JoJoGAN 是一种One-Shot风格迁移模型,可让将人脸图像的风格迁移为另一种风格。
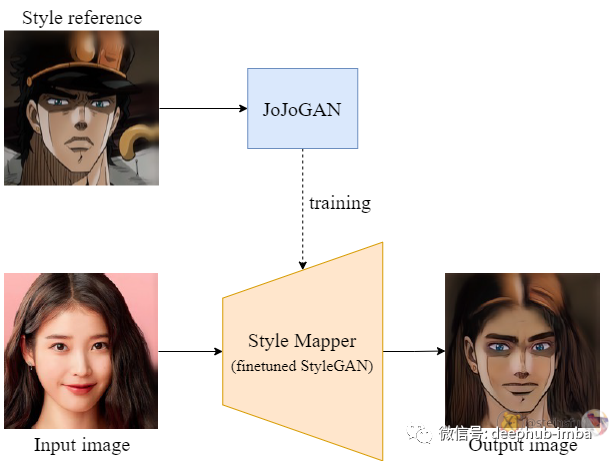
训练时,模型接收一个样式参考图像并快速生成一个样式映射器,在推理时映射器将接受输入并将样式应用于输入,输入图像与样式结合,生成最终图像。
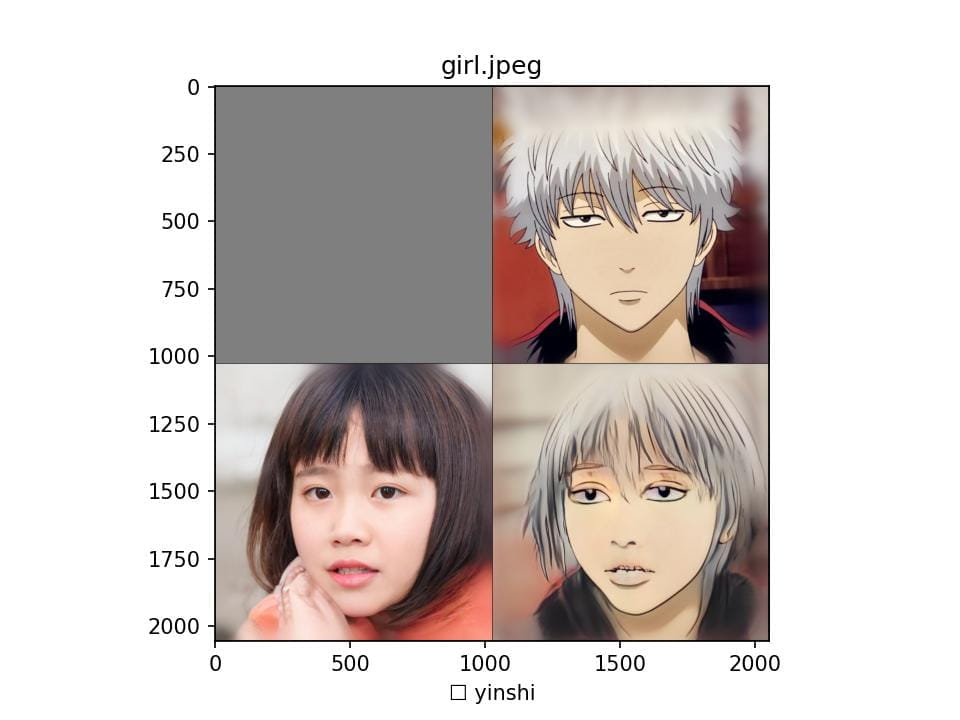
虽然叫做JoJoGAN,但它可以学习任何风格,例如下图。

