前文提到线程的使用以及线程间通信方式,通常情况下我们通过new Thread或者new Runnable创建线程,这种情况下,需要开发者手动管理线程的创建和回收,线程对象没有复用,大量的线程对象创建与销毁会引起频繁GC,那么事否有机制自动进行线程的创建,管理和回收呢?线程池可以实现该能力。
线程池的优点:
- 线程池中线程重用,避免线程创建和销毁带来的性能开销
- 能有效控制线程数量,避免大量线程抢占资源造成阻塞
- 对线程进行简单管理,提供定时执行预计指定间隔执行等策略
线程池的封装实现
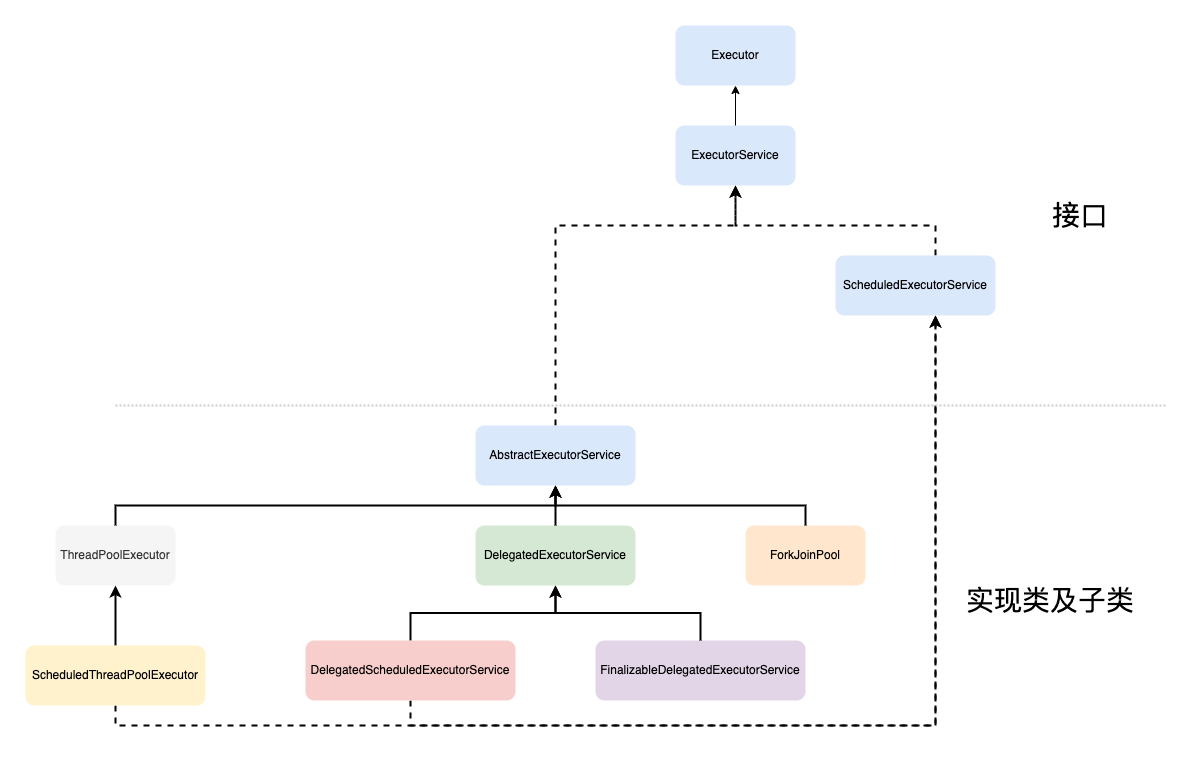
在java.util.concurrent包中提供了一系列的工具类以方便开发者创建和使用线程池,这些类的继承关系及说明如下:
| 类名 | 说明 | 备注 |
|---|---|---|
| Executor | Executor接口提供了一种任务提交后的执行机制,包括线程的创建与运行,线程调度等,通常不直接使用该类 | / |
| ExecutorService | ExecutorService接口,提供了创建,管理,终止Future执行的方法,用于跟踪一个或多个异步任务的进度,通常不直接使用该类 | / |
| ScheduledExecutorService | ExecutorService的实现接口,提供延时,周期性执行Future的能力,同时具备ExecutorService的基础能力,通常不直接使用该类 | / |
| AbstractExecutorService | AbstractExecutorService是个虚类,对ExecutorService中方法进行了默认实现,其提供了newTaskFor函数,用于获取RunnableFuture对象,该对象实现了submit,invokeAny和invokeAll方法,通常不直接使用该类 | / |
| ThreadPoolExecutor | 通过创建该类对象就可以构建一个线程池,通过调用execute方法可以向该线程池提交任务。通常情况下,开发者通过自定义参数,构造该类对象就来获得一个符合业务需求的线程池 | / |
| ScheduledThreadPoolExecutor | 通过创建该类对象就可以构建一个可以周期性执行任务的线程池,通过调用schedule,scheduleWithFixedDelay等方法可以向该线程池提交任务并在指定时间节点运行。通常情况下,开发者通过构造该类对象就来获得一个符合业务需求的可周期性执行任务的线程池 | / |
由上表可知,对于开发者而言,通常情况下我们可以通过构造ThreadPoolExecutor对象来获取一个线程池对象,通过其定义的execute方法来向该线程池提交任务并执行,那么怎么创建线程池呢?让我们一起看下
ThreadPoolExecutor
ThreadPoolExecutor完整参数的构造函数如下所示:
/*** Creates a new {@code ThreadPoolExecutor} with the given initial* parameters.** @param corePoolSize the number of threads to keep in the pool, even* if they are idle, unless {@code allowCoreThreadTimeOut} is set* @param maximumPoolSize the maximum number of threads to allow in the* pool* @param keepAliveTime when the number of threads is greater than* the core, this is the maximum time that excess idle threads* will wait for new tasks before terminating.