正文
模块(Module)、组件(Component)、包(Package),这些概念对于我们技术同学并不陌生,但并不是所有人都能理解其要义。
深入理解之后,我才发现,其背后的深意是分类思维。而这种分类也是应用架构的核心所在,通过不同粒度、不同层次的分类,把复杂的软件系统实现控制在可以被理解、被维护的程度。否则,对于动则上100万行代码的软件,人类根本没有办法理解和维护。
试想一个极端情况,假如没有这些概念协助我们分类,我们把所有业务逻辑都写在一个类里面,会是什么样的结果呢?我们很多的“非人类”系统,正是因为没有进行合理的分类造成的。
早期,我不喜欢JavaScript的一个重要原因,正是因为其缺少像Java中package和jar的概念,导致代码的组织形式比较松散、随意。这个问题直到ES6、React才得到比较好的解决,在此之前,前端工程师不得不依靠seaJS,requireJS这些框架来做模块化、组件化的事情。
至此,你可能有疑问,分类有什么魔力?怎么就成了应用架构的核心了呢?客官别着急,由我细细道来。
分类的重要性
所谓分类,就是依据一定的标准对给定的事物进行组别的划分。我们人类天生就有分类的本能,例如,当我们观察下面这张图的时候。

无论是谁,乍一看到上面的六个黑点,都会认为共有两组墨点,每组三个。造成这种印象的原因主要是,人类大脑会自动将发现的所有事物以某种持续组织起来。基本上,大脑会认为同时发生的任何事物之间都存在某种关联,并且会将这些事物按某种逻辑模式组织起来。
之所以我们大脑有这样的本能,是因为人一次能够理解的思想或概念的数量是有限的。正如乔治米勒在他的论文《奇妙的数字7》中提出的。人类大脑的短期记忆无法一次容纳7个以上的记忆项目。所以,当信息量过大时,唯有归类分组才能帮助我们去理解和处理问题。
其实,自古及今,人类一直在做着归类/分类,早在春秋时期,《战国策》中就提出过“物以类聚,人以群分”的概念。
在互联网行业,我们会对客户进行分类,然后针对不同的客户进行分层运营,也是这个道理。
平常我们所说的分析和综合的背后,其实就是分类能力。分析是在一个类里面找差异性,综合是在不同事物中找联系、找共同性,而这个共同性相当于分类的维度。
分类思维的能力,直接体现的就是看透事物本质的能力。
应用架构中的分类思维
概念定义
在讨论架构之前,我们先来明确一下Module、Component和Package这几个概念。
因为这些概念一直以来存在不小的歧义。通过Stack Overflow上几十篇询问这些概念差异的提问,以及五花八门的回答就能可见一斑。
在一篇Stack Overflow的帖子[1]中,我们看到这样的回答:
The terms are similar. I generally think of a “module” as being larger than a “component”. A component is a single part, usually relatively small in scope, possibly general-purpose.
然而,另一篇Stack Overflow的帖子[2],却有着不同的答案:
There is n o criteria to measure which one is greater than the other. One component can contain list of modules, and one module also can contain many co mponents.
在《实现领域驱动设计》一书中,作者有这样的描述:
If you are using Java or C#, you are already familiar with Modules, though you know them by another name. Java calls them packages. C# calls them namespaces.
然而,在AngularJS的设计文档[3]中,它对Module和Component是这样定义的:
The module can be considered as a collection of components, Each component can use other components. One of many modules combines up to make an Application.