JoJoGAN 工作流程
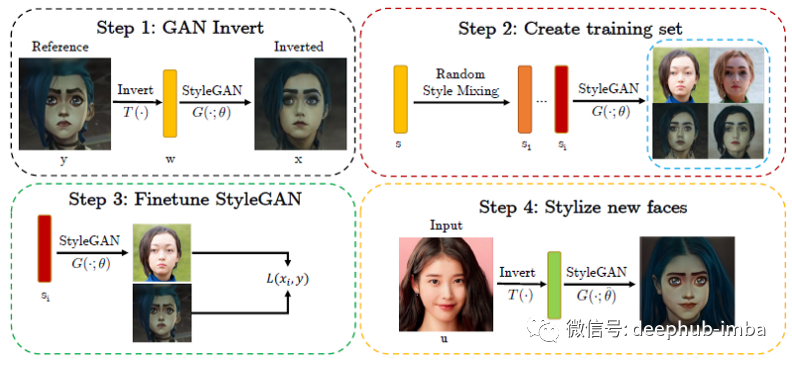
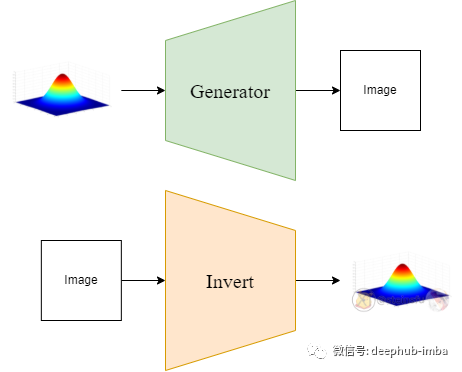
第 1 步:GAN 反演
通常,GAN 从输入的潜在噪声中生成图像。GAN反演意味着从给定的图像中获得相应的潜在噪声。
对样式参考图像 y 进行编码以获得潜在样式代码 w = T(y),然后从中获得一组样式参数 s。
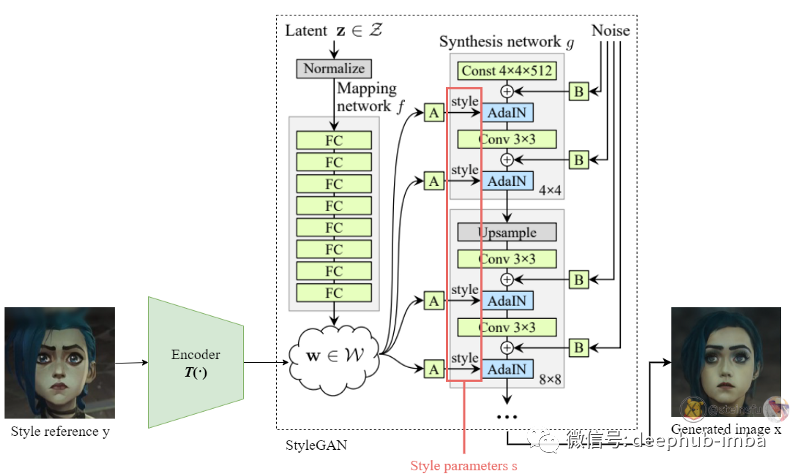
对于 GAN 逆变器(编码器 T)的选择,论文的研究人员比较了 e4e、II2S 和 ReStyle。他们发现 ReStyle 提供了最准确的重建,从而更好地保留了输入的特征和属性。