* @param unit the time unit for the {@code keepAliveTime} argument* @param workQueue the queue to use for holding tasks before they are* executed. This queue will hold only the {@code Runnable}* tasks submitted by the {@code execute} method.* @param threadFactory the factory to use when the executor* creates a new thread* @param handler the handler to use when execution is blocked* because the thread bounds and queue capacities are reached* @throws IllegalArgumentException if one of the following holds:<br>* {@code corePoolSize < 0}<br>* {@code keepAliveTime < 0}<br>* {@code maximumPoolSize <= 0}<br>* {@code maximumPoolSize < corePoolSize}* @throws NullPointerException if {@code workQueue}* or {@code threadFactory} or {@code handler} is null*/public ThreadPoolExecutor(int corePoolSize,int maximumPoolSize,long keepAliveTime,TimeUnit unit,BlockingQueue<Runnable> workQueue,ThreadFactory threadFactory,RejectedExecutionHandler handler) {if (corePoolSize < 0 ||maximumPoolSize <= 0 ||maximumPoolSize < corePoolSize ||keepAliveTime < 0)throw new IllegalArgumentException();if (workQueue == null || threadFactory == null || handler == null)throw new NullPointerException();this.acc = System.getSecurityManager() == null ?null :AccessController.getContext();this.corePoolSize = corePoolSize;this.maximumPoolSize = maximumPoolSize;this.workQueue = workQueue;this.keepAliveTime = unit.toNanos(keepAliveTime);this.threadFactory = threadFactory;this.handler = handler;}
从上述代码可以看出,在构建ThreadPoolExecutor时,主要涉及以下参数:
- corePoolSize:核心线程个数,一般情况下可以使用 处理器个数/2 作为核心线程数的取值,可以通过Runtime.getRuntime().availableProcessors()来获取处理器个数
- maximumPoolSize:最大线程个数,该线程池支持同时存在的最大线程数量
- keepAliveTime:非核心线程闲置时的超时时长,超过这个时长,非核心线程就会被回收,我们也可以通过allowCoreThreadTimeOut(true)来设置核心线程闲置时,在超时时间到达后回收
- unit:keepAliveTime的时间单位
- workQueue:线程池中的任务队列,当核心线程数满或最大线程数满时,通过线程池的execute方法提交的Runnable对象存储在这个参数中,遵循先进先出原则