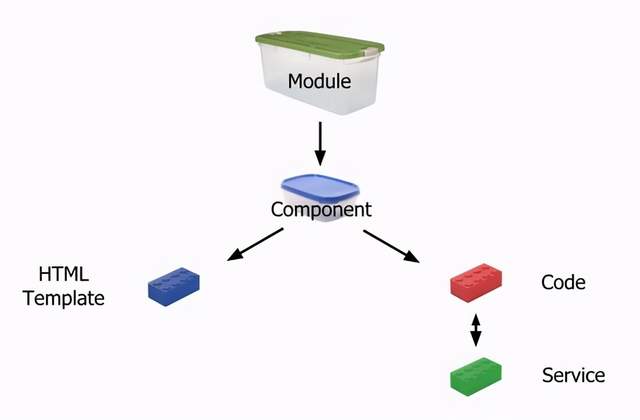
通过比较,结合我自己的认知,我更赞同AngularJS里面的定义,即Module是比Component更大的概念。比如在Maven中,Module是组成Application的第一级层次,而Component的粒度一般比Module要小,多个Component会组成一个Module。
因此,在进一步探讨之前,我特意对这些概念做如下定义:
-
应用(Application):应用系统,有多个Module组成,用方框表示。
-
模块(Module):一个Module是有一组Component构成,用正方体表示。
-
组件(Component):表示一个可以独立提供某方面功能的物件,用UML的组件图表示。
-
包(Package):Package相对比较tricky,它是一种组织形式,和粒度不是一个维度的,也就是说,一个Component可以包含多个Package,一个Package也可以包含多个Component。
基于上面的定义,他们的表示法(Notation)是这样的:

应用架构的要素
关于架构的定义有很多,我最喜欢,也是最简洁的定义是:

即架构是一种结构,是由物件(Components)+ 物件之间的关系 + 指导原则组成的。
应用架构也是如此,从大的层面来说,企业级应用都逃不过如下图所示的三层结构,即前端、后端和数据库。
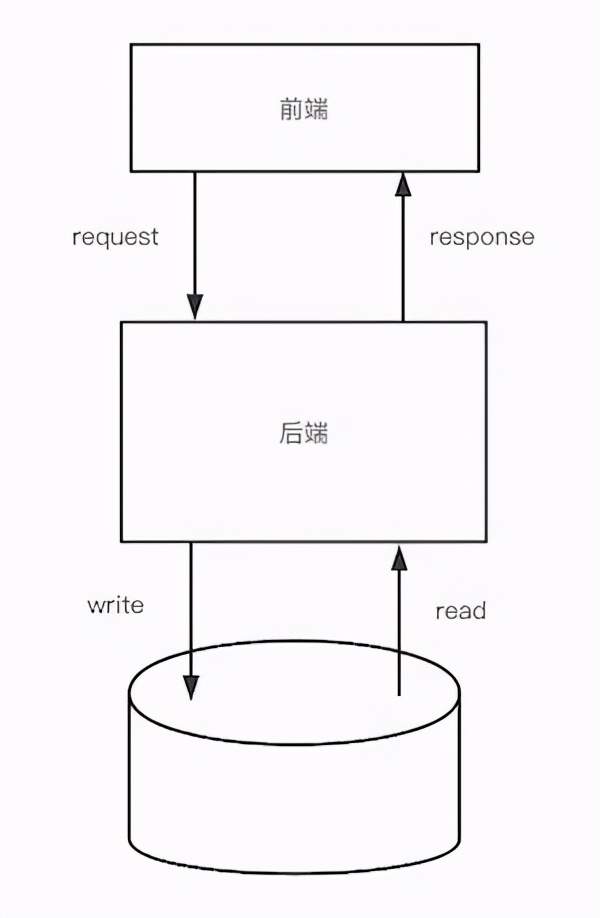
对于后端开发来说,应用层是我们的主战场,也是整个系统最复杂的部分(当然,前端也不简单),所有的业务逻辑都汇聚在此。所以,对于应用层,我们需要进行进一步拆分,而不仅仅是在这里写业务逻辑就完事了。
对应用层的进一步分层,就形成了COLA所提倡的四层结构,对应到Maven中,就是有4个Module,编译打包之后会有4个Jar。一个典型的应用,其Module呈现出如下的结构:
<modules> <module>cloudstore-adapter</module> <!--Adapter 层--> <module>cloudstore-app</module> <!--App 层--> <module>cloudstore-domain</module> <!--Domain 层--> <module>cloudstore-infrastructure</module> <!--Infra 层--> <module>cloudstore-client</module> <!--RPC SDK--> <module>start</module> <!--SpringBoot启动--> </modules>
当业务变得复杂时,这种分层结构自然比没有分层要好。这也是COLA一直致力要去解决的问题——控制复杂度。
