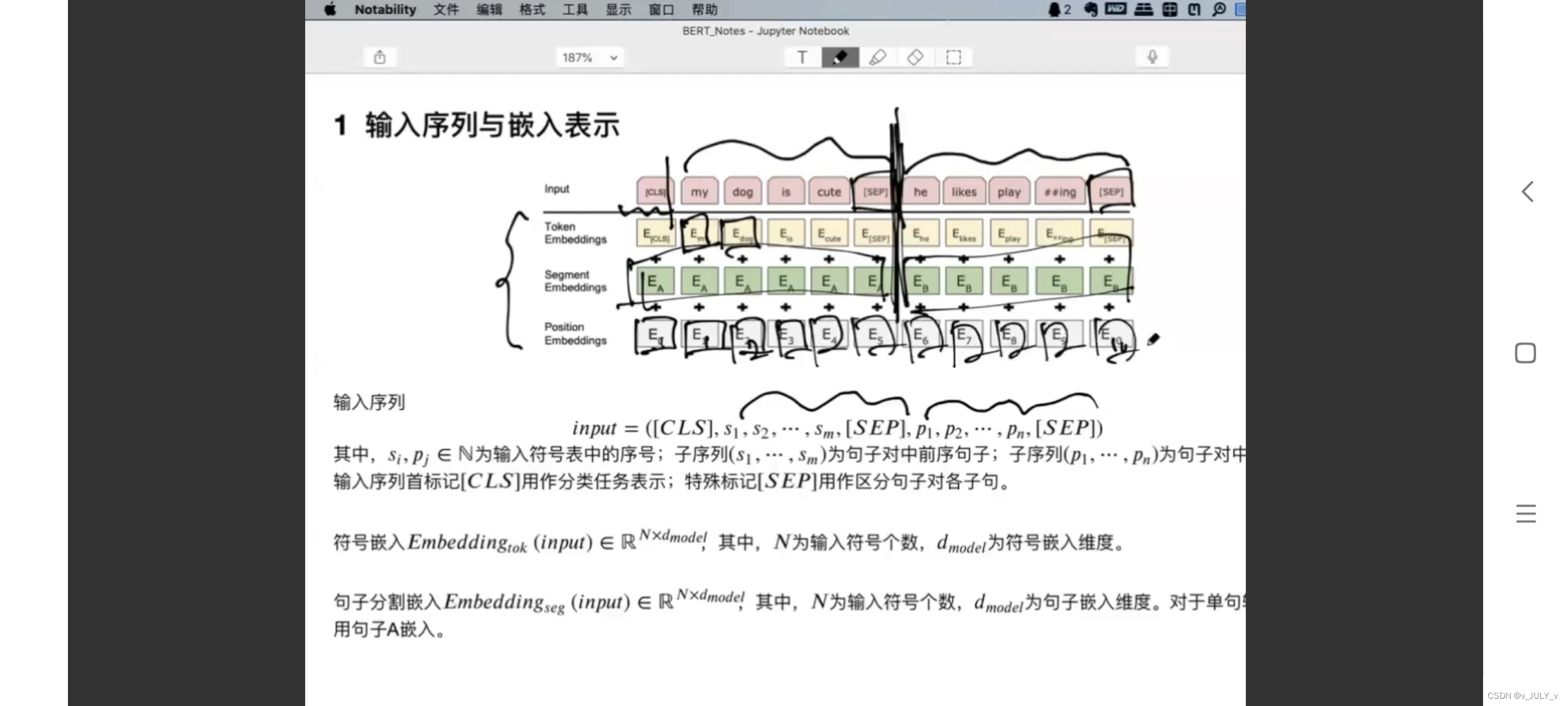
在聊 Word2vec 之前,先聊聊 NLP。NLP里面,最细粒度的是词语,词语组成句子,句子再组成段落、篇章、文档。所以处理 NLP 的问题,首先就要拿词语开刀。
举个简单例子,判断一个词的词性,是动词还是名词。用机器学习的思路,我们有一系列样本 ( x , y ) (x,y) (x,y),这里 x x x 是词语, y y y 是它们的词性,我们要构建 f ( x ) − > y f(x)->y f(x)−>y 的映射,但这里的数学模型 f f f(比如神经网络、SVM)只接受数值型输入,而NLP里的词语,是人类的抽象总结,是符号形式的(比如中文、英文、拉丁文等等),所以需要把他们转换成数值形式,或者说——嵌入到一个数学空间里,这种嵌入方式,就叫词嵌入(word embedding),而 Word2vec,就是词嵌入( word embedding) 的一种
在NLP中,把 x x x看做一个句子里的一个词语, y y y是这个词语的上下文词语,那么这里的 f f f,便是 NLP 中经常出现的『语言模型』(language model),这个模型的目的,就是判断 ( x , y ) (x,y) (x,y) 这个样本,是否符合自然语言的法则,更通俗点说就是:词语 x x x和词语 y y y放在一起,是不是人话。
Word2vec正是来源于这个思想,但它的最终目的,不是要把 f f f 训练得多么完美,而是只关心模型训练完后的副产物——模型参数(这里特指神经网络的权重),并将这些参数,作为输入 x x x 的某种向量化的表示,这个向量便叫做——词向量.
我们来看个例子,如何用 Word2vec 寻找相似词:
- 对于一句话:『她们 夸 吴彦祖 帅 到 没朋友』,如果输入 x x x 是『吴彦祖』,那么 y y y 可以是『她们』、『夸』、『帅』、『没朋友』这些词
- 现有另一句话:『她们 夸 我 帅 到 没朋友』,如果输入 x x x 是『我』,那么不难发现,这里的上下文 y y y 跟上面一句话一样
- 从而 f(吴彦祖) = f(我) = y,所以大数据告诉我们:我 = 吴彦祖(完美的结论)
Skip-gram 和 CBOW 的简单情形
我们先来看个最简单的例子。上面说到, y y y 是 x x x 的上下文,所以 y y y 只取上下文里一个词语的时候,语言模型就变成:
- 用当前词 x x x 预测它的下一个词 y y y
但如上面所说,一般的数学模型只接受数值型输入,这里的 x x x 该怎么表示呢? 显然不能用 Word2vec,因为这是我们训练完模型的产物,现在我们想要的是 x x x 的一个原始输入形式。
- 答案是:one-hot encoder
所谓 one-hot encoder,其思想跟特征工程里处理类别变量的 one-hot 一样。本质上是用一个只含一个 1、其他都是 0 的向量来唯一表示词语。
我举个例子,假设全世界所有的词语总共有 V V V 个,这 V V V 个词语有自己的先后顺序,假设『吴彦祖』这个词是第1个词,『我』这个单词是第2个词,那么『吴彦祖』就可以表示为一个 V V V 维全零向量、把第1个位置的0变成1,而『我』同样表示为 V V V 维全零向量、把第2个位置的0变成1。这样,每个词语都可以找到属于自己的唯一表示。
OK,那我们接下来就可以看看 Skip-gram 的网络结构了, x x x 就是上面提到的 one-hot encoder 形式的输入, y y y 是在这 V V V 个词上输出的概率,我们希望跟真实的 y y y 的 one-hot encoder 一样。
首先说明一点:隐层的激活函数其实是线性的,相当于没做任何处理(这也是 Word2vec 简化之前语言模型的独到之处),我们要训练这个神经网络,用反向传播算法,本质上是链式求导,在此不展开说明了,
