ARM Cortex-M处理器家族现在有8款处理器成员。在本文中,我们会比较Cortex-M系列处理器之间的产品特性,重点讲述如何根据产品应用选择正确的Cortex-M处理器。本文中会详细的对照Cortex-M 系列处理器的指令集和高级中断处理能力,以及 SoC系统级特性,调试和追踪功能和性能的比较。
1、简介
今天, ARM Cortex-M 处理器家族有8款处理器成员。除此之外,ARM的产品系列还有很多其他的处理器成员。对很多初学者,甚至某些芯片设计经验丰富但是不熟悉ARM系列处理器的设计者来说,也是很容易混淆这些产品的。不同的ARM 处理器有不同的指令集,系统功能和性能。本文会深入展现Cortex-M系列处理器之间的关键区别,以及它们和ARM其他系列处理器的不同。
1.1ARM处理器家族
多年来, ARM已经研发了相当多的不同的处理器产品。 如下图中(图1): ARM 处理器产品分为经典ARM处理器系列和最新的Cortex处理器系列。并且根据应用范围的不同,ARM处理器可以分类成3个系列。
Application Processors(应用处理器)–面向移动计算,智能手机,服务器等市场的的高端处理器。这类处理器运行在很高的时钟频率(超过1GHz),支持像Linux,Android,MS Windows和移动操作系统等完整操作系统需要的内存管理单元(MMU)。 如果规划开发的产品需要运行上述其中的一个操作系统,你需要选择ARM 应用处理器.
Real-time Processors (实时处理器)–面向实时应用的高性能处理器系列,例如硬盘控制器,汽车传动系统和无线通讯的基带控制。多数实时处理器不支持MMU,不过通常具有MPU、Cache和其他针对工业应用设计的存储器功能。实时处理器运行在比较高的时钟频率(例如200MHz 到 >1GHz ),响应延迟非常低。虽然实时处理器不能运行完整版本的Linux和Windows操作系统, 但是支持大量的实时操作系统(RTOS)。
Microcontroller Processors(微控制器处理器)–微控制器处理器通常设计成面积很小和能效比很高。通常这些处理器的流水线很短,最高时钟频率很低(虽然市场上有此类的处理器可以运行在200Mhz之上)。 并且,新的Cortex-M处理器家族设计的非常容易使用。因此,ARM 微控制器处理器在单片机和深度嵌入式系统市场非常成功和受欢迎。
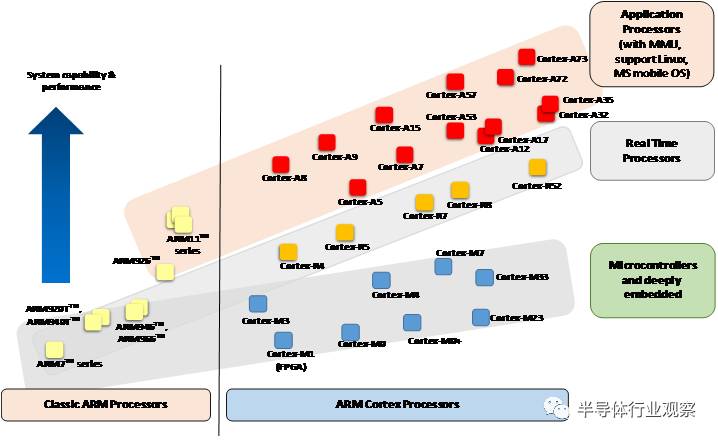
图 1: 处理器家族
表1总结了三个处理器系列的主要特征。
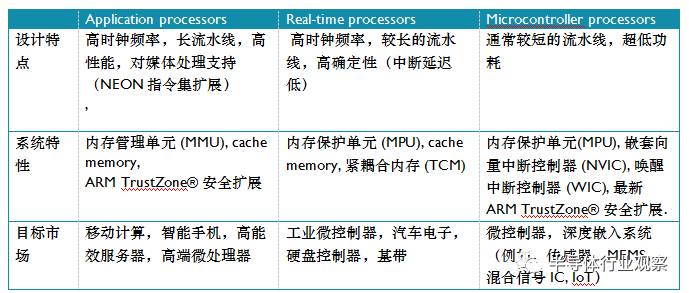
表 1: 处理器特性总结
1.2Cortex-M 处理器家族
Cortex-M处理器家族更多的集中在低性能端,但是这些处理器相比于许多微控制器使用的传统处理器性能仍然很强大。例如,Cortex-M4和Cortex-M7处理器应用在许多高性能的微控制器产品中,最大的时钟频率可以达到400Mhz。
当然,性能不是选择处理器的唯一指标。在许多应用中,低功耗和成本是关键的选择指标。因此,Cortex-M处理器家族包含各种产品来满足不同的需求:

表 2: Cortex-M 处理器家族
不同于老的经典ARM处理器(例如,ARM7TDMI, ARM9), Cortex-M处理器有一个非常不同的架构。例如:
-仅支持ARM Thumb®指令,已扩展到同时支持16位和32位指令Thumb-2版本
-内置的嵌套向量中断控制负责中断处理,自动处理中断优先级,中断屏蔽,中断嵌套和系统异常处理。
-中断处理函数可以使用标准的C语言编程,嵌套中断处理机制避免了使用软件判断哪一个中断需要响应处理。同时,中断响应速度是确定性的,低延迟的
-向量表从跳转指令变为中断和系统异常处理函数的起始地址。
-寄存器组和某些编程模式也做了改变。
这些变化意味着许多为经典ARM处理器编写的汇编代码需要修改,老的项目需要修改和重新编译才能迁移到Cortex-M的产品上。软件移植具体的细节记录在ARM文档:
ARM Cortex-M3 Processor Software Development for ARM7TDMI Processor Programmers
http://www.arm.com/files/pdf/Cortex-M3_programming_for_ARM7_developers.pdf
1.3Cortex-M系列处理器的共同特性
Cortex-M0, M0+, M3, M4 and M7之间有很多的相似之处,例如:
-基本编程模型 (章节 3.1)
-嵌套向量中断控制器(NVIC)的中断响应管理
-架构设计的休眠模式:睡眠模式和深度睡眠模式 (章节 4.1)
-操作系统支持特性 (章节 3.3)
-调试功能 (章节 6)
-易用性
例如,嵌套向量中断控制器是内置的中断控制器
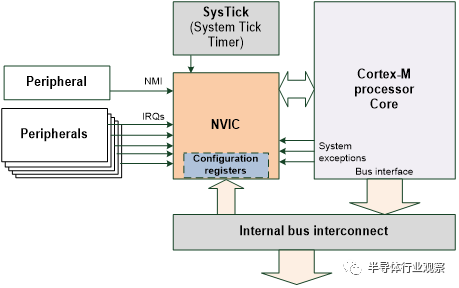
图 2: Cortex-M处理器的嵌套向量中断控制器
支持许多外围设备的中断输入,一个不可屏蔽的中断请求,一个来自内置时钟(SysTick)的中断请求(见章节 3.3)和一定数量的系统异常请求。NVIC处理这些中断和异常的优先级和屏蔽管理。
