文章目录
- Nacos集群下心跳机制相对于单机会有怎样的改变?
- CAP原则和BASE原则
- 常见的注册中心实现对比
- Nacos集群实现协议
- Nacos CP架构实现源码
- Nacos CP架构leader是如何选举的呢?
Nacos集群下心跳机制相对于单机会有怎样的改变?
在上一遍单机模式下心跳机制的文字中有提到过这段代码:

我们发现第一个判断,如果这个服务的心跳不是由当前server负责,直接退出。这句话是什么意思呢?我们现在就来阅读以下其中源码。

通过这样一个逻辑,取到对应的Nacos机器。
- 这样的做的原因是什么呢?
当Nacos在集群模式下,需要对客户端的机器检查心跳,维护心跳,那么需要集群中的每台机器都去检查心跳吗?肯定是只有一台去做心跳检查,然后进行同步,这样设计才是合理的。所以再看上面的代码,当有服务进行健康检查时,执行到这个方法,取模以后发现负责心跳检查的服务并不是当前服务,那么直接退出。只有当负责这个服务心跳检查的服务执行时才能正常执行。
后续逻辑就和单机模式一样了。
- 如果其中一台集群挂了,取模不就发生错误了,需要使用一致性hash算法吗?
不需要。Nacos集群相互之间也维护了心跳,它会定时的去调用其它集群机器的心跳接口, 如果一段時間未请求在,则认为服务已经挂了,则会更新服务size,解决取模发生错误。这就是集群服务之间节点状态的同步。
Nacos对于每个节点独立处理的数据,会及时同步给其它节点,来保持一个数据的一致性,可能会有一点点时间延迟,但是基本可以忽略。
CAP原则和BASE原则
- CAP原则
C:一致性(Consistency)
A:可用性(Availability)
P:分区容错性(Partition tolerance) - BASE原则
BA:基本可用(Basically Available)
S:软状态(Soft State)
E:最终一致性(Eventual Consistency)
常见的注册中心实现对比
- mysql单机(CA)
- eureka集群(AP)
