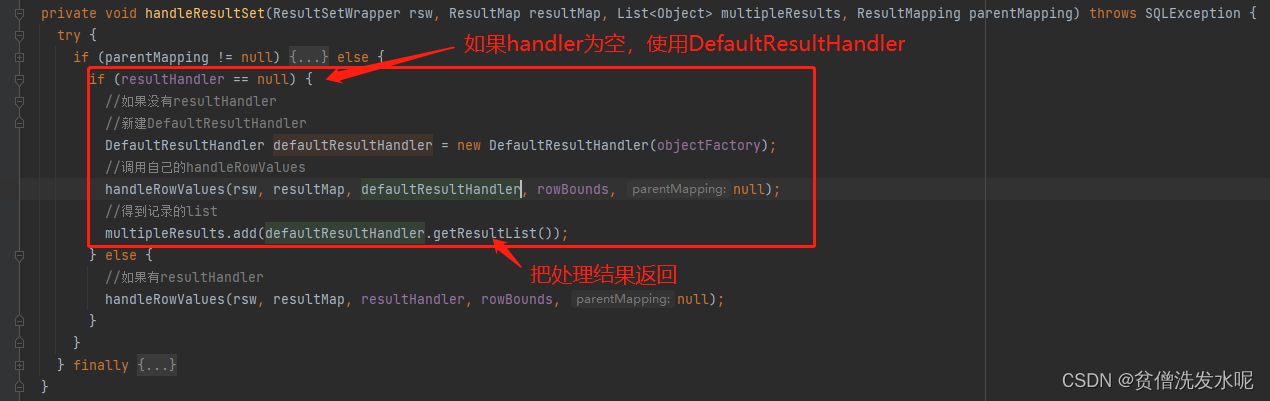

至于Map的情况,则是SqlSession做的扩展
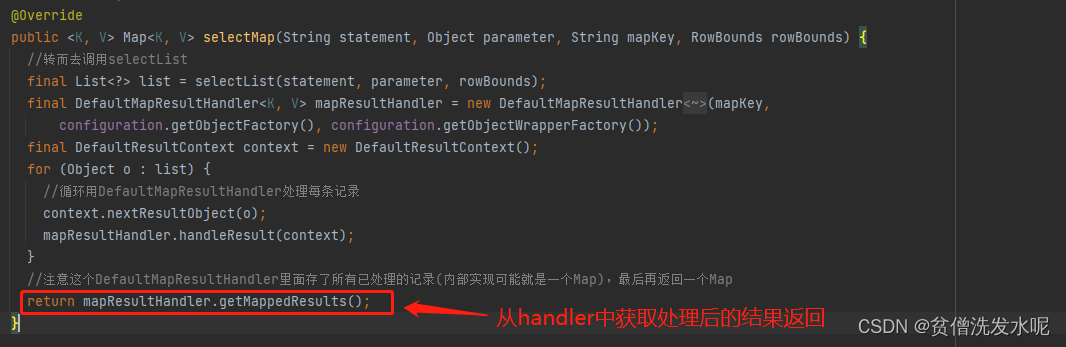
SqlSession
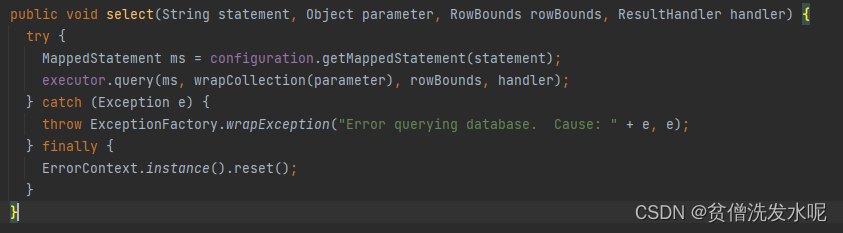
刚提到代理类最终会通过sqlSession去操作数据库,而sqlSession实际上又是通过Executor去操作数据库,以select为例。
Executor(执行器)
Executor的继承关系如下:
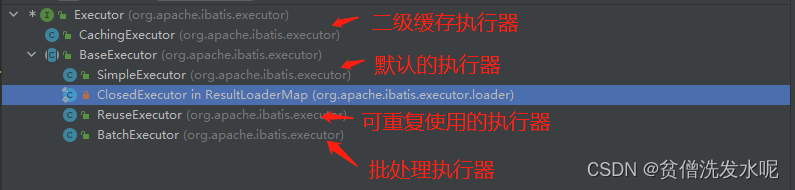
对于query查询方法来说,最终都会调到BaseExecutor这个基类。
public <E> List<E> query(MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler, CacheKey key, BoundSql boundSql) throws SQLException {ErrorContext.instance().resource(ms.getResource()).activity("executing a query").object(ms.getId());//如果已经关闭,报错if (closed) {throw new ExecutorException("Executor was closed.");}//先清局部缓存,再查询.