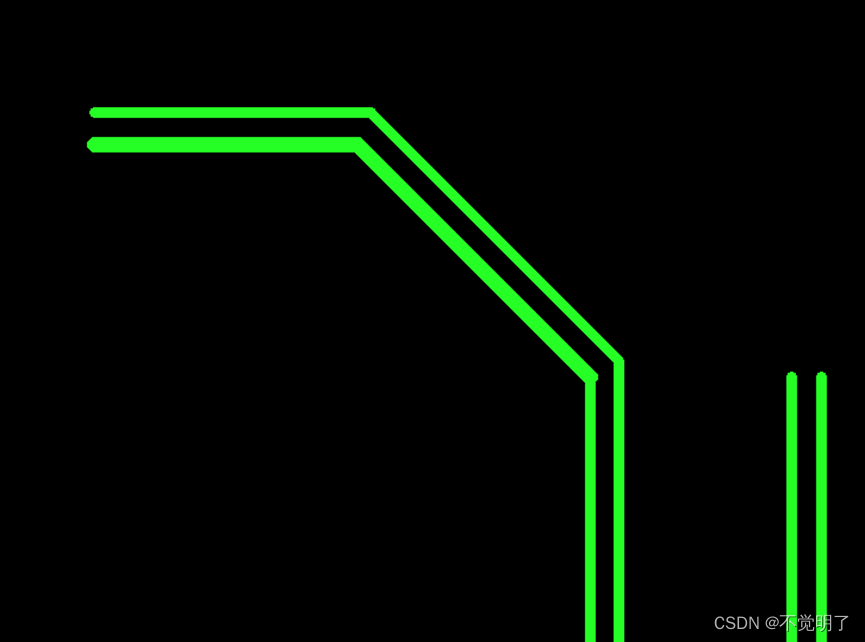
SnowFlake算法生成id的结果是一个64bit大小的整数,它的结构如下图:

- 1bit,不用,因为二进制中最高位是符号位,1表示负数,0表示正数。生成的id一般都是用整数,所以最高位固定为0。
- 41bit时间戳,毫秒级。可以表示的数值范围是 (2^41-1),转换成单位年则是69年。
- 10bit工作机器ID,用来表示工作机器的ID,包括5位datacenterId和5位workerId。
- 12bit序列号,用来记录同毫秒内产生的不同id,12位可以表示的最大整数为4095,来表示同一机器同一时间截(毫秒)内产生的4095个ID序号。
1. 产生背景,为什么要使用雪花算法
现如今越来越多的公司都在用分布式、微服务,那么对应的就会针对不同的服务进行数据库拆分,然后当数据量上来的时候也会进行分表,那么随之而来的就是分表以后id的问题。
例如之前单体项目中一个表中的数据主键id都是自增的,mysql是利用autoincrement来实现自增,而oracle是利用序列来实现的,但是当单表数据量上来以后就要进行水平分表,阿里java开发建议是单表大于500w的时候就要分表,但是具体还是得看业务,如果索引用的号的话,单表千万的数据也是可以的。水平分表就是将一张表的数据分成多张表,那么问题就来了如果还是按照以前的自增来做主键id,那么就会出现id重复,这个时候就得考虑用什么方案来解决分布式id的问题了。
1.1. 解决方法
1.1.1. 数据库表
可以在某个库中专门维护一张表,然后每次无论哪个表需要自增id的时候都去查这个表的记录,然后用for update锁表,然后取到的值加一,然后返回以后把再把值记录到表中,但是这个方法适合并发量比较小的项目,因此每次都得锁表。
1.1.2. redis
因为redis是单线程的,可以在redis中维护一个键值对,然后哪个表需要直接去redis中取值然后加一,但是这个跟上面一样由于单线程都是对高并发的支持不高,只适合并发量小的项目。
1.1.3. uuid
可以使用uuid作为不重复主键id,但是uuid有个问题就是其是无序的字符串,如果使用uuid当做主键,那么主键索引就会失效。
1.1.4.雪花算法
雪花算法是解决分布式id的一个高效的方案,大部分互联网公司都在使用雪花算法,当然还有公司自己实现其他的方案。
2. 雪花算法源码
package com.pxzf.website.utils;import java.util.concurrent.locks.Lock;
import java.util.concurrent.locks.ReentrantLock;public class SnowFlake {/*** 起始的时间戳*/private final static long START_STMP = 1480166465631L;/*** 每一部分占用的位数*/private final static long SEQUENCE_BIT = 12; //序列号占用的位数private final static long MACHINE_BIT = 5; //机器标识占用的位数private final static long DATACENTER_BIT = 5;//数据中心占用的位数/*** 每一部分的最大值*/private final static long MAX_DATACENTER_NUM = -1L ^ (-1L << DATACENTER_BIT);private final static long MAX_MACHINE_NUM = -1L ^ (-1L << MACHINE_BIT);private final static long MAX_SEQUENCE = -1L ^ (-1L << SEQUENCE_BIT);/*** 每一部分向左的位移*/private final static long MACHINE_LEFT = SEQUENCE_BIT;private final static long DATACENTER_LEFT = SEQUENCE_BIT + MACHINE_BIT;private final static long TIMESTMP_LEFT = DATACENTER_LEFT + DATACENTER_BIT;private long datacenterId; //数据中心private long machineId; //机器标识private long sequence = 0L; //序列号private long lastStmp = -1L;//上一次时间戳
// private Lock lock=new ReentrantLock(true);public SnowFlake(long datacenterId, long machineId) {if (datacenterId > MAX_DATACENTER_NUM || datacenterId < 0) {throw new IllegalArgumentException("datacenterId can't be greater than MAX_DATACENTER_NUM or less than 0");}if (machineId > MAX_MACHINE_NUM || machineId < 0) {throw new IllegalArgumentException("machineId can't be greater than MAX_MACHINE_NUM or less than 0");}this.datacenterId = datacenterId;this.machineId = machineId;}/*** 产生下一个ID** @return*/public synchronized long nextId() {long currStmp = getNewstmp();if (currStmp < lastStmp) {throw new RuntimeException("Clock moved backwards. Refusing to generate id");}if (currStmp == lastStmp) {//相同毫秒内,序列号自增sequence = (sequence + 1) & MAX_SEQUENCE;//同一毫秒的序列数已经达到最大if (sequence == 0L) {currStmp = getNextMill();}} else {//不同毫秒内,序列号置为0sequence = 0L;}lastStmp = currStmp;return (currStmp - START_STMP) << TIMESTMP_LEFT //时间戳部分| datacenterId << DATACENTER_LEFT //数据中心部分| machineId << MACHINE_LEFT //机器标识部分| sequence; //序列号部分}private long getNextMill() {long mill = getNewstmp();while (mill <= lastStmp) {mill = getNewstmp();}return mill;}private long getNewstmp() {return System.currentTimeMillis();}
}3. 缺点
由于雪花算法严重依赖时间,所以当发生服务器时钟回拨的问题是会导致可能产生重复的id。