SpringCloud(8)— 使用ElasticSearch(RestClient)
一 认识RestClient
ES 官方提供了各种语言的客户端用来操作ES,这些客户端的本质就是组创DSL语句,通过 Http 请求发送给ES
官方文档地址:Elasticsearch Clients | Elastic
提示1:ES 中支持两种地理坐标数据类型
- geo_point:ES中的 mapping 类型中利用经度和纬度确定一个点
- geo_shape:由多个 geo_point 组成的复杂几何图形
提示2:字段拷贝可以使用 copy_to 属性将当前字段的属性值拷贝到指定的属性上,方便以后搜索,且被指定的字段在查询数据时对外不可见
例如:以下示例中的 all 字段,在后边查询数据时不会返回
{"all":{"type":"text","analyzer":"ik_max_word"},"brand":{"type":"keyword","copy_to":"all"}
}
二 RestClient操作索引库
1.初始化RestClient
在项目中引入 RestClient 的 mavne 依赖坐标,版本需与 ElasticSearch 的版本一致。这里使用的是 7.12.1
<properties><elasticsearch.version>7.12.1</elasticsearch.version>
</properties>
<dependencies><dependency><groupId>org.elasticsearch.client</groupId><artifactId>elasticsearch-rest-high-level-client</artifactId><version>${elasticsearch.version}</version></dependency>
</dependencies>
由于 SpringBoot 项目中已经对 elasticsearch 进行管理,所以需要手动定义相同的参数值去覆盖默认的版本号,从而使用我们想使用的版本
编写测试代码,测试 RestHighLevelClient 是否初始化成功
private RestHighLevelClient restHighLevelClient;//初始化 RestHighLevelClient 对象
@BeforeEach
void setUp(){this.restHighLevelClient=new RestHighLevelClient(RestClient.builder(HttpHost.create("http://192.168.119.101:9200")));
}//销毁 RestHighLevelClient 对象
@AfterEach
void tearDown() throws IOException {this.restHighLevelClient.close();
}@Test
void testInit(){System.out.println(restHighLevelClient);
}
或者可以使用 Ioc 思想,创建一个 Bean 到内存中,然后使用它即可
@Bean
public RestHighLevelClient restHighLevelClient(){return new RestHighLevelClient(RestClient.builder(HttpHost.create("http://192.168.119.101:9200")));
}
2.创建索引库
编写一个测试方法,用来测试创建索引库是否成功
@Test
void testCreateIndex() throws IOException {//1.创建一个 CreateIndexRequest 对象,指定 indexName(索引库名称)CreateIndexRequest request = new CreateIndexRequest("hotel");// 这是一段很恶心的 DSL 语句的拼接,为了方便可以将这一块代码提了出来,这里为了方便演示不做优化处理String mapping ="{\n" +" \"mappings\": {\n" +" \"properties\": {\n" +" \"all\":{\n" +" \"type\": \"text\"\n" +" },\n" +" \"id\":{\n" +" \"type\": \"long\",\n" +" \"index\": false\n" +" },\n" +" \"name\":{\n" +" \"type\": \"text\",\n" +" \"copy_to\": \"all\"\n" +" },\n" +" \"address\":{\n" +" \"type\": \"text\",\n" +" \"index\": false, \n" +" \"copy_to\": \"all\"\n" +" },\n" +" \"price\":{\n" +" \"type\": \"keyword\",\n" +" \"copy_to\": \"all\"\n" +" },\n" +" \"score\":{\n" +" \"type\": \"keyword\",\n" +" \"copy_to\": \"all