文章目录
- 📚引言
- 📖数据加载以及基本观察
- 📑缺失值观察及处理
- 🔖缺失值观察以及可视化
- 🔖缺失值处理
- 📖用户数据探索
- 📑什么时间预定酒店将会更经济实惠?
- 📑哪个月份的酒店预订是最繁忙的?
- 📖商家数据探索
- 📑按市场细分的不同预定情况是怎样的?
- 📑什么样的人更容易取消预订?
- 🔖数据编码
- 🔖特征筛选
- 🔖构建模型并预测
- 🔖根据特征重要性得出结论
- 📍总结
📚引言
🙋♂️作者简介:生鱼同学,大数据科学与技术专业硕士在读👨🎓,曾获得华为杯数学建模国家二等奖🏆,MathorCup 数学建模竞赛国家二等奖🏅,亚太数学建模国家二等奖🏅。
✍️研究方向:复杂网络科学
🏆兴趣方向:利用python进行数据分析与机器学习,数学建模竞赛经验交流,网络爬虫等。
在有预定酒店的需求时,你是否考虑过以下的问题:
- 你是否曾想过每年什么时候是预订酒店房间的最佳时间?
- 为了获得最佳的每日价格,最佳的逗留时间?
- 如果你想预测一家酒店是否有可能收到过多的特殊要求呢?
在本文中我们就对Kaggle平台上的酒店需求数据集进行分析,这个数据集包含了一家城市酒店和一家度假酒店的预订信息,并包括诸如预订时间、逗留时间、成人、儿童和/或婴儿的数量,以及可用的停车位数量等信息。话不多说,我们开始吧。
本项目中的数据来源于Kaggle开放数据Hotel booking demand链接如下:
Hotel booking demand
需要的小伙伴可以自行下载获取。
📖数据加载以及基本观察
在进行数据加载之前,我们首先对数据的各个列进行解释,具体情况如下表所示:
| 列名 | 表达含义 |
|---|---|
| hotel | 酒店(H1=度假酒店或H2=城市酒店) |
| is_canceled | 表示预订是否被取消(1)或不被取消(0)的值。 |
| lead_time | 从预订进入PMS的日期到抵达日期之间的天数。 |
| arrival_date_year | 到达日期的年份 |
| arrival_date_month | 到达日期的月份 |
| arrival_date_week_number | 抵达日期的年份的周数 |
| arrival_date_day_of_month | 抵达日期当天 |
| stays_in_weekend_nights | 客人入住或预订入住酒店的周末晚数(周六或周日)。 |
| stays_in_week_nights | 客人入住或预订入住酒店的周夜数(周一至周五)。 |
| adults | 成人的数目 |
| children | 小孩的数目 |
| babies | 婴儿的数目 |
| meal | 预订的膳食类型。类别以标准接待餐包的形式呈现: 未定义/SC–无餐包;BB–床和早餐;HB–半餐(早餐和另外一餐–通常是晚餐);FB–全餐(早餐、午餐和晚餐)。 |