NVIC以及异常处理模型的更多的内容在章节3.2描述。其他Cortex-M处理器间的异同点会在本文的其余部分讲解。
2、Cortex-M处理器指令集
2.1指令集简介
大多数情况下,应用程序代码可以用C或其他高级语言编写。但是,对Cortex-M 处理器支持指令集的基本了解有助于开发者针对具体应用选择合适的Cortex-M处理器。指令集(ISA)是处理器架构的一部分,Cortex-M处理器可以分为几个架构规范

表 3: Cortex-M 处理器ARM架构规范的规范
所有的Cortex-M 处理器都支持Thumb指令集。整套Thumb指令集扩展到Thumb-2版本时变得相当大。但是,不同的Cortex-M处理器支持不同的Thumb 指令集的子集,如图3所示
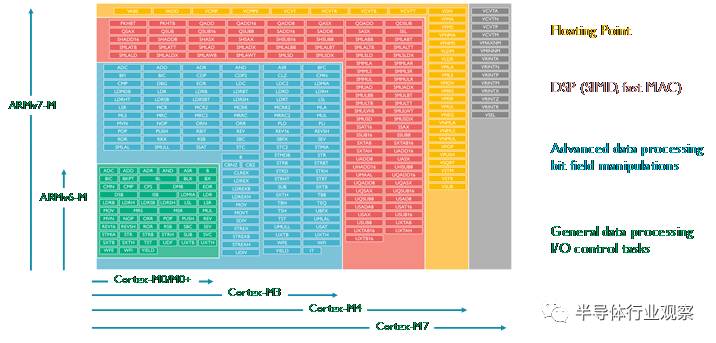

图 3: Cortex-M 处理器的指令集
2.2Cortex-M0/M0+/M1指令集
Cortex-M0/M0+/M1处理器基于ARMv6-M架构。这是一个只支持56条指令的小指令集,大部分指令是16位指令,如图3所示只占很小的一部分。但是,此类处理器中的寄存器和处理的数据长度是32位的。对于大多数简单的I/O控制任务和普通的数据处理,这些指令已经足够了。这么小的指令集可以用很少的电路门数来实现处理器设计,Cortex-M0 和 Cortex-M0+最小配置仅仅12K门。
然而,其中的很多指令无法使用高位寄存器(R8 到R12), 并且生成立即数的能力有限。这是平衡了超低功耗和性能需求的结果。
2.3Cortex-M3指令集
Cortex-M3处理器是基于ARMv7-M架构的处理器,支持更丰富的指令集,包括许多32位指令,这些指令可以高效的使用高位寄存器。另外,M3还支持:
-
查表跳转指令和条件执行(使用IT指令)
-
硬件除法指令
-
乘加指令(MAC)
-
各种位操作指令
更丰富的指令集通过几种途径来增强性能;例如,32位Thumb指令支持了更大范围的立即数,跳转偏移和内存数据范围的地址偏移。支持基本的DSP操作(例如,支持若干条需要多个时钟周期执行的MAC指令,还有饱和运算指令)。最后,这些32位指令允许用单个指令对多个数据一起做桶型移位操作。
支持更丰富的指令导致了更大的面积成本和更高的功耗。典型的微控制器,Cortex-M3的电路门数是Cortex-M0 和 Cortex-M0+两倍还多。但是,处理器的面积只是大多数现代微控制器的很小的一部分,多出来的面积和功耗经常不那么重要。
2.4Cortex-M4指令集
Cortex-M4在很多地方和Cortex-M3相同:流水线,编程模型。Cortex-M4支持Cortex-M3的所有功能,并额外支持各种面向DSP应用的指令,像SIMD, 饱和运算指令,一系列单周期MAC指令(Cortex-M3只支持有限条MAC指令,并且是多周期执行的),和可选的单精度浮点运算指令。
Cortex-M4的SIMD操作可以并行处理两个16位数据和4个8位数据。例如,图4展示的QADD8 和 QADD16 操作:
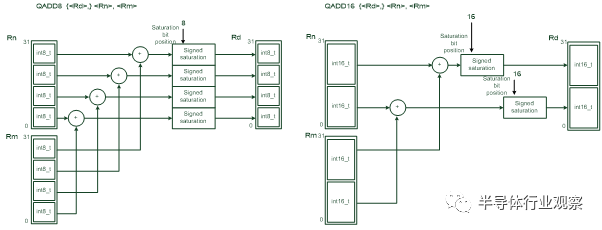
图 4: SIMD指令例子: QADD8 and QADD16
The uses of SIMD enable much faster computation of 16-bit and 8-bit data in certain DSP operations as the calculation can be parallelized. However, in general programming, C compilers are unlikely to utilize the SIMD capability. That is why the typical benchmark results of the Cortex-M3 and Cortex-M4. However, the internal data path of the Cortex-M4 is different from Cortex-M3, which enable faster operations in a few cases (e.g. single cycle MAC, and allow write back of two registers in a single cycle).在某些DSP运算中,使用SIMD可以加速更快计算16位和8位数据,因为这些运算可以并行处理。但是,一般的编程中,C编译器并不能充分利用SIMD运算能力。这是为什么Cortex-M3 和 Cortex-M4典型benchmark的分数差不多。然而,Cortex-M4的内部数据通路和Cortex-M3的不同,某些情况下Cortex-M4可以处理的更快(例如,单周期MAC,可以在一个周期中写回到两个寄存器)。
2.5Cortex-M7指令集
Cortex-M7支持的指令集和Cortex-M4相似,添加了:
-
浮点数据架构是基于FPv5的,而不是Cortex-M4的FPv4,所以Cortex-M7支持额外浮点指令
-
可选的双精度浮点数据处理指令
-
支持缓存数据预取指令(PLD)
