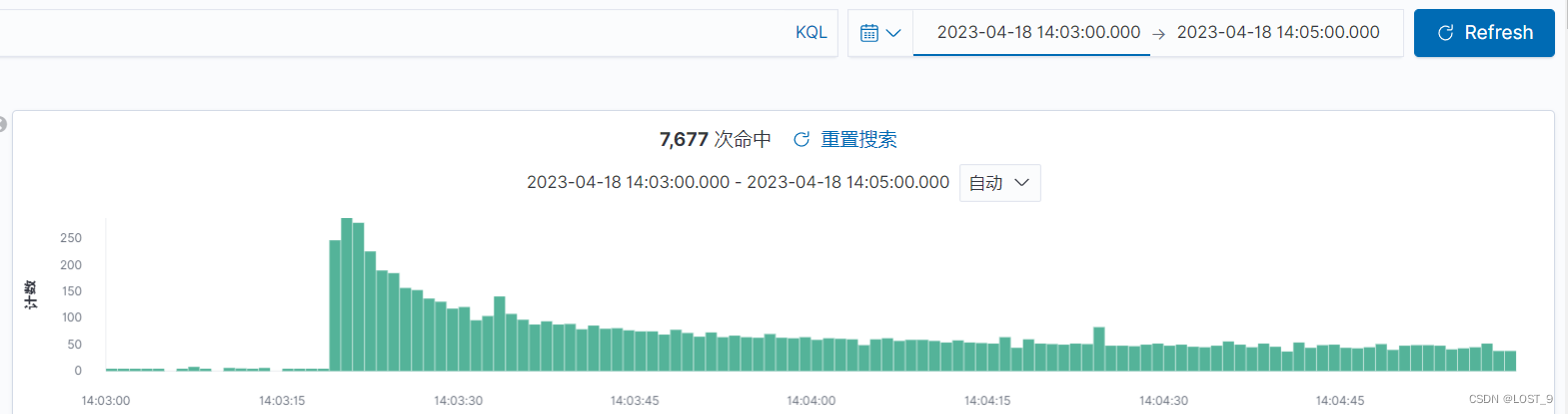
Rate limits 速率并发限制
- 前言
- Introduction 导言
- What are rate limits? 什么是速率限制?
- Why do we have rate limits? 为什么我们有速率限制?
- What are the rate limits for our API? 我们API的速率限制是什么?
- GPT-4 rate limits GPT-4速率限制
- How do rate limits work? 速率限制是如何工作的?
- What happens if I hit a rate limit error? 如果我遇到速率限制错误会发生什么?
- Rate limits vs max_tokens 速率限制与最大标记数
- Error Mitigation 错误消除
- What are some steps I can take to mitigate this? 我可以采取哪些措施来缓解这种情况?
- Retrying with exponential backoff 使用指数回退重试
- Example #1: Using the Tenacity library 示例#1:使用Tenacity库
- Example #2: Using the backoff library 示例2:使用backoff 库
- Example 3: Manual backoff implementation 示例3:手动backoff 实现
- Batching requests 批处理请求
- Example without batching 无批处理示例 Python代码示例
- Example with batching 批处理示例 Python代码示例
- Request Increase 增加请求
- When should I consider applying for a rate limit increase?我应该在什么时候考虑申请提高利率限制?
- Will my rate limit increase request be rejected? 我的速率上限增加请求会被拒绝吗?
- I’ve implemented exponential backoff for my text/code APIs, but I’m still hitting this error. How do I increase my rate limit? 我已经为我的文本/代码API实现了指数回退,但我仍然遇到这个错误。我如何提高我的速率上限?
- DALL-E API examples DALL-E API示例
- Language model examples 语言模型示例
- Code model examples 代码模型示例
- 其它资料下载

前言
为了保证系统的可靠性和稳定性,ChatGPT设置了速率限制,限制每个用户在特定时间段内可以发送的消息数量。这样可以防止某些用户对系统进行滥用,并且减少资源占用。ChatGPT 的速率限制比较灵活,会根据用户的行为以及服务器的负载情况动态调整。例如,在繁忙的时段,我们可能会采取更加严格的限制策略,以确保服务器的稳定性。可以说ChatGPT 的速率限制是确保系统运行稳定、避免恶意滥用的重要措施。
Introduction 导言
What are rate limits? 什么是速率限制?