\"\n" +" },\n" +" \"brand\":{\n" +" \"type\": \"keyword\",\n" +" \"copy_to\": \"all\"\n" +" },\n" +" \"city\":{\n" +" \"type\": \"keyword\",\n" +" \"copy_to\": \"all\"\n" +" },\n" +" \"starName\":{\n" +" \"type\": \"keyword\",\n" +" \"copy_to\": \"all\"\n" +" },\n" +" \"business\":{\n" +" \"type\": \"keyword\",\n" +" \"copy_to\": \"all\"\n" +" },\n" +" \"location\":{\n" +" \"type\": \"geo_point\"\n" +" },\n" +" \"pic\":{\n" +" \"type\": \"keyword\",\n" +" \"copy_to\": \"all\"\n" +" }\n" +" }\n" +" }\n" +"}";//2.定义 DSLrequest.source(mapping, XContentType.JSON);//3.创建索引库restHighLevelClient.indices().create(request, RequestOptions.DEFAULT);
}
运行完成后,可以去浏览器通过 GET 方法访问,如果返回对应的JSON格式信息,则说明创建索引库成功。
# 浏览器访问
http://192.168.119.101:9200/hotel
# kibana 中的 dev tools 中测试
GET /hotel
CreateIndexRequest 对象中的 indices() 对象里,包含了操作索引库的所有方法
3.删除索引库
@Test
void testDeleteIndex() throws IOException {// 定义 DeleteIndexRequest 对象DeleteIndexRequest request=new DeleteIndexRequest("hotel");// 执行删除操作restHighLevelClient.indices().delete(request,RequestOptions.DEFAULT);
}
4.判断指定索引库是否存在
@Test
void testDeleteExist() throws IOException {// 定义 GetIndexRequest 对象GetIndexRequest request=new GetIndexRequest("hotel");// 发送请求restHighLevelClient.indices().exists(request,RequestOptions.DEFAULT);
}
三 RestClient操作文档
1.添加文档
编写测试方法,从数据库查询到指定数据,并且格式化为 Json,然后将数据存储到 特定的索引库中
Hotel 实体对象示例:
@Data
public class Hotel implements Serializable {private final static Long serialVersionUID=1L;private Long id;private String name;private String address;private Integer price;private Integer score;private String city;private String starName;private String brand;private String business;private String latitude;private String longitude;private String pic;
}
HotelDoc 文档实体对象:
注意:文档的实体应该与创建时的 mapping 字段完全一致
@Data
public class HotelDoc implements Serializable {public HotelDoc() {}public HotelDoc(Hotel hotel) {BeanUtils.copyProperties(hotel,this);// 主要是此处处理了经纬度的格式,使用字符串格式时,要求 纬度在前,经度在后this.location=hotel.getLatitude()+","+hotel.getLongitude();}private final static Long serialVersionUID = 1L;private Long id;private String name;private String address;private Integer price;private Integer score;private String city;private String starName;private String brand;private String business;private String pic;private String location;}
添加一条文档到索引库中:
@Test