但仅查询堆栈为0,才清。为了处理递归调用if (queryStack == 0 && ms.isFlushCacheRequired()) {clearLocalCache();}List<E> list;try {//加一,这样递归调用到上面的时候就不会再清局部缓存了queryStack++;//先根据cachekey从localCache去查list = resultHandler == null ? (List<E>) localCache.getObject(key) : null;if (list != null) {//若查到localCache缓存,处理localOutputParameterCachehandleLocallyCachedOutputParameters(ms, key, parameter, boundSql);} else {//从数据库查list = queryFromDatabase(ms, parameter, rowBounds, resultHandler, key, boundSql);}} finally {//清空堆栈queryStack--;}if (queryStack == 0) {//延迟加载队列中所有元素for (DeferredLoad deferredLoad : deferredLoads) {deferredLoad.load();}// issue #601//清空延迟加载队列deferredLoads.clear();if (configuration.getLocalCacheScope() == LocalCacheScope.STATEMENT) {// issue #482//如果是STATEMENT,清本地缓存clearLocalCache();}}return list;}
BaseExecutor中实现了对一级缓存的支持,对应里面的localCache变量。因为每一个sqlSession都会新建一个executor,所以一级缓存是sqlSession级别的缓存。
为减少篇幅,直接来到最常用的SimpleExecutor.doQuery(queryFromDatabase方法进)。
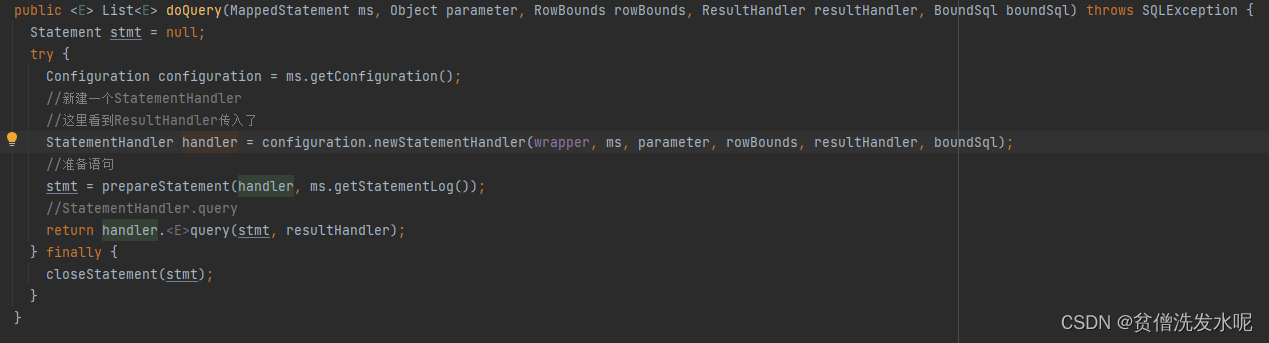
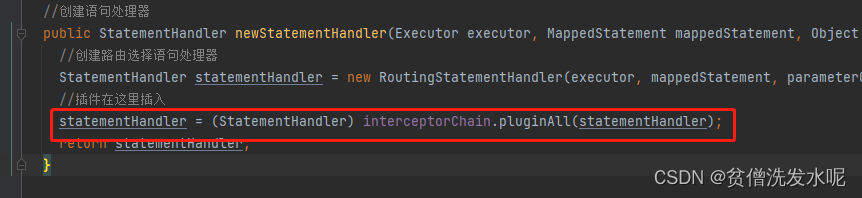
每一次查询都会根据configuration中的配置,新建一个StatementHandler。

在新建的同时也安装了插件
StatementHandler(声明处理器)
从上面可以得知,默认使用的是RoutingStatementHandler。但实际上他不是真正干事的家伙,他更像是一个路由/一个代理。根据statementType的不同创建不同的委托。

