目录
1. 插入区间 🌟🌟🌟
2. 单词拆分 🌟🌟
3. 不同路径 🌟🌟
🌟 每日一练刷题专栏 🌟
Golang每日一练 专栏
Python每日一练 专栏
C/C++每日一练 专栏
Java每日一练 专栏
1. 插入区间
给你一个 无重叠的 ,按照区间起始端点排序的区间列表。
在列表中插入一个新的区间,你需要确保列表中的区间仍然有序且不重叠(如果有必要的话,可以合并区间)。
示例 1:
输入:intervals = [[1,3],[6,9]], newInterval = [2,5] 输出:[[1,5],[6,9]]
示例 2:
输入:intervals = [[1,2],[3,5],[6,7],[8,10],[12,16]], newInterval = [4,8] 输出:[[1,2],[3,10],[12,16]] 解释:这是因为新的区间 [4,8] 与 [3,5],[6,7],[8,10] 重叠。
示例 3:
输入:intervals = [], newInterval = [5,7] 输出:[[5,7]]
示例 4:
输入:intervals = [[1,5]], newInterval = [2,3] 输出:[[1,5]]
示例 5:
输入:intervals = [[1,5]], newInterval = [2,7] 输出:[[1,7]]
提示:
0 <= intervals.length <= 104intervals[i].length == 20 <= intervals[i][0] <= intervals[i][1] <= 105intervals根据intervals[i][0]按 升序 排列newInterval.length == 20 <= newInterval[0] <= newInterval[1] <= 105
以下程序实现了这一功能,请你填补空白处内容:
```c++
#include <stdio.h>
#include <stdlib.h>
static int compare(const void *a, const void *b)
{
return ((int *)a)[0] - ((int *)b)[0];
}
int **insert(int **intervals, int intervalsSize, int *intervalsColSize, int *newInterval,
int newIntervalSize, int *returnSize, int **returnColumnSizes)
{
int i, len = 0;
int *tmp = malloc((intervalsSize + 1) * 2 * sizeof(int));
for (i = 0; i < intervalsSize; i++)
{
tmp[i * 2] = intervals[i][0];
tmp[i * 2 + 1] = intervals[i][1];
}
tmp[i * 2] = newInterval[0];
tmp[i * 2 + 1] = newInterval[1];
qsort(tmp, intervalsSize + 1, 2 * sizeof(int), compare);
int **results = malloc((intervalsSize + 1) * sizeof(int *));
results[0] = malloc(2 * sizeof(int));
results[0][0] = tmp[0];
results[0][1] = tmp[1];
for (i = 1; i < intervalsSize + 1; i++)
{
results[i] = malloc(2 * sizeof(int));
if (tmp[i * 2] > results[len][1])
{
len++;
________________________;
}
else if (tmp[i * 2 + 1] > results[len][1])
{
results[len][1] = tmp[i * 2 + 1];
}
}
len += 1;
*returnSize = len;
*returnColumnSizes = malloc(len * sizeof(int));
for (i = 0; i < len; i++)
{
(*returnColumnSizes)[i] = 2;
}
return results;
}
int main(int argc, char **argv)
{
if (argc < 3 || argc % 2 == 0)
{
fprintf(stderr, "Usage: ./test new_s new_e s0 e0 s1 e1...");
exit(-1);
}
int new_interv[2];
new_interv[0] = atoi(argv[1]);
new_interv[1] = atoi(argv[2]);
int i, count = 0;
int *size = malloc((argc - 3) / 2 * sizeof(int));
int **intervals = malloc((argc - 3) / 2 * sizeof(int *));
for (i = 0; i < (argc - 3) / 2; i++)
{
intervals[i] = malloc(2 * sizeof(int));
intervals[i][0] = atoi(argv[i * 2 + 3]);
intervals[i][1] = atoi(argv[i * 2 + 4]);
}
int *col_sizes;
int **results = insert(intervals, (argc - 3) / 2, size, new_interv, 2, &count, &col_sizes);
for (i = 0; i < count; i++)
{
printf("[%d,%d]\n", results[i][0], results[i][1]);
}
return 0;
}
```
出处:
https://edu.csdn.net/practice/25949978
代码:
#include <stdio.h>
#include <stdlib.h>static int compare(const void *a, const void *b)
{return ((int *)a)[0] - ((int *)b)[0];
}int **insert(int **intervals, int intervalsSize, int *intervalsColSize, int *newInterval,int newIntervalSize, int *returnSize, int **returnColumnSizes)