Cortex-M7的流水线和Cortex-M4的非常不同。Cortex-M7是6级双发射流水线,可以获得更高的性能。多数为Cortex-M4设计的软件可以直接运行在Cortex-M7上。但是,为了充分利用流水线差异来达到最好的优化,软件需要重新编译,并且在许多情况下,软件需要一些小的升级,以充分利用像Cache这样的新功能。
2.6Cortex-M23指令集
Cortex-M23的指令集是基于ARMv8-M的Baseline子规范,它是ARMv6-M的超集。扩展的指令包括:
-
硬件除法指令
-
比较和跳转指令,32位跳转指令
-
支持TrustZone安全扩展的指令
-
互斥数据访问指令(通常用于信号量操作)
-
16位立即数生成指令
-
载入获取及存储释放指令(支持C11)
在某些情况下,这些增强的指令集可以提高处理器性能,并且对包含多个处理器的SoC设计有用(例如,互斥访问对多处理器的信号量处理有帮助)
2.7I Cortex-M33指令集
因为Cortex-M33设计是非常可配置的,某些指令也是可选的。例如:
-
DSP指令(Cortex-M4 和Cortex-M7支持的)是可选的
-
单精度浮点运算指令是可选的,这些指令是基于FPv5的,并且比Cortex-M4多几条。
: Cortex-M33也支持那些ARMv8-M Mainline引入的新指令:
-
支持TrustZone安全扩展的指令
-
载入获取及存储释放指令(支持C11)
2.8指令集特性比较总结
ARMv6-M, ARMv7-M 和 ARMv8-M架构有许多指令集功能特点, 很难介绍到所有的细节。但是,下面的表格(表4)总结了那些关键的差异。
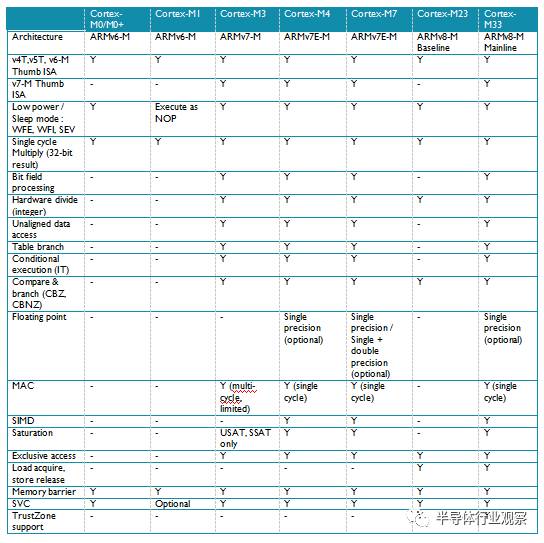
表 4: 指令集特性总结
Cortex-M处理器指令集的最重要的特点是向上兼容。Cortex-M3的指令是Cortex-M0/M0+/M1的超集。所以,理论上讲,如果存储空间分配是一致的,运行在Cortex-M0/M0+/M1上的二进制文件可以直接运行在Cortex-M3上。同样的原理也适用于Cortex-M4/M7和其他的Cortex-M处理器;Cortex-M0/M0+/M1/M3支持的指令也可以运行在Cortex-M4/M7上。
虽然Cortex-M0/M0+/M1/M3/M23处理器没有浮点运算单元配置选项,但是处理器仍然可以利用软件来做浮点数据运算。这也适用于基于Cortex-M4/M7/M33但是没有配置浮点运算单元的产品。在这种情况下,当程序中使用了浮点数,编译工具包会在链接阶段插入需要的运行软件库。软件模式的浮点运算需要更长的运行时间,并且会略微的增加代码大小。但是,如果浮点运算不是频繁使用的,这种方案是适合这种应用的。
3、架构特性
3.1编程模型
Cortex-M处理器家族的编程模型是高度一致的。例如所有的Crotex-M处理器都支持R0到R15,PSR, CONTROL 和 PRIMASK。两个特殊的寄存器— FAULTMASK 和 BASEPRI—只有Cortex-M3, Cortex-M4, Cortex-M7 和 Cortex-M33支持;浮点寄存器组和FPSCR(浮点状态和控制寄存器)寄存器,是Cortex-M4/M7/M33可选的浮点运算单元使用的。
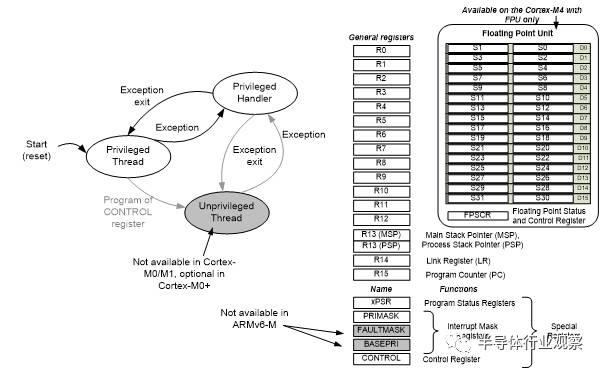
图 5: 编程模型
BASEPRI寄存器允许程序阻止指定优先级或者低的优先级中断和异常。对ARMv7-M来说这是很重要的,因为Cortex-M3, Cortex-M4, Cortex-M7 和 Cortex-M33有大量的优先级等级,而ARMv6-M 和 ARMv8-M Baseline只有有限的4个优先等级。FAULTMASK通常用在复杂的错误处理上(查看章节3.4)
非特权级别的实现对ARMv6-M处理器是可选的,对ARMv7-M 和ARMv8-M处理器一直支持的。对Cortex-M0+处理器,它是可选的, Cortex-M0 and Cortex-M1不支持这个功能。这意味着在各种Cortex-M处理器的CONTROL 寄存器是稍微不同的。FPU的配置也会影响到CONTROL寄存器,如图6所示。
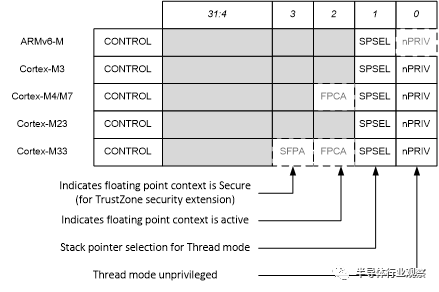
图 6: CONTROL 寄存器
另外一个编程模型之间的不同是PSR寄存器(程序状态寄存器)的细节。所有的Cortex-M处理器,PSR寄存器都被再分成应用程序状态寄存器(APSR),执行程序状态寄存器(EPSR)和中断程序状态寄存器(IPSR)。 ARMv6-M 和 ARMv8-M Baseline系列的处理器不支持APSR的Q位和EPSR的ICI/IT位。ARMv7E-M系列 ( Cortex-M4, Cortex-M7) 和ARMv8-M Mainline (配置了DSP扩展的Cortex-M33 )支持GE位。另外,ARMv6-M系列处理器IPSR的中断号数字范围很小,如图7所示。
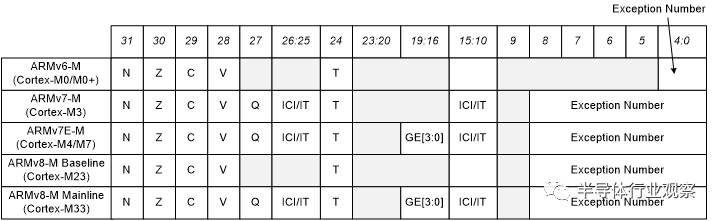
图 7: PSR 差异