StatementHandler的继承关系如下
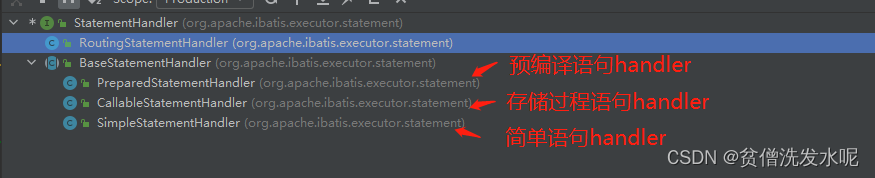
其中最常用的是PreparedStatementHandler。
除此之外,从BaseStatementHandler的构造方法中可以看出,**新建StatementHandler的同时也会新建ParameterHandler和ResultSetHandler并赋值给StatementHandler。**所以执行器只需面向一个StatementHandler即可。
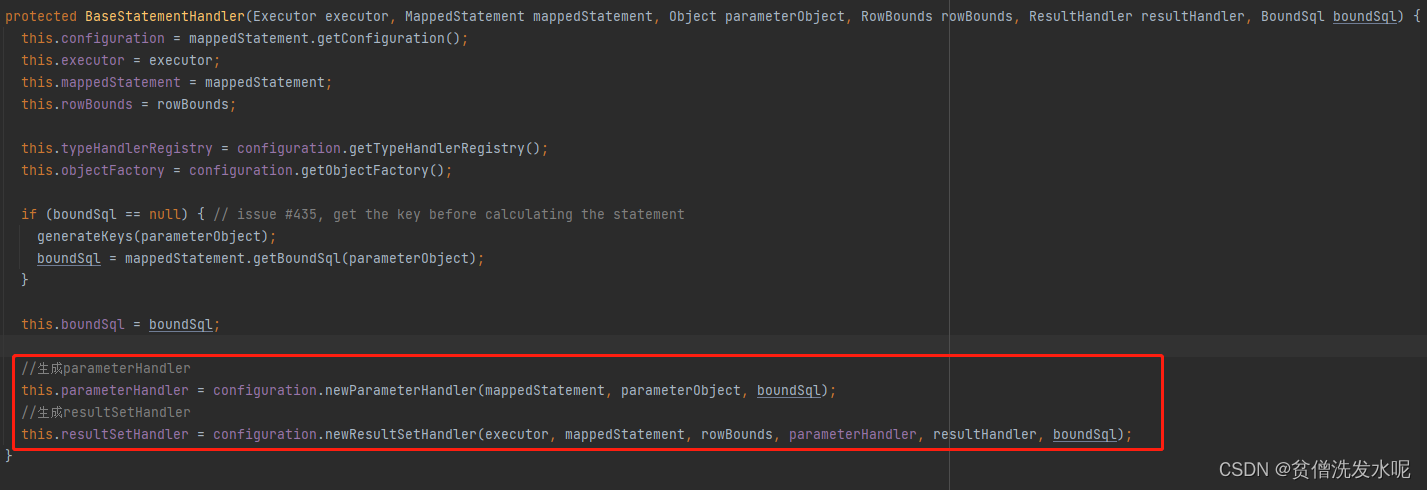
ParameterHandler(参数处理器)
接下来看看执行器是如何对参数进行处理的。跟踪doQuery里面的prepareStatement方法得到。
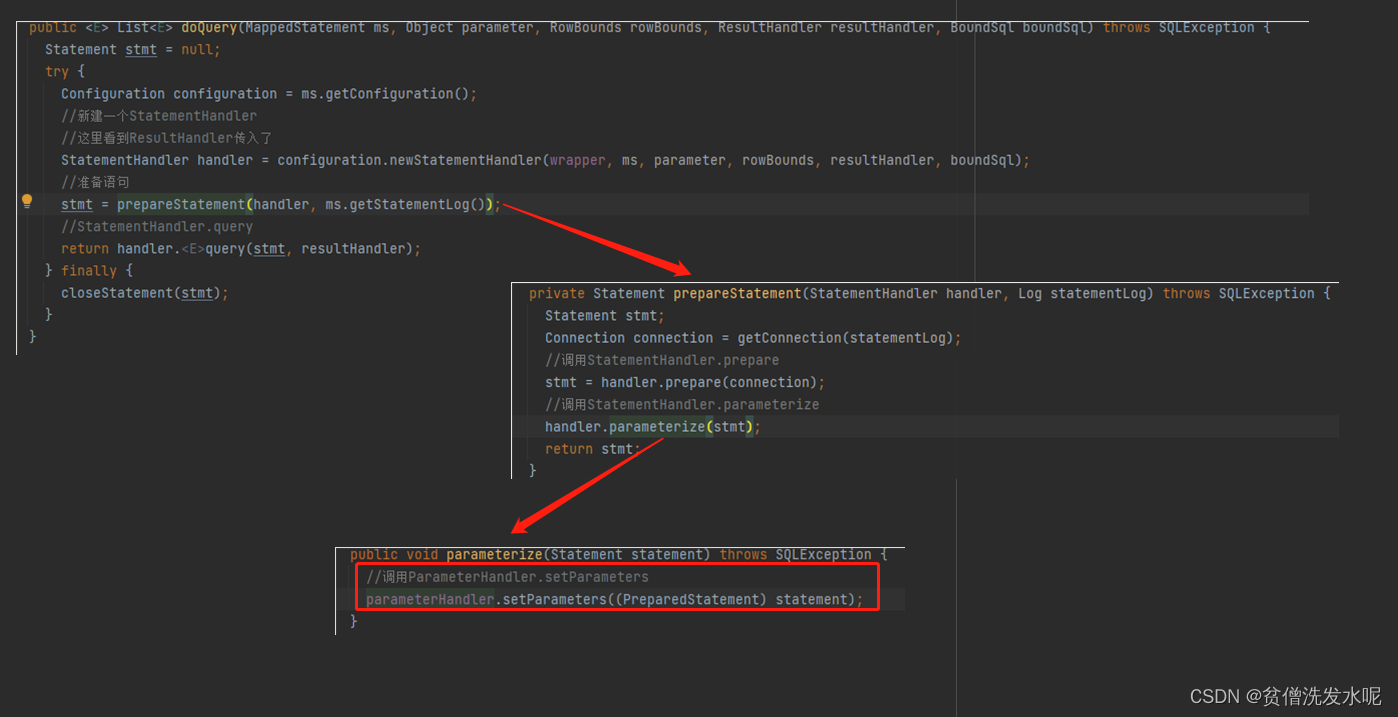
parameterHandler.setParameters
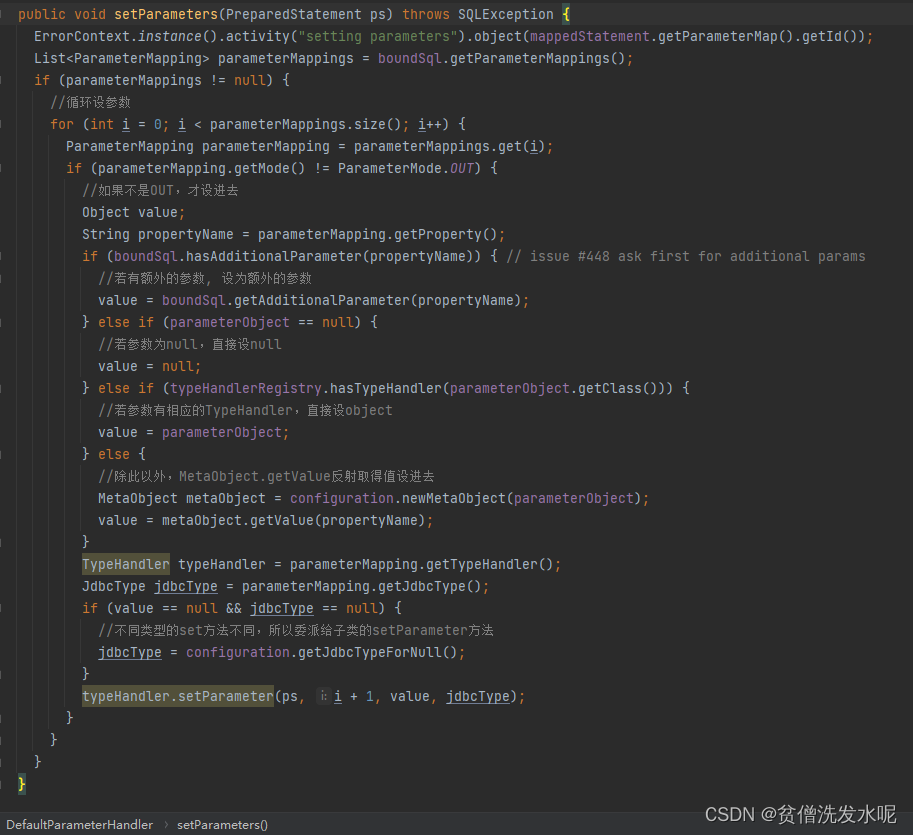
TypeHandler针对参数类型的处理就是在这一步实现的。
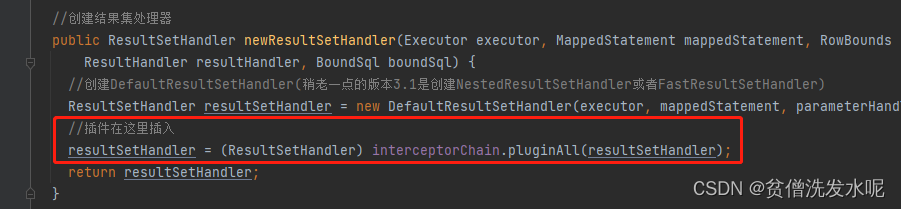
ResultSetHandler(结果集处理器)
结果集是如何查询和处理的?
