论文题目:Gradient Harmonized Single-stage Detector
论文链接:https://arxiv.org/pdf/1811.05181.pdf
解决
正、负样本简单和困难眼样本之间的不均衡问题,负样本和简单样本数量多。
之前工作
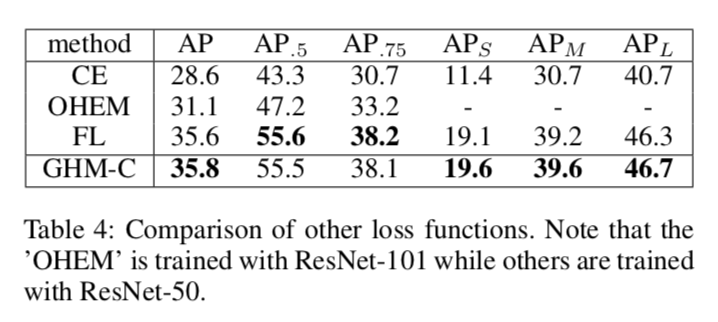
- 基于实例挖掘: 为了解决之前的不平衡问题,基于实例挖掘的方法如OHEM被广泛使用,但它们直接放弃了大部分的例子,训练效率低下。
- Focal Loss: 对于类不平衡,Focal Loss试图通过修改交叉熵损失函数来解决这个问题。然而,Focal loss采用了两个超参数,需要进行大量的调整。它是一种静态损失,不适应数据分布的变化,随训练过程的变化而变化。
提出
类不平衡可以归结为难度的不平衡,难度的不平衡可以归结为梯度范数分布的不平衡。如果正样本好分类,说明是个简单样本,对模型训练的作用很小,产生的梯度很小由于异常值的梯度可能与其他常见的例子有较大的差异,因此可能会影响模型的稳定性。
- 揭示了单阶段检测器在梯度范数分布方面存在显著不平衡的基本原理,并提出了一种新的梯度协调机制(GHM)来解决这一问题。
- 将分类和回归的损失分别嵌入到GHM-C和GHM-R中,修正了不同属性样本的梯度贡献,对超参数具有鲁棒性。