void testAddDocument() throws IOException {Long id = 36934L;Hotel hotel = hotelService.getById(id);if (Objects.nonNull(hotel)) {// 1.创建 IndexRequest 对象,指定文档要存入的【索引库】及【文档Id】,此处的【文档Id】使用数据库的【主键Id】IndexRequest request = new IndexRequest("hotel").id(id.toString());// 2.准备 JSON 数据HotelDoc hotelDoc = new HotelDoc(hotel);String jsonString = JSON.toJSONString(hotelDoc);request.source(jsonString, XContentType.JSON);// 3.发送请求restHighLevelClient.index(request, RequestOptions.DEFAULT);return;}System.out.println("id=" + id + "的信息不存在");
}
踩坑底:对于 mapping 类型为 geo_point 的经纬度,使用字符串格式时,需要“纬度在前经度在后
运行成功后,数据将被存入到 ES 中
2.查看文档
编写查看文档的示例代码,重点API 【GetRequest】
@Test
void testGetDocument() throws IOException {Long id = 36934L;// 1.创建 GetRequest 对象,指定【索引库】和【文档ID】GetRequest request = new GetRequest("hotel", id.toString());// 2.发送请求,读取到数据GetResponse documentFields = restHighLevelClient.get(request, RequestOptions.DEFAULT);String sourceStr = documentFields.getSourceAsString();//3. 使用fastJson转为实体对象HotelDoc hotelDoc = JSON.parseObject(sourceStr, HotelDoc.class);System.out.println(hotelDoc);
}
3.修改文档
编写修改文档的示例代码,重点API 【UpdateRequest】
@Test
void testUpdateDocument() throws IOException {Long id=36934L;// 1.创建 UpdateRequest 对象,指定【索引库】和 【文档Id】UpdateRequest request=new UpdateRequest("hotel",id.toString());// 2.准备要更新的参数和值,每两个参数为一对 key valuerequest.doc("price",200,"name","8天假日酒店");// 3.发送请求restHighLevelClient.update(request,RequestOptions.DEFAULT);
}
4.删除文档
编写删除文档的示例代码,重点API 【DeleteRequest】
@Test
void testDeleteDocument() throws IOException {Long id=36934L;// 1.创建 DeleteRequest 对象,指定【索引库】和 【文档Id】DeleteRequest deleteRequest=new DeleteRequest("hotel",id.toString());// 2.发送请求restHighLevelClient.delete(deleteRequest,RequestOptions.DEFAULT);
}
5.批量导入文档
编写批量导入测试方法,重点API 【BulkRequest】
@Test
void tesBulkDocument() throws IOException {// 1.定义 BulkRequest 对象BulkRequest request=new BulkRequest();List<Hotel> list = hotelService.list();// 2.查询所有数据并且转换为 List<HotelDoc>List<HotelDoc> listDoc=list.stream().map(t->{HotelDoc doc=new HotelDoc(t);return doc;}).collect(Collectors.toList());// 3.遍历 List<HotelDoc> 对象,创建 IndexRequest 并且通过 add() 添加到 BulkRequest 对象中for (HotelDoc doc: listDoc) {IndexRequest indexRequest=new IndexRequest("hotel").id(doc.getId().toString());indexRequest.source(JSON.toJSONString(doc),XContentType.JSON);request.add(indexRequest);}// 4.发送 ES 请求restHighLevelClient.bulk(request,RequestOptions.DEFAULT);
