转自:量子位
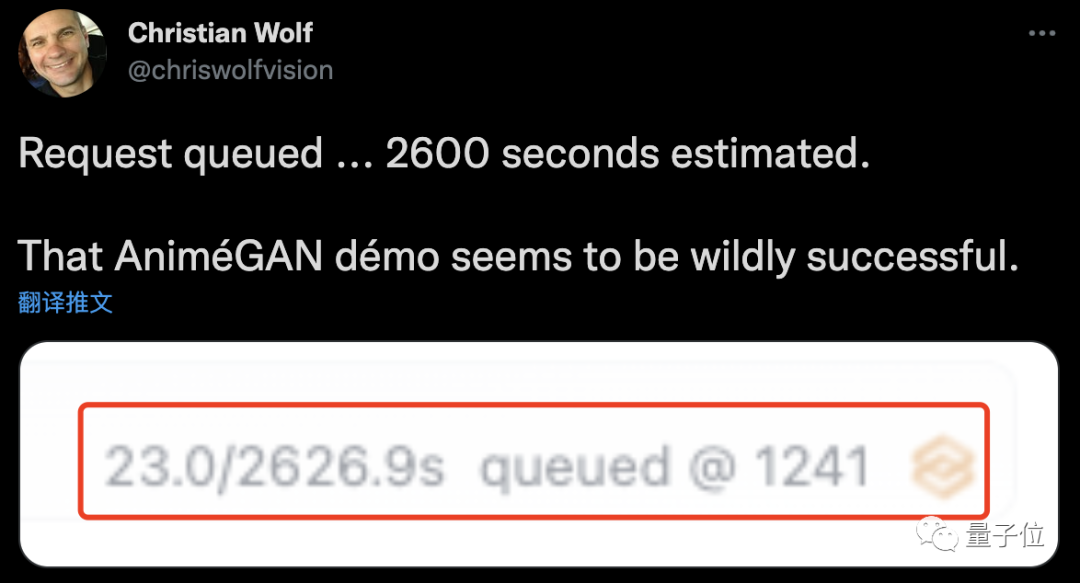
“排队1241人,等待2600秒……”
——这届网友为了看一眼自己在动漫里的样子,可真是拼了!
“始作俑者”是一款可以把人像变动漫的生成器。

只需一张图片或一段视频,无论男女老少、明星素人都可以一睹自己的“动漫风采”~
什么“国民老婆”王冰冰:

什么“国民妹妹”IU:

什么科技圈大佬、EDG成员、金发美女、容嬷嬷……

发丝、眉宇,甚至眼神里流露出来的情绪,都给你“描绘”得淋漓尽致……


这也难怪网友把服务器都给挤爆了 。
。
随便翻翻大家的作品,简直是深不见底。
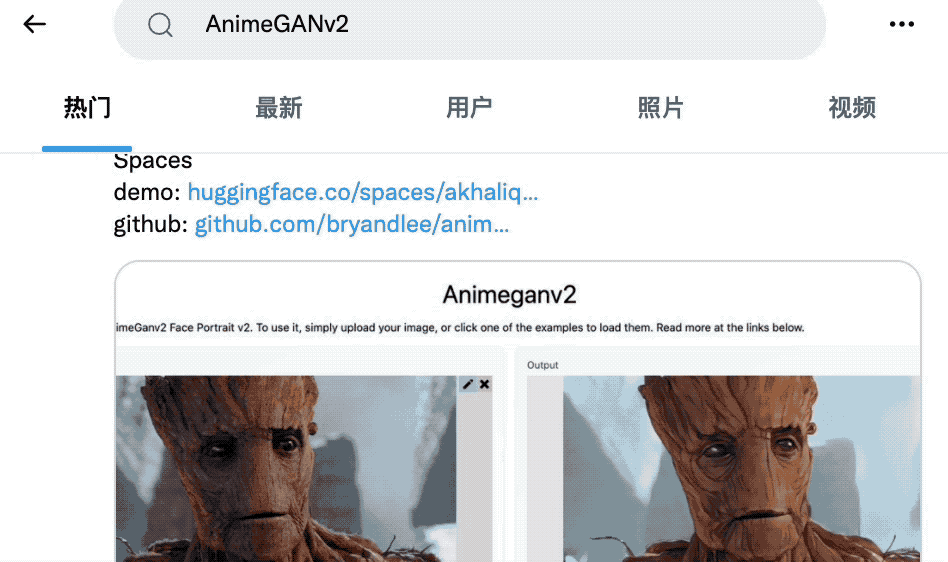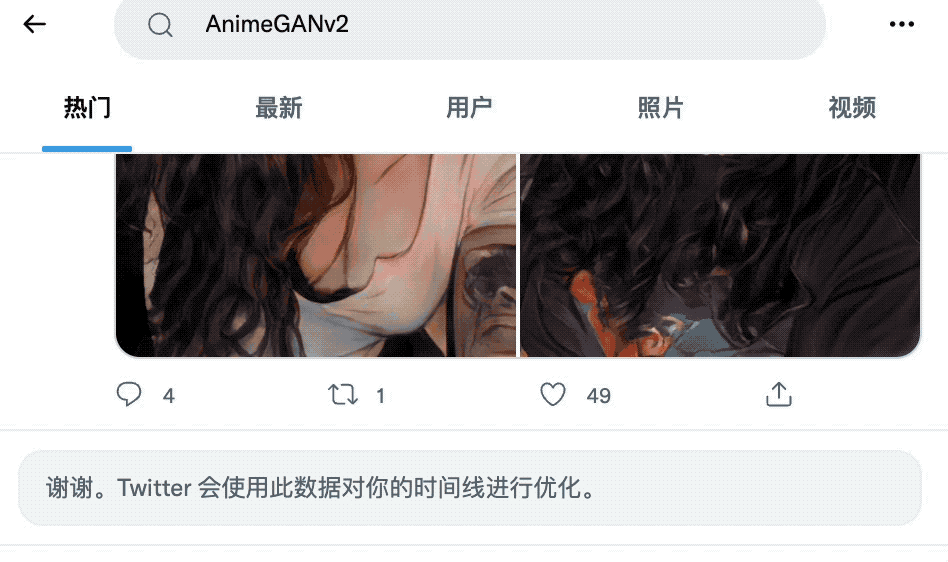