请注意Cortex-M的编程模型和ARM7TDMI等这些经典的ARM处理器是不一样的。除了寄存器组不同外,经典ARM处理器中“模式”和“状态”的定义与Cortex-M中的也是不同的。Cortex-M只有两个模式:线程模式(Thread)和管理者模式(Handler),并且Cortex-M处理器一直运行在Thumb状态(不支持ARM指令)
3.2异常处理模型和嵌套向量中断控制器NVIC
所有的Cortex-M处理器都包含了NVIC模块,采用同样的异常处理模型。如果一个异常中断发生,它的优先等级高于当前运行等级,并且没有被任何的中断屏蔽寄存器屏蔽,处理器会响应这个中断/异常,把某些寄存器入栈到当前的堆栈上。这种堆栈机制下,中断处理程序可以编写为一个普通的C函数,许多小的中断处理函数可以立即直接响应工作而不需要额外的堆栈处理花销。
一些ARMv7-M/ARMv8-M Mainline系列的处理器使用的中断和系统异常并不被ARMv6-M/ARMv8-M Baseline的产品支持,如图8. 例如,Cortex-M0, M0+ 和M1的中断数被限制在32个以下,没有调试监测异常,错误异常也只限于HardFault(错误处理细节请参看章节3.4)。相比之下,Cortex-M23, Cortex-M3, Cortex-M4 和Cortex-M7处理器可以支持到多达240个外围设备中断。Cortex-M33支持最多480个中断。
另外一个区别是可以使用的优先等级数量:
ARMv6-M 架构 - ARMv6-M支持2级固定的(NMI 和 HardFault)和4级可编程的(由每个优先等级寄存器的两个位表示)中断/异常优先级。这对大多数的微控制器应用来说足够了。
ARMv7-M 架构 - ARMv7-M系列处理器的可编程优先级等级数范围,根据面积的限制,可以配置成8级(3位)到256级(8位)。ARMv7-M处理器还有一个叫做中断优先级分组的功能,可以把中断优先级寄存器再进一步分为组优先级和子优先级,这样可以详细地制定抢占式优先级的行为。
ARMv8-M Baseline – 类似 ARMv6-M,M23也有2位的优先级等级寄存器。借助可选的TrustZone安全扩展组件,安全软件可以把非安全环境中的中断的优先等级转换到优先等级区间的下半区,这就保证了安全环境中的某些中断/异常总是比非安全环境中的优先级要高。
ARMv8-M Mainline – 类似于 ARMv7-M。 可以支持8到256个中断优先等级和中断优先级分组。还支持ARMv8-M Baseline具有的优先等级调整功能。
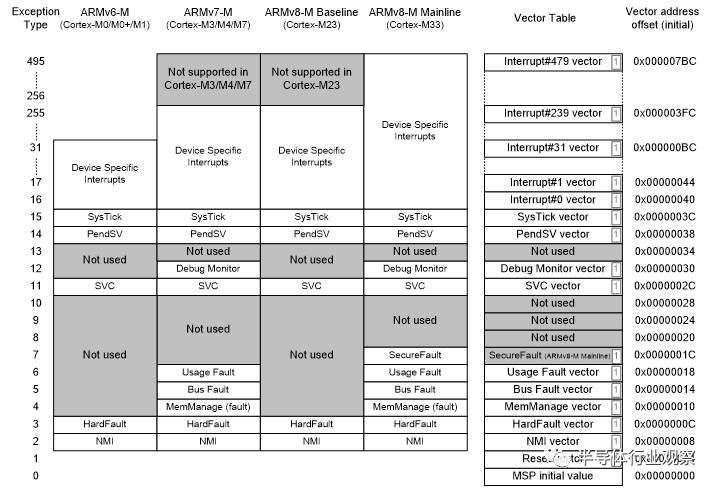
图 8: Cortex-M 处理器异常中断类型
所有的Cortex-M处理器在异常处理是都要依靠向量表。向量表保存着异常处理函数的起始地址(如图8所示)。向量表的起始地址由名为向量表偏移寄存器(VTOR)决定。
-
Cortex-M0+, Cortex-M3 and Cortex-M4 processors: by default the vector table is located in the starting of the memory map (address 0x0). Cortex-M0+, Cortex-M3 and Cortex-M4: 向量表默认放在存储空间的起始地址(地址 0x0)。
-
In Cortex-M7, Cortex-M23 and Cortex-M33 processors: the default value for VTOR is defined by chip designers. Cortex-M23 and Cortex-M33 processors can have two separated vector tables for Secure and Non-secure exceptions/interrupts. Cortex-M7, Cortex-M23 and Cortex-M33:VTOR的初始值由芯片设计者定义。Cortex-M23 and Cortex-M33处理器面向安全和非安全的异常/中断有两个独立的向量表。
-
Cortex-M0 and Cortex-M1 does not implement programmable VTOR and vector table starting address is always 0x00000000. Cortex-M0 and Cortex-M1没有实现可编程的VTOR,向量表起始地址一直为0x00000000。
Cortex-M0+ 和 Cortex-M23处理器的VTOR是可选项。如果VTOR被实现了,向量表的起始地址可以通过设置VTOR来改变,这个功能对下列情况有用:
-
重定位向量表到SRAM来实现动态改变异常处理函数入口点
-
重定位向量表到SRAM来实现更快的向量读取(如果flash存储器很慢)
-
重定位向量表到ROM不同位置(或者Flash),不同的程序运行阶段可以有不同的异常处理程序
不同的Cortex-M处理器之间的NVIC编程模型也有额外的不同。差异点总结在表 5中:
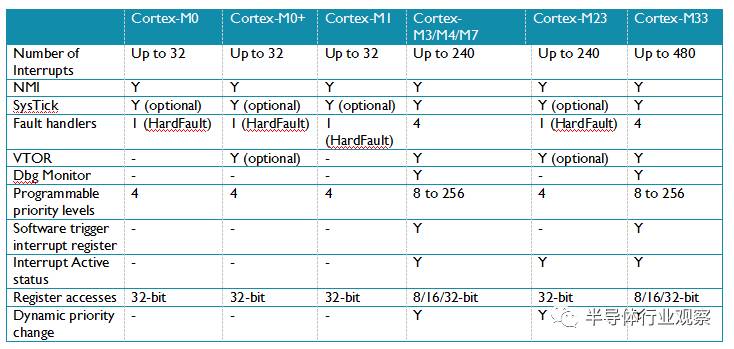
表 5: NVIC 编程模型和特性差异