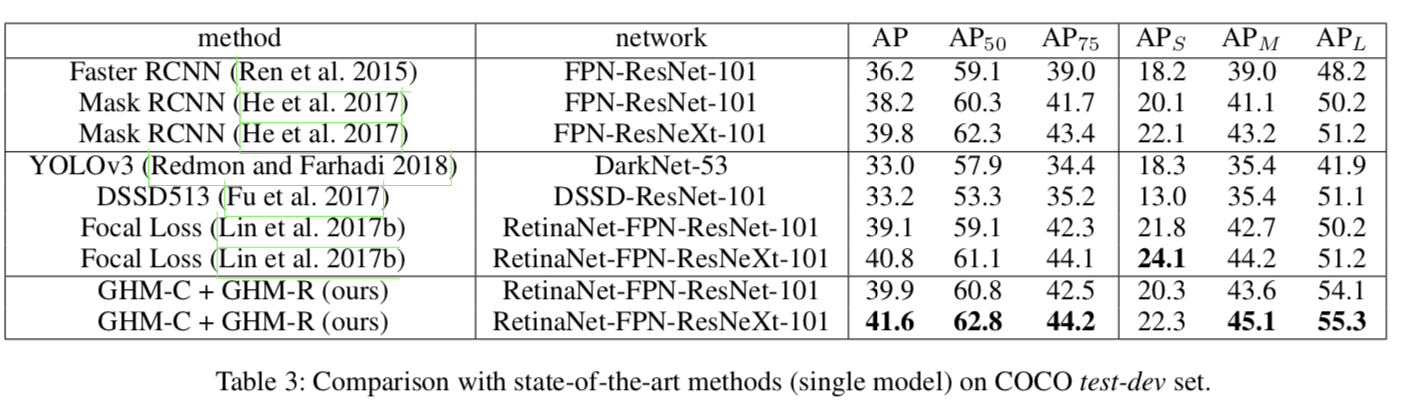
- 通过与GHM的合并,我们可以很容易地训练一个单阶段检测器,而不需要任何数据采样策略,并在COCO基准上实现最优的结果。
CHM-C Loss
梯度范数
- original gradient norm ,即 g = ∣ p − p ∗ ∣ g=|p-p^*| g=∣p−p∗∣。g等于x对应的梯度范数。 g的值表示一个例子的属性(例如easy或hard),表示这个例子对全局梯度的影响。虽然梯度的严格定义是在整个参数空间上,即g是一个例子梯度的相对范数,但为了方便起见,本文将g称为梯度范数。
- N是总共样例的个数。

- 为了更好地理解梯度密度协调参数,可以将其改写为 β i = 1 G D ( g i ) / N \beta_i=\frac{1}{GD(g_i)/N} βi=GD(gi)/N1,分母 G D ( g i ) / N GD(g_i)/N GD(gi)/N是一个标准化器指示了邻域梯度到第i个样本的样本分数。如果样例关于梯度均匀分布,对任何 g i g_i gi,$ GD(g_i)=N$,每个样例有相同的 β i = 1 \beta_i=1 βi=1,这意味着什么都没有改变。否则,密度较大的算例将被归一化器相对降权。