A rate limit is a restriction that an API imposes on the number of times a user or client can access the server within a specified period of time.
速率限制是API对用户或客户端在指定时间段内可以访问服务器的次数施加的限制。
Why do we have rate limits? 为什么我们有速率限制?
Rate limits are a common practice for APIs, and they’re put in place for a few different reasons:
速率限制是API的常见做法,它们的实施有几个不同的原因:
- They help protect against abuse or misuse of the API. For example, a malicious actor could flood the API with requests in an attempt to overload it or cause disruptions in service. By setting rate limits, OpenAI can prevent this kind of activity.
**它们有助于防止滥用或误用API。**例如,恶意行为者可能会向API发送大量请求,试图使其过载或导致服务中断。通过设置速率限制,OpenAI可以防止此类活动。 - Rate limits help ensure that everyone has fair access to the API. If one person or organization makes an excessive number of requests, it could bog down the API for everyone else. By throttling the number of requests that a single user can make, OpenAI ensures that the most number of people have an opportunity to use the API without experiencing slowdowns.
**速率限制有助于确保每个人都可以公平地访问API。**如果一个人或组织发出过多的请求,它可能会使其他人的API陷入困境。通过限制单个用户可以发出的请求数量,OpenAI确保大多数人有机会使用API而不会遇到速度减慢。 - Rate limits can help OpenAI manage the aggregate load on its infrastructure. If requests to the API increase dramatically, it could tax the servers and cause performance issues. By setting rate limits, OpenAI can help maintain a smooth and consistent experience for all users.
**速率限制可以帮助OpenAI管理其基础设施上的总负载。**如果对API的请求急剧增加,可能会加重服务器的负担并导致性能问题。通过设置速率限制,OpenAI可以帮助所有用户保持流畅一致的体验。
Please work through this document in its entirety to better understand how OpenAI’s rate limit system works. We include code examples and possible solutions to handle common issues. It is recommended to follow this guidance before filling out the Rate Limit Increase Request form with details regarding how to fill it out in the last section.
请完整阅读本文档,以更好地了解OpenAI的速率限制系统是如何工作的。我们包括代码示例和处理常见问题的可能解决方案。建议您在填写费率限额增加申请表之前遵循本指南,并在最后一节中详细说明如何填写。
What are the rate limits for our API? 我们API的速率限制是什么?
We enforce rate limits at the organization level, not user level, based on the specific endpoint used as well as the type of account you have. Rate limits are measured in two ways: RPM (requests per minute) and TPM (tokens per minute). The table below highlights the default rate limits for our API but these limits can be increased depending on your use case after filling out the Rate Limit increase request form.
我们根据所使用的特定端点以及您拥有的帐户类型,在组织级别(而非用户级别)实施速率限制。速率限制以两种方式测量:RPM(每分钟请求数)和TPM(每分钟标记数)。下表突出显示了我们API的默认速率限制,但在填写速率限制增加请求表单后,这些限制可以根据您的用例进行增加。
The TPM (tokens per minute) unit is different depending on the model:
TPM(每分钟标记数)单位因模型而异:
| TYPE 模型类型 | 1 TPM EQUALS 1 TPM等于 |
|---|---|
| davinci | 1 token per minute 每分钟1个标记 |
| curie | 25 tokens per minute 每分钟25个标记 |
| babbage | 100 tokens per minute 每分钟100个标记 |
| ada | 200 tokens per minute 每分钟200个标记 |
In practical terms, this means you can send approximately 200x more tokens per minute to an ada model versus a davinci model.
