准备工作
我先是在板子里通过LTTng Stream的方式将log保存在了上位机里。
然后在上位机中打开TraceCompass分析log。
导出整理log数据
然后我在events表格中搜索我的进程名,发现主要是sched_switch sched_waking sched_wakeup这三类。
然后我又搜索了一下,发现sched_switch是真正在cpu上切换了进程,waking 和 wakeup是唤醒过程的开始和结束。分别位于try_to_wake_up的入口和出口。
我准备观察一下运行周期。然后我在内容区域搜索:
next_comm=我的进程名
之后选中所有的log 导出到csv中。
然后编写公式上下两个时间戳相减。
时间戳的格式可以在Tracecompass的属性设置里 Trace那个条目下方便的更改。
得出时间差后,开启筛选。轻松找到异常的数据。
回到Tracecompass分析
我发现30ms周期的任务在某一次唤醒间隔了46ms.
我找到shced_waking 和sched_switch的位置。
发现之间确实间隔了16ms属于是wait for cpu的状态。
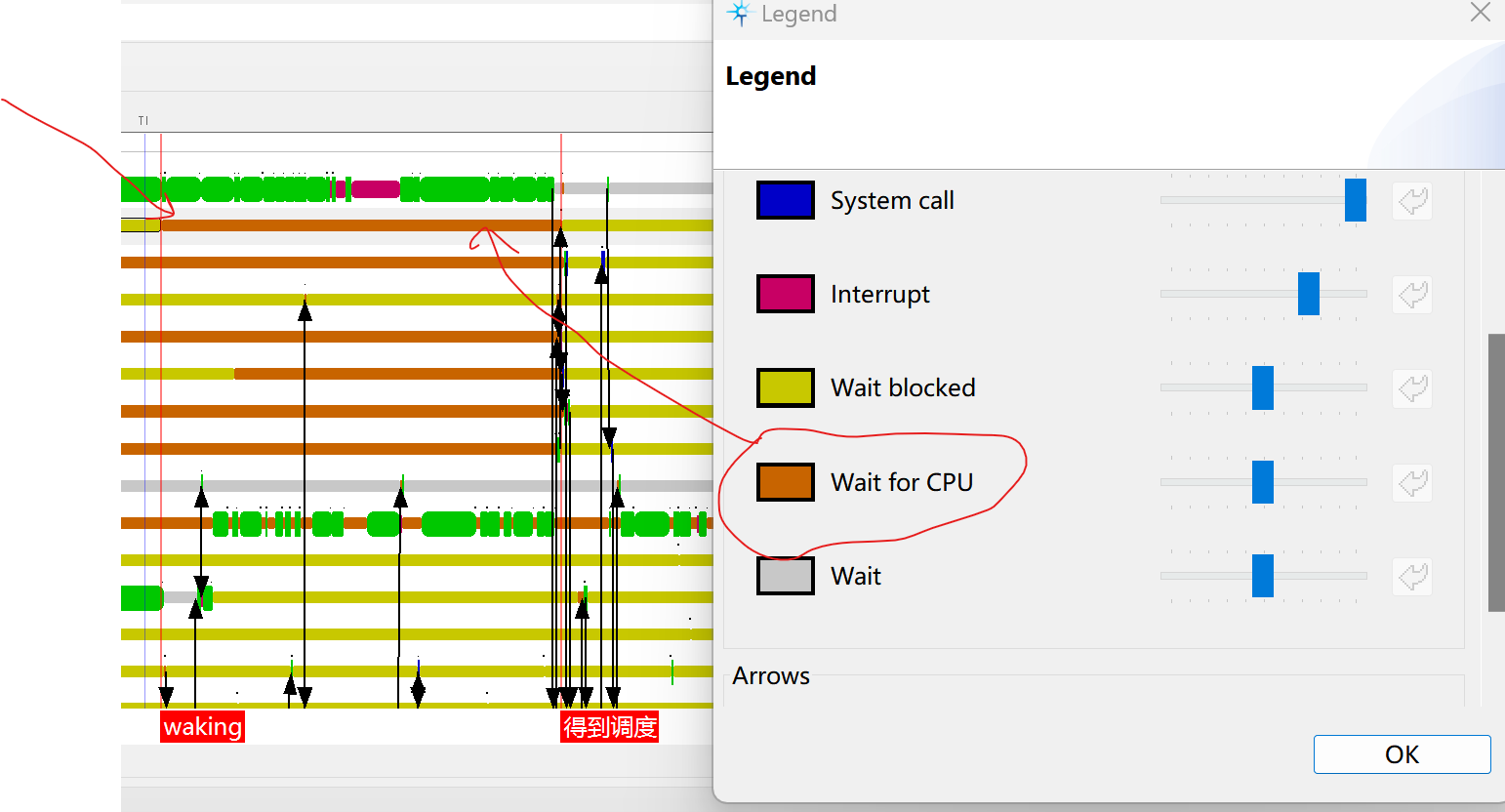
在另外的视图中显示被抢占。:
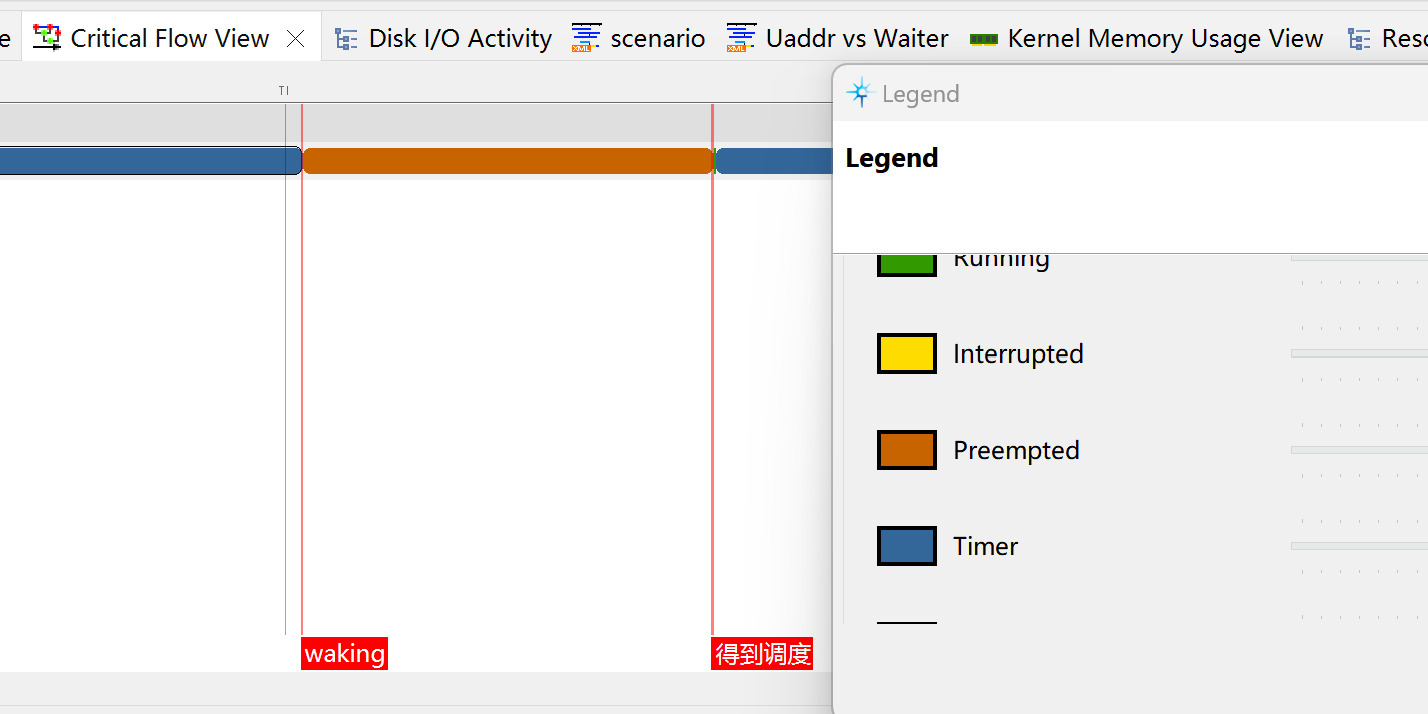
在仔细观察了执行流之后发现:
该进程先是在CPU0上被唤醒,但是CPU0上先唤醒了一个同优先级的RT进程。
在执行这些RT进程之前,CPU0长期陷入一个叫kworker的进程中。没有被抢占。
这个kworker还多次被irq或者软中断打断。
另外,kworker释放之后,显示被先来的同优先级RT进程占有,中间还被另外一个高优先级的RT进程抢占。
最后我观测的进程等不下去了,迁移到领一个cpu上。得到执行。
在这个过程中,另外一个cpu多次得到闲置。
这里我发现一个小技巧,可以在resources视图下,沿着cpu来走,结合调度flow看cpu的分配。
那这个优先级是20 nice=0的普普通通的kworker是什么?
在往前面看,这个kworker曾经多次被其他的rt进程抢占,甚至优先级不如本进程高。
那我怀疑可能是什么资源被占用了吧。这样需要具体进代码研究了。
好像从内核函数上并没有看出来。
![[解决] We don‘t have an op for aten::normal but it isn‘t a special case](/images/no-images.jpg)