{int i, len = 0;int *tmp = (int*)malloc((intervalsSize + 1) * 2 * sizeof(int));for (i = 0; i < intervalsSize; i++){tmp[i * 2] = intervals[i][0];tmp[i * 2 + 1] = intervals[i][1];}tmp[i * 2] = newInterval[0];tmp[i * 2 + 1] = newInterval[1];qsort(tmp, intervalsSize + 1, 2 * sizeof(int), compare);int **results = (int**)malloc((intervalsSize + 1) * sizeof(int *));results[0] = (int*)malloc(2 * sizeof(int));results[0][0] = tmp[0];results[0][1] = tmp[1];for (i = 1; i < intervalsSize + 1; i++){results[i] = (int*)malloc(2 * sizeof(int));if (tmp[i * 2] > results[len][1]){len++;results[len][0] = tmp[i * 2];results[len][1] = tmp[i * 2 + 1];}else if (tmp[i * 2 + 1] > results[len][1]){results[len][1] = tmp[i * 2 + 1];}}len += 1;*returnSize = len;*returnColumnSizes = (int*)malloc(len * sizeof(int));for (i = 0; i < len; i++){(*returnColumnSizes)[i] = 2;}return results;
}int main(int argc, char* argv[])
{if (argc<3) return 1;int new_interv[2];new_interv[0] = atoi((char*)argv[1]);new_interv[1] = atoi((char*)argv[2]);int i, count = 0;int *size = (int*)malloc((argc - 3) / 2 * sizeof(int));int **intervals = (int**)malloc((argc - 3) / 2 * sizeof(int *));for (i = 0; i < (argc - 3) / 2; i++){intervals[i] = (int*)malloc(2 * sizeof(int));intervals[i][0] = atoi((char*)argv[i * 2 + 3]);intervals[i][1] = atoi((char*)argv[i * 2 + 4]);}int *col_sizes;int **results = insert(intervals, (argc - 3) / 2, size, new_interv, 2, &count, &col_sizes);for (i = 0; i < count; i++){printf("[%d,%d]\n", results[i][0], results[i][1]);}return 0;
}
输出:
略
2. 单词拆分
给定一个非空字符串 s 和一个包含非空单词的列表 wordDict,判定 s 是否可以被空格拆分为一个或多个在字典中出现的单词。
说明:
- 拆分时可以重复使用字典中的单词。
- 你可以假设字典中没有重复的单词。
示例 1:
输入: s = "leetcode", wordDict = ["leet", "code"] 输出: true 解释: 返回 true 因为 "leetcode" 可以被拆分成 "leet code"。
示例 2:
输入: s = "applepenapple", wordDict = ["apple", "pen"] 输出: true 解释: 返回 true 因为 "applepenapple" 可以被拆分成 "apple pen apple"。注意你可以重复使用字典中的单词。
示例 3:
输入: s = "catsandog", wordDict = ["cats", "dog", "sand", "and", "cat"] 输出: false
出处:
https://edu.csdn.net/practice/25949980
代码:
#include <bits/stdc++.h>
using namespace std;
class Solution
{
public:bool wordBreak(string s, vector<string> &wordDict){map<string, int> tmp;for (int i = 0; i < wordDict.size(); i++){tmp[wordDict[i]]++;}int n = s.length();vector<bool> res(n + 1, false);res[0] = true;for (int i = 0; i <= n; i++){for (int j = 0; j < i; j++){if (res[j] && tmp[s.substr(j, i - j)]){res[i] = true;break;}}}return res[n];}
};int main()
{Solution sol;string s = "leetcode";vector<string> wordDict = {"leet", "code"};cout << (sol.wordBreak(s, wordDict) ? "true" : "false") << endl;s = "applepenapple", wordDict = {"apple", "pen"};cout << (sol.wordBreak(s, wordDict) ? "true" : "false") << endl;s = "catsandog", wordDict = {"cats", "dog", "sand", "and", "cat"};cout << (sol.wordBreak(s, wordDict) ? "true" : "false") << endl;return 0;
}输出:
true
true
false
3. 不同路径
一个机器人位于一个 m x n 网格的左上角 (起始点在下图中标记为 “Start” )。
机器人每次只能向下或者向右移动一步。机器人试图达到网格的右下角(在下图中标记为 “Finish” )。
问总共有多少条不同的路径?