| country | 国家。类别以ISO 3155-3:2013的格式表示 |
| market_segment | 市场细分的指定。在类别中,"TA "指 “旅行社”,"TO "指 “旅游经营者”。 |
| distribution_channel | 预订分销渠道。术语 "TA "指 “旅行社”,"TO "指 “旅游经营者” |
| is_repeated_guest | 表示该预订名称是否来自重复的客人(1)或不(0)的值。 |
| previous_cancellations | 在当前预订之前被客户取消的先前预订的数量 |
| previous_bookings_not_canceled | 在本次预订之前,客户没有取消的先前预订的数量 |
| reserved_room_type | 保留的房间类型的代码。出于匿名的原因,用代码代替名称。 |
| assigned_room_type | 为预订分配的房间类型的代码。有时,由于酒店运营的原因(如超额预订)或客户要求,分配的房间类型与预订的房间类型不同。出于匿名的原因,用代码代替指定。 |
| booking_changes | 从预订被输入PMS到入住或取消的那一刻起,对预订进行更改/修正的次数 |
| deposit_type | 指明客户是否支付了押金以保证预订。这个变量可以有三个类别: 无押金–没有押金;不退款–押金的价值相当于总住宿费用;可退款–押金的价值低于总住宿费用。 |
| agent | 进行预订的旅行社的ID |
| company | 进行预订或负责支付预订的公司/实体的ID。出于匿名的原因,将出示身份证而不是指定的身份。 |
| days_in_waiting_list | 预订在确认给客户之前在等待名单中的天数 |
| customer_type | 预订的类型,假设是四类之一: 合同–当预订有一个分配或其他类型的合同与之相关时;团体–当预订与一个团体相关时;暂住–当预订不是团体或合同的一部分,并且没有与其他暂住预订相关时;暂住方–当预订是暂住的,但至少与其他暂住预订相关时 |
| adr | 日均房价的定义是用所有住宿交易的总和除以总的住宿夜数。 |
| required_car_parking_spaces | 预客户需要的车位数量 |
| total_of_special_requests | 客户提出的特殊要求的数量(如双床或高楼层)。 |
| reservation_status | 预订的最后状态,假设是三类中的一类: 取消–预订被客户取消;退房–客户已入住但已离开;未入住–客户未入住但已通知酒店原因 |
| reservation_status_date | 最后一次设置状态的日期。这个变量可以和ReservationStatus一起使用,以了解预订何时被取消或客户何时退房。 |
