MySQL - 事务/索引
- 1. 数据库级别的MD5加密
- 2. 事务
- 2.1 事务原则:ACID
- 2.2 事务并发导致的问题
- 2.3 隔离级别
- 2.4 执行事务的过程
- 3. 索引
- 3.1 索引的分类
- 3.2 索引的使用
- 3.3 测试索引
- 3.4 索引原则
- 4. explain关键字
- 5. 权限管理和备份
- 5.1 用户管理
- 5.2 数据库备份
- 6. 三大范式
- 7. python连接MySQL
1. 数据库级别的MD5加密
-
MD5信息摘要算法(MD5 Message-Digest Algorithm)
MD5由MD4、MD3、MD2改进而来,主要增强算法复杂度和不可逆性
MD5破解网站的原理,背后有一个字典,{ MD5加密后的值 : 加密前的值 }
CREATE TABLE `testMD5`(`id` INT(4) NOT NULL,`name` VARCHAR(20) NOT NULL,`pwd` VARCHAR(50) NOT NULL,PRIMARY KEY(`id`)
)ENGINE=INNODB DEFAULT CHARSET =utf8;-- 明文密码
INSERT INTO `testMD5` VALUES(1,'zsr','200024'),
(2,'gcc','000421'),(3,'bareth','123456');-- 加密
UPDATE `testMD5` SET `pwd`=MD5(pwd) WHERE id=1;
UPDATE `testMD5` SET `pwd`=MD5(pwd); -- 加密全部的密码-- 插入的时候加密
INSERT INTO `testMD5` VALUES(4,'barry',MD5('654321'));-- 如何校验:将用户传递进来的密码,进行MD5加密,然后对比加密后的值
SELECT * FROM `testMD5` WHERE `name`='barry' AND `pwd`=MD5('654321');
2. 事务
-
要么都成功,要么都失败
SQL执行:A转账给B
SQL执行:B收到A的钱
将一组SQL放在一个批次中去执行
- 例如银行转账:只有A转账成功且B成功到账,该事件才算结束,如果一方不成功,则该事务不成功
2.1 事务原则:ACID
事务ACID理解
谈到事务一般都是以下四点
| 名称 | 描述 |
|---|---|
| 原子性(Atomicity) | 原子性是指事务是一个不可分割的工作单位,事务中的操作要么都发生,要么都不发生。 |
| 一致性(Consistency) | 事务前后数据的完整性必须保持一致。 |
| 隔离性(Isolation) | 事务的隔离性是多个用户并发访问数据库时,数据库为每一个用户开启的事务,不能被其他事务的操作数据所干扰,多个并发事务之间要相互隔离。 |
| 持久性(Durability) | 持久性是指一个事务一旦被提交,它对数据库中数据的改变就是永久性的,接下来即使数据库发生故障也不应该对其有任何影响 |
