一.虚拟机安装CentOS7并配置共享文件夹
二.CentOS 7 上hadoop伪分布式搭建全流程完整教程
三.本机使用python操作hdfs搭建及常见问题
四.mapreduce搭建
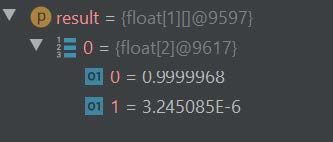
五.mapper-reducer编程搭建
mapreduce搭建
- 一、配置
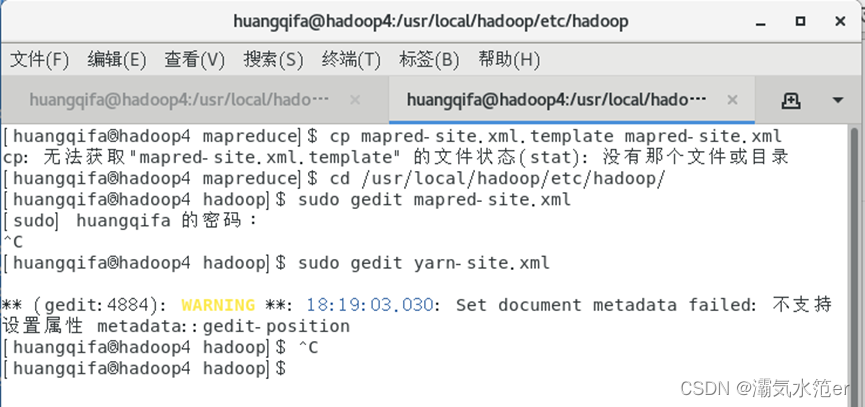
- 1.创建mapred-site.xml文件
- 2.修改配置文件
- 二、打开hadoop
- 0.删除data文件夹
- 1.格式化 namenode
- 2.启动集群
- 3.启动 namenode 和 datanode
- 4.查看服务
- 5.web访问
- 三、执行测试历程
一、配置
1.创建mapred-site.xml文件
cd /usr/local/hadoop/etc/hadoop/
cp mapred-site.xml.template mapred-site.xml
2.修改配置文件
编辑mapred-site.xml
sudo gedit mapred-site.xml
替换
<configuration>
</configuration>
为
<configuration><property><name>mapreduce.framework.name</name><value>yarn</value></property>
</configuration>
修改yarn-site.xml
sudo gedit yarn-site.xml
configuration内容替换如下
<configuration><property><name>yarn.nodemanager.aux-services</name><value>mapreduce_shuffle</value></property>
</configuration>
二、打开hadoop
0.删除data文件夹
删除/home/huangqifa/data(core-site.xml、hdfs-site.xml中的存储路径)
1.格式化 namenode
hadoop namenode -format
2.启动集群
sh /usr/local/hadoop/sbin/start-all.sh
3.启动 namenode 和 datanode
hadoop-daemon.sh start namenode
hadoop-daemon.sh start datanode
4.查看服务
[huangqifa@hadoop4 ~]$ jps
3012 NameNode
3562 ResourceManager
4044 Jps
3869 NodeManager
3374 SecondaryNameNode
3167 DataNode
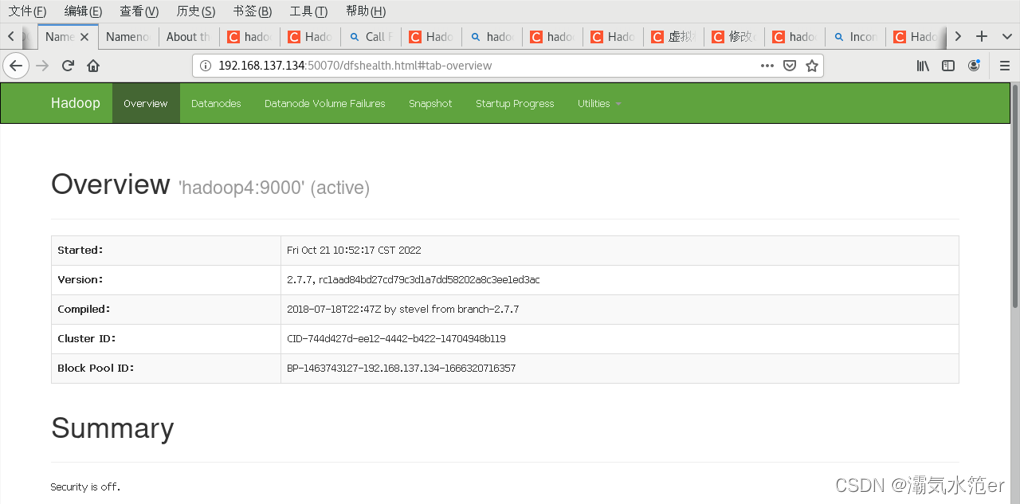
5.web访问
三、执行测试历程
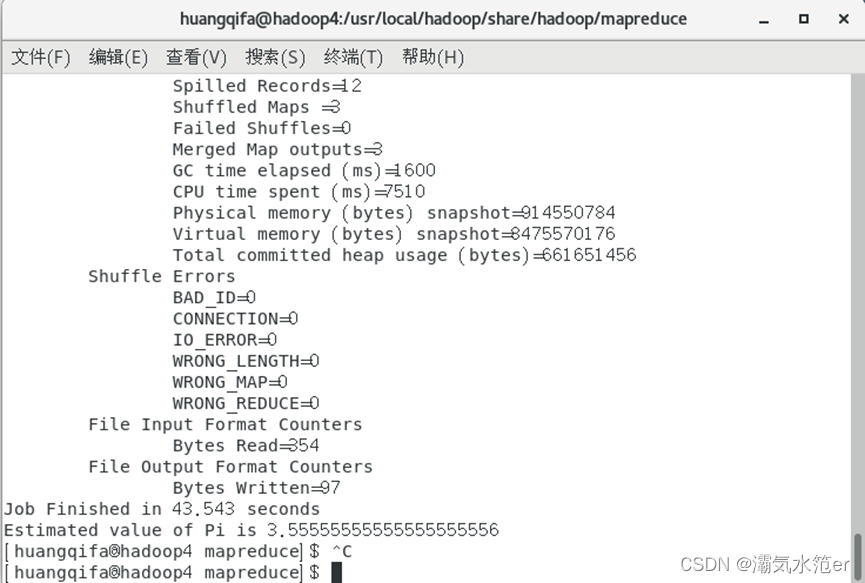
cd /usr/local/hadoop/share/hadoop/mapreduce/
hadoop jar hadoop-mapreduce-examples-2.7.7.jar pi 3 3
其中第一个3的含义是指开启3个map任务,第二个3是每个map里面投掷3次,这两个参数可以修改
参考网址:https://blog.csdn.net/jjjjjjabnannnan/article/details/110239351