当模型训练完后,最后得到的其实是神经网络的权重,比如现在输入一个 x x x 的 one-hot encoder: [1,0,0,…,0],对应刚说的那个词语『吴彦祖』,则在输入层到隐含层的权重里,只有对应 1 这个位置的权重被激活,这些权重的个数,跟隐含层节点数是一致的,从而这些权重组成一个向量 v x v_{x} vx 来表示 x x x,而因为每个词语的 one-hot encoder 里面 1的位置是不同的,所以,这个向量 v x v_{x} vx 就可以用来唯一表示 x x x。
注意:上面这段话说的就是 Word2vec 的精髓
此外,我们刚说了,输出 y y y 也是用 V V V 个节点表示的,对应 V V V个词语,所以其实,我们把输出节点置成 [1,0,0,…,0],它也能表示『吴彦祖』这个单词,但是激活的是隐含层到输出层的权重,这些权重的个数,跟隐含层一样,也可以组成一个向量 v y v_{y} vy,跟上面提到的 v x v_{x} vx 维度一样,并且可以看做是词语『吴彦祖』的另一种词向量。而这两种词向量 v x v_{x} vx 和 v y v_{y} vy,正是 Mikolov 在论文里所提到的,『输入向量』和『输出向量』,一般我们用『输入向量』。
需要提到一点的是,这个词向量的维度(与隐含层节点数一致)一般情况下要远远小于词语总数 V V V 的大小,所以 Word2vec 本质上是一种降维操作——把词语从 one-hot encoder 形式的表示降维到 Word2vec 形式的表示。
Skip-gram更一般的情形
上面讨论的是最简单情形,即 y y y 只有一个词,当 y y y 有多个词时,网络结构如下:
可以看成是单个x->单个y模型的并联,cost function 是单个 cost function 的累加(取log之后)
如果你想深入探究这些模型是如何并联、 cost function的形式怎样,不妨仔细阅读参考资料, 在此我们不展开。
CBOW更一般的情形
跟 Skip-gram 相似,只不过:
Skip-gram 是预测一个词的上下文,而 CBOW 是用上下文预测这个词
网络结构如下
和 kip-gram 的模型并联不同,这里是输入变成了多个单词,所以要对输入处理下(一般是求和然后平均),输出的 cost function 不变,在此依然不展开,建议你阅读参考资料.
Word2vec 的训练trick
相信很多初次踩坑的同学,会跟我一样陷入 Mikolov 那篇论文里提到的 hierarchical softmax 和 negative sampling 里不能自拔,但其实,它们并不是 Word2vec 的精髓,只是它的训练技巧,但也不是它独有的训练技巧。
Hierarchical softmax 只是 softmax 的一种近似形式,而 negative sampling 也是从其他方法借鉴而来。
为什么要用训练技巧呢? 如我们刚提到的,Word2vec 本质上是一个语言模型,它的输出节点数是 V V V 个,对应了 V V V 个词语,本质上是一个多分类问题,但实际当中,词语的个数非常非常多,会给计算造成很大困难,所以需要用技巧来加速训练。
这里我总结了一下这两个 trick 的本质,有助于大家更好地理解,在此也不做过多展开.
-
hierarchical softmax
- 本质是把 N N N 分类问题变成 l o g ( N ) log(N) log(N)次二分类
-
negative sampling
- 本质是预测总体类别的一个子集
扩展
很多时候,当我们面对林林总总的模型、方法时,我们总希望总结出一些本质的、共性的东西,以构建我们的知识体系,比如我在分类和回归的本质里,原创性地梳理了分类模型和回归模型的本质联系,比如在词嵌入领域,除了 Word2vec之外,还有基于共现矩阵分解的 GloVe 等等词嵌入方法。