可以看到,数据所给出的特征还是比较多的。接下来我们就基于上述数据来解决一些商业角度可能关心的问题,本文解决的问题如下:
首先是从用户的角度来看关心的问题:
- 什么时间预定酒店将会更经济实惠?
- 哪个月份的酒店预订是最繁忙的?
其次是商家更容易关心的问题:
- 客人来自哪里?
- 按市场细分的不同预定情况是怎样的?
- 对酒店提出特殊要求的人有什么共同点?
- 什么样的人更容易取消预订?
首先我们调用**info()**函数来对数据进行初步的观察。代码和结果如下:
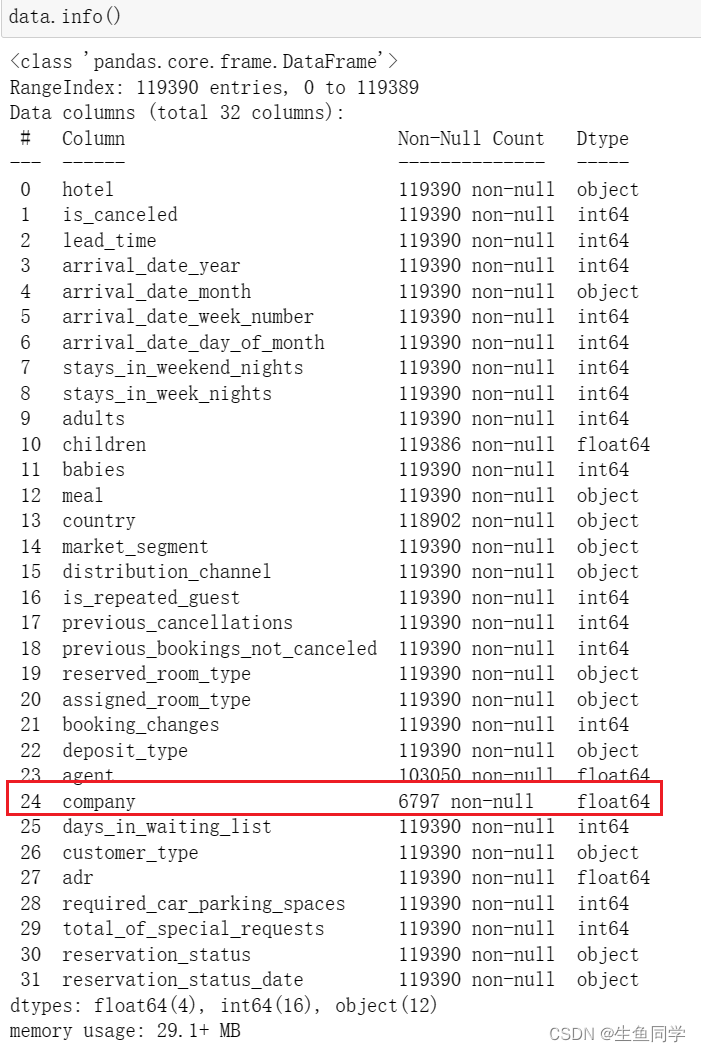
我们可以看到,公司这列有明显的缺失情况。与此同时,在这里我们也能了解到不同的数据类型。
📑缺失值观察及处理
🔖缺失值观察以及可视化
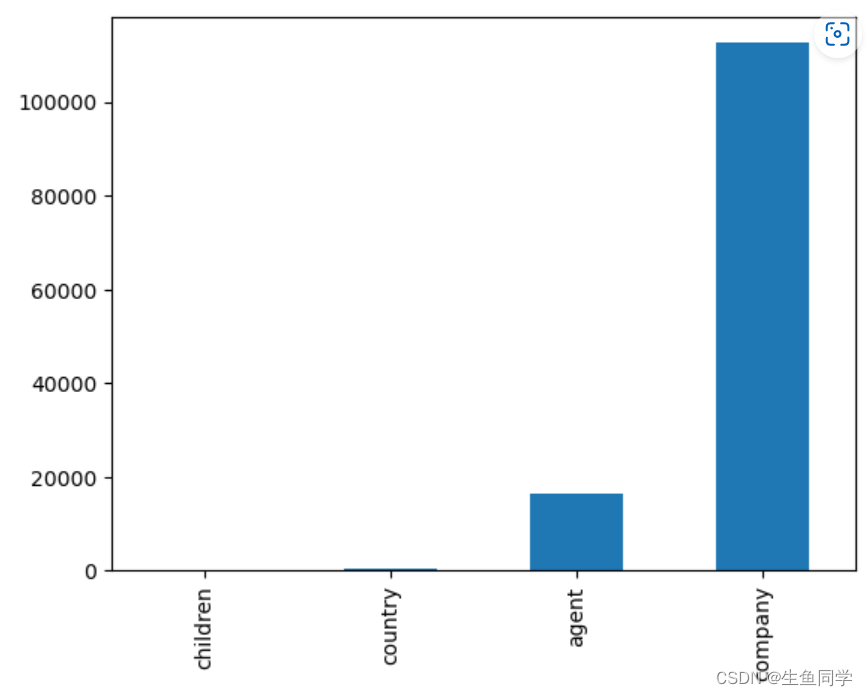
首先提取所有缺失的列以及它们缺失的个数情况,代码如下:
data_missing = data.isnull().sum()
data_missing = data_missing[data_missing > 0]
data_missing
结果如下:

接下来,我们对数据的缺失值进行一些简单的柱状图可视化。代码如下:
data_missing.plot.bar()
🔖缺失值处理
我们首先来看一下缺失值的实际意义代表情况,如下:
| 列名 | 表达含义 |
|---|---|
| children | 小孩的个数 |
| country | 国家。类别以ISO 3155-3:2013的格式表示 |
| agent | 进行预订的旅行社的ID |
| company | 进行预订或负责支付预订的公司/实体的ID。出于匿名的原因,将出示身份证而不是指定的身份。 |
基于上述特征的实际意义,我们对其进行如下的处理:
- children :缺失数据相对较少,我们选择删除携带孩子缺失的数据行。
- country:因为后续我们可能会用到该数据,所以设置为‘Unknown’。
- agent:预定的ID在本次数据分析中,不太重要,删除该特征。
- company:公司的数据在本次数据中,不太重要,而且确实程度过大,直接删除。
相关代码如下:
# inplace表示是否在原数据进行填充
data.dropna(axis=0, how='any',subset=['children'], inplace=True)
# 用Unknown填充'country'为Nan的数据
data.fillna({'country':'Unknown'}, inplace=True)
# 删除'agent','company'的列
data.drop(['agent','company'],axis=1, inplace=True)
📖用户数据探索
在进行了用户数据的基础探索后,接下来就开始对其进行一些分析工作。
📑什么时间预定酒店将会更经济实惠?