实际上,这意味着您每分钟可以向 ada 模型发送大约200倍的标记,而不是 davinci 模型。

It is important to note that the rate limit can be hit by either option depending on what occurs first. For example, you might send 20 requests with only 100 tokens to the Codex endpoint and that would fill your limit, even if you did not send 40k tokens within those 20 requests.
重要的是要注意,根据首先发生的情况,任何一种选择都可能达到速率限制。例如,您可以向Codex端点发送20个仅包含100个标记的请求,这将满足您的限制,即使您在这20个请求中没有发送40K标记。
GPT-4 rate limits GPT-4速率限制
During the rollout of GPT-4, the model will have more aggressive rate limits to keep up with demand. Default rate limits for gpt-4/gpt-4-0314 are 40k TPM and 200 RPM. Default rate limits for gpt-4-32k/gpt-4-32k-0314 are 80k TPM and 400 RPM. Please note that during the limited beta phase of GPT-4 we will be unable to accommodate requests for rate limit increases. In its current state, the model is intended for experimentation and prototyping, not high volume production use cases.
在GPT-4的推出期间,该模型将具有更积极的速率限制,以跟上需求。 gpt-4 / gpt-4-0314 的默认速率限制为40k TPM和200 RPM。 gpt-4-32k / gpt-4-32k-0314 的默认速率限制为80k TPM和400 RPM。请注意,在GPT-4的有限测试阶段,我们将无法满足费率限制增加的请求。在目前的状态下,该模型旨在用于实验和原型设计,而不是大批量生产用例。
How do rate limits work? 速率限制是如何工作的?
If your rate limit is 60 requests per minute and 150k davinci tokens per minute, you’ll be limited either by reaching the requests/min cap or running out of tokens—whichever happens first. For example, if your max requests/min is 60, you should be able to send 1 request per second. If you send 1 request every 800ms, once you hit your rate limit, you’d only need to make your program sleep 200ms in order to send one more request otherwise subsequent requests would fail. With the default of 3,000 requests/min, customers can effectively send 1 request every 20ms, or every .02 seconds.
如果您的速率限制是每分钟60个请求和每分钟150k个 davinci 标记,您将受到限制,要么达到请求/分钟上限,要么用完标记-以先发生的为准。例如,如果您的max requests/min是60,那么您应该能够每秒发送1个请求。如果你每800 ms发送一个请求,一旦你达到了你的速率限制,你只需要让你的程序休眠200 ms就可以再发送一个请求,否则后续的请求就会失败。在默认值为3,000个请求/分钟的情况下,客户实际上可以每20 ms或每0.02秒发送一个请求。
What happens if I hit a rate limit error? 如果我遇到速率限制错误会发生什么?
Rate limit errors look like this:
速率限制错误如下所示:
Rate limit reached for default-text-davinci-002 in organization org-{id} on requests per min. Limit: 20.000000 / min. Current: 24.000000 / min.
组织org-{id}中的default-text-davinci-002达到每分钟请求数的速率限制。限制:20.000000 /分钟 现在:24.000000 /分钟
If you hit a rate limit, it means you’ve made too many requests in a short period of time, and the API is refusing to fulfill further requests until a specified amount of time has passed.
如果你达到了速率限制,这意味着你在短时间内发出了太多的请求,API将拒绝满足更多的请求,直到指定的时间过去。
Rate limits vs max_tokens 速率限制与最大标记数
Each model we offer has a limited number of tokens that can be passed in as input when making a request. You cannot increase the maximum number of tokens a model takes in. For example, if you are using text-ada-001, the maximum number of tokens you can send to this model is 2,048 tokens per request.
我们提供的每个模型都有有限数量的标记,可以在发出请求时作为输入传入。不能增加模型接受的最大标记数。例如,如果您使用 text-ada-001 ,则您可以向此模型发送的标记的最大数量为每个请求2,048个标记。
Error Mitigation 错误消除
What are some steps I can take to mitigate this? 我可以采取哪些措施来缓解这种情况?
The OpenAI Cookbook has a python notebook that explains details on how to avoid rate limit errors.