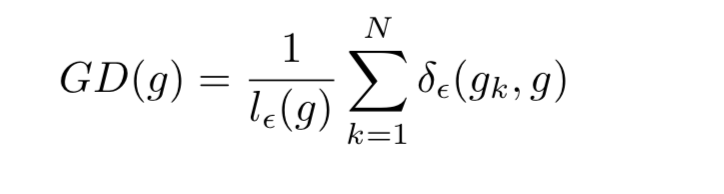
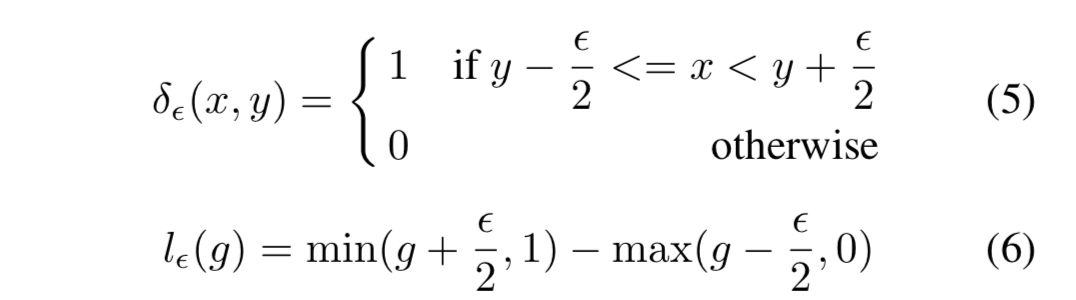
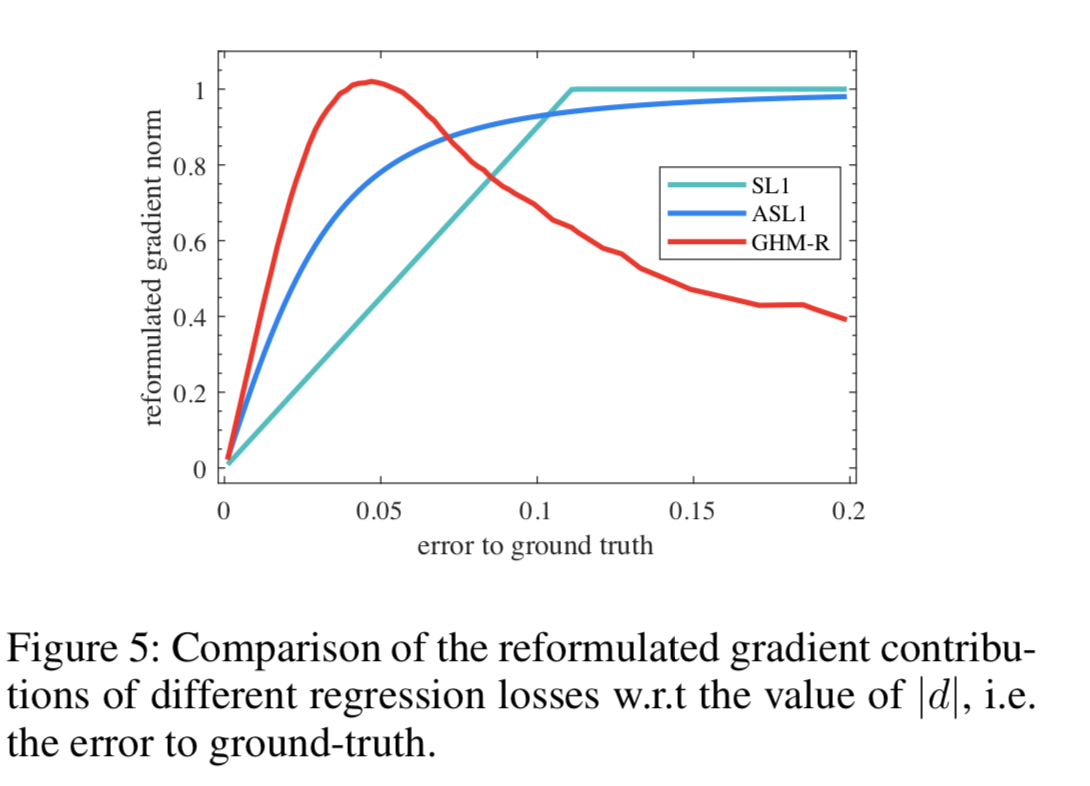
- 可以看到Focal Loss和GHM-C损失的曲线有相似的趋势,这意味着CHM-C Loss与设置的最好参数的focal loss 都有均匀梯度协调的优点。 此外,GHM-C还有一个特别的优点:降低了异常值梯度贡献的权重。
- CHM-C Loss降低了大量简单样本和异常样本的权重。由于梯度密度是每次迭代计算得到的,所以权值是随着训练动态改变适应的。
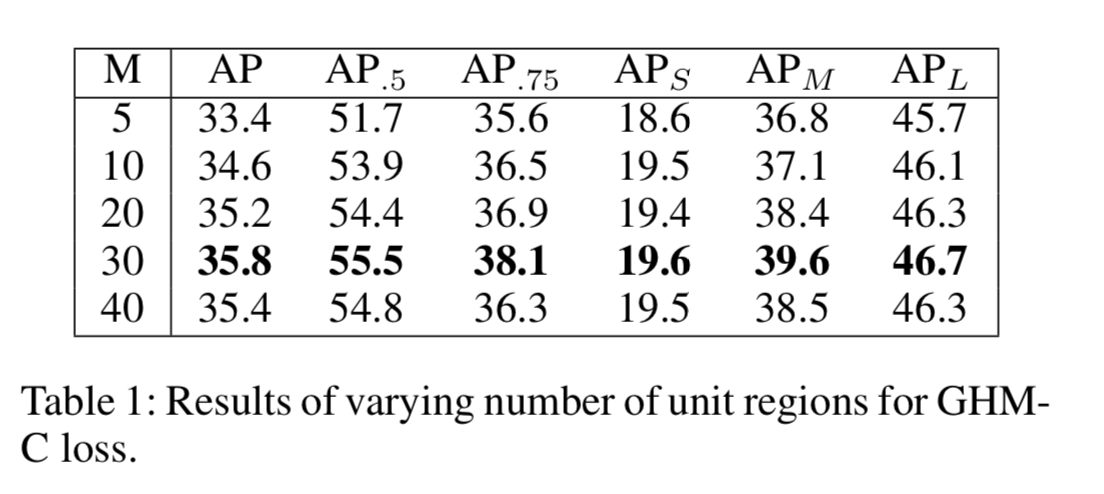
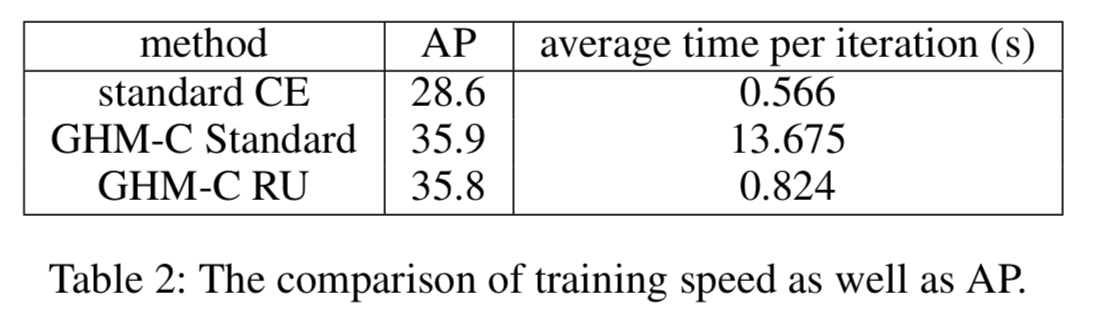
 - 单位区域近似 1、朴素的计算复杂度:$O(n^2)$ 2、最好算法也是先对 样本gradient norm 进行排序,复杂度$O(NlogN)$然后使用队列扫描样本,得到样本的密度。 $O(N)$ 3、因为图片数量一般比较大,直接计算梯度密度费时。提出近似计算。