作为游客或者用户,我们较为关注的通常是酒店是否经济实惠。在下面的工作中,我们首先提取没有取消的那些订单作为我们分析的数据,然后对其进行一些处理最后进行可视化,代码如下:
import seaborn as sns
# 提取没有取消订单的数据
data_no_canceled = data[data['is_canceled']==0]
# 算出人均价格
data_no_canceled['adr_deal'] = data_no_canceled['adr']/ (data_no_canceled['adults'] + data_no_canceled['children'])
# 对结果进行可视化
ax = sns.lineplot(data=data_no_canceled, x = 'arrival_date_month',y='adr_deal',hue='hotel')
# 设置图片尺寸
ax.figure.set_size_inches(12,6)
结果如下:
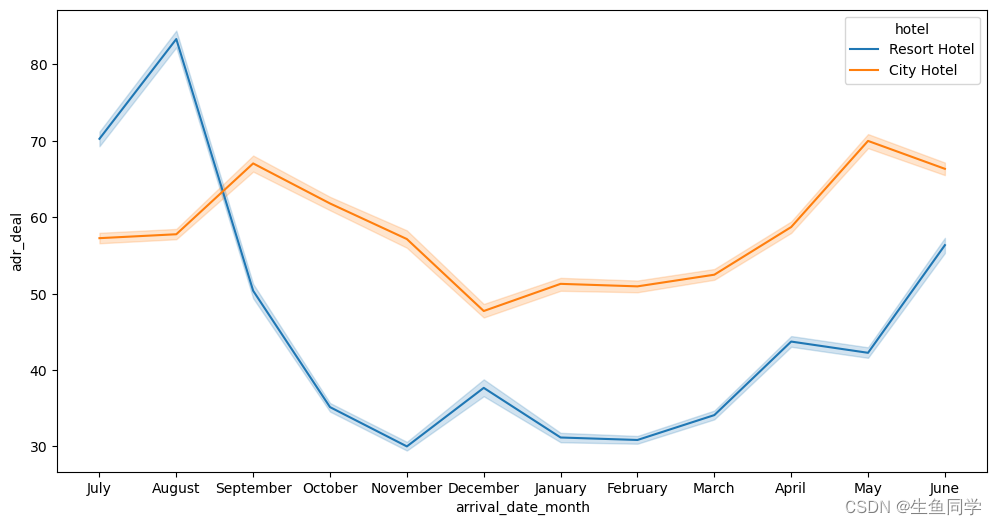
在图中我们可以发现,在七月Resort Hotel价格最高,而在其他时间City Hote的价格会稍高一些。另外,在十一月以及十二月两种酒店的价格是全年最低的,也就是最经济实惠的。
另外,我还探究了不同房型的价格分布情况,代码如下:
# 提取数据并进行排序
roomtype = data_no_canceled[["hotel", "reserved_room_type", "adr_deal"]].sort_values("reserved_room_type")
# 绘制箱线图
ax_box = sns.boxplot(data = roomtype, x = 'reserved_room_type',y='adr_deal',hue='hotel')
ax_box.figure.set_size_inches(12,6)
结果如下:
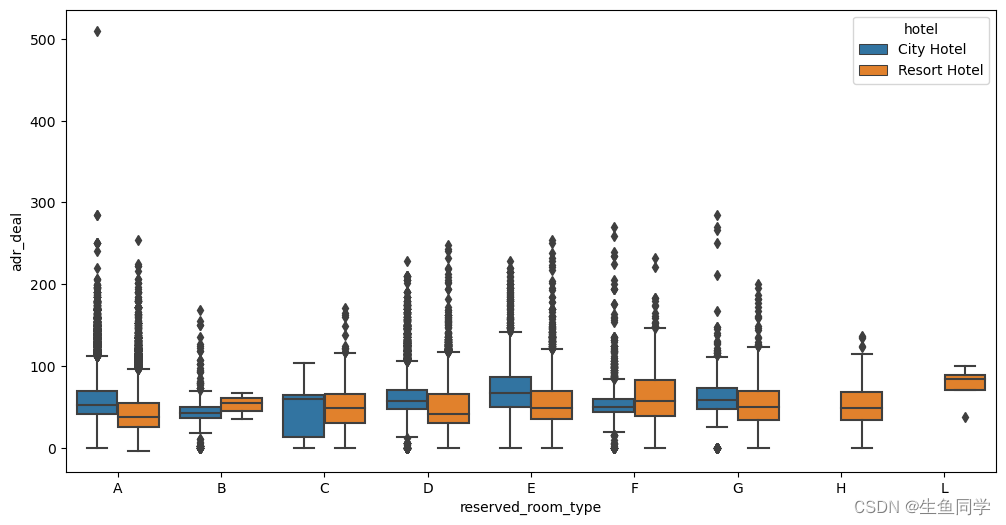
可以看到,在图中City Hotel的E房型价格偏高,而Resort Hotel的F房型价格偏高。
📑哪个月份的酒店预订是最繁忙的?