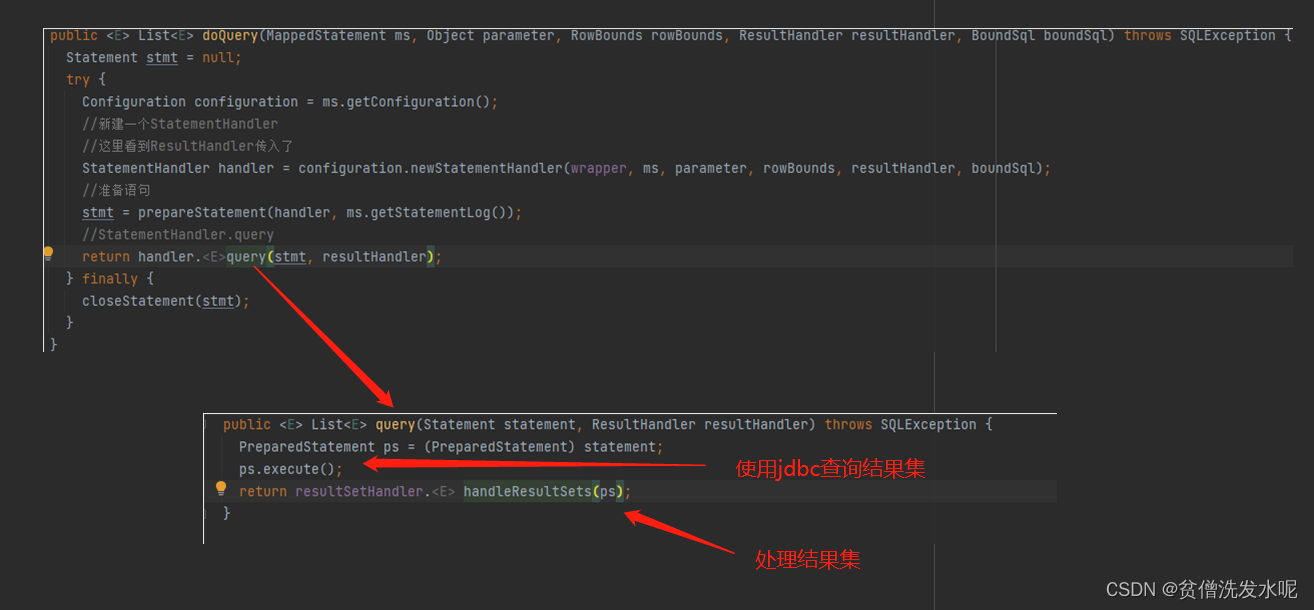
resultSetHandler.handleResultSets
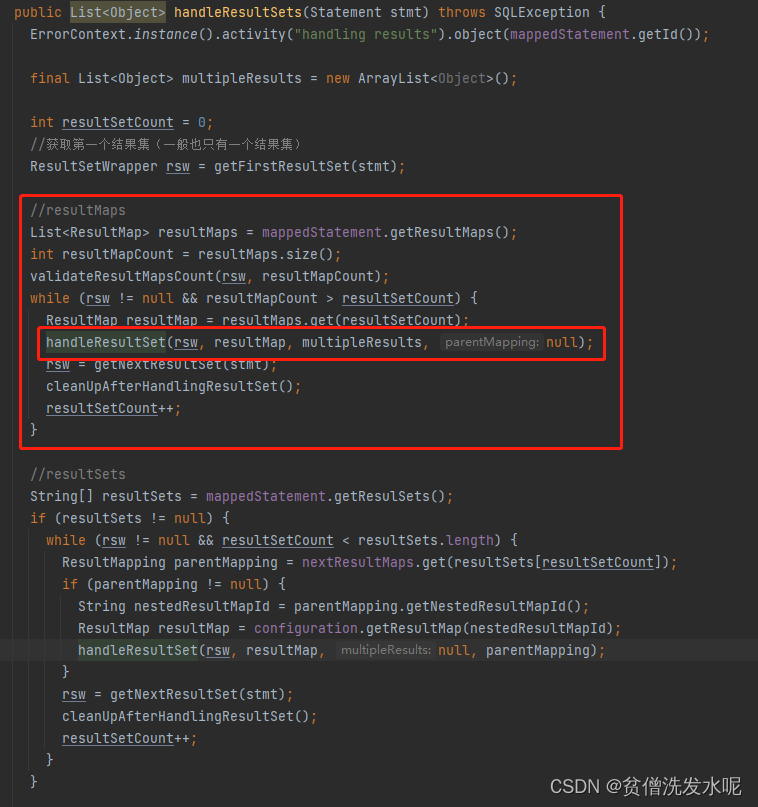
每一个结果集处理逻辑
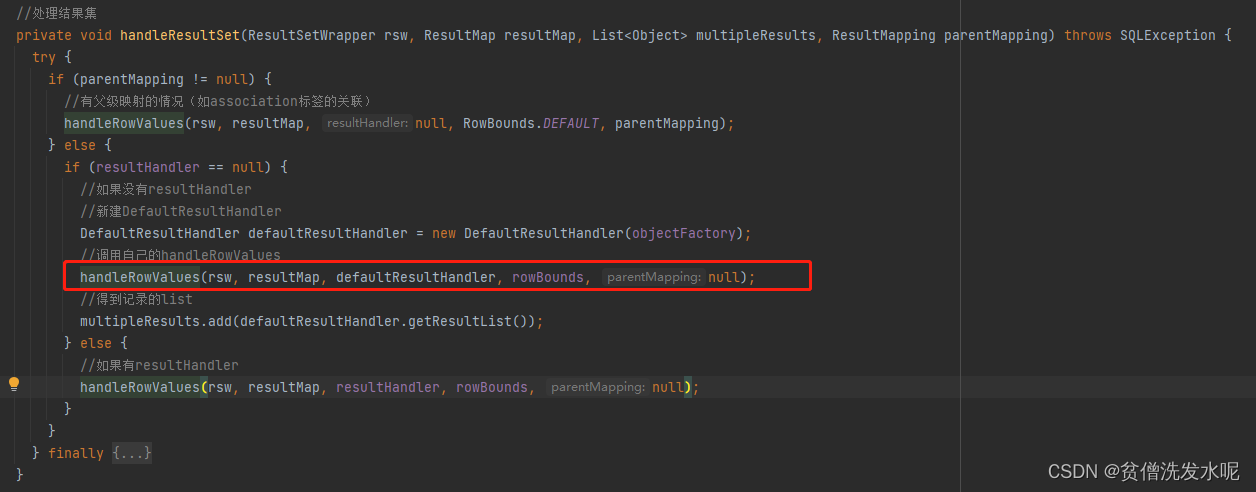
每一行数据的处理逻辑


getRowValue
根据查询结构得到一个POJO对象

创建POJO对象代码:
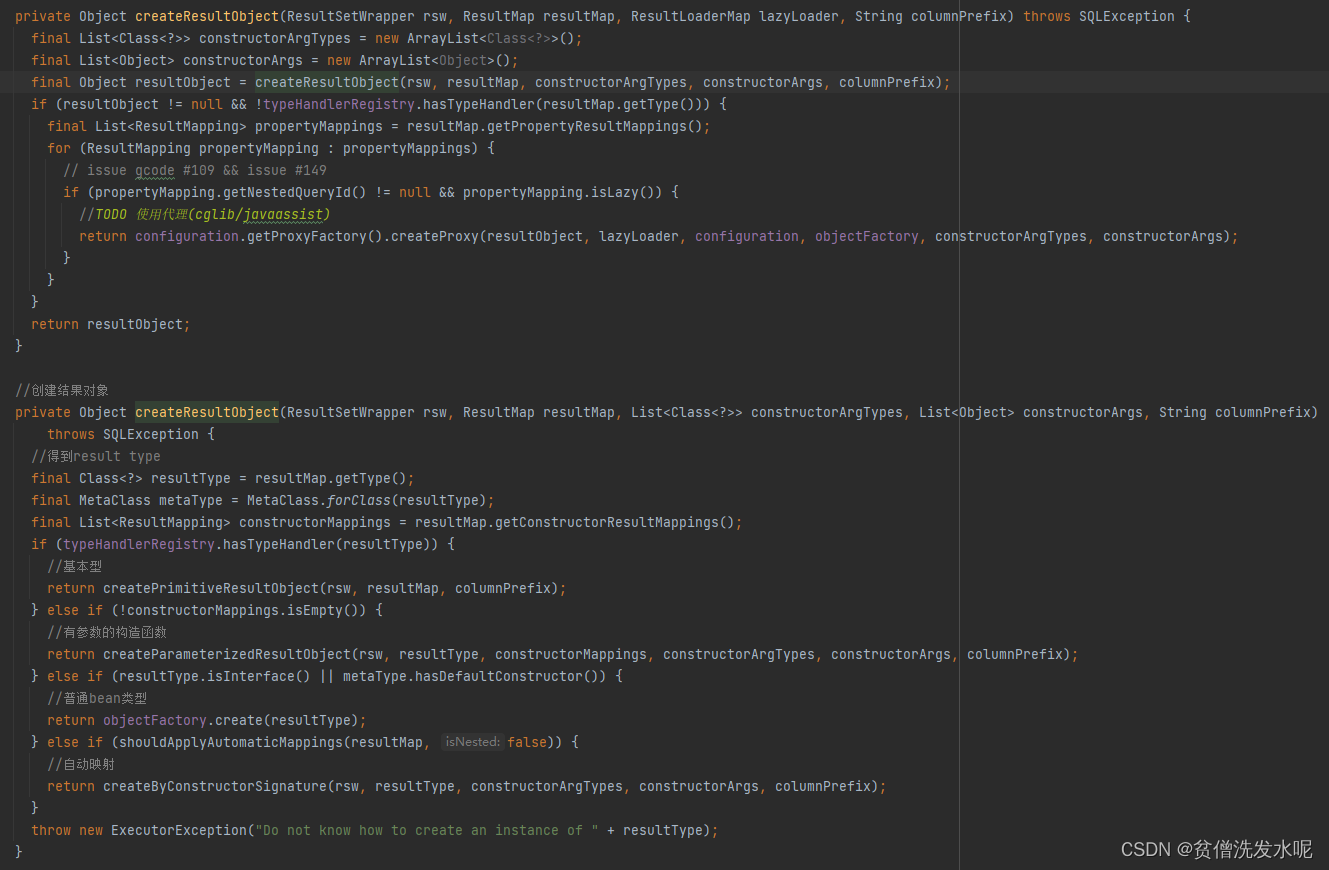
这里有几个细节:
1、创建实例时会再次使用到TypeHandler(所以TypeHandler不仅在处理参数时有用到)
2、如果需要会使用objectFactory创建实例(默认是DefaultObjectFactory,这个可自定义配置)
3、会尝试自动映射,把值按字段名填充上去。且在resultMap中明确指定的列,会被加入mappedColumnNames,不会参与自动映射。即自动映射只会映射unmappedColumnNames中的列
storeObject
把生成的POJO结果交给resultHandler

至此就完成了一个最基本的执行流程。
