- --数据库多表的连接查询
- 一、外连接
- 1.左连接 left join / left outer join
- 左外连接包含left join 左表里的所有行,若左表在右表没有匹配,则结果中对应
- 行的右表部分全部为空
- select * from student left join course on student.ID =course.ID
- 2. 右连接 right join/ right outer join
- 3. 完全外连接 full join 或 full outer join
- select * from student full join course on student.ID =course.ID
- 二、内连接 join / inner join
- inner join 是比较运算符,返回符合条件的行
- select * from student,cour where student.ID=course.ID;
- 三、交叉连接 cross join
- 第一个表的行数乘以第二个表的行数等于笛卡尔积结果集的大小
- select * from student cross join course
- 若在此sql上加上条件where 语句例如
- select * from student cross join course where student.ID =course.ID
- 则结果和内连接一样
- 四、当两表关系为一对多,多对一,或多对多时
- 例如学生、课程、学生-选课情况,一个学生可以选择多个课程,一个课程也可以被多个学生
- 选择
- 此时student和course就是多对多的关系
- 当满足多对多关系时,需要一个中间表如S-C
- select s.Name, c.Name from
- S_C as sc left join Student as s on s.sno=sc.sno
- left join Course as c on c.cno=sc.cno
- --mysql 查询的五种子句
- 1.where 常用运算符
- 1.1比较运算符:
- 大于> 小于 < 等于= 不等于!= 或<>
- 大于等于>= 小于等于<=
- in (v1,v2……vn)
- between v1 and v2 左右都是闭区间
- 1.2逻辑运算符:
- 逻辑非 not(!)
- 逻辑或 or(||)
- 逻辑与 and(&&)
- 例如:
- where price>=3000 and price<=5000 or price >=500 and pric <=1000
- 或
- where price not between 3000 and 5000
- 1.3 模糊查询
- 像 like
- 通配符: %任意字符 _单个字符
- 例如where goods_name like 'iphone%';
- where goods_name like '诺基亚N_';
- 2. group by 分组, 一般情况下group by 与统计函数一起使用才有意义
- 例如:
- select goods_id,good_name,cat_id,max(shop_price)
- from goods
- group by cat_id;
- 这里因为没有用聚合函数,所以查询语句是有问题的
- MySQL的五种统计函数
- 2.1 max 求最大值
- select max(good_price) from goods group by cat_id-- 取出每个cat里最大的一个值
- select good_id, max(good_price) from goods group by good_id;--查询价格最高的商品编号
- 2.2 min 求最小值
- 2.3 sum 求总数和
- select sum(goods_number) from goods;
- 2.4 avg 求平均值
- select cat_id, avg(good_price) from goods group by cat_id;
- 2.5 count 求总行数
- select cat_id,count(*) from goods group by cat_id;
- --将每个字段名当做变量来理解,可以进行计算
- --1.查询本店每个商品比市场价低多少
- select goods_id,good_name, good_price - market_price from goods;
- --2.查询本店每个栏目下面积压的货款
- select cat_id,sum(goods_price * goods_number) from goods group by cat_id;
- -- 可用as 来给计算结果取别名
- select cat_id,sum(good_price*good_number) as hk from goods group by cat_id;
- 3. having 和where的异同点
- having和where类似,可用来筛选数据,where后的表达式怎么写,having后就怎么写
- 但是
- where 针对表中的列发挥作用,查询数据
- having 针对查询结果中的列发挥作用,筛选数据
- --查询本店商品价格比市场价低多少钱,输出低200元以上的商品,
- --这里不能用where因为s 是查询结果,where只能对表中的字段进行筛选
- select good_id ,good_name, market_price-shop_price as s
- from goods
- having s>200;
- --如果要用where的话应该
- select good_id,good_name from goods
- where market_price-shop_price>200;
- --如果想要同时使用where和having应该怎么做?