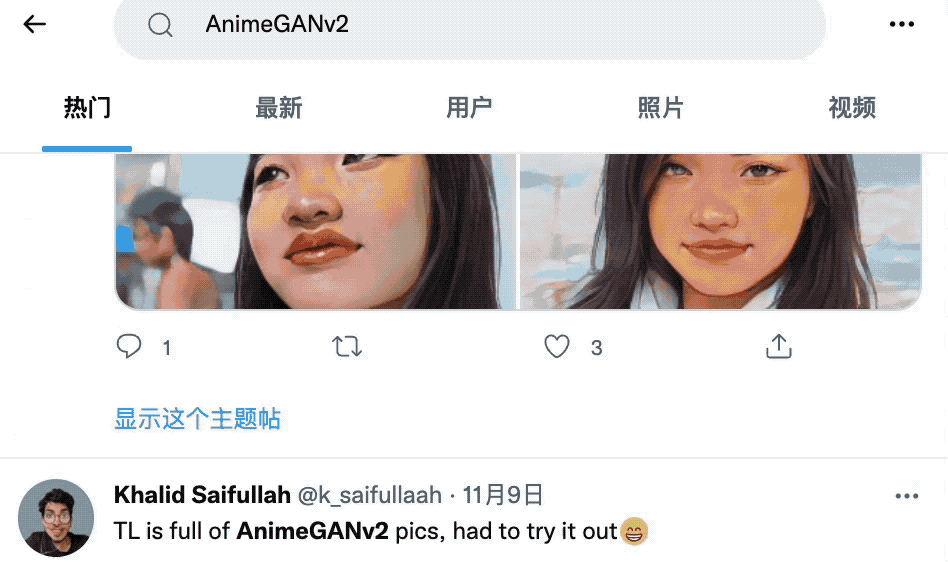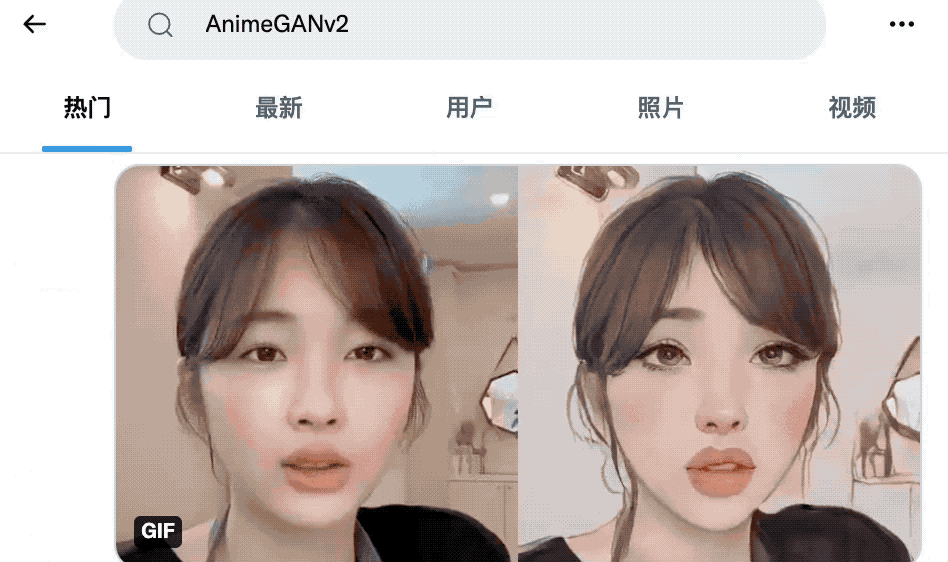
再看看GitHub上的相关项目,果然也冲上了趋势榜第一名。
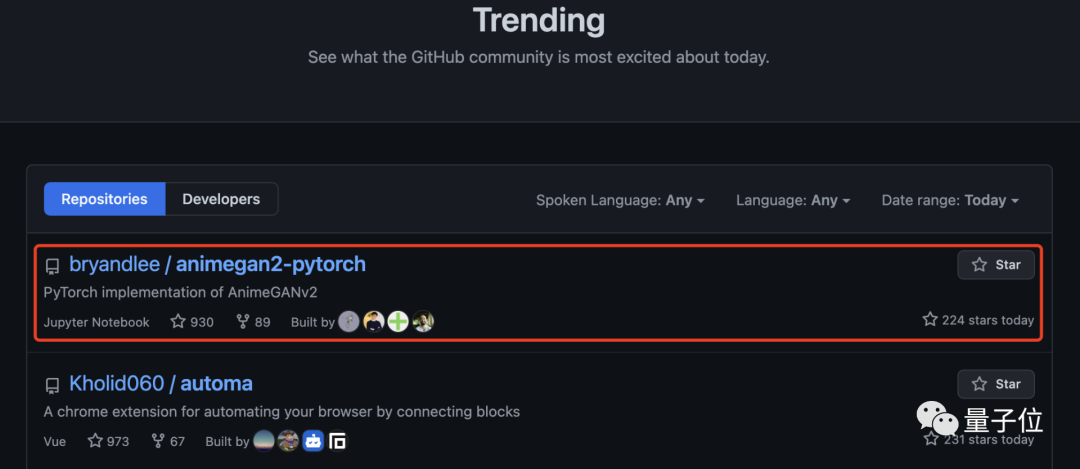
这个AnimeGAN,真是厉害了!
如何给自己捏一个动漫脸?
看完展示的效果,你是不是也想打造一个自己专属的漫画脸了呢?