大部分情况下,对NVIC的中断控制特性的操作都是通过CMSIS-CORE提供的APIs处理的,他们在微控制器厂商提供的设备驱动程序库里。对Cortex-M3/M4/M7/M23/M33处理器,即使中断被使能了,它的优先级也可以被改变。ARMv6-M处理器不支持动态优先等级调整,当你需要改变中断优先等级是,需要暂时的关掉这个中断。
3.3操作系统支持特性
Cortex-M处理器架构在设计时就考虑到了操作系统的支持。针对操作系统的特性有:
-
影子堆栈指针
-
系统服务调用(SVC)和可挂起系统调用(PenSV)异常
-
SysTick – 24位递减计时器,为操作系统的计时和任务管理产生周期性的异常中断
-
Cortex-M0+/M3/M4/M7/M23/M33支持的非特权执行和存储保护单元(MPU)
系统服务调用(SVC)异常由SVC指令触发,他可以让运行在非特权状态的应用任务启动特权级的操作系统服务。可挂起系统调用异常在操作系统中像上下文切换这样的非关键操作的调度非常有帮助。
为了能把Cortex-M1放到很小的FPGA器件中,所有用来支持操作系统的特性对Cortex-M1都是可选的。对Cortex-M0, Cortex-M0+ 和Cortex-M23处理器,系统时钟SysTick是可选的。
通常,所有的Cortex-M处理器都支持操作系统。执行在Cortex-M0+, Cortex-M3, Cortex-M4, Cortex-M7, Cortex-M23 和 Cortex-M33的应用可以运行在非特权运行状态,并且可以同时利用可选的存储器管理单元(MPU)以避免内存非法访问。这可以增强系统的鲁棒性。
3.4TrustZone安全扩展
近几年来, 物联网(IoT)成为了嵌入式系统开发者们的热门话题。IoT系统产品变得更加复杂,上市时间的压力也与日俱增。嵌入式系统产品需要更好的方案来保证系统的安全,但是同时又要方便软件开发者开发。传统的方案是通过把软件分成特权和非特权两部分解决的,特权级软件利用MPU防止非特权的应用访问包含安全敏感信息在内的的关键的系统资源。这种方案对一些IoT系统非常适合,但是在一些情况下,只有两层划分是不够的。特别是那些包含很多复杂特权级别的软件组件的系统,特权级的代码的一个缺陷就可以导致黑客彻底的控制这个系统
ARMv8-M架构包含了一个叫做TrustZone的安全扩展,TrustZone导入了安全和非安全状态的正交划分。
-
普通应用是非安全态
-
软件组件和安全相关的资源(例如,安全存储,加密加速器,正随机数发生器(TRNG))处在安全状态。
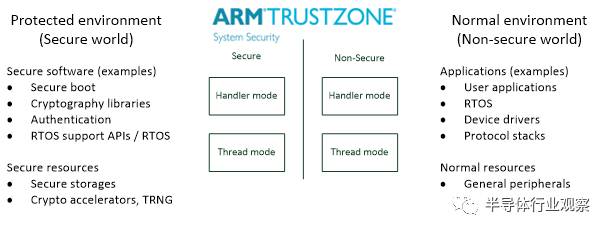
图 9: 安全状态和非安全状态的隔离
非安全状态的软件只能访问非安全状态的存储空间和外围设备,安全软件可以访问两种状态下的所有资源。
用这种方案,软件开发者可以用以往的方式开发非安全环境下的应用程序。同时,他们可以借助芯片厂商提供的安全通讯软件库执行安全物联网连接。并且即使运行在非安全环境的特权级的程序有漏洞,TrustZone安全机制可以阻止黑客控制整个设备,限制了攻击的影响,还可以实现系统远程恢复。此外,ARMv8-M架构也引入了堆栈边界检查和增强的MPU设计,促使额外安全措施的采用。
安全架构定义也扩展到了系统级别,每个中断都可以被设置为安全或者非安全属性。中断异常处理程序也会自动保存和恢复安全环境中的寄存器数据以防止安全信息泄露。所以,TrustZone安全扩展让系统能够支持实时系统的需求,为IoT应用提供了坚实的安全基础,并且容易让软件开发在此技术上开发应用程序。
TrustZone模块对Cortex-M23 and Cortex-M33处理器是可选的。关于ARMv8-M TrustZone更多的信息请查找The Next Steps in the Evolution of Embedded Processors for the Smart Connected Era。更多的TrustZone的资源请查看community.arm.com网站上的“TrustZone for ARMv8-M Community”,
3.5错误处理
ARM处理器和其他架构的微控制器的一个区别是错误处理能力。当错误被检测到时,一个错误异常处理程序被触发去执行恰当的处理。触发错误的情况可能是:
-
未定义的指令(例如,Flash存储器损坏)
-
访问非法地址空间(例如,堆栈指针崩溃)或者MPU非法访问
-
非法操作(例如,当处理器已经在优先级高于SVC的中断中试图触发SVC异常)
错误处理机制使嵌入式系统能够更快的响应各种问题。否则,如果系统死机了,看门狗定时需要非常长的时间重启系统。
ARMv6-M架构中,所有的错误事件都会触发HardFault处理程序,它的优先级是-1(优先级比所有的可编程异常都高,但是仅低于非屏蔽中断NMI)。 所有的错误事件都被认为是不可恢复的,通常我们在HardFault处理程序中仅运行错误报告然后进一步触发自动复位。
ARMv8-M Baseline架构和ARMv6-M类似,只有一个错误异常(HardFault)。但是ARMv8-M Baseline的HardFault优先级可以是-1或者当实现了TrustZone安全扩展时优先级是-3.