}
在 kibana 控制台通过查询命令可以查询到已经导入数据
#1.hotel为索引库名称
GET /hotel/_search
四 RestClient查询
RestClient 所有解析的归根结底是逐层解析 Json 结构
1.快速入门(match_all)
通过 match_all 演示 RestClient 的基本API
编写以下测试代码,实现 match_all 的使用
@Test
void testMatchAll() throws IOException {//1.创建 SearchRequest 对象,指定索引库名称SearchRequest request=new SearchRequest("hotel");//2.组织 DSL 参数request.source().query(QueryBuilders.matchAllQuery()).from(0).size(3); //3.发送请求,得到响应结果SearchResponse response=restHighLevelClient.search(request, RequestOptions.DEFAULT);//4. 通过 SearchResponse 对象的 getHits 拿到数据结果集,然后进行处理SearchHits hits = response.getHits();//5.获取数据总条数Long totalHits = hits.getTotalHits().value;System.out.println(totalHits);//6.处理结果for (SearchHit hit : hits) {HotelDoc doc = JSON.parseObject(hit.getSourceAsString(), HotelDoc.class);System.out.println(doc.toString());}
}
RestClient 与 DSL 语法对比:
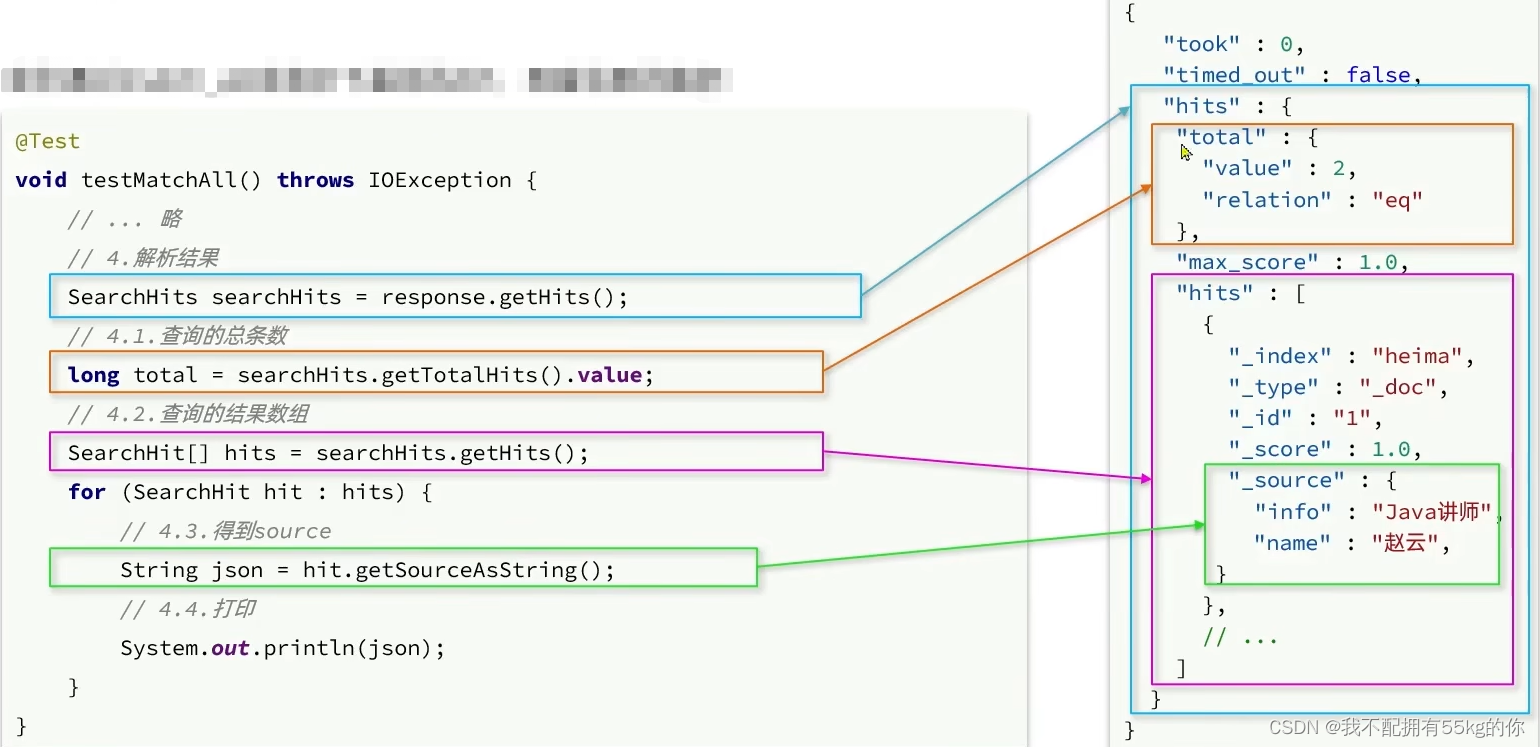
- 使用 QueryBuilders 实现各种查询方式
- 通过 SearchRequest 对象的 source() 对象实现链式编程,从而设置分页,排序,高亮,复合查询等操作
- 通过 RestHighLevelClient 对象的 search() 方法发送查询请求,实现查询
- 通过 SearchResponse 对象接受查询结果并进行处理
- 通过 SearchHits 对象拿到结果集和数据总行数
主要通过解析 DSL 语法返回结果集中的 hits 对象,获取到总条数及数据内容,从而对数据进行处理
2.全文检索
全文检索 与 match_all 的API基本一致,差别在于 match 有了查询条件,即 DSL 语句中的 query 部分。
1.match(特定字段)
//1.创建 SearchRequest 对象,指定索引库名称
SearchRequest request = new SearchRequest("hotel");//2.组织 DSL 参数
request.source().query(QueryBuilders.matchQuery("all", "如家"));//3.发送请求,得到响应结果
SearchResponse response = restHighLevelClient.search(request, RequestOptions.DEFAULT);
2.multi_match(多字段)
//1.创建 SearchRequest 对象,指定索引库名称
SearchRequest request = new SearchRequest("hotel");//2.组织 DSL 参数
request.source().query(QueryBuilders.multiMatchQuery("如家","name","brand"))//3.发送请求,得到响应结果
SearchResponse response = restHighLevelClient.search(request, RequestOptions.DEFAULT);
match 和 multi_match 的区别主要在于 QueryBuilders 类的调用方法不同
match 中 QueryBuilders 使用了 matchQuery()
multi_match 中 QueryBuilders 使用了 multiMatchQuery()
3.term(精准查询)
与 前面的相比,唯一的区别是使用了 termQuery()
@Test
void testMatch() throws IOException {//1.创建 SearchRequest 对象,指定索引库名称SearchRequest request = new SearchRequest("hotel");//2.组织 DSL 参数request.source().query(QueryBuilders.termQuery("brand","如家"));//3.发送请求,得到响应结果SearchResponse response = restHighLevelClient.search(request, RequestOptions.DEFAULT);