OpenAI Cookbook有一个Python笔记本,解释了如何避免速率限制错误的细节。
You should also exercise caution when providing programmatic access, bulk processing features, and automated social media posting - consider only enabling these for trusted customers.
在提供程序化访问、批量处理功能和自动社交媒体发布功能时,您还应谨慎行事-请考虑仅为受信任的客户启用这些功能。
To protect against automated and high-volume misuse, set a usage limit for individual users within a specified time frame (daily, weekly, or monthly). Consider implementing a hard cap or a manual review process for users who exceed the limit.
为了防止自动化和大量滥用,请在指定的时间范围内(每天、每周或每月)为单个用户设置使用限制。考虑对超出限制的用户实施硬上限或手动审查流程。
Retrying with exponential backoff 使用指数回退重试
One easy way to avoid rate limit errors is to automatically retry requests with a random exponential backoff. Retrying with exponential backoff means performing a short sleep when a rate limit error is hit, then retrying the unsuccessful request. If the request is still unsuccessful, the sleep length is increased and the process is repeated. This continues until the request is successful or until a maximum number of retries is reached. This approach has many benefits:
避免速率限制错误的一种简单方法是使用随机指数退避自动重试请求。使用指数回退重试意味着当达到速率限制错误时执行短暂休眠,然后重试不成功的请求。如果请求仍然不成功,则增加休眠长度并重复该过程。这将持续到请求成功或达到最大重试次数。这种方法有很多好处:
- Automatic retries means you can recover from rate limit errors without crashes or missing data
自动重试意味着您可以从速率限制错误中恢复,而不会崩溃或丢失数据 - Exponential backoff means that your first retries can be tried quickly, while still benefiting from longer delays if your first few retries fail
指数回退意味着您的第一次重试可以快速尝试,同时如果您的前几次重试失败,仍然可以从更长的延迟中受益 - Adding random jitter to the delay helps retries from all hitting at the same time.
向延迟添加随机抖动有助于同时重试所有命中。
Note that unsuccessful requests contribute to your per-minute limit, so continuously resending a request won’t work.
请注意,不成功的请求会影响您的每分钟限制,因此连续重新发送请求将不起作用。
Below are a few example solutions for Python that use exponential backoff.
下面是一些使用指数回退的Python示例解决方案。
Example #1: Using the Tenacity library 示例#1:使用Tenacity库
Tenacity is an Apache 2.0 licensed general-purpose retrying library, written in Python, to simplify the task of adding retry behavior to just about anything. To add exponential backoff to your requests, you can use the tenacity.retry decorator. The below example uses the tenacity.wait_random_exponential function to add random exponential backoff to a request.
Tenacity是一个Apache 2.0许可的通用重试库,用Python编写,用于简化将重试行为添加到任何内容的任务。要在请求中添加指数回退,可以使用 tenacity.retry 装饰器。下面的示例使用 tenacity.wait_random_exponential 函数向请求添加随机指数退避。
Using the Tenacity library 使用Tenacity库 Python 代码示例:
import openai
from tenacity import (retry,stop_after_attempt,wait_random_exponential,
) # for exponential backoff@retry(wait=wait_random_exponential(min=1, max=60), stop=stop_after_attempt(6))
def completion_with_backoff(**kwargs):return openai.Completion.create(**kwargs)completion_with_backoff(model="text-davinci-003", prompt="Once upon a time,")
Note that the Tenacity library is a third-party tool, and OpenAI makes no guarantees about its reliability or security.
请注意,Tenacity库是第三方工具,OpenAI不保证其可靠性或安全性。
Example #2: Using the backoff library 示例2:使用backoff 库
Another python library that provides function decorators for backoff and retry is backoff:
另一个为backoff和retry提供函数装饰器的python库是backoff:
import backoff
import openai
@backoff.on_exception(backoff.expo, openai.error.RateLimitError)
def completions_with_backoff(**kwargs):return openai.Completion.create(**kwargs)completions_with_backoff(model="text-davinci-003", prompt="Once upon a time,")
Like Tenacity, the backoff library is a third-party tool, and OpenAI makes no guarantees about its reliability or security.