ARMv7-M 和 ARMv8-M Mainline产品除了HardFault还有几个可配置的错误异常:
-
Memmanage(内存管理错误)
-
总线错误(总线返回错误的响应)
-
用法错误(未定义指令或者其他的非法操作)
-
SecureFault(只用ARMv8-M Mainline产品支持,处理TrustZone安全扩展中的安全非法操作)
这些异常的优先级可以编程改变,可以单独的打开和关掉。如果需要,它们也可以利用FAULTMASK寄存器把它们的优先级提高到和HardFault相同的级别。ARMv7-M 和 ARMv8-M Mainline产品还有几个错误状态寄存器可以提供关于触发错误异常事件的线索和错误地址的寄存器,用来确定触发这个错误异常的访问地址,使调试更加容易。
ARMv7-M 和 ARMv8-M Mainline产品子规范中额外的错误处理程序提供了灵活的错误处理能力,错误状态寄存器让错误事件的定位和调试更加容易。很多商业开发套件中的调试器已经内嵌了使用错误状态寄存器来诊断错误事件的功能。此外,错误处理程序可以在运行时做一些修复工作。
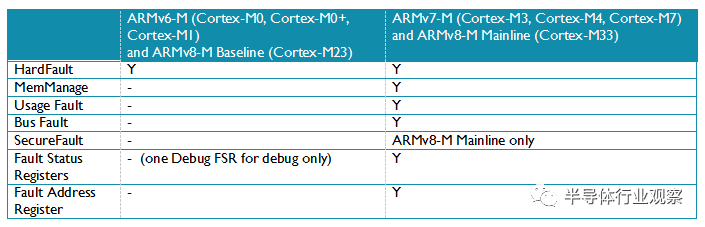
表 6: 错误处理特性比较总结
4、系统特性
4.1低功耗
低功耗是Cortex-M处理器的一个关键优点。低功耗是其架构的组成部分:
-
WFI和WFE指令
-
架构级的休眠模式定义
此外,Cortex-M支持许多其他的低功耗特性:
-
休眠和深度休眠模式:架构级支持的特性,通过设备特定的功耗管理寄存器可以进一步扩展。
-
Sleep-on-exit模式:中断驱动的应用的低功耗技术。开启设置后,当异常处理程序结束并且没有其他等待处理的异常中断时,处理器自动进入到休眠模式。这样避免了额外的线程模式中指令的执行从而省电,并且减少了不必要的堆栈读写操作。
-
唤醒中断控制器(WIC):一个可选的特性,在特定的低功耗状态,由一个独立于处理器的小模块侦测中断情况。例如,在状态保留功耗管理(SRPG)设计中,当处理器被关电的设计。
-
时钟关闭和架构级时钟关闭:通过关闭处理器的寄存器或者子模块的时钟输入来省电
所有这些特性都被Cortex-M0, Cortex-M0+, Cortex-M3, Cortex-M4, Cortex-M7, Cortex-M23 和 Cortex-M33支持。此外,各种低功耗设计技术被用来降低处理器功耗。
因为更少的电路,Cortex-M0 and Cortex-M0+处理器比Cortex-M3, Cortex-M4 和 Cortex-M7功耗低。此外,Cortex-M0+额外优化减少了程序存取(例如跳转备份)来保持系统层级的低功耗。
Cortex-M23没有Cortex-M0 和 Cortex-M0+那么小,但是在相同的配置下,仍然和Cortex-M0+能效一样。
由于更好性能和低功耗优化,在相同配置下,Cortex-M33比Cortex-M4能效比更好。
4.2Bit-band feature位段
Cortex-M3 和Cortex-M4处理器支持一个叫做位段的可选功能,允许有两段通过位段别名地址实现可以位寻址的1MB的地址空间(一段在从地址0x20000000起始的SRAM空间。另一段是从地址0x40000000起始的外围设备空间)。Cortex-M0, M0+ 和 Cortex-M1不支持位段(bit-band)功能,但是可以利用ARM Cortex-M系统设计套件(CMSDK)中的总线级组件在系统层面实现位段(bit-band)功能。Cortex-M7不支持位段(bit-band),因为M7的Cache功能不能与位段一块使用(Cache控制器不知道内存空间的别名地址)。
ARMv8-M的TrustZone 不支持位段, 这是由于位段别名需要的两个不同的地址可能会在不同的安全域中。对于这些系统,外围设备数据的位操作反而可以在外围设备层面处理(例如,通过添加位设置和清除寄存器)。
4.3存储器保护单元(MPU)
除了Cortex-M0, 其他的Cortex-M处理器都有可选的MPU来实现存储空间访问权限和存储空间属性或者存储区间的定义。运行实时操作系统的嵌入式系统, 操作系统会每个任务定义存储空间访问权限和内存空间配置来保证每个任务都不会破坏其他的任务或者操作系统内核的地址空间。Cortex-M0+, Cortex-M3 和 Cortex-M4都有8个可编程区域空间和非常相似的编程模型。主要的区别是Cortex-M3/M4的MPU允许两级的存储空间属性(例如,系统级cache类型),Cortex-M0+仅支持一级。Cortex-M7的MPU可以配置成支持8个或者16个区域,两级的存储空间属性。Cortex-M0 和 Cortex-M1不支持MPU.
Cortex-M23 和 Cortex-M33也支持MPU选项,如果实现了TrustZone安全扩展(一个用于安全软件程序,另一个用于非安全软件程序)可以有最多两个MPU。
4.4单周期I/O接口
单周期I/O接口是Cortex-M0+处理器独特的功能,这使Cortex-M0+可以很快的运行I/O控制任务。Cortex-M大多数的处理器的总线接口是基于AHB Lite或者AHB 5协议的,这些接口都是流水实现总线协议,运行在高时钟频率。但是,这意味着每个传输需要两个时钟周期。单时钟周期I/O接口添加了额外的简单的非流水线总线接口,连接到像GPIO(通用输入输出)这样的一部分设备特定的外设上。结合单周期I/O和Cortex-M0+天然比较低的跳转代价(只有两级流水线),许多I/O控制操作都会比大多数其他微控制器架构的产品运行的更快。
5、性能考虑
5.1通用数据处理能力
在通用微控制器市场,benchmark数据经常用来衡量微控制器的性能,表7是Cortex-M处理器常用benchmark测试的性能数据:
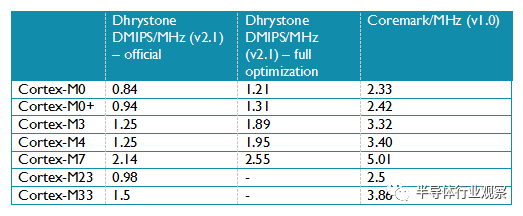