虽然里面还有很多细节没有提到,不过代码上大体就是这么一个流程。
动态sql
动态sql的每一个标签mybatis都将其描述成一个sqlNode,并且不同标签有不同的实现类。比如ChooseSqlNode对应choose标签,IfSqlNode对应if标签,WhereSqlNode对应where标签…至于在处理标签过程中有关表达式的判断则用的是ognl表达式,最后把所有标签的结果拼接起来得到最终的sql。

缓存
1、一级缓存是默认打开的,在BaseExecutor中实现了对一级缓存的支持,对应的是localCache变量。因为每一个sqlSession都会新建一个executor,所以一级缓存是sqlSession级别的缓存。同时当同一个sqlSession有对数据进行更新操作的话,会清空缓存导致缓存失效。
2、二次缓存默认是不打开的,属于nameSpace级别的缓存。如果要打开二级缓存,需要在mybatis.xml中添加cache标签或者设置cacheEnabled为true,并且具体实体类还要支持序列化。二级缓存是在sqlSession关闭的时候才存入的。
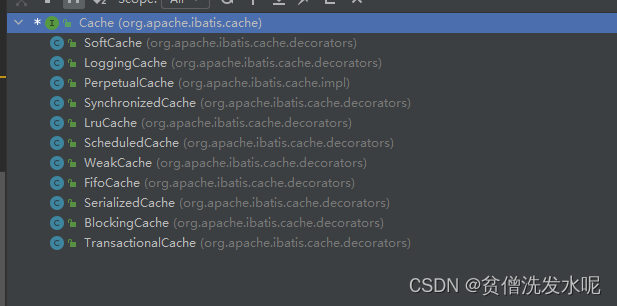
3、缓存器有多个实现,并且这些缓存器是可以同时使用的,设计模式是责任链模式。
插件
