日志是一个十分必要的操作,有助于后期分析实验结果,特别是在多台不同环境下训练,为了区分,还是十分有必要记录相关平台信息的,比如 hostname,Python版本信息,Pytorch版本信息等!
import socket
import platform'Python-{platform.python_version()}' # Python 版本
'torch-{torch.__version__}' # Pytorch 版本
socket.gethostname() # 主机名s = f'YOLOv5 🚀 {time_date()} Python-{platform.python_version()} torch-{torch.__version__} '
1、查看显卡信息
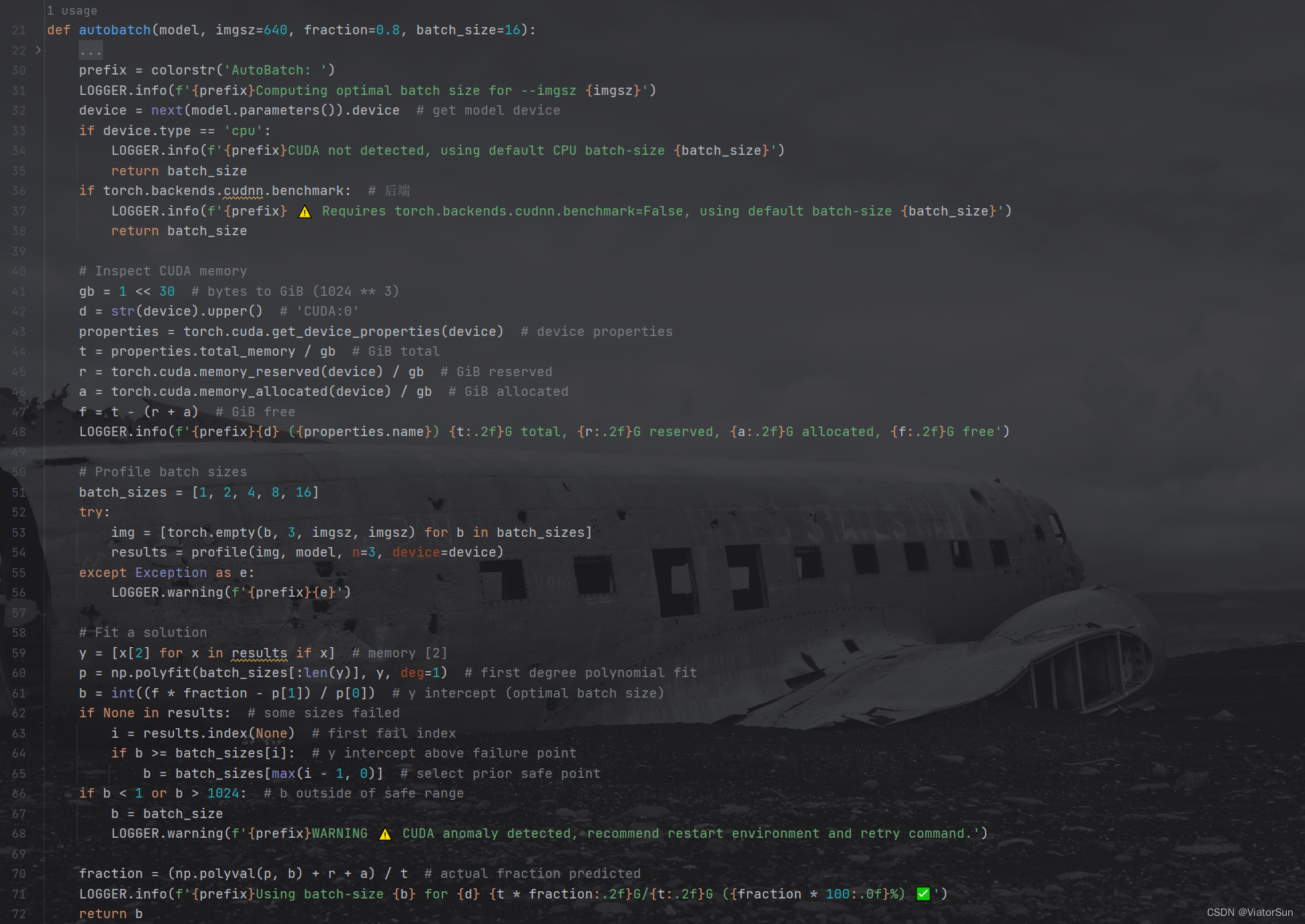
首先需要获取显卡信息,查看显存 File path: yolov5-7.0/utils/autobatch.py
torch.cuda.get_device_properties(0) # 获取显卡属性
>>> _CudaDeviceProperties(name='NVIDIA GeForce RTX 4090', major=8, minor=9, total_memory=24563MB, multi_processor_count=128)
'name:' 显卡型号
'major:'
'minor:'
'total_memory:' 总显存
'multi_processor_count: 'torch.cuda.empty_cache()"""-----------------------------------------------------------------------------------------"""
properties = torch.cuda.get_device_properties(device) # 获取cuda:i属性a = torch.cuda.memory_allocated(device) / gb # GiB allocated 当前Tensor占用的显存
# Returns the current GPU memory occupied by tensors in bytes for a given device.r = torch.cuda.memory_reserved(device) / gb # GiB reserved 总共占用的显存
# Returns the current GPU memory managed by the caching allocator in bytes for a given device.t = properties.total_memory / gb # GiB total
f = t - (r + a) # GiB freeprint(f'{cuda_i} ({properties.name}) {t:.2f}G total, {r:.2f}G reserved, {a:.2f}G allocated, {f:.2f}G free')