2.2 事务并发导致的问题
隔离所导致的一些问题
| 名称 | 描述 |
|---|---|
| 脏读 | 指一个事务读取了另外一个事务来提交的数据 |
| 不可重复读 | 在一个事务内读取表中的某一行数据,多次读取结果不同 |
| 虚读(幻读) | 是指在一个事务内读取到了别的事务插入的数据,导致前后读取不一致 |
2.3 隔离级别
在数据库操作中,为了有效保证并发读取数据的正确性,提出的事务隔离级别
-
读未提交:一个事务读取到其他事务未提交的数据;这种隔离级别下,查询不会加锁,一致性最差,会产生脏读、不可重复读、幻读的问题
-
读已提交:一个事务只能读取到其他事务已经提交的数据;该隔离级别避免了脏读问题的产生,但是不可重复读和幻读的问题仍然存在;
读提交事务隔离级别是大多数流行数据库的默认事务隔离级别,比如 Oracle,但是不是 MySQL 的默认隔离界别 -
可重复读:事务在执行过程中可以读取到其他事务已提交的新插入的数据,但是不能读取其他事务对数据的修改,也就是说多次读取同一记录的结果相同;该个里级别避免了脏读、不可重复度的问题,但是仍然无法避免幻读的问题
可重复读是MySQL默认的隔离级别 -
串行化:事务串行化执行,事务只能一个接着一个地执行,并且在执行过程中完全看不到其他事务对数据所做的更新;缺点是并发能力差,最严格的事务隔离,完全符合ACID原则,但是对性能影响比较大
| 事务隔离级别 | 脏读 | 不可重复读 | 幻读 |
|---|---|---|---|
| 读未提交(read-uncommitted) | 是 | 是 | 是 |
| 读已提交(read-committed) | 否 | 是 | 是 |
| 可重复读(repeatable-read) | 否 | 否 | 是 |
| 串行化(serializable) | 否 | 否 | 否 |
2.4 执行事务的过程
- 关闭自动提交
SET autocommit=0;
- 事务开启
START TRANSACTION -- 标记一个事务的开始,从这个之后的sql都在同一个事务内
- 成功则提交,失败则回滚
-- 提交:持久化(成功)
COMMIT
-- 回滚:回到原来的样子(失败)
ROLLBACK
- 事务结束
SET autocommit=1; -- 开启自动提交
- 其他操作
SAVEPOINT 保存点名; -- 设置一个事务的保存点
ROLLBACK TO SAVEPOINT 保存点名; -- 回滚到保存点
RELEASE SAVEPOINT 保存点名; -- 撤销保存点
3. 索引
MySQL索引背后的数据结构及算法原理
索引(Index)是帮助MySQL高效获取数据的数据结构。
提高查询速度确保数据的唯一性可以加速表和表之间的连接 , 实现表与表之间的参照完整性使用分组和排序子句进行数据检索时 , 可以显著减少分组和排序的时间全文检索字段进行搜索优化
3.1 索引的分类
-- 创建学生表student
