MI-SegNet: Mutual Information-Based US Segmentation for Unseen Domain Generalization
摘要
- 解决医学成像泛化能力
- 提出了一种新的基于互信息(MI)的框架MI- segnet
- 分离解剖结构和领域特征
- 采用两个编码器提取相关特征:两个特征映射中出现的任何MI都将受到惩罚,以进一步促进单独的特征空间
- 分割只使用解剖特征图进行预测
- 训练过程中使用了交叉重建方法
- 代码链接
引言
领域自适应:网络可泛化到与源域不同的目标域
特征解耦(Feature Disentanglement):许多研究人员没有直接在图像级别上解决域适应问题,而是专注于在潜在空间中解耦特征
互信息:测量两个随机变量之间共享信息的数量
方法
目标:训练一个分割网络,它可以泛化到未见的领域,并作为下游任务的良好预训练模型,而训练数据集只包含来自单个领域的图像
思路:
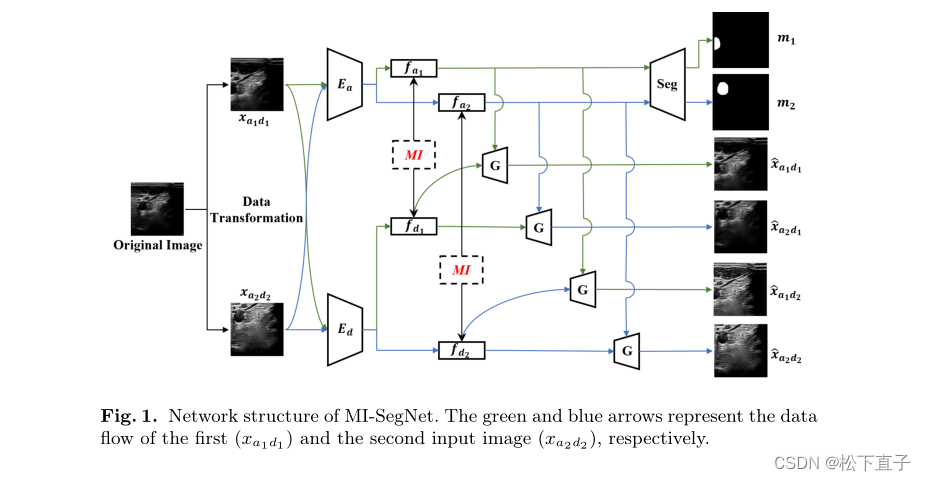
- 对于每个图像进行参数转换,两组参数用于空间(a1, a2)和域(d1, d2)转换
- 单个输入,根据空间和域配置参数的四种可能组合,创建四张转换后的图像(xa1d1, xa2d2, xa1d2, xa2d1)
- 使用两个编码器(Ea, Ed)分别提取解剖特征(fa1, fa2)和结构域特征(fd1, fd2)
- 使用互信息神经估计器(MINE)计算从同一图像中提取的解剖特征和域特征之间的互信息,并在训练过程中最小化
- 仅使用解剖特征来预测分割掩模(m1, m2)
- 然后将提取的解剖和域特征结合起来,输入到生成器网络(G)中,相应地重建图像(bxa1d1, bxa1d2, bxa2d1, bxa2d2)
- 转换后的图像中只有两张(xa1d1, xa2d2)被输入到网络中,而另外两张(xa1d2, xa2d1)仅用作重建的ground truth
互信息
MI定义为联合分布与随机变量fa和fd的边际分布乘积之间的Kullback-Leibler (KL)散度:
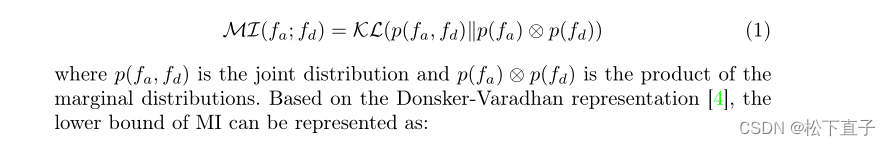

为了迫使结构编码器和域编码器提取解耦的特征,MI被作为一个损失来更新这两个编码器网络的权重:

分割和重建
分割损失:
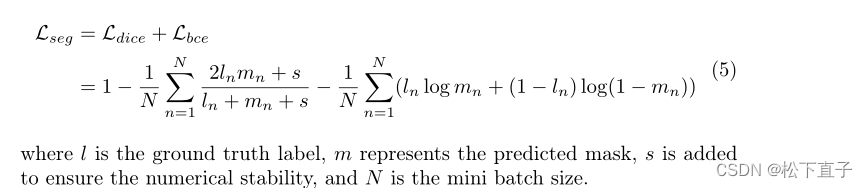
重建损失函数:
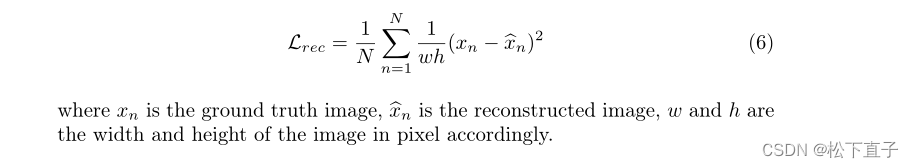
数据转换
训练数据集只包含单个域的图像,因此需要丰富训练数据的多样性
领域转换
将单域图像转换为不同的域样式。这方面涉及到五种变换方法,即模糊度、锐度、噪声水平、亮度和对比度。所有域变换的可能性经验地设置为10%
空间转换
裁剪和翻转两部分:
对于裁剪,原始图像大小的[0.7,0.9],然后将裁剪区域调整为原始大小,以引入不同形状的解剖结构。这里λ控制裁剪窗口的大小和位置。除了裁剪,水平翻转也涉及到。与域转换不同,标签也通过相同的空间转换进行相应的转换。翻转的概率§为5%,而裁剪的概率§为50%,以引入不同的解剖尺寸。然后这些图像以堆叠的方式进行转换:

交叉重建
根据实验结果,MI损失确实迫使两种表示具有最小的共享信息。然而,结构特征和领域特征之间MI的最小化并不一定使两个特征都包含各自的信息。该网络经常进入局部最优,其中域特征保持不变,所有信息都存储在解剖特征中。由于域特征中没有信息,因此两个表示之间的MI接近于零。
然而,这并不是我们的初衷。因此,引入交叉重构策略来解决这一问题。交叉重建损失将惩罚将所有信息汇总到一个表示中的行为。因此,它可以迫使每个编码器相应地提取信息特征,并防止整个网络进入局部最优。训练采用交替进行,具体过程如算法1所示