>>> 'CUDA:0 (NVIDIA GeForce RTX 4090) 23.99G total, 0.09G reserved, 0.05G allocated, 23.85G free'
2、自动计算 batchsize
上面已经获取了显卡的占用显存,空余显存和总显存
首先创建个 batch_size 的列表,用于计算不同小batch时,显卡的使用情况,最后再通过 np.polyfit 拟合计算出最佳的 batch_size
# Profile batch sizes
batch_sizes = [1, 2, 4, 8, 16]
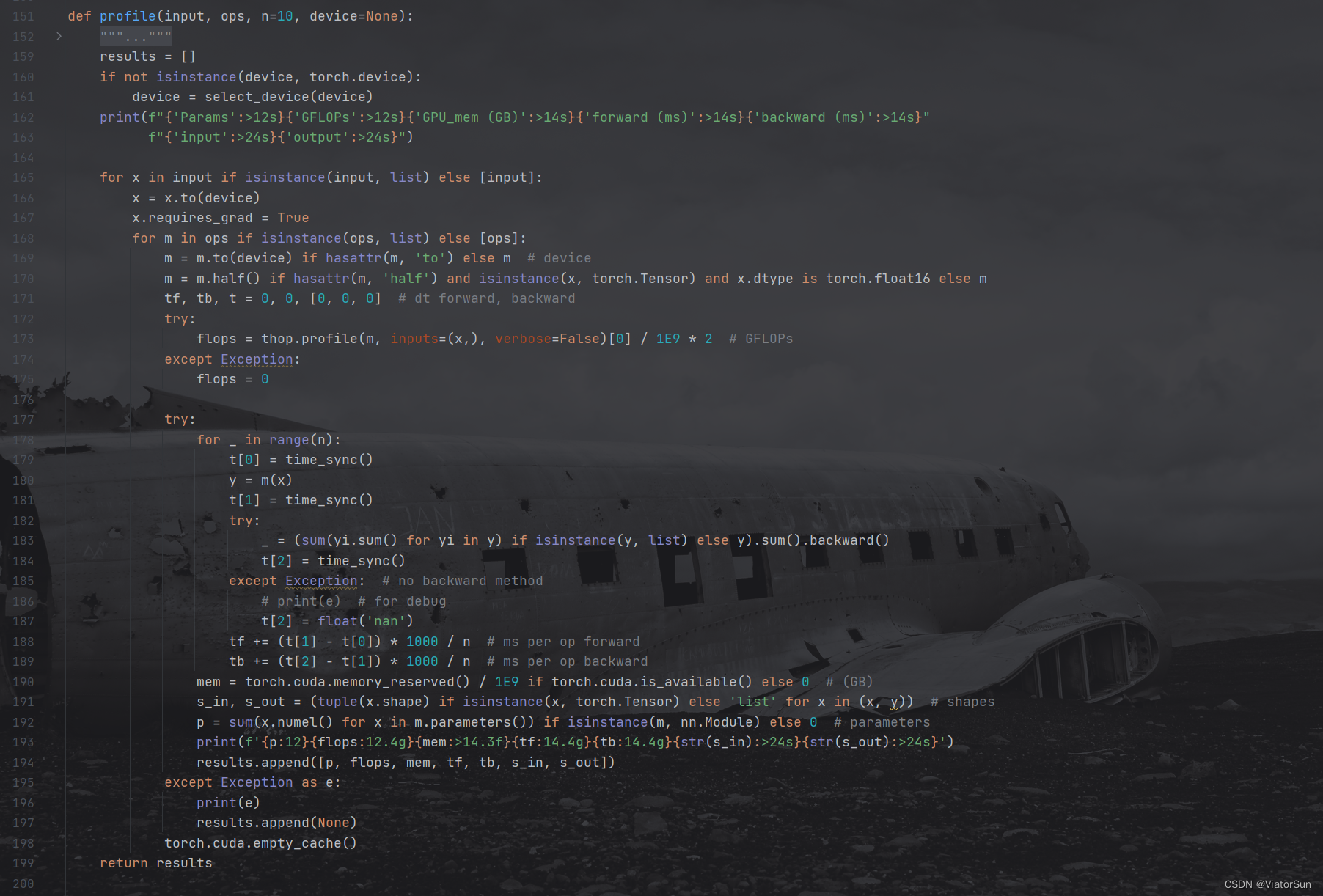
try:img = [torch.empty(b, 3, imgsz, imgsz) for b in batch_sizes]results = profile(img, model, n=3, device=device) # profile:yolov5-7.0/utils/torch_utils.py
except Exception as e:LOGGER.warning(f'{prefix}{e}')# Fit a solution
y = [x[2] for x in results if x] # memory [2]
p = np.polyfit(batch_sizes[:len(y)], y, deg=1) # first degree polynomial fit
b = int((f * fraction - p[1]) / p[0]) # y intercept (optimal batch size)
- hasattr(): 函数用于判断对象是否包含对应的属性
- isinstance(): 用来判断一个函数是否是一个已知的类型,类似 type()
- torch.cuda.synchronize(): 等待当前设备上所有流中的所有核心完成
- torch.numel(input) → int 返回输入张量中元素的总数
通过 np.polyfit 拟合可以看出,显存占用情况基本随 batch_size 线性增加,其中 np.polyfit 的 deg参数表示待拟合多项式的次数,输出结果从最高次幂依次递减 。通过上述计算的 free 显存,乘以 设定比例,然后减去 偏置显存,然后除以 斜率既是对应的 batch_size,再对其取整获得即可

3、完整版代码