CREATE TABLE `student`( `StudentNo` INT(4) NOT NULL COMMENT '学号',`LoginPwd` VARCHAR(20) DEFAULT NULL,`StudentName` VARCHAR(20) DEFAULT NULL COMMENT '学生姓名',`Sex` TINYINT(1) DEFAULT NULL COMMENT '性别,取值0或1',`GradeID` INT(11) DEFAULT NULL COMMENT '年级编号',`Phone` VARCHAR(50) NOT NULL COMMENT '联系电话,允许为空,即可选输入',`Adress` VARCHAR(255) NOT NULL COMMENT '地址,允许为空,即可选输入',`BornDate` DATETIME DEFAULT NULL COMMENT '出生时间',`Email` VARCHAR(50) NOT NULL COMMENT '邮箱账号,允许为空,即可选输入',`IdentityCard` VARCHAR(18) DEFAULT NULL COMMENT '身份证号',PRIMARY KEY (`StudentNo`),UNIQUE KEY `IdentityCard` (`IdentityCard`),KEY `Email` (`Email`)
)ENGINE=MYISAM DEFAULT CHARSET=utf8;
主键索引(PRIMARY KEY)
唯一的标识,主键不可重复,只有一个列作为主键
最常见的索引类型,不允许为空值确保数据记录的唯一性确定特定数据记录在数据库中的位置
-- 创建表的时候指定主键索引
CREATE TABLE tableName(......PRIMARY KEY(columeName)
)-- 修改表结构添加主键索引
ALTER TABLE tableName ADD PRIMARY KEY(columnName)
普通索引(KEY / INDEX)
默认的,快速定位特定数据
index 和 key 关键字都可以设置常规索引
应加在查询找条件的字段
不宜添加太多常规索引,影响数据的插入,删除和修改操作
-- 直接创建普通索引
CREATE INDEX indexName ON tableName (columnName)-- 创建表的时候指定普通索引
CREATE TABLE tableName(......INDEX [indexName] (columeName)
)-- 修改表结构添加普通索引
ALTER TABLE tableName ADD INDEX indexName(columnName)
唯一索引(UNIQUE KEY)
它与前面的普通索引类似,不同的就是:索引列的值必须唯一,但允许有空值
与主键索引的区别:主键索引只能有一个、唯一索引可以有多个
-- 直接创建唯一索引
CREATE UNIQUE INDEX indexName ON tableName(columnName)-- 创建表的时候指定唯一索引
CREATE TABLE tableName( ......UNIQUE INDEX [indexName] (columeName)