}
3.boolean query(组合)
boolean query 查询 与 前面的查询略有不同,需要先创建 BoolQueryBuilder 对象,然后通过 BoolQueryBuilder 对象添加过滤条件
@Test
void testBooleanQuery() throws IOException {//1.创建 SearchRequest 对象,指定索引库名称SearchRequest request = new SearchRequest("hotel");//2.创建 BoolQueryBuilder 对象,通过链式编程方式添加查询条件BoolQueryBuilder queryBuilder = new BoolQueryBuilder();queryBuilder.should(QueryBuilders.matchQuery("city", "上海")).must(QueryBuilders.termQuery("brand", "如家")).filter(QueryBuilders.rangeQuery("price").gte(200).lte(300));//3.组织 DSL 参数,填充 BoolQueryBuilder对象到 query中request.source().query(queryBuilder);//4.发送请求,得到响应结果SearchResponse response = restHighLevelClient.search(request, RequestOptions.DEFAULT);
}
或者可以直接一步到位
@Test
void testBooleanQuery() throws IOException {//1.创建 SearchRequest 对象,指定索引库名称SearchRequest request = new SearchRequest("hotel");//2.组织 DSL 参数request.source().query(new BoolQueryBuilder().should(QueryBuilders.matchQuery("city", "上海")).must(QueryBuilders.termQuery("brand", "如家")).filter(QueryBuilders.rangeQuery("price").gte(200).lte(300)));//3.发送请求,得到响应结果SearchResponse response = restHighLevelClient.search(request, RequestOptions.DEFAULT);
}
4.排序和分页
DSL 语句中,排序和分页 在 query 同级,RestClient 中与 DSL 一样,也是在 query() 之后
@Test
void testPageAndOrder() throws IOException {//1.创建 SearchRequest 对象,指定索引库名称SearchRequest request = new SearchRequest("hotel");//2.组织 DSL 参数request.source().query(new BoolQueryBuilder().should(QueryBuilders.matchQuery("city", "上海")).must(QueryBuilders.termQuery("brand", "如家")).filter(QueryBuilders.rangeQuery("price").gte(200).lte(300))).from(0).size(3).sort("score", SortOrder.DESC).sort("price",SortOrder.ASC);//3.发送请求,得到响应结果SearchResponse response = restHighLevelClient.search(request, RequestOptions.DEFAULT);
}
- from:开始位置,默认为0
- size:获取的数据数量,默认为10
- sort:使用 sort() 方法来进行排序,传入 字段名 和 排序方式

5.highlight(高亮显示)
高亮API包括 请求DSL构建 和 结果解析 两部分

测试代码实现如下:
@Test
void testHighLight() throws IOException {//1.创建 SearchRequest 对象,指定索引库名称SearchRequest request = new SearchRequest("hotel");//2.组织 DSL 参数request.source().query(QueryBuilders.matchQuery("all", "如家")).highlighter(//高亮字段是否和查询字段匹配new HighlightBuilder().field("name").requireFieldMatch(false).preTags("<em>").postTags("</em>"));//3.发送请求,得到响应结果SearchResponse response = restHighLevelClient.search(request, RequestOptions.DEFAULT);//4. 