表 7: Cortex-M处理器常用benchmakr的性能分数(来源:CoreMark.org 网站 and ARM 网站)
关于Dhrystone需要注意的是用来测试的Dhrystone是由官方源程序在没有启用inline and 和multi-file compilation编译选项的情况编译出来的(官方分数)。但是,很多微控制器厂商引用的是完全优化编译的Dhrystone测试出来的数据。
但是,benchmark工具的性能测试数据可能无法准确反应你的应用能达到的性能。例如,单周期I/O接口和DSP应用中使用SIMD,或者Cortex-M4/M7中使用FPU的加速效果并没有在这些测试数据中体现出来。
通常,Cortex-M3 和 Cortex-M4由于以下原因提供了更高的数据处理性能:
-
更丰富的指令集
-
哈佛总线架构
-
写缓存(单周期写操作)
-
跳转目标的预测取指
Cortex-M33也是基于哈佛总线的架构,有丰富的指令集。但是不像Cortex-M3 和 Cortex-M4,Cortex-M33处理器流水线是重新设计的高效流水线,支持有限的指令双发射(可以在一个时钟周期中执行最多两条指令)。
Cortex-M7支持更高的性能,这是因为M7拥有双发射六级流水线并支持分支预测。而且,通过支持指令和数据Cache,和即便使用慢速内存(例如,嵌入式Flash)也能避免性能损失的紧耦合内存,来实现更高的系统级性能。
但是,某些I/O操作密集的任务在Cortex-M0+上运行更快,这是因为:
-
更短的流水线(跳转只需要两个周期)
-
单周期I/O端口
当然也有设备相关的因素。例如,系统级设计,内存的速度也会影响到系统的性能。
你自己的应用程序经常是你需要的最好的benchmark。CoreMark分数是另外一个处理器两倍的处理器并不意味着执行你的应用也快一倍。对I/O密集操作的应用来说,设备相关的系统级架构对性能有巨大的影响。
5.2中断延迟
性能相关的另外一个指标是中断延迟。这通常用从中断请求到中断服务程序第一条指令执行的时钟周期数来衡量。表8列出了Cortex-M处理器在零等待内存系统条件下的中断延迟比较。
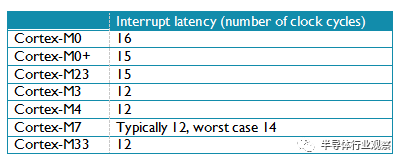
表 8: 零等待内存系统条件下的中断延迟比较
事实上,真正的中断延迟受到内存系统等待状态的影响。例如,许多运行频率超过100Mhz的微控制器搭配的是非常慢的Flash存储器(例如30到50MHz)。虽然使用了Flash访问加速硬件来提高性能,中断延迟仍然受到Flash存储系统等待状态的影响。所以完全有可能运行在零等待内存系统Cortex-M0/M0+系统比Cortex-M3/M4/M7有更短的中断延迟。
当评估性能的时候,不要忘记把中断处理程序的执行时间考虑在内。某些8位或者16位处理器架构可能中断延迟很短,但是会花费数倍的时钟周期完成中断处理。非常短的中断响应时间和很短的中断处理时间才是实际有效的。
6、调试和跟踪特性
6.1调试和跟踪特性简介
不同Cortex-M处理器之间有若干区别。总结在表9中。
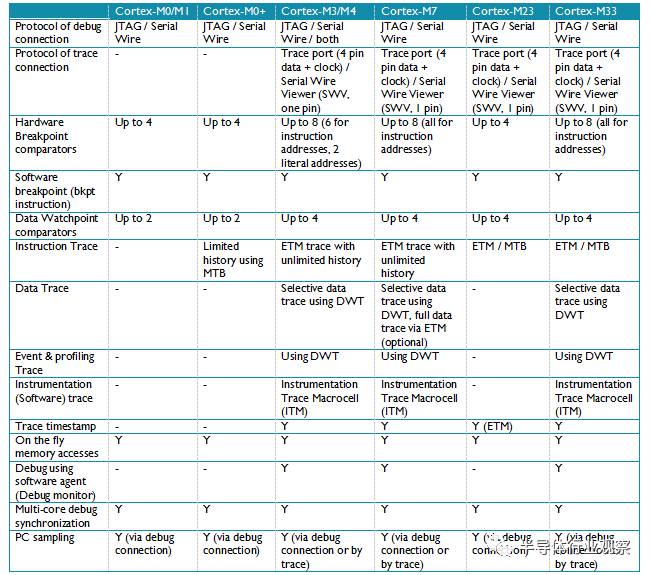
表9: 调试和跟踪特性比较
Cortex-M处理器的调试架构是基于ARM CoreSight调试架构设计的,它是个非常容易扩展的架构,支持多处理器系统。
表9列出的是典型设计需要考虑的。在CoreSight架构下,调试接口和跟踪接口模块是和处理器分离的。因此你采用的设备的调试和跟踪连接和表9的可能不一样。也可能通过添加一些额外的CoreSight调试组件来增加一些调试特性。
6.2Debug connections调试接口
调试接口可以让调试者实现
-访问控制调试和跟踪特性的寄存器。
-访问内存空间。对Cortex-M系列处理器,及时当处理器运行时也可以执行内存空间访问。这被称作实时内存访问。
-访问处理器核心寄存器。这只能当处理器停止的时候才可以操作。
-访问Cortex-M0处理器中微跟踪缓存(MTB)生成的跟踪历史记录。
另外,调试接口也会用作:
-Flash 编程
Cortex-M系列处理器可以选择传统的4到5个引脚(TDI, TDO, TCK, TMS 和可选的 nTRST)的JTAG接口,或者选择新的只需要两个引脚的串行调试协议接口,串行调试接口对有限数目引脚的设备是非常适合的。
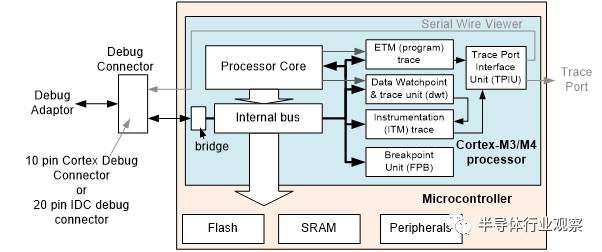
图 10: 串口线或者JTAG调试接口allows access to processor’s debug features and memory space including peripherals
串行线调试协议接口可以处理JTAG支持的所有特性,支持奇偶校验。串行调试协议被ARM工具厂商广泛的采用,许多调试适配器两种协议都支持,串行线型号共享调试接口上TCK和TMS针脚。
6.3跟踪接口
跟踪接口让调试者可以在程序执行时实时的(很小的延时)收集程序运行的信息。收集的信息可以是Cortex-M3/M4/M7/M33支持的嵌入式跟踪单元(ETM)生成的程序指令流信息(指令跟踪),可以是数据跟踪单元(DWT)生成的数据/事件/性能分析信息,或者是软件控制数据跟踪单元(ITM)生成的信息。
有两种类型的跟踪接口可用:
-跟踪端口(Trace port)– 多个数据线加上时钟信号线。比SWV有更高的跟踪带宽,可以支持SWV的所有跟踪类型加上指令跟踪。Cortex-M3/M4/M7或者 Cortex-M33的设备上,跟踪端口通常有4个数据线和一个时钟线。(图11)
-串行监视器(SWV)– 单引脚线跟踪接口,可以选择性的支持数据跟踪,事件跟踪,性能分析和测量跟踪。(图 12)
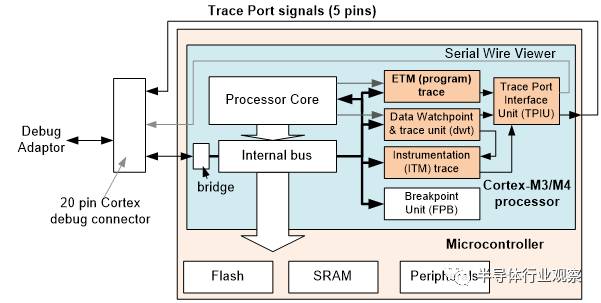
图 11: Trace port 支持指令跟踪和其他跟踪功能必要的带宽