从COLA 1.0的事无巨细,到COLA 3.0的化繁为简。我渐渐明白,COLA作为应用架构,其核心不是去提供功能,而是提供基模(Archetype)。
在1.0的时候,COLA提供了Interceptor能力,提供了Event Bus能力,提供了扩展点能力。一个是我认为大家“需要”这些,另一个是感觉NB的框架就应该面面俱到,没有几个高级功能都不好意思开源。事实证明,我犯了一个惯性错误——过度设计。Interceptor完全可以用AOP替代,内部事件和扩展点很少被用到。所以在COLA 3.0的时候,果断的去掉了这些“鸡肋”,只保留了扩展点功能。
回归到架构的本质,COLA的核心应该是规定应用的结构和规范,即应用架构基模(Archetype)。而不是去纠结那些锦上添花的功能。
升级到COLA 3.1
实际上,这样的回归工作,COLA 3.0已经做的差不多了。在这次3.1的升级中,除了进一步去除了Event Bus的功能之外,最重要的就是重新规范了分包策略,和扩充了原来控制层(Controller)的职责。
分包策略调整
分层是一种在功能维度上的横向切分,即每一层都有自己的职责。
-
Adapter层:路由用户request + 适配response。
-
App层:接收请求,联合domain层一起做业务处理。
-
Domain层:领域模型 + 领域能力。
-
Infrastructure层:技术细节(DB,Search,RPC…) + 防腐(Anti-corruption)。
分层处理没有问题,只是这种功能划分,会带来一个问题,即领域维度的内聚性会收到影响。当一个application只负责一个领域的时候没有问题。然而,当一个application包含多个业务领域的时候,这种内聚性缺失的弊端就比较明显了。
更好的分包策略是按领域划分,而不是按功能。因为,领域更内聚,功能是为领域服务的,应该归属于领域。
然而,不巧的是,在COLA应用架构里面,我们要综合横向功能维度的划分,和纵向领域维度的划分,两个都很好,两个都想要。怎么办?我们可以采用物理划分和逻辑划分相结合的办法。
横向上,我们用Module做有层次划分,属于物理划分。纵向上,通过Package来进行逻辑划分。最后,形成一个如下的结构:
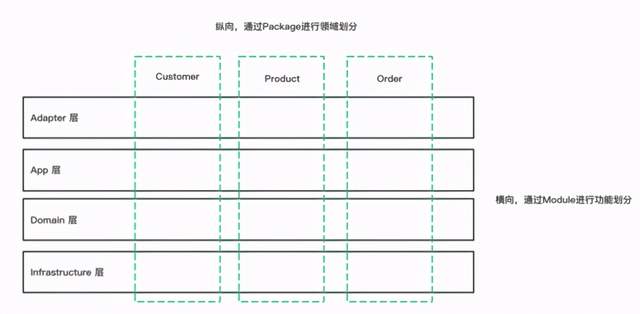
按照这个思想去分包,在工程中,Module下的顶层package不再是功能,而是领域:

按照领域的分包策略至少会带来两个好处:
-
系统的可理解性和可维护性更好,用白话说,就是找东西更好找了。
-
方便以后的拆分,比如下单域(Order)变得越来越复杂,需要拆出去,我们只需要把Order下面的东西迁移到一个新应用就好了。