- threadFactory:创建线程的工厂 ,用于批量创建线程,统一在创建线程时进行一些初始化设置,如是否守护线程、线程的优先级等。不指定时,默认使用Executors.defaultThreadFactory() 来创建线程,线程具有相同的NORM_PRIORITY优先级并且是非守护线程
- handler:任务拒绝处理策略,当线程数量等于最大线程数且等待队列已满时,就会采用拒绝处理策略处理新提交的任务,不指定时,默认的处理策略是AbortPolicy,即抛弃该任务
综上,我们可以看出创建一个线程池最少需要明确核心线程数,最大线程数,超时时间及单位,等待队列这五个参数,下面我们创建一个核心线程数为1,最大线程数为3,5s超时回收,等待队列最多能存放5个任务的线程池,代码如下:
ThreadPoolExecutor executor = new ThreadPoolExecutor(1,3,5,TimeUnit.SECONDS,new LinkedBlockingQueue<>(5));
随后我们使用for循环向该executor中提交任务,代码如下:
public static void main(String[] args) {// 创建线程池ThreadPoolExecutor executor = new ThreadPoolExecutor(1,3,5,TimeUnit.SECONDS,new LinkedBlockingQueue<>(5));for (int i=0;i<10;i++) {int finalI = i;System.out.println("put runnable "+ finalI +"to executor");// 向线程池提交任务executor.execute(new Runnable() {@Overridepublic void run() {System.out.println(Thread.currentThread().getName()+",runnable "+ finalI +"start");try {Thread.sleep(5000);} catch (InterruptedException e) {throw new RuntimeException(e);}System.out.println(Thread.currentThread().getName()+",runnable "+ finalI +"executed");}});}
}
输出如下:

从输出可以看到,当提交一个任务到线程池时,其执行流程如下:
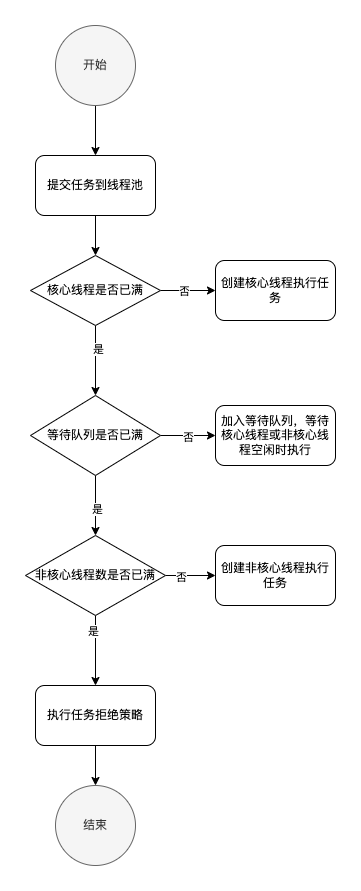
线程池拒绝策略
线程池拒绝策略有四类,定义在ThreadPoolExecutor中,分别是:
- AbortPolicy:默认拒绝策略,丢弃提交的任务并抛出RejectedExecutionException,在该异常输出信息中,可以看到当前线程池状态
- DiscardPolicy:丢弃新来的任务,但是不抛出异常
- DiscardOldestPolicy:丢弃队列头部的旧任务,然后尝试重新执行,如果再次失败,重复该过程
- CallerRunsPolicy:由调用线程处理该任务
当然,如果上述拒绝策略不能满足需求,我们也可以自定义异常,实现RejectedExecutionHandler接口,即可创建自己的线程池拒绝策略,下面是使用自定义拒绝策略的示例代码:
public static void main(String[] args) {RejectedExecutionHandler handler = new RejectedExecutionHandler() {@Overridepublic void rejectedExecution(Runnable r, ThreadPoolExecutor executor) {System.out.println("runnable " + r +" in executor "+executor+" is refused");}};ThreadPoolExecutor executor = new ThreadPoolExecutor(1,3,5,TimeUnit.SECONDS,new