深入进去我们会发现,神经网络形式表示的模型(如 Word2vec),跟共现矩阵分解模型(如 GloVe),有理论上的相通性. ——来斯惟博士在它的博士论文附录部分,证明了 Skip-gram 模型和 GloVe 的 cost fucntion 本质上是一样的。是不是一个很有意思的结论? 所以在实际应用当中,这两者的差别并不算很大,尤其在很多 high-level 的 NLP 任务(如句子表示、命名体识别、文档表示)当中,经常把词向量作为原始输入,而到了 high-level 层面,差别就更小了。
鉴于词语是 NLP 里最细粒度的表达,所以词向量的应用很广泛,既可以执行词语层面的任务,也可以作为很多模型的输入,执行 high-level 如句子、文档层面的任务,包括但不限于:
- 计算相似度
- 寻找相似词
- 信息检索
- 作为 SVM/LSTM 等模型的输入
- 中文分词
- 命名体识别
- 句子表示
- 情感分析
- 文档表示
- 文档主题判别
实战
上面讲了这么多理论细节,其实在真正应用的时候,只需要调用 Gensim (一个 Python 第三方库)的接口就可以。但对理论的探究仍然有必要,你能更好地知道参数的意义、模型结果受哪些因素影响,以及举一反三地应用到其他问题当中,甚至更改源码以实现自己定制化的需求。
这里我们将使用 Gensim 和 NLTK 这两个库,来完成对生物领域的相似词挖掘,将涉及:
- 解读
Gensim里Word2vec模型的参数含义 - 基于相应语料训练
Word2vec模型,并评估结果 - 对模型结果调优
正文
建议使用jupyter notebook,方便执行代码片段。并提前安装好gensim和nltk这两个python库
数据集
我们这里使用的是一个医学领域的数据集,这个数据集是一个非公开数据集,爬取了多篇医学论文的摘要,被我处理成一句话一行的形式。
我们可以再jupyter notebook上运行来查看数据集大致情况
import pandas as pd
data = pd.read_table('/content/drive/My Drive/VQA/bioCorpus_5000.txt',header=None)
print(data.shape)
data.head()

可以看到,这个数据集相对还是比较干净的,因为我做了一些预处理,包括去除异常字符,首字母改小写等,但并没有做 stemming 之类的操作,个人觉得不同时态的单词应该区别对待。
模型训练
先import我们今天的主角–word2vec
from gensim.models import word2vec
word2vec接受的输入格式类似于
- [[‘I’, ‘am’, ‘hansome’], [‘Mu’, ‘wen’, ‘looks’, ‘cool’], …]
即一个列表,里面的元素也是列表,每个列表里代表一句话,把这句话的单词切割开作为列表元素
但当我们有非常多的句子而内存有限时,把他们都存储到列表并load到内存里,就不太合适了,所以我们此时定义一个生成器
# 用生成器的方式读取文件里的句子 适合读取大容量文件,而不用加载到内存中class MySentences(object):def __init__(self,fname):self.fname=fnamedef __iter__(self):for line in open(self.fname,'r'):yield line.split()
同时还可以定义一个训练函数,指定输入的文件路径和待输出的模型路径,如下
# 模型训练函数
def w2vTrain(f_input, model_output): sentences = MySentences(DataDir+f_input)w2v_model = word2vec.Word2Vec(sentences, min_count = MIN_COUNT, workers = CPU_NUM, size = VEC_SIZE,window = CONTEXT_WINDOW)w2v_model.save(ModelDir+model_output)
注意到,这里的word2vec.Word2Vec()便是word2vec在gensim中的实现,里面的而参数解释如下:
-