); -- 修改表结构添加唯一索引
ALTER TABLE tableName ADD UNIQUE INDEX [indexName] (columnName)
全文索引(FULLText)
快速定位特定数据(百度搜索就是全文索引)
在特定的数据库引擎下才有:MyISAM只能用于CHAR , VARCHAR , TEXT数据列类型适合大型数据集
-- 增加一个全文索引
ALTER TABLE `student` ADD FULLTEXT INDEX `StudentName`(`StudentName`);-- EXPLAIN 分析sql执行的情况
EXPLAIN SELECT * FROM student; -- 非全文索引
EXPLAIN SELECT * FROM student WHERE MATCH(StudentName) AGAINST('d'); -- 全文索引

MySQL-Explain详解
3.2 索引的使用
-
索引的创建
在创建表的时候给字段增加索引
CREATE TABLE 表名 ( 字段名1 数据类型 [完整性约束条件…], 字段名2 数据类型 [完整性约束条件…], [UNIQUE|FULLTEXT|SPATIAL] INDEX|KEY [索引名] (字段名[(长度)] [ASC |DESC]) );Mysql Spatial 索引
创建完毕后,增加索引
-- 方法一:CREATE在已存在的表上创建索引CREATE [UNIQUE|FULLTEXT|SPATIAL] INDEX 索引名ON 表名 (字段名[(长度)] [ASC |DESC]) ;-- 方法二:ALTER TABLE在已存在的表上创建索引ALTER TABLE 表名 ADD [UNIQUE|FULLTEXT|SPATIAL] INDEX 索引名 (字段名[(长度)] [ASC |DESC]) ; -
索引的删除
-- 删除索引DROP INDEX 索引名 ON 表名; -- 删除主键索引ALTER TABLE 表名 DROP PRIMARY KEY; -
显示索引信息
SHOW INDEX FROM 表名; -
explain分析sql执行的情况
-- 增加一个全文索引 ALTER TABLE `student` ADD FULLTEXT INDEX `StudentName`(`StudentName`);-- EXPLAIN 分析sql执行的情况 EXPLAIN SELECT * FROM student; -- 非全文索引 EXPLAIN SELECT * FROM student WHERE MATCH(StudentName) AGAINST('d'); -- 全文索引
3.3 测试索引
建表app_user:
CREATE TABLE `app_user` (`id` bigint(20) unsigned NOT NULL AUTO_INCREMENT,`name` varchar(50) DEFAULT '' COMMENT '用户昵称',`email` varchar(50) NOT NULL COMMENT '用户邮箱',`phone` varchar(20) DEFAULT '' COMMENT '手机号',`gender` tinyint(4) unsigned DEFAULT '0' COMMENT '性别(0:男;1:女)',`password` varchar(100) NOT NULL COMMENT '密码',`age` tinyint(4) DEFAULT '0' COMMENT '年龄',`create_time` datetime DEFAULT CURRENT_TIMESTAMP,
-- `update_time` timestamp NULL DEFAULT CURRENT_TIMESTAMP ON UPDATECURRENT_TIMESTAMP,PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COMMENT='app用户表'
批量插入数据:100w
-- 1418错解决方案(创建函数前执行此语句)
set global log_bin_trust_function_creators=true;-- 插入100万条数据
DELIMITER $$ -- 写函数之前要写的标志
CREATE FUNCTION mock_data() -- 创建mock_data()函数
RETURNS INT
BEGINDECLARE num INT DEFAULT 1000000;DECLARE i INT DEFAULT 0;WHILE i < num DOINSERT INTO app_user(`name`, `email`, `phone`, `gender`, `password`, `age`)VALUES(CONCAT('用户', i), '24736743@qq.com', CONCAT('18', FLOOR(RAND()*(999999999-100000000)+100000000)),FLOOR(RAND()*2),UUID(), FLOOR(RAND()*100));SET i = i + 1;END WHILE;RETURN i;
END;-- 执行函数
SELECT mock_data();
测试查询速度
-- 查询用户名为'用户9999'性能分析
EXPLAIN SELECT * FROM app_user where name='用户99999'

增加索引后测试
-- 给name列创建常规索引
CREATE INDEX id_app_user_name ON app_user(`name`)
-- 再测试
EXPLAIN SELECT * FROM app_user where name='用户99999'

对比两次结果,速度有了很大的提升
3.4 索引原则
索引不是越多越好,小数据量的表不需要加索引,不要对经常变动的数据增加索引,索引一般加在经常要查询的列上
4. explain关键字
建议阅读:
MySQL优化——看懂explain
MySQL高级 之 explain执行计划详解