第 2 步:训练集
通过使用 StyleGAN 的风格混合机制,可以创建一个训练集来微调 StyleGAN。
假设 StyleGAN 有 26 个风格调制层,那么定义一个掩码 M {0, 1}²⁶,它是一个长度为 26 的数组,存储 0 或 1。通过在不同层中打开 (1) 和关闭 (0) M ,我们可以混合 s 和 s(FC(zᵢ)) 为我们的训练集创建许多对 (sᵢ, y)。使用 sᵢ = M · s+(1−M) · s(FC(zᵢ)).生成新的样式代码。
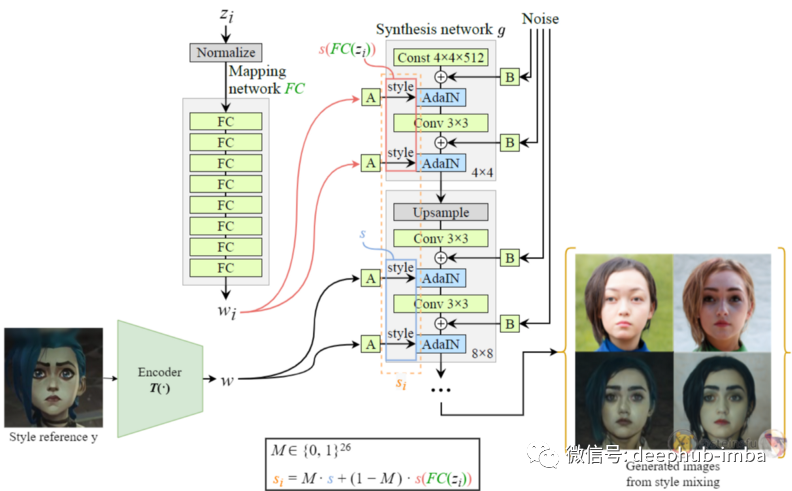
StyleGAN 只是在不同的风格调制层中混合不同的风格代码以创建不同的输出,这里就不详细介绍了,如果又几乎我们再找相关的文章进行详细介绍。
第 3 步:微调
通过使用训练集 s,可以微调 StyleGAN 强制从这些风格混合代码 s 中生成接近风格参考图像 y。
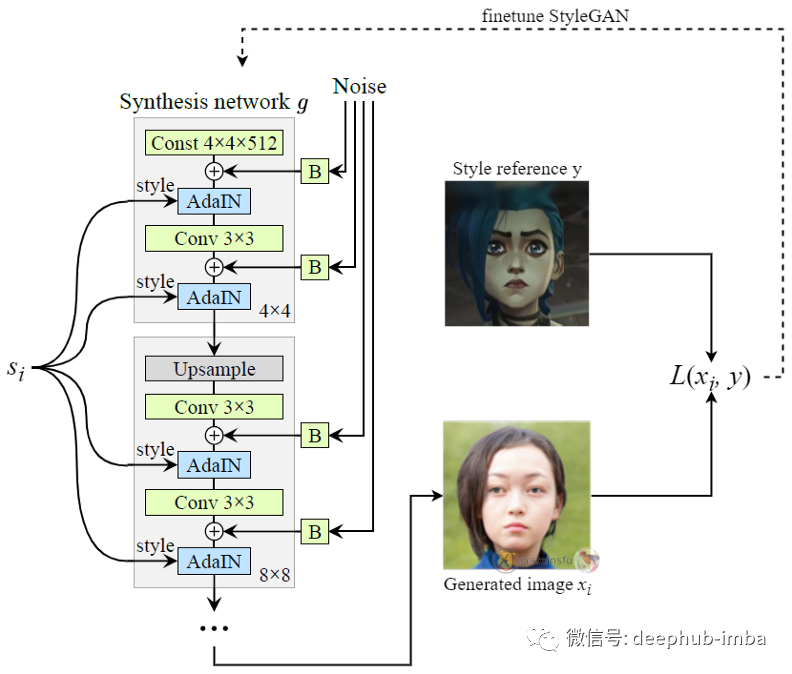
微调步骤就是学习了从任何风格的图像到特定风格的图像的映射(即风格参考 y),但保留了整体空间内容(即该人的面部/身份)。
第 4 步:风格化新面孔
在微调 StyleGAN 之后,可以简单地将输入反转为样式代码,然后使用微调后的 StyleGAN 生成图像(它将目标样式应用于生成的图像)。
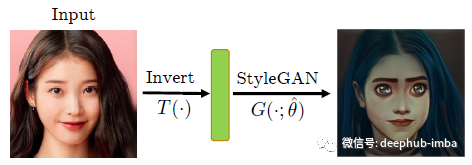
结果展示


看着效果要比其他一些模型好一些。
最后我们再看一下JOJO效果的对比(笑):
虚假的GAN研究:

真实的需求,我们真正需要的风格迁移:


论文地址如下,有兴趣的看看吧
[1] M. Chong and D. Forsyth, “JoJoGAN: One-Shot Face Stylization”, arXiv.org, 2022. https://arxiv.org/abs/2112.11641
源代码也已发布
https://www.overfit.cn/post/12e213388e654d55807c06ffdd37f968
作者:Steins
![【BUUCTF】[WUSTCTF2020]alison_likes_jojo](https://img-blog.csdnimg.cn/7ee8d73f409f4bc69e4656bde92f392a.png#pic_center)