min_count: 对于词频 <min_count的单词,将舍弃(其实最合适的方法是用 UNK 符号代替,即所谓的『未登录词』,这里我们简化起见,认为此类低频词不重要,直接抛弃) -
workers: 可以并行执行的核心数,需要安装 Cython 才能起作用(安装 Cython 的方法很简单,直接 pip install cython) -
size: 词向量的维度,神经网络隐层节点数 -
window: 目标词汇的上下文单词距目标词的最长距离,很好理解,比如 CBOW 模型是用一个词的上下文预测这个词,那这个上下文总得有个限制,如果取得太多,距离目标词太远,有些词就没啥意义了,而如果取得太少,又信息不足,所以 window 就是上下文的一个最长距离
在理解这些参数的含义以后,我们便可以根据自己的数据集真实情况,手动设置。我们这里用到的是个小数据集,所以参数一般都不会设置很大,训练过程如下
# 训练
DataDir = "/content/drive/My Drive/VQA/"
ModelDir = "/content/drive/My Drive/VQA/"
MIN_COUNT = 4
CPU_NUM = 2 # 需要预先安装 Cython 以支持并行
VEC_SIZE = 20
CONTEXT_WINDOW = 5 # 提取目标词上下文距离最长5个词f_input = "bioCorpus_5000.txt"
model_output = "test_w2v_model"w2vTrain(f_input, model_output)
模型评估
模型训练好后,我们先加载一下本地模型
# 加载模型
w2v_model = word2vec.Word2Vec.load(ModelDir+model_output)
这里我们的评估方法,就是查找一些现有词的相似词,看看是否make sense,比如我们查找body这个词的近义词
w2v_model.most_similar('body') # 结果一般
[('in', 0.9992338418960571),('liver', 0.9990773797035217),('serum', 0.9990760684013367),('acid', 0.9990513324737549),('pH', 0.999042809009552),('to', 0.9989815354347229),('and', 0.9989808797836304),('metabolism', 0.9989798069000244),('rat', 0.9989719390869141),('The', 0.9989321827888489)]
左边一列是相似词,右边是相似度,我们可以看到,除了 sodium, function这些比较make sense的词外,混入了 possible, .这些明显不make sense 的词
我们再看下heart的近义词
w2v_model.most_similar('heart') # 结果太差
[('on', 0.999566912651062),('protein', 0.9994598627090454),('inhibition', 0.999455988407135),('response', 0.9993799328804016),('tissue', 0.9993324279785156),('normal', 0.9993281364440918),('during', 0.9993237853050232),('proceedings', 0.9993192553520203),('isolated', 0.9993017911911011),('chronic', 0.9992607235908508)]
模型调优
混入的这些奇怪的东西,在 NLP 里面我们叫『停止词』,也就是像常见代词、介词之类,造成这种结果的原因我认为有二
-
参数设置不佳,比如 vec_size 设置的太小,导致这 20 个维度不足以 capture单词间不同的信息,所以我们需要继续调整超参数
-