- 单位区域近似 1、朴素的计算复杂度:$O(n^2)$ 2、最好算法也是先对 样本gradient norm 进行排序,复杂度$O(NlogN)$然后使用队列扫描样本,得到样本的密度。 $O(N)$ 3、因为图片数量一般比较大,直接计算梯度密度费时。提出近似计算。
单元区域
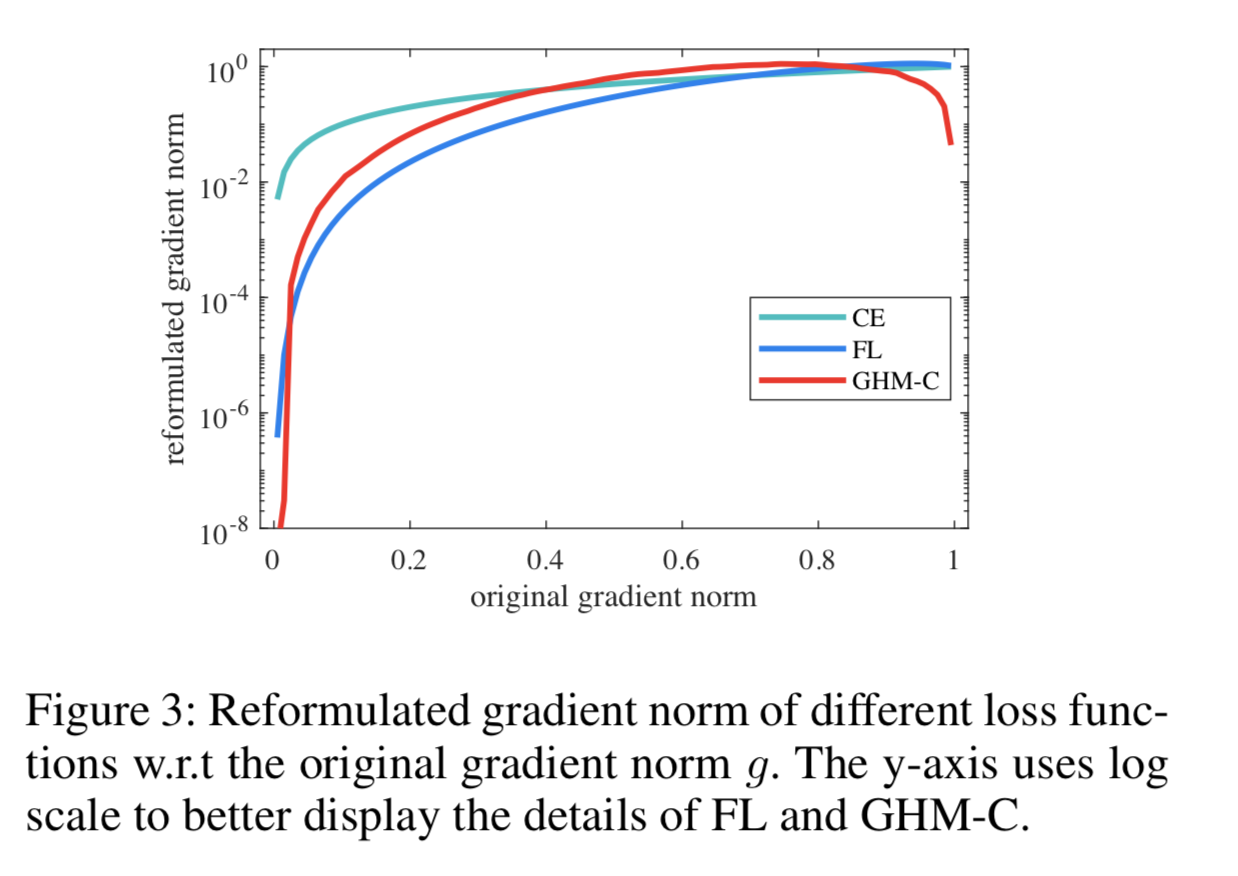
- 将g的值域空间划分为长度为 ε \varepsilon ε的单位区域,即有 M = 1 / ε M=1/\varepsilon M=1/ε个单位区域。
- r j r_j rj是第j个的区域,即 r j = [ ( j − 1 ) ε , j ε ] r_j=[(j-1)\varepsilon,j\varepsilon] rj=[(j−1)ε,jε]
- R j R_j Rj代表 r j r_j rj中的样本个数
- 定义 i n d ( g ) = t ind(g)=t ind(g)=t,即 ( t − 1 ) ε < = g < t ε (t-1)\varepsilon<= g < t\varepsilon (t−1)ε<=g<tε
- 定义近似梯度密度函数:
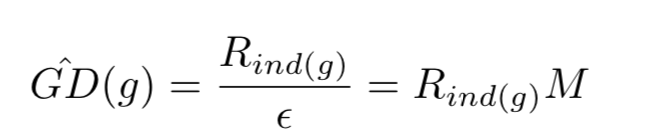
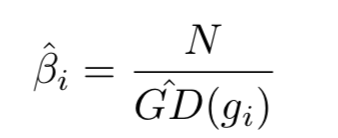
if 单位区域代表的样本少,GD小, β \beta β 大