这个可以有,现在就手把手教你。
第一种方法就very very简单了,只需要上传一张照片就可以。
提供在线玩法的网站(链接见文末),就是那个著名的抱抱脸 (Hugging Face)。
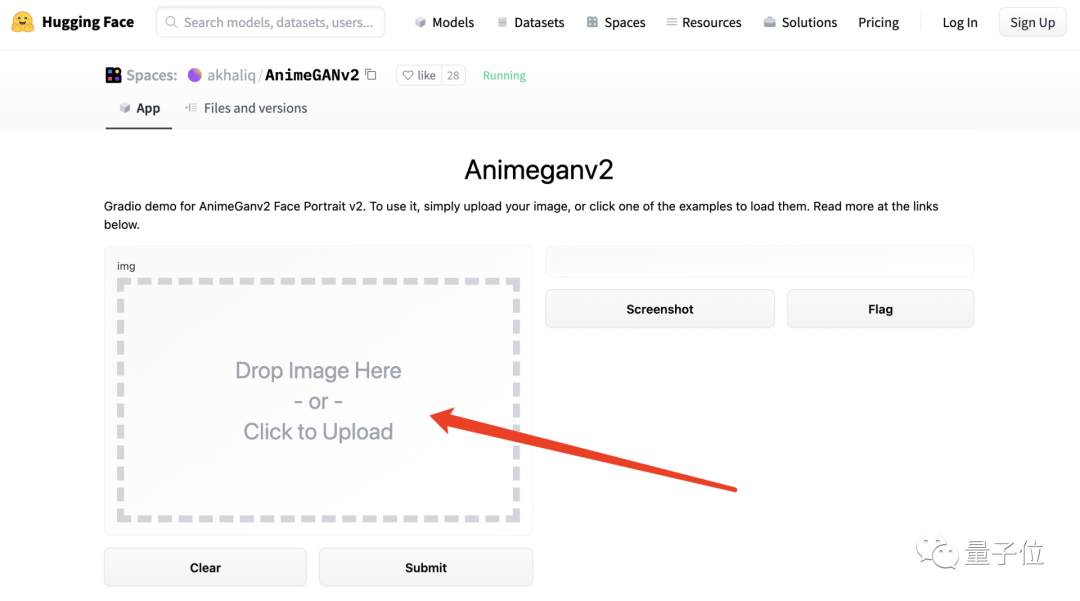
它专门开设了一个在线AnimeGANv2的App,直接把图片“丢”进去就好。

BUT!!!
也正如刚才提到的,现在这个AI着实有点太火了,简单的在线方法,就等同于排大队。

这不,等了5259秒之后,前面还有15人……
如果不想排队怎么办?
接下来,就是第二种方法了——上代码!
热心网友在苦等了3小时之后,终于还是忍不住了,强烈安利Colab版本(链接见文末):
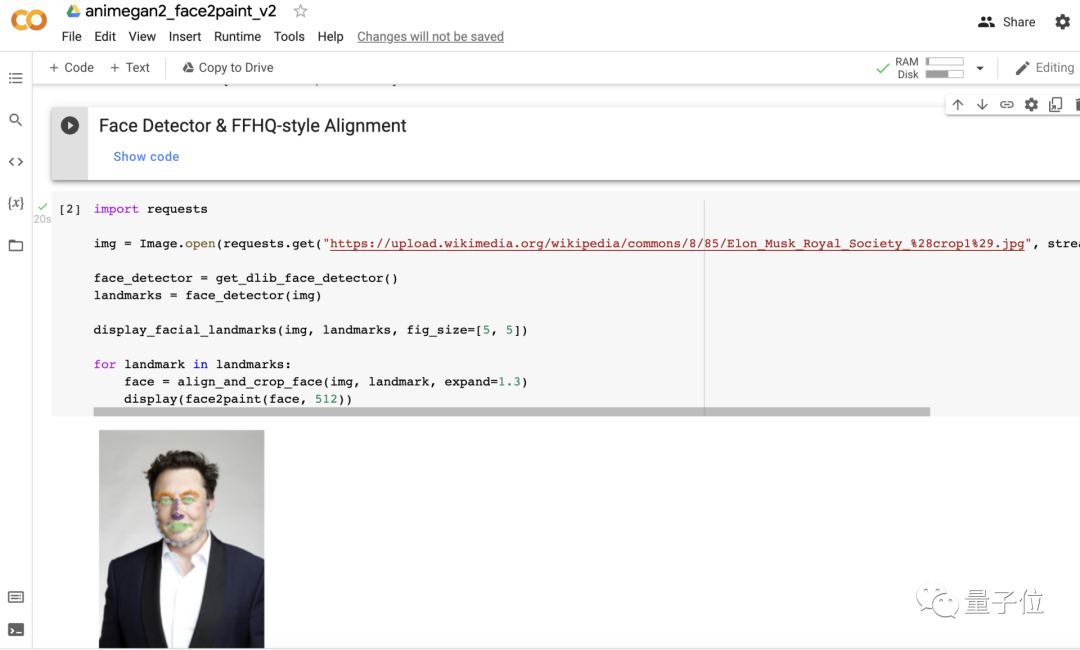
先运行一下文档里的前两段代码,然后只需要简单修改照片路径即可。
当然,如果想加大难度挑战一下,AnimeGANv2的GitHub项目也是有的哈:
以上介绍的方法都是用图片转换,如果你想用视频的话,在AnimeGANv2项目中执行下面这两条命令就OK:

当然,该项目的Pytorch实现也有,不过Pytorch版本目前只支持图片转换;如果想转视频,暂时就需要你自己写个脚本了~
风格迁移+GAN
那么,如此效果的背后,到底是用了什么原理呢?
