注1:本文系“简要介绍”系列之一,仅从概念上对图像聚类进行非常简要的介绍,不适合用于深入和详细的了解。
图像聚类:概念、原理与方法
Cluster Analysis | NVIDIA Developer
1. 背景介绍
图像聚类(Image Clustering)是一种无监督学习方法,主要用于将相似的图像分组到同一个类别。这种技术在计算机视觉、机器学习和数据挖掘等领域具有广泛的应用,例如图像搜索、图像分割、图像压缩、异常检测等。
2. 原理介绍与推导
2.1 特征提取
在进行图像聚类之前,首先需要从图像中提取特征。特征提取的方法有很多,主要包括:
- 颜色特征:例如颜色直方图、颜色矩等;
- 纹理特征:例如灰度共生矩阵、局部二值模式等;
- 形状特征:例如轮廓、Hu矩等;
- 深度学习特征:例如卷积神经网络(CNN)提取的特征。
2.2 距离度量
在特征提取之后,需要选择一个合适的距离度量方法来衡量图像之间的相似度。常用的距离度量方法有:
- 欧氏距离(Euclidean Distance)
- 曼哈顿距离(Manhattan Distance)
- 余弦相似度(Cosine Similarity)
- 马氏距离(Mahalanobis Distance)
2.3 聚类算法
有了特征表示和距离度量,接下来就可以利用聚类算法将相似的图像分到同一个类别。常用的聚类算法有:
- K-means算法:基于划分的聚类方法,通过迭代更新,最小化每个类别内的样本与中心的距离之和。
- 层次聚类(Hierarchical Clustering):通过不断地将最近的两个类别合并,最终形成一个层次结构。
- 密度聚类(Density-Based Clustering):例如DBSCAN,通过密度连接将相似的图像分到同一个类别。
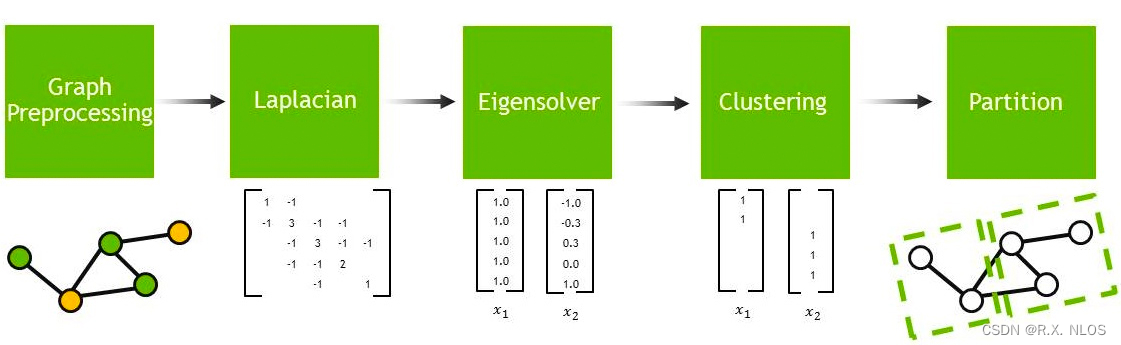
- 谱聚类(Spectral Clustering):基于图论的聚类方法,通过对图的拉普拉斯矩阵进行谱分解,最终得到聚类结果。
3. 研究现状
随着深度学习的发展,图像聚类方法也取得了显著的进步。近年来,研究者提出了许多基于神经网络的图像聚类方法,例如:
- 深度聚类(Deep Clustering):利用深度神经网络学习图像的特征表示,并将聚类任务与特征提取任务同步进行,以达到端到端的训练效果。
- 自监督学习(Self-supervised Learning):通过设计一些预先定义的任务,使得神经网络在训练过程中自动学习到有用的特征表示,从而为后续的聚类任务提供有力支持。
4. 挑战
尽管图像聚类方法取得了很多进展,但仍然面临一些挑战,例如:
- 高维数据:图像数据通常具有高维度,这会导致计算复杂度增加、距离度量失效等问题。
- 数据不平衡:在实际应用中,很多数据集的类别分布是不平衡的,这可能导致聚类结果偏向于少数类别。
- 可解释性:深度学习方法在提高聚类效果的同时,往往牺牲了一定的可解释性。
5. 未来展望
图像聚类作为计算机视觉和机器学习领域的一个重要研究方向,将继续吸引研究者的关注。未来的研究可能会关注以下几个方向:
- 多模态数据聚类:将图像与其他模态的数据(例如文本、音频等)结合起来进行聚类,以提高聚类效果。
- 可解释性与鲁棒性:研究更具有可解释性和鲁棒性的聚类方法,以应对现实环境中的复杂挑战。
- 在线学习与增量学习:针对动态变化的数据流,研究在线学习和增量学习的聚类方法。
6. 代码示例
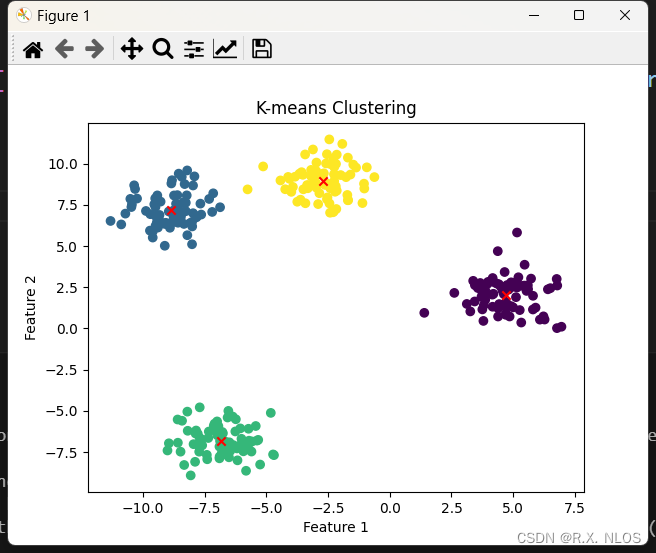
下面是一个使用Python和scikit-learn库实现K-means算法的简单示例:
import numpy as np
import matplotlib.pyplot as plt
from sklearn.cluster import KMeans
from sklearn.datasets import make_blobs# 生成示例数据
data, labels = make_blobs(n_samples=300, centers=4, random_state=42)# 使用K-means聚类
kmeans = KMeans(n_clusters=4, random_state=42)
kmeans.fit(data)# 可视化聚类结果
plt.scatter(data[:, 0], data[:, 1], c=kmeans.labels_, cmap='viridis')
plt.scatter(kmeans.cluster_centers_[:, 0], kmeans.cluster_centers_[:, 1], c='red', marker='x')
plt.title('K-means Clustering')
plt.xlabel('Feature 1')
plt.ylabel('Feature 2')
plt.show()