跟踪接口提供了在处理器运行的时候获取大量有用信息的能力。例如嵌入式跟踪单元(ETM)可以获取指令运行历史记录,数据跟踪单元(ITM)让软件产生消息(例如,通过printf)并利用Trace接口获取。另外,Cortex-M3/M4/M7/M33支持数据跟踪单元(DWT)模块。
-可选的数据跟踪:内存地址的信息(例如,地址,数据和时间戳的组合)可以在处理器访问这个地址的时候采集
-性能分析跟踪:CPU在不同操作任务使用的时钟周期数(例如,内存访问,休眠)
-事件跟踪:提供服务器响应的中断/异常的运行时间和历史
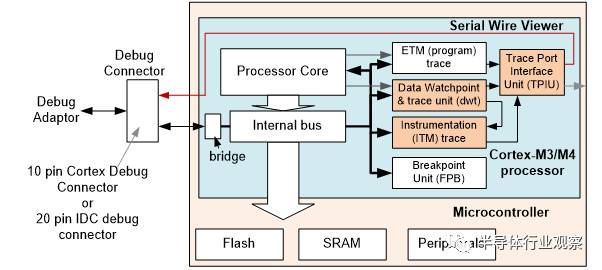
图 12: Serial wire viewer 提供了低成本,少引脚的跟踪方案
这些跟踪特性被各种工具厂商广泛采用,采集的信息也被以各种方式直观的展现出来。例如DWT获取的数据可以在Keil µVision调试器中以波形的方式展现出来(Keil微控制器开发工具的一部分)如图 13所示。
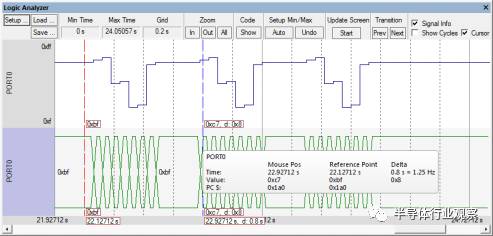
Figure 13: Keil µVision 调试器的逻辑分析器
虽然Cortex-M0 和 Cortex-M0+不支持跟踪接口,Cortex-M0+支持叫做微跟踪缓存的特性(MTB,图14)。MTB让用户分配一小块系统SRAM作为存储指令的缓存,通常设置为循环缓存,这样可以抓取最新的指令执行历史并在调试器上显示出来。
这个MTB跟踪特性也被Cortex-M23 and Cortex-M33支持。
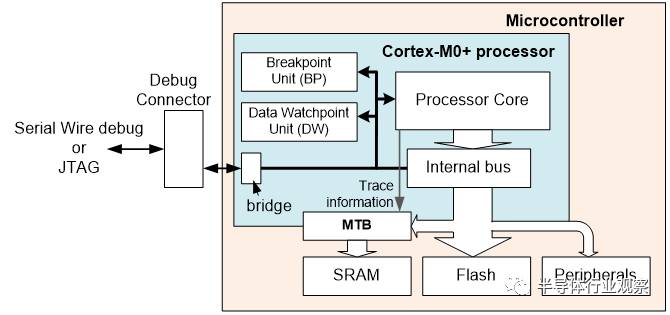
图 14: Cortex-M0+/M23/M33 的MTB提供了低成本指令跟踪方案
7、基于Cortex-M处理器的产品开发
7.1为什么Cortex-M系列处理器容易使用
虽然Cortex-M系列处理器有非常多的特性,但是很容易使用的。例如,差不多所有的开发都可以用像C语言这样的高级编程语言。虽然,基于Cortex-M系列处理器产品都大不相同(例如,有不同大小的内存,不同的外设,性能和封装等等),架构的一致性让开发者一旦对他们其中的一块有开发经验,就很容易开始使用新的Cortex-M处理器。
为了实现更容易的软件开发,更好的软件重用性和可移植性,ARM开发了CMSIS-CORE,这儿CMSIS表示Cortex-Microcontroller Software Interface Standard,CMSIS-CORE通过一组APIs为处理器的各种特性像终端管理控制提供了一个标准的硬件抽象层(HAL), CMSIS-CORE集成在各种微处理器厂商提供的设备驱动程序库里,被各种开发工具套件支持。
除了CMSIS-CORE, CMSIS还包含一个DSP软件库(CMSIS-DSP)。这个库提供了为Cortex-M4 和 Cortex-M7优化过的各种DSP函数,当然也支持其他的Cortex-M系列处理器。CMSIS-CORE 和 CMSIS-DSP库都是免费的,可以从GitHub (CMSIS 4, CMSIS 5)下载到,并被许多工具厂商支持。
7.2处理器选择
对大多数微控制器用户来说,微控制器设备的选择标准主要取决于成本和外设的支持情况。但是,你们中间的很多人可能是为下个芯片产品选择处理器核心芯片设计者,这种情况下,处理器 本身会是考虑的焦点。
明显的,在这样的情况下,性能,芯片面积,功耗和成本会是至关重要的因素。同时,还有各种其他的因素需要考虑。例如,如果你在开发一款互联网连接产品,你也许需要选择有TrustZone安全扩展和MPU的处理器,这样你可以用TrustZone保护关键的安全特性数据,运行某些任务在非特权级别并用MPU来保护内存空间。另一方面,如果你需要在某些方面认证你的产品,Cortex-M23, Cortex-M33, Cortex-M3, Cortex-M4 和 Cortex-M7支持的ETM生成的指令跟踪会对代码覆盖率认证非常有帮助。
在其他的芯片设计领域,如果你正在设计可以运行在能量采集设备供电的小传感器,那么Cortex-M23 和 Cortex-M0+会是最好的选择,因为他们非常小并且做了最先进的功耗优化。
7.3生态系统
使用ARM Cortex-M系列处理器的关键优势之一是广泛的成熟设备,开发工具链和软件库的支持。目前有
-超过15家微控制器厂商正在销售基于ARM Cortex-M系列内核的微控制器产品
-超过10种开发套件支持ARM Cortex-M系列处理器
-40多家操作系统厂商的操作系统支持Cortex-M系列处理器
这给了你大量选择,让你可以获得适合目标应用的最好的设备,开发工具和中间件组合。
8、总结
性能,特性和芯片面积,功耗之间总是需要平衡。为此,ARM开发了各种Cortex-M处理器,拥有不同级别的指令集特性,性能,系统和调试特性。本文介绍了Cortex-M处理器家族各种异同。
虽然存在这差别,但架构的一致性和CMSIS-CORE标准化的APIs都让Cortex-M系列处理器软件有更好的移植性和可重用性。同时,Cortex-M系列处理器非常方便使用。因此,Cortex-M系列处理器很快成为微控制器市场的最受欢迎的32位处理器架构。
额外的资源
Cortex-M系列处理器产品信息可以查找https://developer.arm.com/products/processors/cortex-m
一系列有用的Cortex-M资源存在下面的网址https://community.arm.com/processors/b/blog/posts/cortex-m-resources
关于ARMv8-M TrustZone的其他的有用的资源可以查找ARM社区(community.arm.com)的“TrustZone for ARMv8-M Community”。ARM社区是为开发者和开发工具厂商,产品方案商之间提供的一个免费的,开放的,非正式的交流区