数据集较小,因此停止词占据了太多信息量
调节参数的方法我就不多讨论了,这是门玄学(好吧其实是觉得太boring,有空试试贝叶斯调参。针对第二个问题,我们可以事先去除数据集中的停止词,方法如下,首先从 nltk 里 import 停止词列表
# 停止词
import nltk
nltk.download('stopwords')
from nltk.corpus import stopwords
stopwords=stopwords.words('english')
我们可以看下停止词都有啥
stopwords[:20]['i','me','my','myself','we','our','ours','ourselves','you',"you're","you've","you'll","you'd",'your','yours','yourself','yourselves','he','him','his']
接下来我们需要在读取数据集每句话之后,对该句话进行处理,再扔进 word2vec,所以我们需要定义一个新的训练函数,再原来基础上加上去除停止词的操作,并重新训练模型(为了方便对比,参数设置跟上面一样保持不变)
# 重新训练
# 模型训练函数
def w2vTrain_removeStopWords(f_input, model_output): sentences = list(MySentences(DataDir+f_input))for idx,sentence in enumerate(sentences):sentence = [w for w in sentence if w not in stopwords]sentences[idx]=sentencew2v_model = word2vec.Word2Vec(sentences, min_count = MIN_COUNT, workers = CPU_NUM, size = VEC_SIZE)w2v_model.save(ModelDir+model_output)w2vTrain_removeStopWords(f_input, model_output)
w2v_model = word2vec.Word2Vec.load(ModelDir+model_output)
接下来我们再看看看效果
w2v_model.most_similar('body')
[('The', 0.9393178224563599),('mechanism', 0.939207911491394),('liver', 0.9391828775405884),('serum', 0.9390921592712402),('pH', 0.9387758374214172),('metabolism', 0.9385097026824951),('uptake', 0.9363429546356201),('acid', 0.9353644847869873),('properties', 0.9350367784500122),('enzymes', 0.9347226619720459)]
恩,除了 The 之外,其他都还比较 make sense(但是相似度依然是0.9+,明显太高了,所以还是要调超参数的)
w2v_model.most_similar('heart') # 结果一般
[('protein', 0.9816111326217651),('inhibition', 0.9803719520568848),('Effect', 0.979965329170227),('response', 0.9796340465545654),('proceedings', 0.978588879108429),('.', 0.978377103805542),('normal', 0.9782481789588928),('liver', 0.9780206680297852),('rat', 0.9776134490966797),('effects', 0.9773460030555725)]