5. 权限管理和备份
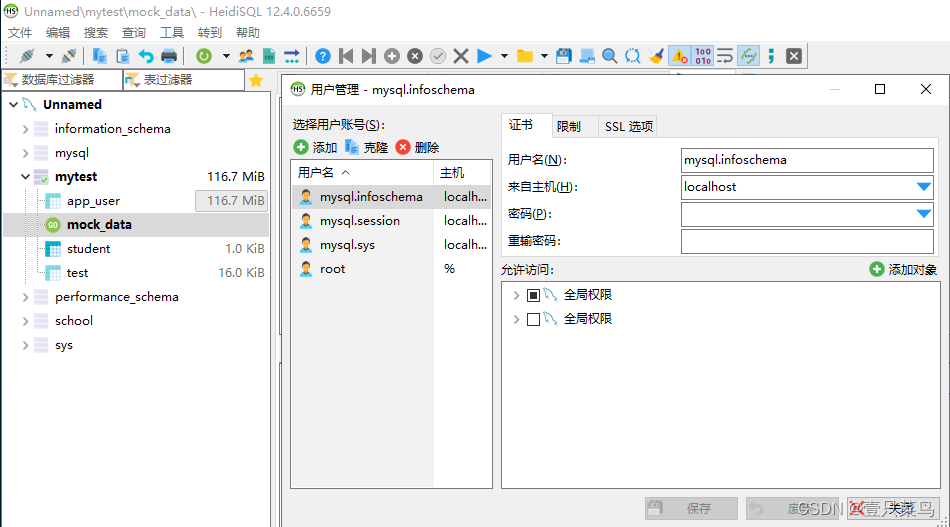
5.1 用户管理
-
方式一:可视化管理
-
方式二:SQL命令操作
用户信息存储在mysql数据库的user表中,对用户的管理本质上就是对这张表进行增删改查
-- 创建用户 CREATE USER zsr IDENTIFIED BY '123456'-- 查询用户 SELECT * FROM mysql.user-- 删除用户 DROP USER zsr-- 修改当前用户密码 SET PASSWORD = PASSWORD('200024')-- 修改指定用户密码 SET PASSWORD FOR zsr = PASSWORD('200024')-- 重命名 RENAME USER zsr to zsr2-- 用户授权(授予全部权限,除了给其他用户授权) GRANT ALL PRIVILEGES on *.* TO zsr2-- 查询权限 SHOW GRANTS FOR zsr-- 查看root用户权限 SHOW GRANTS FOR root@localhost-- 撤销权限 REVOKE ALL PRIVILEGES ON *.* FROM zsr
5.2 数据库备份
保证重要的数据不丢失、数据转义
- 方式一:直接拷贝物理文件,MySQL数据表以文件方式存放在磁盘中
包括表文件 , 数据文件 , 以及数据库的选项文件
位置 : Mysql安装目录/var/lib/mysql(参考/etc/my.conf目录名对应数据库名 , 该目录下文件名对应数据表)
[root@node-251 opt]# grep -v "^#" /etc/my.cnf[mysqld]datadir=/var/lib/mysqlsocket=/var/lib/mysql/mysql.socklog-error=/var/log/mysqld.logpid-file=/var/run/mysqld/mysqld.pid
-
方式二:可视化管理
通过可视化工具进行备份
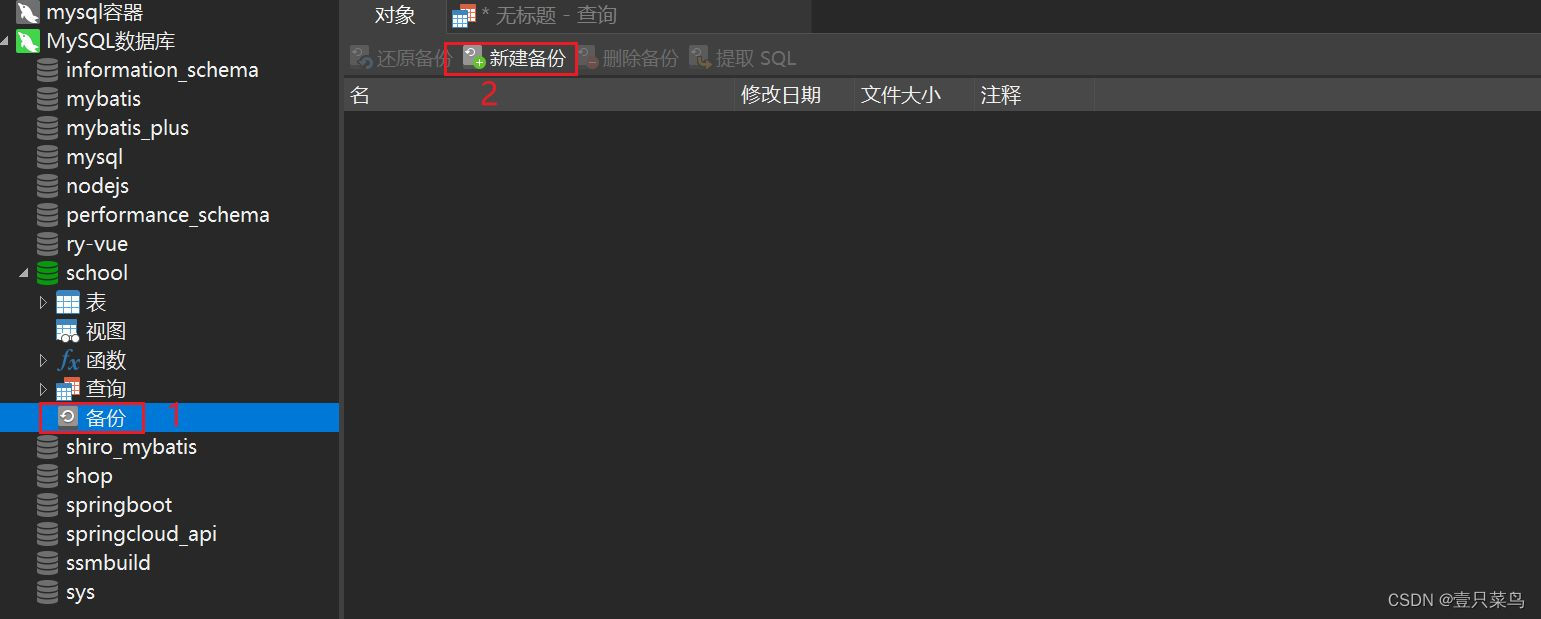
-
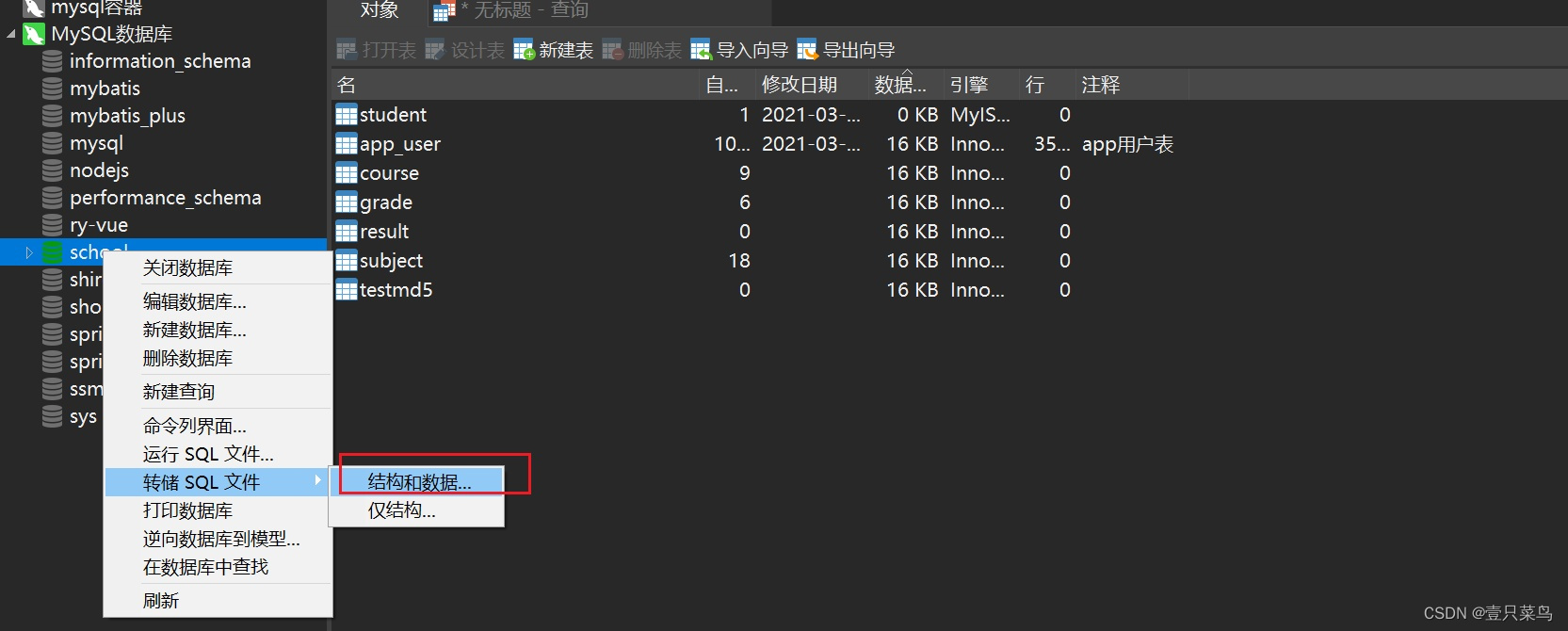
方式三:可视化管理
选中要导出的表,右键转储SQL文件
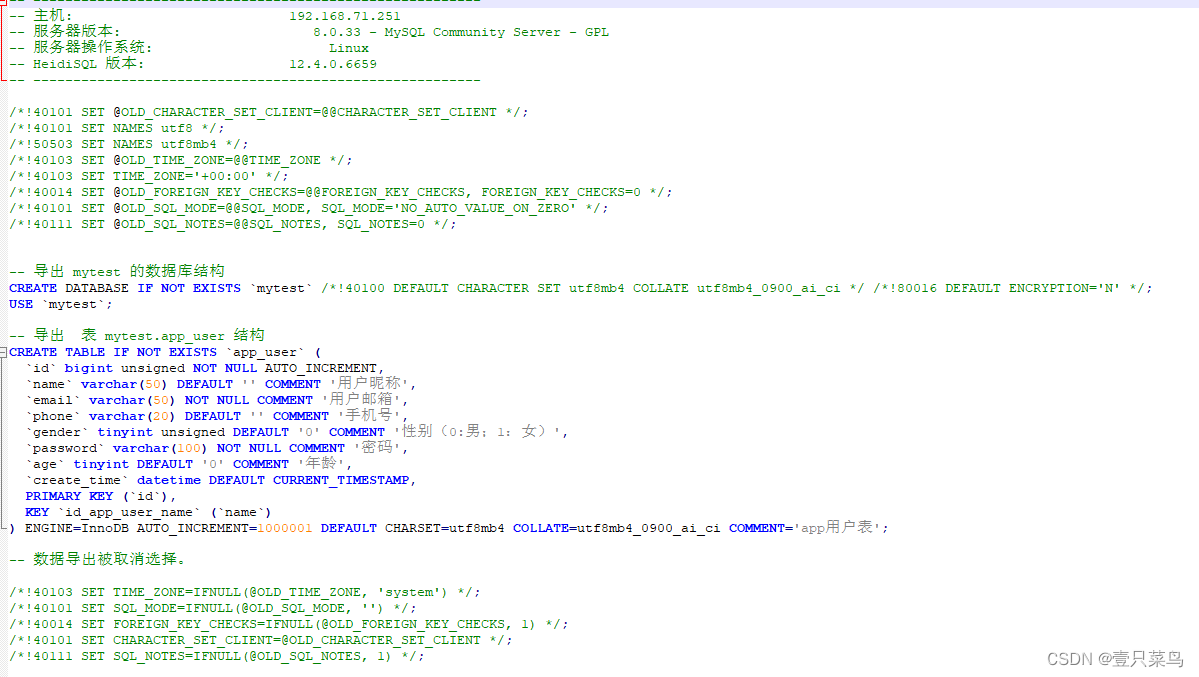
然就就可以得到.sql文件
-
方式四:命令mysqldump导出
# mysqldump -h主机 -u用户名 -p密码 数据库 [表1 表2 表3] >物理磁盘位置/文件名# 导出school数据库的cource grade student表到D:/school.sql
[root@node-251 opt]# mysqldump -h127.0.0.1 -uroot -pAdmin@123 mytest app_user student >/home/yurq/sql_data_bak/mytest.sql