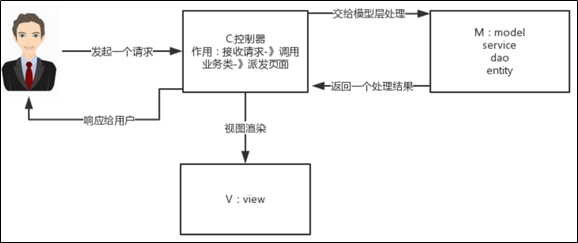
用Adatper代替Controller
Controller这个名字主要是来自于MVC,因为是MVC,所以自带了Web应用的烙印。然而,随着mobile的兴起,现在很少有应用仅仅只支持Web端,通常的标配是Web,Mobile,WAP三端都要支持。
在这样的背景下,狭义的控制层已经不能满足需求了,因为在这一层,不仅仅要做路由转发,还要做多端适配,类似于六边形架构中的Driving Adapter的角色。鉴于此,我们使用适配层(Adapter)替换掉了Controller,一方面,是为了呼应六边形架构;另一方面,的确也是需要做多端适配。
基于这样的变化,我重构了COLA Archetype,把Adapter作为一个层次凸显出来。实际上,Infrastructure也是适配器,是对技术实现的适配(或者叫解耦),比如,我需要数据来帮助构造Domain Entity,但是我不care这个数据是来自于DB、RPC还是Search,或者说,我可以在这些技术实现中进行自由切换,而不影响我Domain层和App层的稳定性。
改造后的COLA在架构风格,模块、组件以及分包策略上都会有所调整,具体变化请参考下面两张图。
COLA架构图:
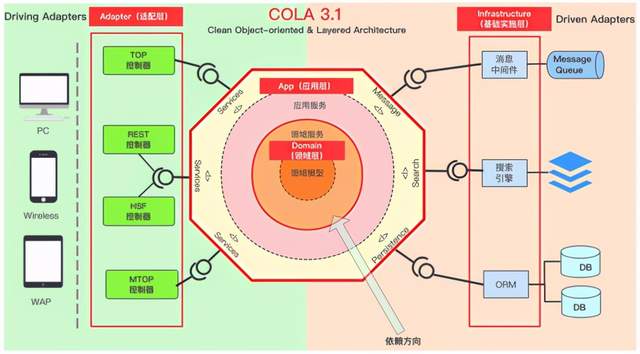
COLA3.1
COLA组件关系图:
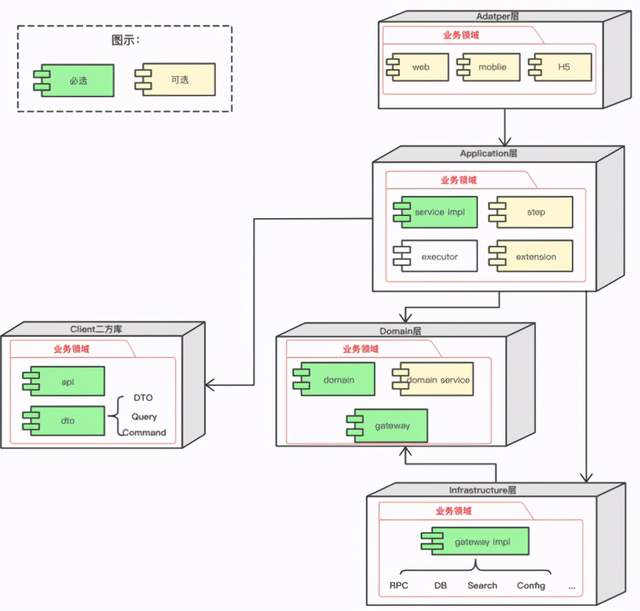
组织架构中的分类思维
这么重要的思维能力,其应用肯定不仅仅局限于架构设计的范畴。开篇已经说过了,分类是我们人类的本能,是分析和综合问题的重要手段。
生产关系决定生产力,好的组织结构会助力业务发展,反之,则会拖业务的后退。因此,大公司的CEO每年都会花很多时间在组织设计上,这也是为什么,在大厂,每年我们都会看到不小的组织调整。
看到一篇文章《苹果公司的组织架构是怎样的》[4],里面介绍了苹果成功和其优秀的组织架构有关系。如下图所示,传统企业偏向于业务型组织,而高科技企业偏向于职能型组织。
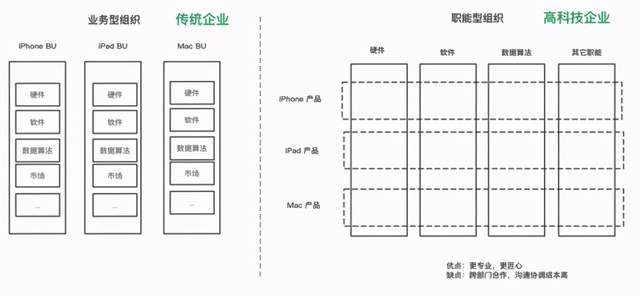
有没有感觉苹果的组织架构,和我们的COLA思想是一样的:),物理上,按照职能划分;逻辑上,按照业务和产品划分。
苹果这样的组织设计,是因为它是技术和创新驱动的公司,协作成本不是最大的问题,缺少专业性(技术不行),缺少创新才是攸关生死的大问题。所以他宁肯牺牲协同效率,也要确保专业性,也就是说,做摄像头的只做摄像头,做iOS的只做iOS,技术leader直接向CEO汇报,可以决定产品的发展方向。因为他们在这个领域更专业。
很早以前,史蒂夫·乔布斯就有这样的观点:苹果公司的经理们应该是他们管理领域的专家。在 1984 年的一次采访中,他说:
我们在苹果经历了那个阶段,当时我们出去想,哦,我们要成为一家大公司,让我们雇佣专业的管理人员。我们出去雇了一群专业的管理人员。一点也不管用……他们知道如何管理,但他们在专业方面什么都不知道。如果你是一个伟大的人,为什么你想为一个你什么都学不到的人工作?你知道什么是有趣的吗?你知道谁是最好的经理吗?他们是伟大的个人贡献者,他们从来都不想成为一名管理者,但却决定自己必须成为,因为没有其他人能够出色地完成工作。
说实话,看完这篇文章,我很感慨,一方面是佩服乔布斯的洞见能力,另一方面也为我们这个行业感到唏嘘,业务技术也是技术啊,却没有一个像样的培育发展技术的环境和土壤。
如今,业务技术Leader还有多少是专注在技术上呢,俨然都变成了业务Leader。如果技术Leader都变成了纯管理者,那么谁去关心技术,谁去关心代码,谁去关心工程师的成长呢?
分类学是科学也是艺术
最后,我还是要中庸一下,分类很重要,但同时也很难,带有一定的主观性。就像比尔.布莱森在《万物简史》里说的:
分类学有时候被描述成一门科学,有时候被描述成一种艺术,但实际上那是一个战场。即使到了今天,那个体系比许多人认为的还要混乱。以描述生物基本结构的门的划分为例。许多生物学家坚持认为总数30个门,但有的认为20来个门,而爱德华在《生命的多样性》一书里提出的数字高达令人吃惊的89门。
我们观察事物的视角不同,对问题的认知程度不同,得出来的分类也会不同。就拿COLA来说,直到现在的3.1版本,我个人认为其分层和分包的方式才相对比较合理。然而,很有可能在后期的迭代中,分类方式又会改变。
组织架构的分类方式也是一样,按照业务和职能划分,都可以。关键看其分类是否匹配你组织的特性,没有最好的分类,只有最合适的。
总结
互联网大厂比较喜欢的人才特点:对技术有热情,强硬的技术基础实力;主动,善于团队协作,善于总结思考。无论是哪家公司,都很重视高并发高可用技术,重视基础,所以千万别小看任何知识。面试是一个双向选择的过程,不要抱着畏惧的心态去面试,不利于自己的发挥。同时看中的应该不止薪资,还要看你是不是真的喜欢这家公司,是不是能真的得到锻炼。其实我写了这么多,只是我自己的总结,并不一定适用于所有人,相信经过一些面试,大家都会有这些感触。
**另外想要面试题及答案的小伙伴请点击这里自行领取,本人还整理收藏了2021年多家公司面试知识点以及各种技术点整理 **
下面有部分截图希望能对大家有所帮助。
公司,是不是能真的得到锻炼。其实我写了这么多,只是我自己的总结,并不一定适用于所有人,相信经过一些面试,大家都会有这些感触。
**另外想要面试题及答案的小伙伴请点击这里自行领取,本人还整理收藏了2021年多家公司面试知识点以及各种技术点整理 **
下面有部分截图希望能对大家有所帮助。