与Tenacity一样,backoff 库是第三方工具,OpenAI不保证其可靠性或安全性。
Example 3: Manual backoff implementation 示例3:手动backoff 实现
If you don’t want to use third-party libraries, you can implement your own backoff logic following this example:
如果你不想使用第三方库,你可以按照这个例子实现你自己的退避逻辑:
# imports
import random
import timeimport openai# define a retry decorator
def retry_with_exponential_backoff(func,initial_delay: float = 1,exponential_base: float = 2,jitter: bool = True,max_retries: int = 10,errors: tuple = (openai.error.RateLimitError,),
):"""Retry a function with exponential backoff."""def wrapper(*args, **kwargs):# Initialize variablesnum_retries = 0delay = initial_delay# Loop until a successful response or max_retries is hit or an exception is raisedwhile True:try:return func(*args, **kwargs)# Retry on specific errorsexcept errors as e:# Increment retriesnum_retries += 1# Check if max retries has been reachedif num_retries > max_retries:raise Exception(f"Maximum number of retries ({max_retries}) exceeded.")# Increment the delaydelay *= exponential_base * (1 + jitter * random.random())# Sleep for the delaytime.sleep(delay)# Raise exceptions for any errors not specifiedexcept Exception as e:raise ereturn wrapper@retry_with_exponential_backoff
def completions_with_backoff(**kwargs):return openai.Completion.create(**kwargs)
Again, OpenAI makes no guarantees on the security or efficiency of this solution but it can be a good starting place for your own solution.
同样,OpenAI不保证此解决方案的安全性或效率,但它可以成为您自己解决方案的良好起点。
Batching requests 批处理请求
The OpenAI API has separate limits for requests per minute and tokens per minute.
OpenAI API对每分钟请求和每分钟标记有单独的限制。
If you’re hitting the limit on requests per minute, but have available capacity on tokens per minute, you can increase your throughput by batching multiple tasks into each request. This will allow you to process more tokens per minute, especially with our smaller models.
如果您达到了每分钟请求数的限制,但每分钟标记有可用容量,则可以通过将多个任务批处理到每个请求中来提高吞吐量。这将允许您每分钟处理更多的标记,特别是对于我们较小的模型。
Sending in a batch of prompts works exactly the same as a normal API call, except you pass in a list of strings to the prompt parameter instead of a single string.
批量发送提示的工作方式与普通API调用完全相同,不同之处在于您向prompt参数传递的是字符串列表而不是单个字符串。
Example without batching 无批处理示例 Python代码示例
import openainum_stories = 10
prompt = "Once upon a time,"# serial example, with one story completion per request
for _ in range(num_stories):response = openai.Completion.create(model="curie",prompt=prompt,max_tokens=20,)# print storyprint(prompt + response.choices[0].text)
Example with batching 批处理示例 Python代码示例
import openai # for making OpenAI API requestsnum_stories = 10
prompts = ["Once upon a time,"] * num_stories# batched example, with 10 story completions per request
response = openai.Completion.create(model="curie",prompt=prompts,max_tokens=20,
)# match completions to prompts by index
stories = [""] * len(prompts)
for choice in response.choices:stories[choice.index] = prompts[choice.index] + choice.text# print stories
for story in stories:print(story)
Warning: the response object may not return completions in the order of the prompts, so always remember to match responses back to prompts using the index field.
警告:响应对象可能不会按照提示的顺序返回完成,因此请始终记住使用索引字段将响应匹配回提示。
Request Increase 增加请求
When should I consider applying for a rate limit increase?我应该在什么时候考虑申请提高利率限制?
Our default rate limits help us maximize stability and prevent abuse of our API. We increase limits to enable high-traffic applications, so the best time to apply for a rate limit increase is when you feel that you have the necessary traffic data to support a strong case for increasing the rate limit. Large rate limit increase requests without supporting data are not likely to be approved. If you’re gearing up for a product launch, please obtain the relevant data through a phased release over 10 days.