- select cat_id,goods_name,market_price - shop_price as s from goods where cat_id = 3 having s > 200;
- --查询货款总和超过2000 的栏目,以及该栏目的积压货款
- select cat_id, sum(shop_price*good_number) as t
- from goods
- group by cat_id
- having s>2000
- --查询两门及两门以上科目不及格的学生的平均分
- (1)先查询 科目不及格的学生名及分数
- select name,score<60 from student;
- (2) 查询两门及两门以上科目不及格 的学生名及不及格科目
- select name, sum(score<60) as bujige from student
- group by name having bujige >1;
- (3) 查询两门及两门以上科目不及格的学生的平均分
- select name, avg(score)as pingjunfen, sum(score<60) as bujige
- from stu group by name
- having bujige>1;
- 4.order by
- 4.1 order by price //默认升序排列
- 4.2 order by pric desc //降序排列
- 4.3 order by price asc //升序
- 4.4 order by rand() //随机排列,效率不高
- --按cat_id 升序排列,按每个cat_id下商品价格降序排列
- select * from goods where cat_id!=2 order by cat_id,price desc
- 5.limit
- limit [offset], N
- offset 偏移量,可选,不写则相当于 limit 0,N
- N 是取出条目
- --取出价格第四-六高的商品(3,3)
- select good_id,good_name,good_price from order by good_price desc limit 3,3;
- --查询每个cat_id 下面最贵的商品
- --先对每个cat_id下的商品排序,将此查询结果放在临时表中
- select cat_id, good_id, good_name, shop_price
- from goods order by cat_id, shop_price desc;
- --再从临时表中选出最贵的商品
- select * form
- (
- select cat_id, good_id, good_name, shop_price
- from goods order by cat_id, shop_price desc
- ) as t group by cat_id;--因为group by 前没有使用聚合函数,所以选取第一行
- ----------------------------------------------------------------
- --MySQL的子查询
- --where型子查询
- select goods_id,goods_name from goods where goods_id =
- (select max(goods_id) from goods);--取出最新产品
- select cat_id,good_id,good_name,from goods where goods_id in
- (
- select max(goods_id) from goods group by cat_id);
- )
- --from 型子查询
- select name,avg(score) from student
- where name in
- (select name from
- (select name, count(*) as bujige from student having
- bujige >=2 and score<60)
- )
- group by name;
- --exists 型子查询
- select cat_id,cat_name from catgory where
- exists
- (select * from goods where goods.cat_id=catgory.cat_id);
- --查询哪些栏目下有商品
- --union 的用法