AnimeGAN是来自武汉大学和湖北工业大学的一项研究,采用的是神经风格迁移 + 生成对抗网络(GAN)的组合。

它其实是基于CartoonGAN的改进,并提出了一个更加轻量级的生成器架构。
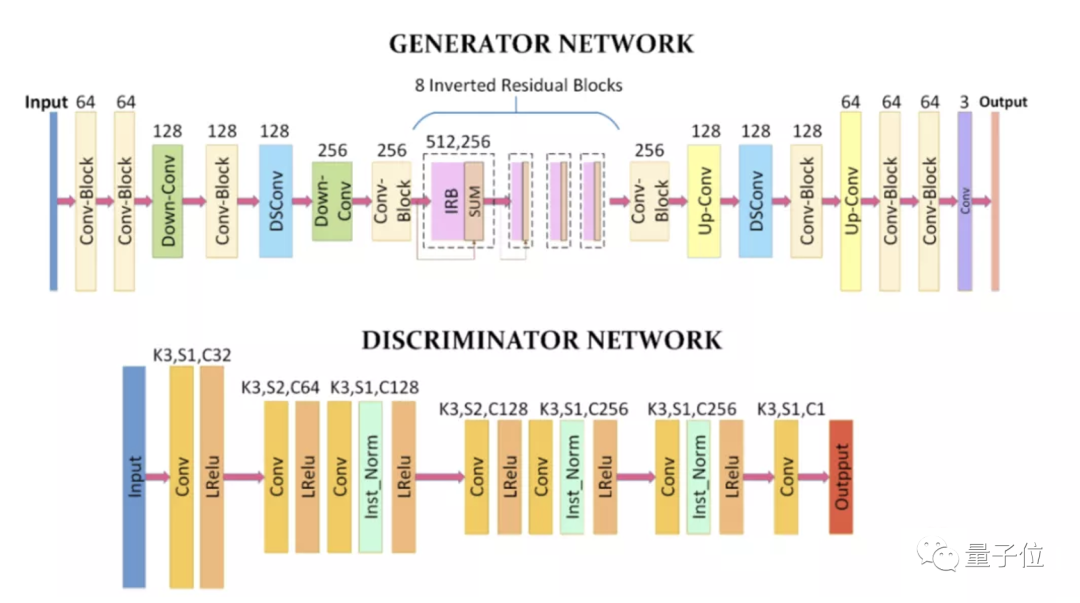
AnimeGAN的生成器可以视作一个对称的编码器-解码器网络,由标准卷积、深度可分离卷积、反向残差块、上采样和下采样模块组成。
为了有效减少生成器的参数数量,AnimeGAN的网络中使用了8个连续且相同的IRB(inverted residual blocks)。
在生成器中,具有1×1卷积核的最后一个卷积层不使用归一化层,跟随其后的是tanh非线性激活函数。
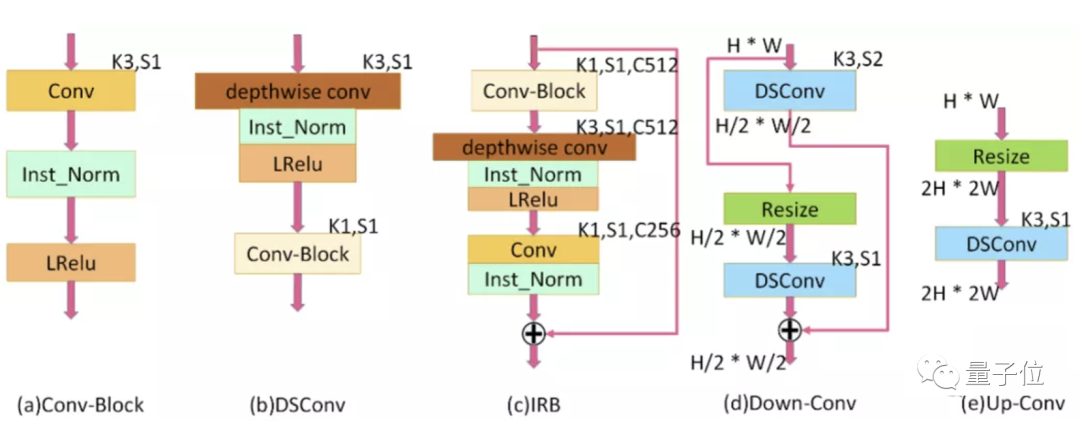
上图中,K为内核大小,C为特征图数量,S为每个卷积层的跨度,H是特征图的高度,W是特征图的宽度,Resize值用于设置特征图大小的插值方法,⊕表示逐元素加法。