基于上述的分析,我们进一步探索哪个月份的酒店预订是最繁忙的,代码如下:
# 提取用户们到达的日期,并对其进行排序可视化
data_no_canceled['arrival_date_month'].value_counts().sort_values(ascending=False).plot.bar()
结果如下:
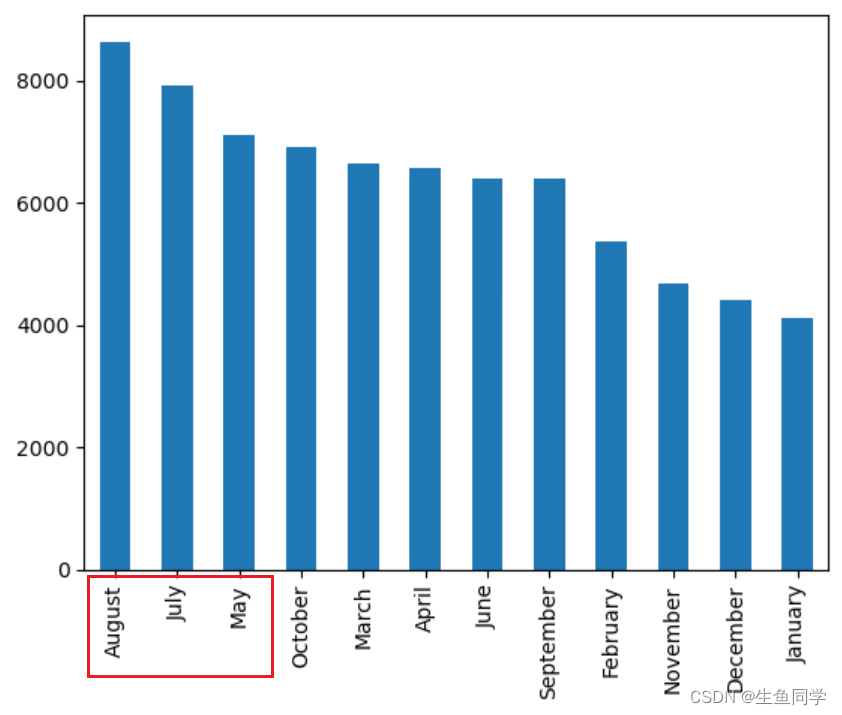
在图中可以看到,5,7,8月是最繁忙的时间,而秋冬季节的酒店人数相对来说较少。
📖商家数据探索
作为商家,较为关心的问题即用户的组成,以便更好的提供服务。另外,做为商家了解不同用户的订购渠道对于进一步的进行市场营销将会有积极的作用。
📑按市场细分的不同预定情况是怎样的?