- (把两次或多次的查询结果合并起来,要求查询的列数一致,推荐查询的对应的列类型一致,可以查询多张表,多次查询语句时如果列名不一样,则取第一次的列名!如果不同的语句中取出的行的每个列的值都一样,那么结果将自动会去重复,如果不想去重复则要加all来声明,即union all)
- ## 现有表a如下
- id num
- a 5
- b 10
- c 15
- d 10
- 表b如下
- id num
- b 5
- c 10
- d 20
- e 99
- 求两个表中id相同的和
- select id,sum(num) from (select * from ta union select * from tb) as tmp group by id;
- //以上查询结果在本例中的确能正确输出结果,但是,如果把tb中的b的值改为10以查询结果的b的值就是10了,因为ta中的b也是10,所以union后会被过滤掉一个重复的结果,这时就要用union all
- select id,sum(num) from (select * from ta union all select * from tb) as tmp group by id;
- #取第4、5栏目的商品,按栏目升序排列,每个栏目的商品价格降序排列,用union完成
- select goods_id,goods_name,cat_id,shop_price from goods where cat_id=4 union select goods_id,goods_name,cat_id,shop_price from goods where cat_id=5 order by cat_id,shop_price desc;
- 【如果子句中有order by 需要用( ) 包起来,但是推荐在最后使用order by,即对最终合并后的结果来排序】
- #取第3、4个栏目,每个栏目价格最高的前3个商品,结果按价格降序排列
- (select goods_id,goods_name,cat_id,shop_price from goods where cat_id=3 order by shop_price desc limit 3) union (select goods_id,goods_name,cat_id,shop_price from goods where cat_id=4 order by shop_price desc limit 3) order by shop_price desc;
sql数据处理,各种条件语句
news/2025/2/12 2:54:17/
相关文章

Qt5.15.2 Webassembly源码裁剪编译
第一步: .\configure -debug-and-release -opensource -prefix "D:\qt-everywhere-src\compFile" -platform win32-g -nomake examples 第二步: mingw32-make -j4 第三步: mingw32-make install 编译core与gui模块&…

layui时间控件单击双击改变状态
文章目录 1️⃣ layui单击隐藏弹出的时间窗2️⃣ layui双击隐藏弹出的时间窗2.1 找到官方的插件2.2 改变引用,加上change函数 优质资源分享 作者:xcLeigh 文章地址:https://blog.csdn.net/weixin_43151418 layui时间控件单击双击改变状态&…
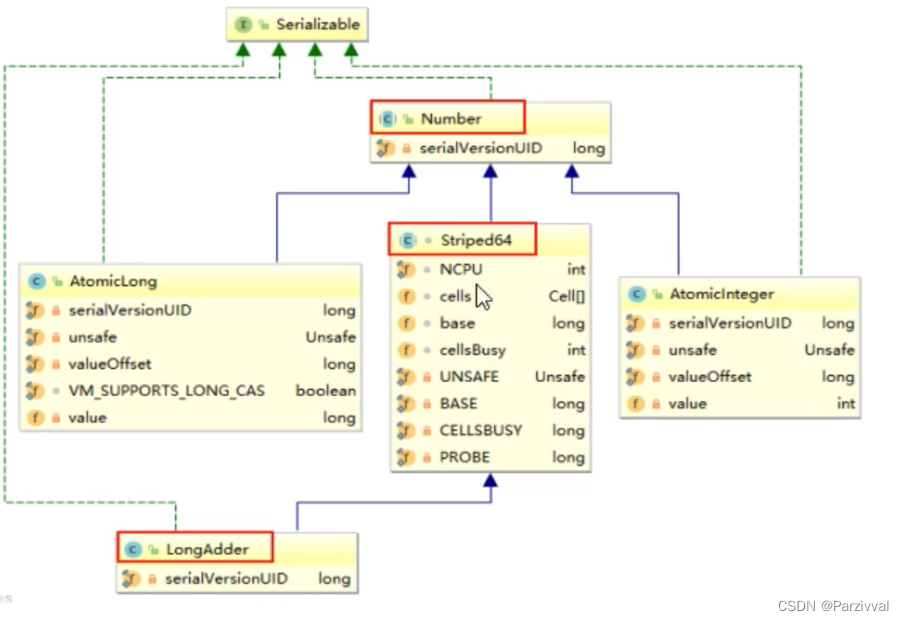
JUC高级-0620
8. CAS
原子类:Atomic没有CAS之前:多线程环境不使用原子类保证线程安全i(基本数据类型),可以使用synchronized,但是很重有CAS之后: 使用AtomicInteger.getAndIncrement这样的API,保…

C++核心编程——详解函数模板
纵有疾风起,人生不言弃。本文篇幅较长,如有错误请不吝赐教,感谢支持。 💬文章目录 一.模板的基础知识①为什么有模板?②初识模板 二.函数模板①函数模板的定义②函数模板的使用③函数模板实例化1️⃣隐式实例化2️⃣显…

最最超级无敌的冷笑话,能把人噎死
最最超级无敌的冷笑话,能把人噎死 图片: 图片: 图片: 图片: 图片: 图片: 图片: Happy new year!!! 感谢河蟹网友魑魅魍魉的投递,原文链接1:从前有个人钓鱼,钓…
冷到冰点的冷笑话(18岁一下慎入)
1.中午和宿舍一兄弟到食堂吃饭,发现旁边餐桌有位低胸劲爆、身材火辣的MM! 我不由得多看了几眼,然后压低声音对兄弟说:“考你道常识题,世界上最大的大象有多重? A:1吨;B࿱…