我们的速率限制帮助我们最大限度地提高稳定性,防止滥用API。我们会提高限制以支持高流量应用程序,因此,申请提高速率限制的最佳时机是当您认为有必要的流量数据来支持提高速率限制的有力理由时。没有支持数据的大幅度速率限额增加请求不太可能获得批准。如果您正在为产品发布做准备,请在10天内通过分阶段发布获取相关数据。
Keep in mind that rate limit increases can sometimes take 7-10 days so it makes sense to try and plan ahead and submit early if there is data to support you will reach your rate limit given your current growth numbers.
请记住,速率限制的增加有时可能需要7-10天,因此如果有数据支持您将达到当前增长数字的速率限制,则尝试提前计划并尽早提交是有意义的。
Will my rate limit increase request be rejected? 我的速率上限增加请求会被拒绝吗?
A rate limit increase request is most often rejected because it lacks the data needed to justify the increase. We have provided numerical examples below that show how to best support a rate limit increase request and try our best to approve all requests that align with our safety policy and show supporting data. We are committed to enabling developers to scale and be successful with our API.
提高速率限制的请求最常被拒绝,因为它缺乏证明提高合理性所需的数据。我们在下面提供了数字示例,说明如何最好地支持速率限制增加请求,并尽最大努力批准符合我们安全政策的所有请求,并显示支持数据。我们致力于使开发人员能够扩展并成功使用我们的API。
I’ve implemented exponential backoff for my text/code APIs, but I’m still hitting this error. How do I increase my rate limit? 我已经为我的文本/代码API实现了指数回退,但我仍然遇到这个错误。我如何提高我的速率上限?
We understand the frustration that limited rate limits can cause, and we would love to raise the defaults for everyone. However, due to shared capacity constraints, we can only approve rate limit increases for paid customers who have demonstrated a need through our Rate Limit Increase Request form. To help us evaluate your needs properly, we ask that you please provide statistics on your current usage or projections based on historic user activity in the ‘Share evidence of need’ section of the form. If this information is not available, we recommend a phased release approach. Start by releasing the service to a subset of users at your current rate limits, gather usage data for 10 business days, and then submit a formal rate limit increase request based on that data for our review and approval.
我们理解有限的速率限制可能导致的挫折感,我们希望提高每个人的速率限制。但是,由于共享容量的限制,我们只能批准通过我们的速率限额增加请求表证明需要的付费客户的速率限额增加。为了帮助我们正确评估您的需求,我们要求您在表格的“分享需求证据”部分提供有关您当前使用情况的统计数据或基于历史用户活动的预测。如果没有这些信息,我们建议采用分阶段发布的方法。首先,以您当前的速率限制向一部分用户发布服务,收集10个工作日的使用数据,然后根据该数据提交正式的速率限制增加请求,供我们审核和批准。
We will review your request and if it is approved, we will notify you of the approval within a period of 7-10 business days.