特殊情况 ε = 1 \varepsilon=1 ε=1,只有一个单位区域,所有的样本都在里面, β = 1 \beta=1 β=1 ,保持原始梯度贡献。
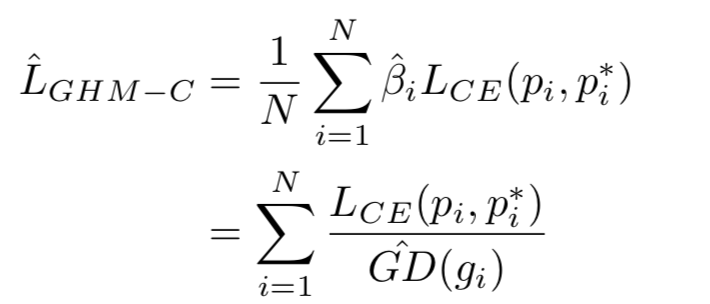
EMA
类似SGD的动量,考虑之前迭代信息。
- 基于小批量统计的方法通常面临一个问题:当大量的极端数据在一个小批量中采样时,统计结果会产生严重的噪声,训练不稳定。
- 由于在近似算法中梯度密度来自于单元区域内的样本个数,在每个单元上应用EMA来获得更加稳定的梯度密度。
- R j ( t ) R_j^{(t)} Rj(t)第j个单元的第t次迭代中的样本数。
- S j ( t ) S_j^{(t)} Sj(t)为滑动平均数
- α \alpha α是动量参数
- 使用EMA,梯度变化更加平滑并且对极端数据更加敏感。
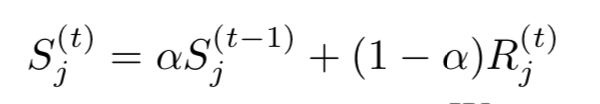
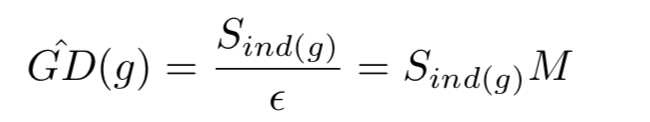
GHM-R loss
-
smooth L1
-
δ \delta δ是在二次部分和线性部分之间的分界点,在实际中通常设为1/9
-
d = t i − t i ∗ d=t_i-t_i^* d=ti−ti∗
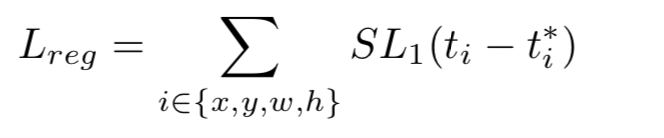