只有四大组件可以安装插件,会对具体拦截的方法进行代理。具体安装的地方在Configuration生成各自实例的地方。
Executor (update、query、commit、rollback等方法);
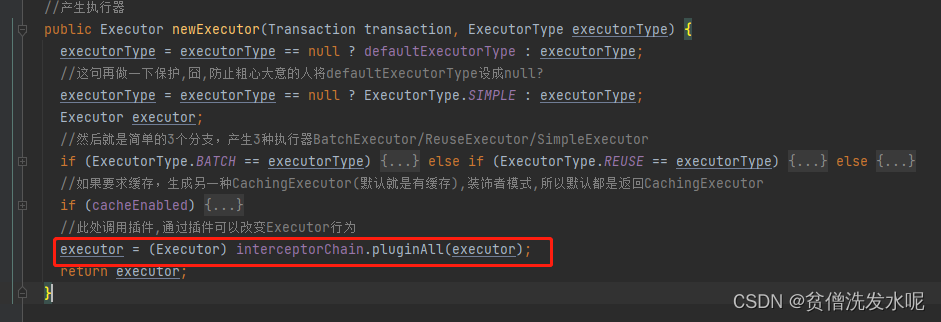
StatementHandler (prepare、parameterize、batch、updates query等方法);
ParameterHandler (getParameterObject、setParameters方法);

ResultSetHandler (handleResultSets、handleOutputParameters等方法);
嵌套查询
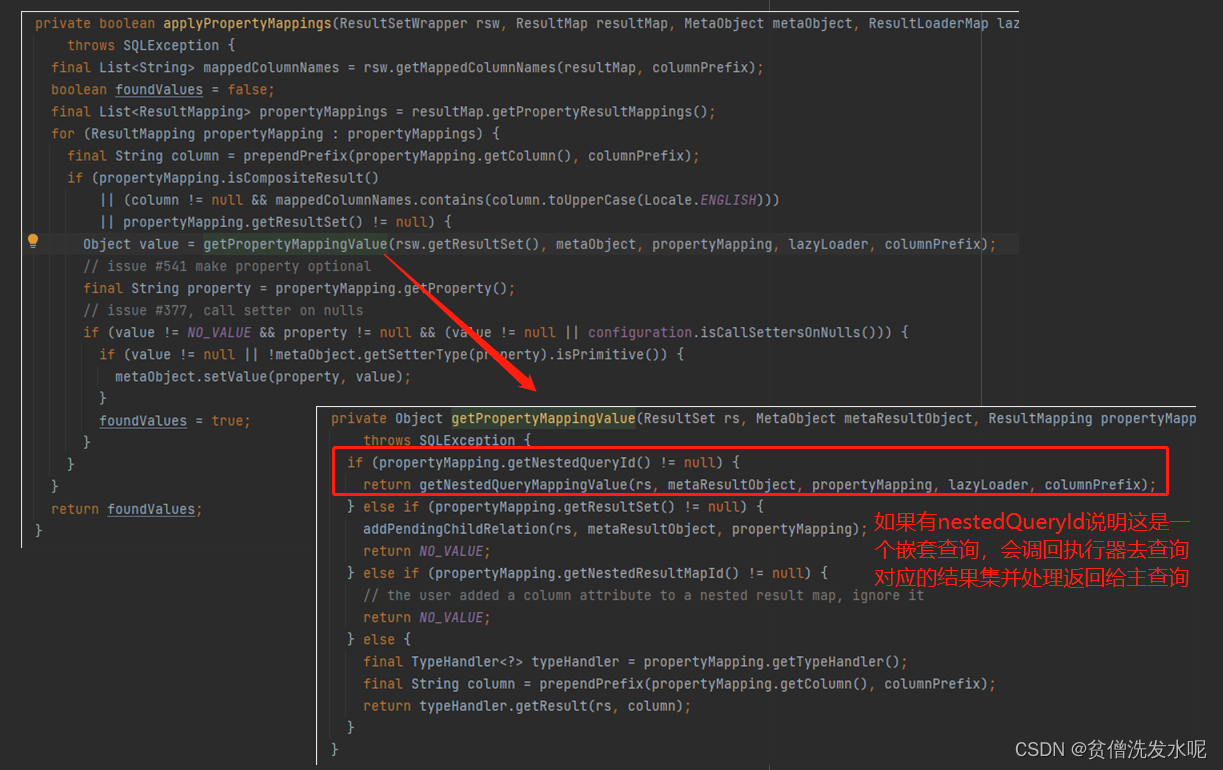
考虑这么一种场景,其中sub这个属性是怎么被赋值的?

mybatis将其描述成了一个嵌套查询。即在处理结果集,填充属性的时候,如果发现这是一个嵌套查询,则就会再次调用执行器,去执行对应的sql语句并处理结果集赋值给该属性。
这里有个细节,就是假如主查询返回10条数据,则相对应的就会有10个嵌套查询。
相关代码体现在 DefaultResultSetHandler.getRowValue获取POJO对象中的填充属性值方法。