而此次的V2版本,是基于第一代AnimeGAN的升级,主要解决了模型生成的图像中存在高频伪影的问题。
具体而言,所采取的措施是使用特征的层归一化(layer normalization),来防止网络在生成的图像中产生高频伪影。
作者认为,层归一化可以使feature map中的不同通道,具有相同的特征属性分布,可以有效地防止局部噪声的产生。
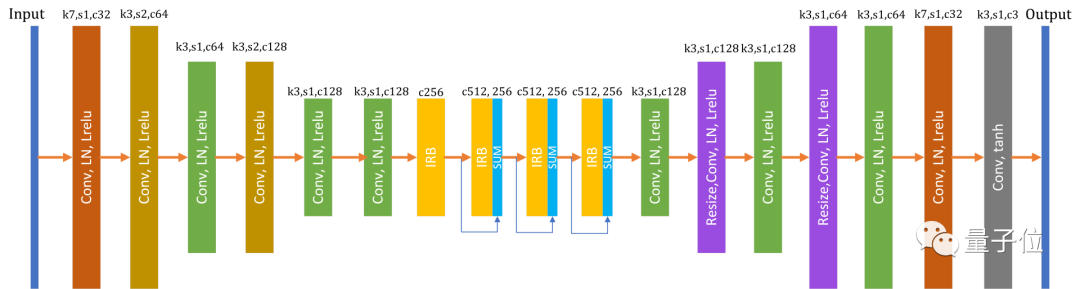
AnimeGANv2的生成器参数大小为8.6MB,而AnimeGAN的生成器参数大小为15.8MB。
它俩使用的鉴别器大致相同,区别在于AnimeGANv2使用的是层归一化,而不是实例归一化(instance normalization)。
网友:我变漂亮了
这个AI可算是圈了一众粉丝。
有些网友“冲进二次元”之后,发现了自己惊人的美貌:
它把我变漂亮了!