参考资料总结
先大概说下我深挖 word2vec 的过程:
先是按照惯例,看了 Mikolov 关于 Word2vec 的两篇原始论文,然而发现看完依然是一头雾水,似懂非懂,主要原因是这两篇文章省略了太多理论背景和推导细节;
然后翻出 Bengio 03年那篇JMLR和 Ronan 11年那篇JMLR,看完对语言模型、用CNN处理NLP任务有所了解,但依然无法完全吃透 word2vec;
这时候我开始大量阅读中英文博客,其中 北漂浪子 的一篇阅读量很多的博客吸引了我的注意,里面非常系统地讲解了 Word2vec 的前因后果,最难得的是深入剖析了代码的实现细节,看完之后细节方面了解了很多,不过还是觉得有些迷雾;
终于,我在 quora 上看到有人推荐 Xin Rong 的那篇英文paper,看完之后只觉醍醐灌顶,酣畅淋漓,相见恨晚,成为我首推的 Word2vec 参考资料。
下面我将详细列出我阅读过的所有 Word2vec 相关的参考资料,并给出评价
- Mikolov 两篇原论文:
- 『Distributed Representations of Sentences and Documents』
- 贡献:在前人基础上提出更精简的语言模型(language model)框架并用于生成词向量,这个框架就是 Word2vec
『Efficient estimation of word representations in vector space』 - 贡献:专门讲训练 Word2vec 中的两个trick:hierarchical softmax 和 negative sampling
- 优点:Word2vec 开山之作,两篇论文均值得一读
- 缺点:只见树木,不见森林和树叶,读完不得要义。这里『森林』指 word2vec 模型的理论基础——即 以神经网络形式表示的语言模型『树叶』指具体的神经网络形式、理论推导、hierarchical softmax 的实现细节等等
- 贡献:在前人基础上提出更精简的语言模型(language model)框架并用于生成词向量,这个框架就是 Word2vec
- 北漂浪子的博客:
- 『深度学习word2vec 笔记之基础篇』
- 优点:非常系统,结合源码剖析,语言平实易懂
- 缺点:太啰嗦,有点抓不住精髓
- Yoav Goldberg 的论文:
- 『word2vec Explained- Deriving Mikolov et al.’s Negative-Sampling Word-Embedding Method』
- 优点:对 negative-sampling 的公式推导非常完备
- 缺点:不够全面,而且都是公式,没有图示,略显干枯
- Xin Rong 的论文:
- 『word2vec Parameter Learning Explained』:重点推荐!理论完备由浅入深非常好懂,且直击要害,既有 high-level 的 intuition 的解释,也有细节的推导过程
一定要看这篇paper!一定要看这篇paper!一定要看这篇paper!
- 来斯惟的博士论文
- 『基于神经网络的词和文档语义向量表示方法研究』以及他的博客(网名:licstar)可以作为更深入全面的扩展阅读,这里不仅仅有 word2vec,而是把词嵌入的所有主流方法通通梳理了一遍
- 几位大牛在知乎的回答:
- 『word2vec 相比之前的 Word Embedding 方法好在什么地方?』刘知远、邱锡鹏、李韶华等知名学者从不同角度发表对 Word2vec 的看法,非常值得一看
- Sebastian 的博客:
- 『On word embeddings - Part 2: Approximating the Softmax』详细讲解了 softmax 的近似方法,Word2vec 的 hierarchical softmax 只是其中一种
参考文献
- https://zhuanlan.zhihu.com/p/26306795
- Word2vec实战