我们首先基于数据来探索预订酒店的不同国家的人数占比,并进行可视化,代码如下:
import plotly.express as px
# 计算不同国家的百分比
country_data = pd.DataFrame(data['country'].value_counts())
country_data.columns = ['guest_num']
country_data['guest_persent'] = round(country_data['guest_num'] / country_data['guest_num'].sum() * 100,2)# 对小于一定比例的国家归类
country_data.loc['OTHER','guest_num'] = country_data[country_data['guest_persent'] < 2]['guest_num'].sum()
country_data.loc['OTHER','guest_persent'] = round(country_data.loc['OTHER','guest_num'] / country_data['guest_num'].sum(),2)
# 可视化
country_data.drop(country_data[country_data['guest_persent'] < 0.5].index, inplace=True)
fig = px.pie(country_data,values = 'guest_persent',names = country_data.index)
fig.update_traces(textposition="inside", textinfo="value+percent+label")
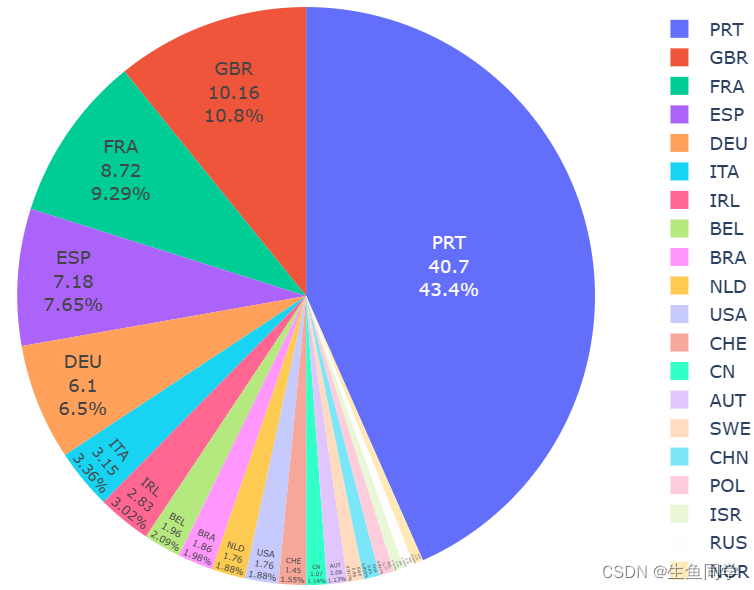
结果如下:
进一步的,我们对不同预订酒店的渠道进行了统计,代码如下:
data_no_canceled['market_segment'].value_counts().plot.bar()
结果如下:
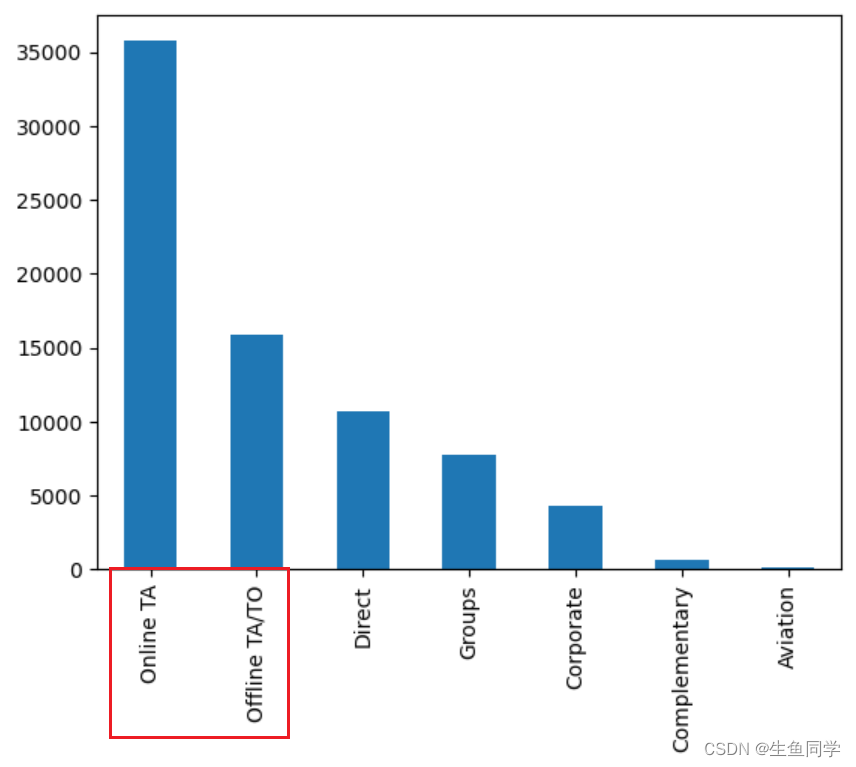
从图中可以看到,预订的主力军都是旅行社居多。另外,在线预定远比线下预订的数目要多很多。针对商家,可以对线上的广告推荐等进一步的进行策划营销。
📑什么样的人更容易取消预订?
