- MI(mutual information):
- 基于互信息的donsker-varadhan下界,则使用神经网络来估计互信息就转化为了一个优化问题,可以通过梯度上升算法来实现。
- 互信息可以看做加强版的 correlation,correlation 只能反映变量之间的线性关系,但是互信息可以进一步反映变量之间的非线性关系;这一点在量化金融里面也非常有用。
- 给定一堆相互关联的数据 x 和 z,需要给出这两组数据之间互信息的估计。方法就是训练一个神经网络(statistic network) T,训练目标就是对 Donsker-Varadhan 下界做梯度上升,最后的估计值就是 Donsker-Varadhan 下界在样本上的估计。
- 仅仅找出两组数据之间的互信息看起来也并不是特别有用。但是很多应用中会把互信息放入目标函数中,可以使用如下的 statistic network 来得到目标函数相对于输入(x 或者 z)的导数,从而完成梯度的传递。
- 互信息可以表示为 KL 散度,而 KL 散度可以写出 Donsker-Varadhan 表示形式;可以看出对于任意的如果目标是 E[f(.)](比如E[log(.)] )对应的随机梯度算法都是真实梯度的无偏估计;但是这里的目标是 f(E[.]),因此无法得到一个无偏的梯度估计(考虑 Jensen 不等式)。一个 T函数,都对应了互信息的一个下界。
- MINE:mutual information neural estimator互信息神经网络估计器
- 应用gan:
- GAN 有一个问题是 mode-dropping,简单说来就是,生成器很容易只学习到一种能够有效“欺骗”判别器的模式;这样生成器生成出来的数据(比如图片)看起来很真,但是它只会生成这一种(比如实际图片分布有各种图片,但是生成器最后只会生成包含狗的图片)。这里的做法就是把 z 分为两个部分 z=[e,c],然后同时最大化生成图片和 c 之间的互信息。这相当于要求生成的图片尽可能反映 c 的信息(比如给定的 c 如果是某个数字,那么 G 就生成狗;如果是另外的数字,G 就生成猫)。
- 通过MINE 方法,可以有效地对于互信息这一项关于 G 求导。实验结果表明,这种方法对应生成出来的数据点更能够有效覆盖整体的原始数据分布。
- 应用:Reconstruction(bi-directional adversarial models)仍然考虑 GAN 类似的网络结构,不过现在加入一个 reverse model F。任务目标是给定一个图片(可能被污染了),重构出来这张图片。一个最明显的目标就是最小化重构误差
- 应用:Information Bottleneck:Information bottleneck 的目标是找到 x 的一个好的表示,使得这个表示比较 compact 但是也能够很好的预测另外一个变量 y。经过推导,可以得到相应的目标函数,目标函数包含互信息项目。
- 应用gan:
- 信息论相关量之间的关系:
- 文氏图:

- area:信息的数量
- relationship:加减关系
- 左圈H(x),右圈H(y),左右两个圈H(x,y)
- 定义:
extropy:H_p=H(x)=-Σ_x p(x)logp(x)joint extropy:H(x,y)=-Σ_x,y p(x,y)logp(x,y)conditional extropy: H(x,y)=-Σ_x,y p(x,y)log[p(x,y)/p(x)]mutual information:l(x,y)=-Σ_x,y p(x,y)log[p(x,y)/(p(x)p(y))]=D_KL (p(x,y) || p(x)p(y) )KL 散度(relative entropy):D_KL (p||q) =-Σ_xp(x)log[q(x)/p(x)]交叉熵:H(p,q)=-Σ_xp(x)log[q(x)]=D_KL (p||q)+H_p
- 文氏图:
MI相关--学习笔记
news/2024/12/22 18:41:23/
相关文章
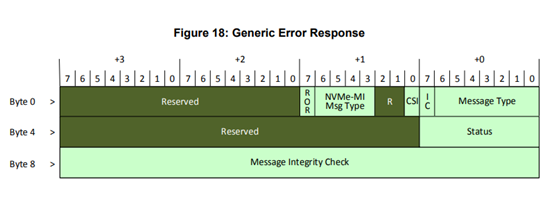
NVMe-MI协议解读
众所周知,在一个存储系统中,将设备管理与业务分离是一个良好的设计,比如在Nvme协议中就有一个Admin命令集,与IO命令分开。为了能够更规范合理得对NVMe SSD进行管理,NVMe-MI协议应运而生。
Nvme-MI(Management Interfa…


百度一款前端图片合成工具库MI开源啦!
什么是MI
Mi全称mix-img,是一个前端图片合成工具库,它可以将多张图片和文字合成一个全新的图片。作为一个轻量级的图片合成解决方案,Mi支持多张图片并行加载合成,减少图片合成时间,提升前端开发者的开发效率,改善开发…

解决cas aba的问题 解决方案–AtomicStampedReference的引用加版本号
public static void main(String[] args) {//---------------------------- ABA问题解决方式AtomicStampedReference--------------------------------AtomicStampedReference<Integer> integerAtomicStampedReferencenew AtomicStampedReference<>(1,1);new Threa…
数据结构-归并排序:理解和实现(附C++代码)
目录
## 1. 引言
## 2. 归并排序概述
## 3. 归并排序的思想和步骤
### 3.1 分解
### 3.2 归并
### 3.3 合并
## 4. 归并排序的时间复杂度和空间复杂度
## 5. C实现归并排序
### 5.1 实现思路
### 5.2 代码实现
## 6. 总结 ## 1. 引言
在计算机科学中,排…
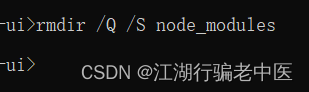
windows 快速删除node_modules文件夹
rmdir /Q /S 目录 删除文件夹(非空) /S 除目录本身外,还将删除指定目录下的所有子目录 /Q 安静模式,带 /S 删除目录树时不要求确认

工具篇6--kafka消息模型介绍
前言:kafka 诞生于需要处理大数据量的背景下,在当前的开发中,数据量的量级也是不断的提高,所以就非常有必要去研究一下kafka 的模型了;
kafka 的官网先放一下: 1 英文官网; 2 中文网站…