示例 1:
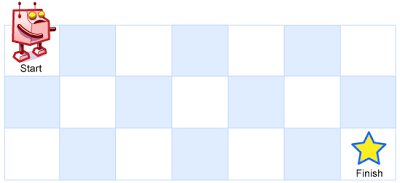
输入:m = 3, n = 7 输出:28
示例 2:
输入:m = 3, n = 2 输出:3 解释:从左上角开始,总共有 3 条路径可以到达右下角。 1. 向右 -> 向下 -> 向下 2. 向下 -> 向下 -> 向右 3. 向下 -> 向右 -> 向下
示例 3:
输入:m = 7, n = 3 输出:28
示例 4:
输入:m = 3, n = 3 输出:6
提示:
1 <= m, n <= 100- 题目数据保证答案小于等于
2 * 109
以下程序实现了这一功能,请你填补空白处内容:
```c
#include <stdio.h>
#include <stdlib.h>
static int uniquePaths(int m, int n)
{
int row, col;
int *grids = malloc(m * n * sizeof(int));
for (col = 0; col < m; col++)
{
grids[col] = 1;
}
for (row = 0; row < n; row++)
{
grids[row * m] = 1;
}
for (row = 1; row < n; row++)
{
for (col = 1; col < m; col++)
{
______________________________;
}
}
return grids[m * n - 1];
}
int main(int argc, char **argv)
{
if (argc != 3)
{
fprintf(stderr, "Usage: ./test m n\n");
exit(-1);
}
printf("%d\n", uniquePaths(atoi(argv[1]), atoi(argv[2])));
return 0;
}
···
出处:
https://edu.csdn.net/practice/24116334
代码:
#include <stdio.h>
#include <stdlib.h>static int uniquePaths(int m, int n)
{int row, col;int *grids = (int*)malloc(m * n * sizeof(int));for (col = 0; col < m; col++){grids[col] = 1;}for (row = 0; row < n; row++){grids[row * m] = 1;}for (row = 1; row < n; row++){for (col = 1; col < m; col++){grids[row * m + col] = grids[row * m + col - 1] + grids[(row - 1) * m + col];}}return grids[m * n - 1];
}int main()
{printf("%d\n", uniquePaths(3, 7));printf("%d\n", uniquePaths(3, 2));printf("%d\n", uniquePaths(7, 3));printf("%d\n", uniquePaths(3, 3));return 0;
}输出:
28
3
28
6
🌟 每日一练刷题专栏 🌟
✨ 持续,努力奋斗做强刷题搬运工!
👍 点赞,你的认可是我坚持的动力!
🌟 收藏,你的青睐是我努力的方向!
✎ 评论,你的意见是我进步的财富!
☸ 主页:https://hannyang.blog.csdn.net/
 | Golang每日一练 专栏 |
 | Python每日一练 专栏 |
 | C/C++每日一练 专栏 |
 | Java每日一练 专栏 |