最后,我们希望了解什么样的人更容易取消预订。商家可以针对这部分用户进行服务优化,并进一步的改善酒店的经营模式。在这里,我们准备基于数据进行机器学习模型的构建。
🔖数据编码
在这一步中,我们将对字符型的数据做编码处理,从而更好的适应不同模型,代码如下:
from sklearn import preprocessing
data_to_ml = data.copy()
# 因为我们预测的目标是是否取消了预订,所以删除这两列
data_to_ml.drop(['reservation_status','reservation_status_date'], axis=1, inplace=True)
# 对大部分特征进行编码处理
for col in ['hotel','arrival_date_month','meal','country','market_segment','distribution_channel','customer_type','deposit_type']:encoder = preprocessing.LabelEncoder()encoder.fit(data_to_ml[col])data_to_ml[f'{col}_labeled'] = encoder.transform(data_to_ml[col])data_to_ml.drop([col], axis=1, inplace=True)
在这里,我们有一个特殊的操作,即我们根据现有的特征提取了一个新的特征,即酒店预留的房间以及用户预定的是否是相同的。因为如果作为用户发现预定的房间和实际房间不同很可能会取消预订。具体代码如下:
import numpy as np
data_to_ml['is_reserved_assigned_equal'] = np.where(data_to_ml['reserved_room_type']==data_to_ml['assigned_room_type'],1,0)
data_to_ml.drop(['reserved_room_type','assigned_room_type'], axis=1, inplace=True)
🔖特征筛选
在这一步中,我们对所有处理后的数据进行了皮尔逊相关分析并做了可视化,代码如下所示:
import matplotlib.pylab as plt
correlation = data_to_ml.corr('pearson')f, ax = plt.subplots(figsize = (9, 9))
plt.title('Correlation of Numeric Features with',y=1,size=16)
sns.heatmap(correlation,square = True, vmax=0.8)
结果如下:
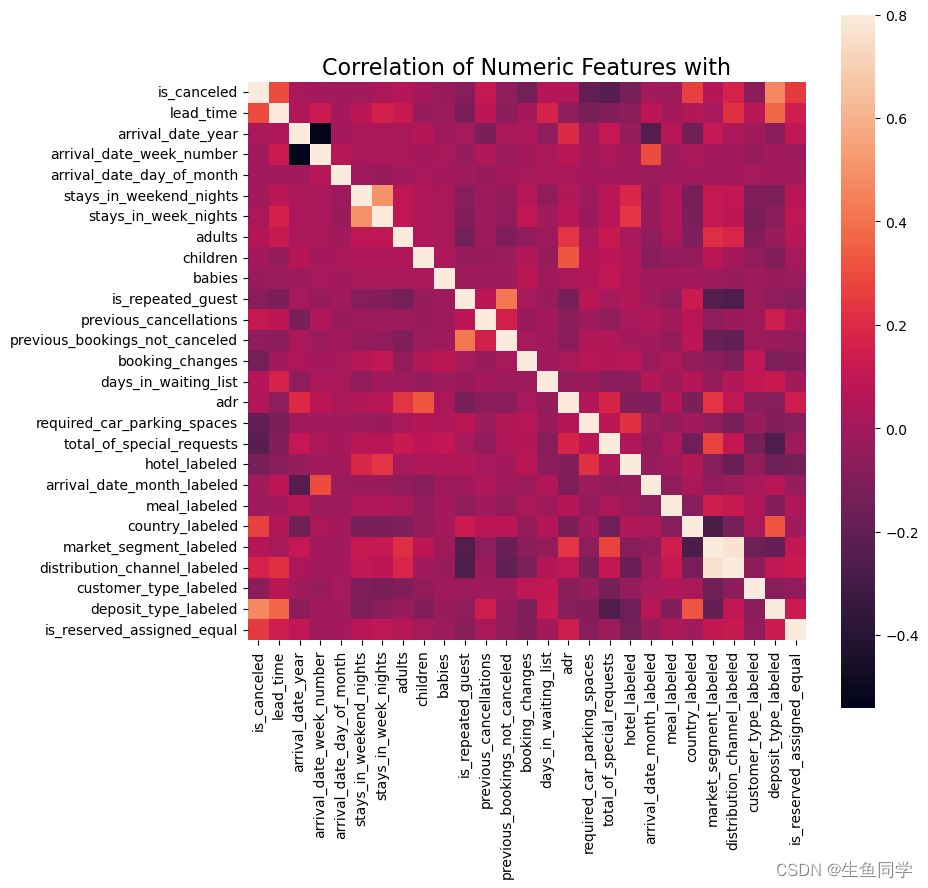
可以看到,我们所挑选的特征自相关性不算太高可以接受。与此同时,其针对我们所选定的目标is_canceled来说相关性也是可以接受的,所以我们暂时不对其进行处理。
🔖构建模型并预测
在这一部分中,我们构建了主流的模型并使用10折交叉认证对其进行验证,代码如下:
from sklearn import svm
from sklearn.ensemble import RandomForestClassifier