LinkedBlockingQueue<>(5),handler);for (int i=0;i<10;i++) {int finalI = i;Runnable runnable = new Runnable() {@Overridepublic void run() {System.out.println(Thread.currentThread().getName()+",runnable "+ finalI +"start");try {Thread.sleep(5000);} catch (InterruptedException e) {throw new RuntimeException(e);}System.out.println(Thread.currentThread().getName()+",runnable "+ finalI +"executed");}};System.out.println("put runnable "+ runnable+" index:"+finalI +" to executor:"+executor);executor.execute(runnable);}
}
输出如下:

任务队列
对于线程池而言,任务队列需要是BlockingQueue的实现类,BlockingQueue接口的实现类类图如下:

下面我们针对常用队列做简单了解:
-
ArrayBlockingQueue:ArrayBlockingQueue是基于数组的阻塞队列,在其内部维护一个定长数组,所以使用ArrayBlockingQueue时必须指定任务队列长度,因为不论对数据的写入或者读取都使用的是同一个锁对象,所以没有实现读写分离,同时在创建时我们可以指定锁内部是否采用公平锁,默认实现是非公平锁。
非公平锁与公平锁
公平锁:多个任务阻塞在同一锁时,等待时长长的优先获取锁
非公平锁:多个任务阻塞在同一锁时,锁可获取时,一起抢锁,谁先抢到谁先执行
-
LinkedBlockingQueue:LinkedBlockingQueue是基于链表的阻塞队列,在创建时可不指定任务队列长度,默认值是Integer.MAX_VALUE,在LinkedBlockingQueue中读锁和写锁实现了分支,相对ArrayBlockingQueue而言,效率提升明显。
-
SynchronousQueue:SynchronousQueue是一个不存储元素的阻塞队列,也就是说当需要插入元素时,必须等待上一个元素被移出,否则不能插入,其适用于任务多但是执行比较快的场景。
-
PriorityBlockingQueue:PriorityBlockingQueue是一个支持指定优先即的阻塞队列,默认初始化长度为11,最大长度为Integer.MAX_VALUE - 8,可以通过让装入队列的对象实现Comparable接口,定义对象排序规则来指定队列中元素优先级,优先级高的元素会被优先取出。
-
DelayQueue:DelayQueue是一个带有延迟时间的阻塞队列,队列中的元素,只有等待延时时间到了才可以被取出,由于其内部用PriorityBlockingQueue维护数据,故其长度与PriorityBlockingQueue一致。一般用于定时调度类任务。
下表从一些角度对上述队列进行了比较:
| 队列名称 | 底层数据结构 | 默认长度 | 最大长度 | 是否读写分离 | 适用场景 |
|---|---|---|---|---|---|
| ArrayBlockingQueue | 数组 | 0 | 开发者指定大小 | 否 | 任务数量较少时使用 |
| LinkedBlockingQueue | 链表 | Integer.MAX_VALUE | Integer.MAX_VALUE | 是 | 大量任务时使用 |
| SynchronousQueue | 公平锁-队列/非公平锁-栈 | 0 | / | 否 | 任务多但是执行速度快的场景 |
| PriorityBlockingQueue | 对象数组 | 11 | Integer.MAX_VALUE-8 | 否 | 有任务需要优先处理的场景 |
| DelayQueue | 对象数组 | 11 | Integer.MAX_VALUE-8 | 否 | 定时调度类场景 |