我们将审核您的请求,如果获得批准,我们将在7-10个工作日内通知您。
Here are some examples of how you might fill out this form:
以下是一些如何填写此表单的示例:
DALL-E API examples DALL-E API示例
| MODEL模型 | ESTIMATE TOKENS/MINUTE 估计标记数/分钟 | ESTIMATE REQUESTS/MINUTE 估计请求/分钟 | # OF USERS 用户数量 | EVIDENCE OF NEED 需要的证据 | 1 HOUR MAX THROUGHPUT COST 1小时最大吞吐量成本 |
|---|---|---|---|---|---|
| text-davinci-003 | 325,000 | 4,000 | 50 | We’re releasing to an initial group of alpha testers and need a higher limit to accommodate their initial usage. We have a link here to our google drive which shows analytics and api usage.我们发布给一个初始的alpha测试组,需要一个更高的限制来适应他们的初始使用。我们这里有一个链接到我们的谷歌驱动器,它显示了分析和API的使用情况。 | $390 |
| text-davinci-002 | 750,000 | 10,000 | 10,000 | Our application is receiving a lot of interest; we have 50,000 people on our waitlist. We’d like to roll out to groups of 1,000 people/day until we reach 50,000 users. Please see this link of our current token/minute traffic over the past 30 days. This is for 500 users, and based on their usage, we think 750,000 tokens/minute and 10,000 requests/minute will work as a good starting point.我们的申请受到了很多关注;我们的候补名单上有五万人我们希望推广到每天1,000人的团队,直到达到50,000名用户。请查看我们在过去30天内的当前标记/分钟流量的链接。这是针对500个用户的,根据他们的使用情况,我们认为750,000个标记/分钟和10,000个请求/分钟将是一个很好的起点。 | $900 |
Language model examples 语言模型示例
| MODEL模型 | ESTIMATE TOKENS/MINUTE 估计标记数/分钟 | ESTIMATE REQUESTS/MINUTE 估计请求/分钟 | # OF USERS 用户数量 | EVIDENCE OF NEED 需要的证据 | 1 HOUR MAX THROUGHPUT COST 1小时最大吞吐量成本 |
|---|---|---|---|---|---|
| text-davinci-003 | 325,000 | 4,000 | 50 | We’re releasing to an initial group of alpha testers and need a higher limit to accommodate their initial usage. We have a link here to our google drive which shows analytics and api usage. 我们发布给一个初始的alpha测试组,需要一个更高的限制来适应他们的初始使用。我们这里有一个链接到我们的谷歌驱动器,它显示了分析和API的使用情况。 | $390 |
| text-davinci-002 | 750,000 | 10,000 | 10,000 | Our application is receiving a lot of interest; we have 50,000 people on our waitlist. We’d like to roll out to groups of 1,000 people/day until we reach 50,000 users. Please see this link of our current token/minute traffic over the past 30 days. This is for 500 users, and based on their usage, we think 750,000 tokens/minute and 10,000 requests/minute will work as a good starting point.我们的申请受到了很多关注;我们的候补名单上有五万人我们希望推广到每天1,000人的团队,直到达到50,000名用户。请查看我们在过去30天内的当前标记/分钟流量的链接。这是针对500个用户的,根据他们的使用情况,我们认为750,000个标记/分钟和10,000个请求/分钟将是一个很好的起点。 | $900 |
Code model examples 代码模型示例
| MODEL模型 | ESTIMATE TOKENS/MINUTE 估计标记数/分钟 | ESTIMATE REQUESTS/MINUTE 估计请求/分钟 | # OF USERS 用户数量 | EVIDENCE OF NEED 需要的证据 | 1 HOUR MAX THROUGHPUT COST 1小时最大吞吐量成本 |
|---|---|---|---|---|---|
| code-davinci-002 | 150,000 | 1,000 | 15 | We are a group of researchers working on a paper. We estimate that we will need a higher rate limit on code-davinci-002 in order to complete our research before the end of the month. These estimates are based on the following calculation […]我们是一群研究人员在写论文。我们估计,为了在月底前完成我们的研究,我们将需要对代码davinci-002进行更高的速率限制。这些估计是基于以下计算[…] | Codex models are currently in free beta so we may not be able to provide immediate increases for these models.Codex模型目前处于免费测试阶段,因此我们可能无法为这些模型提供立即的增加。 |
Please note that these examples are just general use case scenarios, the actual usage rate will vary depending on the specific implementation and usage.
请注意,这些示例只是一般的用例场景,实际使用速率会根据具体的实现和使用情况而有所不同。
其它资料下载
如果大家想继续了解人工智能相关学习路线和知识体系,欢迎大家翻阅我的另外一篇博客《重磅 | 完备的人工智能AI 学习——基础知识学习路线,所有资料免关注免套路直接网盘下载》
这篇博客参考了Github知名开源平台,AI技术平台以及相关领域专家:Datawhale,ApacheCN,AI有道和黄海广博士等约有近100G相关资料,希望能帮助到所有小伙伴们。