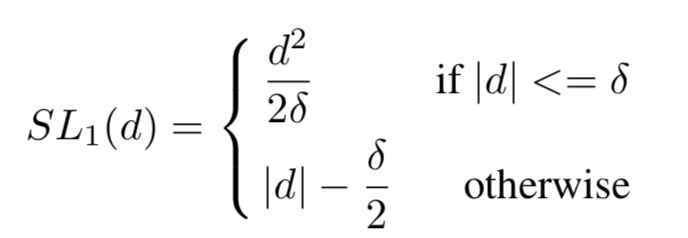
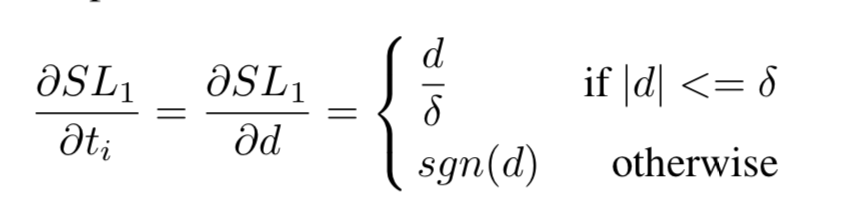
-
如果所有样本的 d d d大于 δ \delta δ,具有相同的梯度密度。这使得如果依赖梯度范数区分不同属性的例子变得不可能。一个可以替代的选择是直接使用|d|作为不同属性的度量,但新的问题是|d|在理论上可以达到无穷大,不能实现单位区域近似。
-
将传统的SL1损失修改为更简洁的形式。当d很小的时候,近似二次函数,当d很大的时候近似线性
-
μ \mu μ设置为0.02
-
GHM-R损失可以通过增加简单样本的重要部分的权重和降低异常值的权重来协调简单样本和困难样本对box回归的贡献
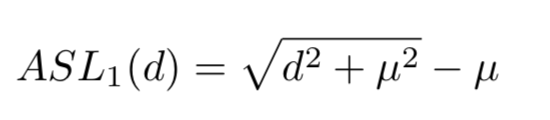
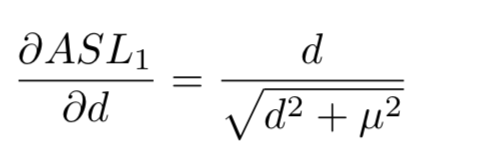
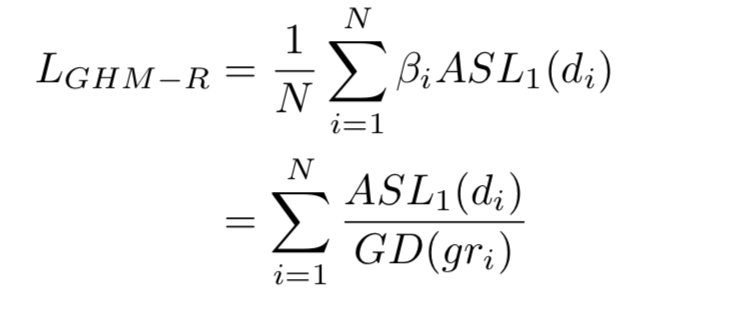
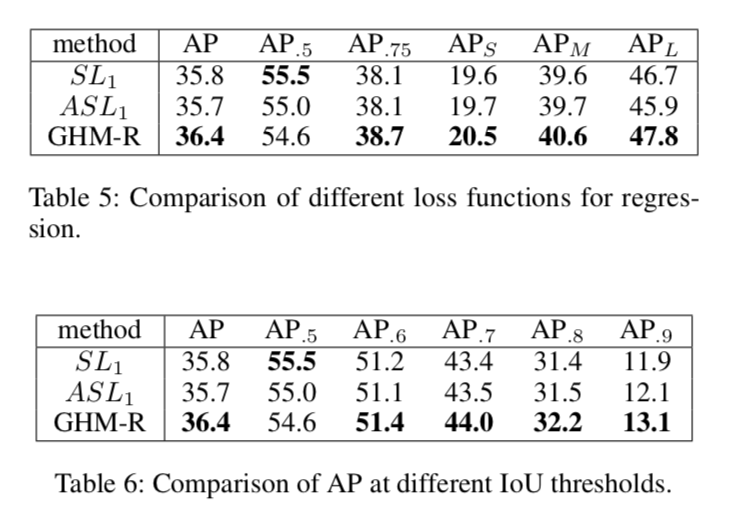
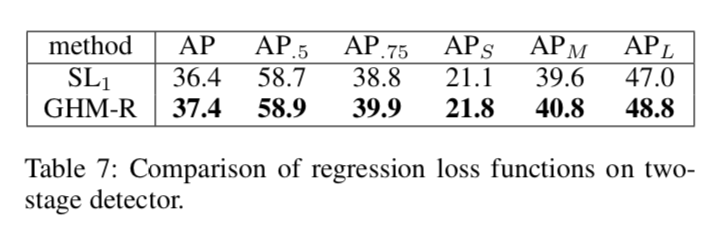
实验
采用RetinaNet+ResNet+FPN作为网络架构