from sklearn.neighbors import KNeighborsClassifier
from sklearn import model_selectionx_all = data_to_ml.drop('is_canceled',axis=1)
y_all = data_to_ml['is_canceled']# 为了避免训练时间过长,这里我选择了部分数据集
x_train = x_all.loc[:19999,:]
y_train = y_all[:20000]model_svm = svm.SVC()
model_knn = KNeighborsClassifier()
model_rf = RandomForestClassifier()model_dict = {'SVM':model_svm,'KNeighborsClassifier':model_knn,'RandomForestClassifier':model_rf
}
# 训练模型
for model in model_dict:model_dict[model].fit(x_train, y_train)scores = model_selection.cross_val_score(model_dict[model], X=x_train, y=y_train, verbose=1, cv = 10, scoring='f1')print(model, scores.mean())>>>SVM 0.6480724503120129
>>>KNeighborsClassifier 0.6577070795293697
>>>RandomForestClassifier 0.7363861778481174
可以看到,随机森林的效果是可以接受的,接下来我们对其特征重要性进行可视化。
🔖根据特征重要性得出结论
调用随机森林中自带的特征重要性函数,并对其进行了可视化,代码如下:
# 构建Series让特征重要性和特征名称一一对应
feature_importances_series = pd.Series(list(model_rf.feature_importances_), index = x_all.columns, )
# 对其进行排序
feature_importances_series =feature_importances_series.sort_values(ascending=False)
# 进行可视化
sns.barplot(x = feature_importances_series.values, y = feature_importances_series.index, orient='h')
结果如下:
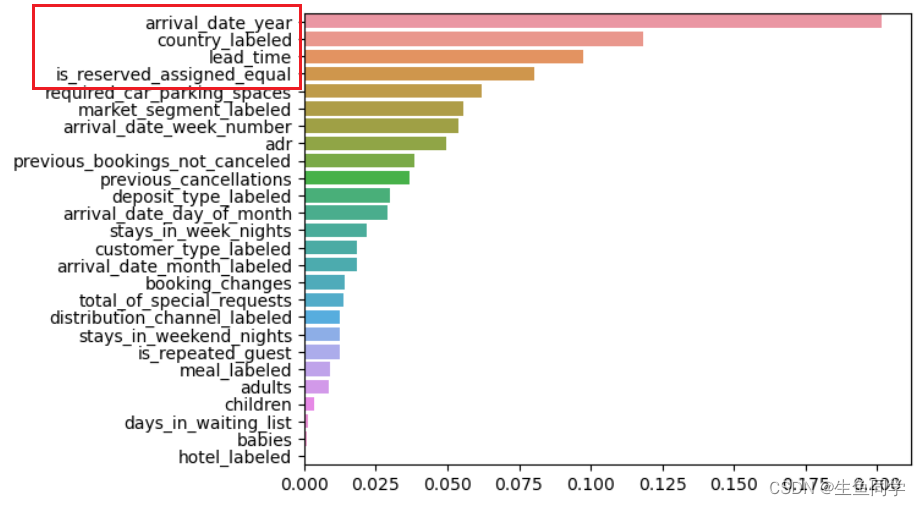
如图所示,用户取消预订和逗留时长、用户国籍、到达年份都有很强的相关性。另外,我们提取的特征也是非常重要的,即用户预定的房间和实际的房间不同时,用户将会更容易取消预订。
📍总结
在本文中,我们基于python对酒店预订需求进行分析,并从多种角度对其展开了探索性的工作。这对于养成数据分析习惯有很大的帮助,在实际工作或者学习中还需要不断练习。
感兴趣的朋友们可以自己按照上述步骤进行操作,或在评论区与我讨论。
需要源码的朋友可以私信我进行索取,我们下次再见。