通过 SearchResponse 对象的 getHits 拿到数据结果集,然后进行处理SearchHits hits = response.getHits();//5.获取数据总条数Long totalHits = hits.getTotalHits().value;System.out.println(totalHits);for (SearchHit hit : hits) {HotelDoc doc = JSON.parseObject(hit.getSourceAsString(), HotelDoc.class);// 获取高亮区域的值Map<String, HighlightField> fields = hit.getHighlightFields();if (fields != null) {// 获取指定字段的高亮内容对象HighlightField highlightField = fields.get("name");String highLightName = highlightField.getFragments()[0].toString();// 替换原有的值doc.setName(highLightName);}System.out.println(doc);}
}
6.距离排序
按照距离排序,需要提供一组经纬度作为中心点,然后按照距离远近进行排序
距离排序中使用到一个新的对象,即 SortBuilders,以下是测试示例代码:
@Test
void testDistanceSort() throws IOException {//1.创建 SearchRequest 对象,指定索引库名称SearchRequest request = new SearchRequest("hotel");//2.组织 DSL 参数request.source().query(QueryBuilders.matchQuery("all", "如家")).sort(SortBuilders.geoDistanceSort("location", new GeoPoint("31.251433,121.47522")).order(SortOrder.ASC).unit(DistanceUnit.KILOMETERS));//3.发送请求,得到响应结果SearchResponse response = restHighLevelClient.search(request, RequestOptions.DEFAULT);
}
7.相关性算分
使用 RestClient 实现相关性算分时代码较为复杂,先看对照示例:

实现方式是基于 FunctionScoreQueryBuilder 对象
以下是测试代码,用于过滤 isAD=true 时,增加权重分值为10,且与原始分值相乘
@Test
void testFunctionScore() throws IOException {//1.创建 SearchRequest 对象,指定索引库名称SearchRequest request = new SearchRequest("hotel");// 原始查询,可以是一般查询,也可以是复合查询 BooleanQueryQueryBuilder queryBuilder = QueryBuilders.matchQuery("all", "如家");// 构建 FunctionScoreQueryBuilder 对象FunctionScoreQueryBuilder functionScoreQueryBuilder = QueryBuilders.functionScoreQuery(//方式查询queryBuilder,//functionScore 数组new FunctionScoreQueryBuilder.FilterFunctionBuilder[]{// 其中一个 function scorenew FunctionScoreQueryBuilder.FilterFunctionBuilder(//过滤条件QueryBuilders.termQuery("isAD", true),//算分函数,这里使用加权重ScoreFunctionBuilders.weightFactorFunction(20))})// 加权模式.boostMode(CombineFunction.MULTIPLY);;//2.组织 DSL 参数request.source().query(QueryBuilders.matchQuery("all", "如家"));//3.发送请求,得到响应结果SearchResponse response = restHighLevelClient.search(request, RequestOptions.DEFAULT);
}
注意:后边的 “isAD” 字段 是为了做相关性算分增加的新字段,前边的 索引库 和 实体类 中没有,需要手动增加。
本结知识点梳理完成,完结撒花。



![[附源码]计算机毕业设计Python公益组织登记与查询系统论文(程序+源码+LW文档)](https://img-blog.csdnimg.cn/a03219a56a8048ac82151730a04de2c8.png)