resultSets
再考虑这么一个场景
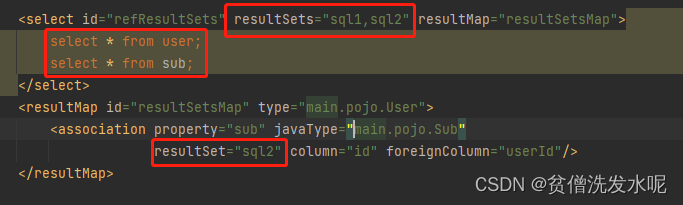
注意看,这里的查询语句有两个select,即说明执行这个mappedStatement会有两个结果集。这里分别命名sql1,sql2。而在resultMap中sub属性对应sql2结果集,说明sql2结果集关联sql1结果集的sub属性。
最终实现的效果是,数据库有且仅会查询两次,得到两个结果集并依次处理。最终返回的结果中,几乎等效于嵌套查询的外键关联。唯一不同的就是,若sql2结果集中的任一条数据在sql1结果集中找不到对应的关联数据会报错。
这是因为mybatis如果用的是resultSets,那么这两个结果集中并没有什么主从关系。mybatis是依次处理结果集的,如果在处理的过程中发现该结果集有关联另一个结果集,就会其结果和相关联的结果集连接起来。
这里有个细节,resultSets的连接是基于内存的,毕竟总共也就只执行了两个sql,不可能依靠数据库连接。
相关代码体现在DefaultResultSetHandler

这个resultSets用的比较少,而且个人认为功能也比较鸡肋。也没有太仔细的去深究,就这样吧。