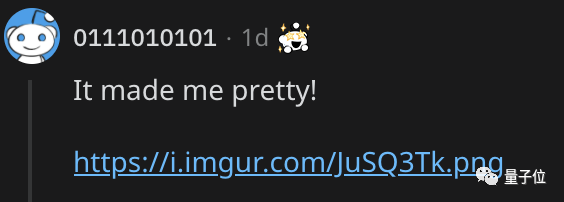
而且非常骄傲的晒出了自己的漫画脸。
还有网友看完比尔盖茨的效果之后,直呼:
天!盖茨看起来聪明又性感。


作者:生成效果更好的AnimeGANv3也快来了
AnimeGAN的原作者一共有3位,分别是湖北工业大学的刘罡副教授,陈颉博士,以及他们的学生Xin Chen。
这个项目的诞生主要出于团队成员的个人兴趣,也就是对二次元宅文化和对艺术的热爱。
作者之一陈同学介绍,AnimeGAN和AnimeGANv2分别耗时2-3个月完成,其中遇到了不少困难。
其中就包括硬件资源的极度匮乏,比如当时做AnimeGAN用到的英伟达单卡服务器还是由该校艺术设计学院的院长饶鉴教授提供,而他负责的研究也曾依赖于向其他同学借机器跑实验。
到了AnimeGANv2时,就只剩一台单卡2080ti服务器供使用了。
不过,所有努力都没有白费,如今AnimeGAN已受到非常多人的关注和喜欢,这让陈同学和他的导师团队都非常有成就感。
要知道,就连新海诚导演都曾转发过AnimeGAN的作品呢。

但,这项以兴趣爱好为驱动的科研项目并不只是“图个好玩”。
在我们与该团队的交流当中,他们表示:
主要目标还是以学术论文为里程牌,以项目能工程化落地到实际应用中为最大期待。
而接下来,AnimeGANv3也快来了。
它到时会采用更小的网络规模,大概缩减到只有4M左右;同时解决AnimeGANv2的一些不足(比如v2保留了原图过多的细节),让生成的动漫效果质量更高。
这也意味着AnimeGANv3将具备商业化的能力。
而在AnimeGANv3完成之后,他们还会对人脸到动漫的算法进行不断地优化。
One More Thing
最后,大家上手之前一定要注意,虽然AnimeGAN展示的效果都是比较好的,但这有一个大前提:
照片一定要高清、五官尽量要清晰!
不然画风可能就会变得诡异(作者亲测,欲哭无泪)……
那么,你在漫画里是什么样子?
快去试试吧~
在线Demo:
https://huggingface.co/spaces/akhaliq/AnimeGANv2
Colab版本:
https://colab.research.google.com/drive/1jCqcKekdtKzW7cxiw_bjbbfLsPh-dEds?usp=sharing#scrollTo=niSP_i7FVC3c
GitHub地址:
https://github.com/TachibanaYoshino/AnimeGANv2
https://github.com/bryandlee/animegan2-pytorch
参考链接:
[1]https://www.reddit.com/r/MachineLearning/comments/qo4kp8/r_p_animeganv2_face_portrait_v2/
[2]https://user-images.githubusercontent.com/26464535/137619176-59620b59-4e20-4d98-9559-a424f86b7f24.jpg
[3]https://twitter.com/chriswolfvision/status/1457489986933170179
推荐阅读
【重磅】斯坦福李飞飞《注意力与Transformer》总结,84页ppt开放下载!
一文总结微软研究院Transformer霸榜模型三部曲!
Swin Transformer为主干,清华等提出MoBY自监督学习方法,代码已开源
加性注意力机制!清华和MSRA提出Fastformer:又快又好的Transformer新变体!
MLP进军下游视觉任务!目标检测与分割领域最新MLP架构研究进展!
周志华教授:如何做研究与写论文?(附完整的PPT全文)
都2021 年了,AI大牛纷纷离职!各家大厂的 AI Lab 现状如何?
常用 Normalization 方法的总结与思考:BN、LN、IN、GN
注意力可以使MLP完全替代CNN吗? 未来有哪些研究方向?
欢迎大家加入DLer-计算机视觉&Transformer群!
大家好,这是计算机视觉&Transformer论文分享群里,群里会第一时间发布最新的Transformer前沿论文解读及交流分享会,主要设计方向有:图像分类、Transformer、目标检测、目标跟踪、点云与语义分割、GAN、超分辨率、视频超分、人脸检测与识别、动作行为与时空运动、模型压缩和量化剪枝、迁移学习、人体姿态估计等内容。
进群请备注:研究方向+学校/公司+昵称(如Transformer+上交+小明)

👆 长按识别,邀请您进群!