mysqldump: [Warning] Using a password on the command line interface can be insecure.
[root@node-251 opt]# ll /home/yurq/sql_data_bak/mytest.sql
-rw-r--r-- 1 root root 121685111 Apr 24 22:58 /home/yurq/sql_data_bak/mytest.sql
[root@node-251 opt]# file /home/yurq/sql_data_bak/mytest.sql
/home/yurq/sql_data_bak/mytest.sql: UTF-8 Unicode text, with very long lines
然后可以命令行登录mysql,切换到指定的数据库,用source命令导入
mysql> use mytest;
Reading table information for completion of table and column names
You can turn off this feature to get a quicker startup with -ADatabase changed
mysql> source /home/yurq/sql_data_bak/mytest.sql;
Query OK, 0 rows affected (0.00 sec)Query OK, 0 rows affected (0.00 sec)Query OK, 0 rows affected (0.00 sec)Query OK, 0 rows affected (0.00 sec)6. 三大范式
规范化理论:改造关系模式,通过分解关系模式来消除其中不合适的数据依赖,以解决插入异常、删除异常、更新异常和数据冗余的问题。
为了建立冗余较小、结构合理的数据库,设计数据库时必须遵循一定规范化理论。在关系型数据库中这种规则就称为范式
三大范式的通俗理解
如果一个关系模式R的所有属性都是不可分的数据项,则R属于第一范式
如果关系模式R属于第一范式,且每一个非主属性完全函数依赖于码,则R属于第二范式
若关系模式R属于第二范式,且R中所有的非主属性都直接依赖于码,则R属于第三范式
规范性问题:
数据库的范式是为了规范数据库的设计,但是实际中相比规范性,往往更需要看中性能、成本、用户体验等问题;
因此有时会故意给某些表增加一个冗余的字段,使多表查询变为单表查询。有时还会增加一些计算列,从大数据量变为小数据量(数据量大时,count(*)很耗时,可以直接添加一列,每增加一行+1,查该列即可);阿里也曾提出关联查询的表最多不超过三张表。
这些就是为了性能、成本而舍弃一定规范性的例子
7. python连接MySQL
4 种 Python 连接 MySQL 数据库的方法

![[世界读书日] 最好的书,都在博雅之中](https://img-blog.csdnimg.cn/img_convert/573e864309bd18cea56fb5bd68aaa89b.jpeg)