- zookeeper集群(CP)
- nacos集群(AP或CP)
- redis集群(AP)
Nacos集群实现协议
- AP架构
阿里自研的distro协议。
特点:
Nacos每个节点都平等的处理写请求,同时会把新数据同步到其它节点。
每个节点只负责部分数据,比如上面提到的心跳检查,每个节点负责一部分心跳检查,然后将结果同步给其它节点来保持数据一致性。
每个节点独立处理读请求,及时从本地发出响应。 - CP架构
raft协议。
特点:
实现简单,使用方便。
能够保证强一致性。
Nacos CP架构实现源码
先看看英文注释:使用简化的raft协议管理nacos集群。
后面这个类会在1.4.x版本废弃,后面会使用JRaft协议。先来看看raft协议的使用吧。
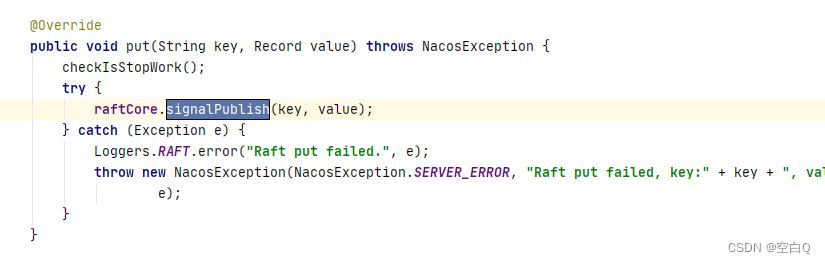
我们从这个方法开始看起,
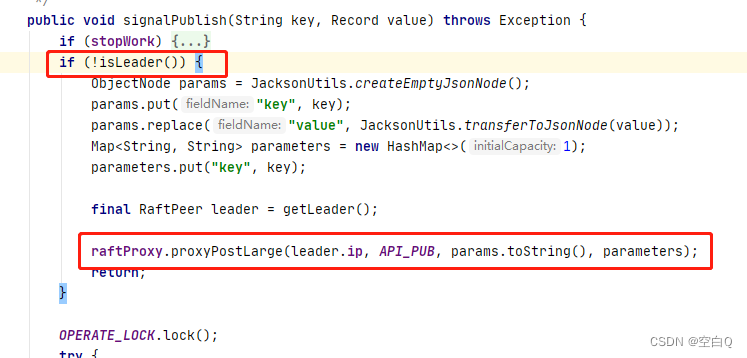
- 当前这个节点是否是leader
如果不是leader节点,那么会调用API。
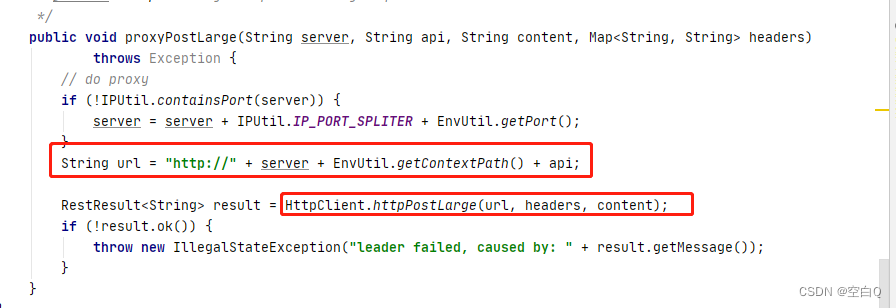
调用API,发送http请求,请求这个地址:/v1/ns/raft/datum。
这块就相当于,一个写请求进来,发现这个节点不是leader节点,那么它就会把这个请求进行转发,转发给leader节点。
- 当前节点是leader节点
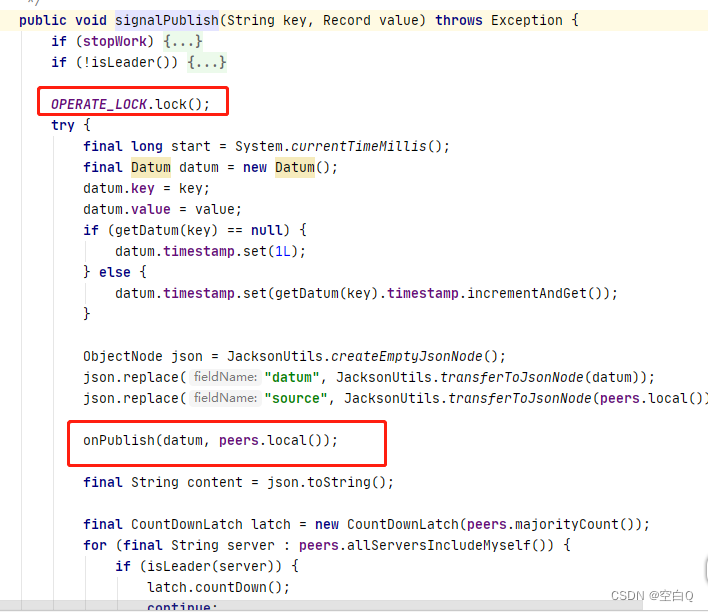
如果是leader节点,那么写数据时,肯定要先加锁,防止并发冲突,然后重点看一下onPublish方法。
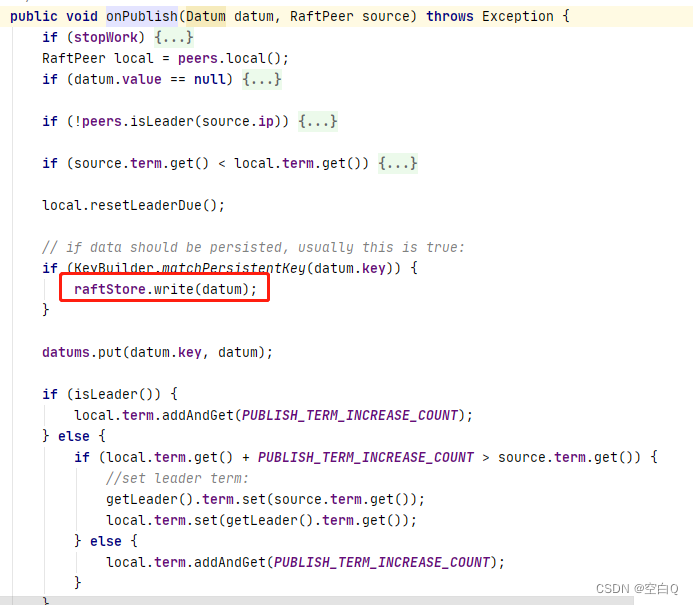
通过raft算法进行写数据。
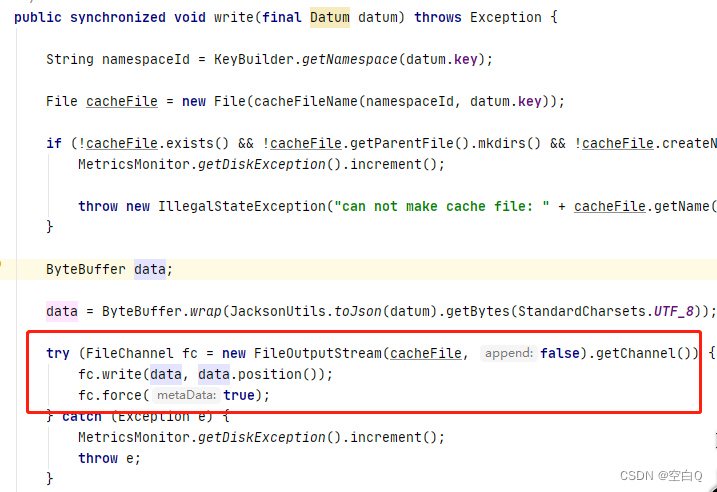
写文件,刷盘。
那么文件会写到哪里呢,我们看下cacheFileName:

最后数据文件会放在这个这个目录下。
然后,数据文件写完之后,后面会进行同步操作。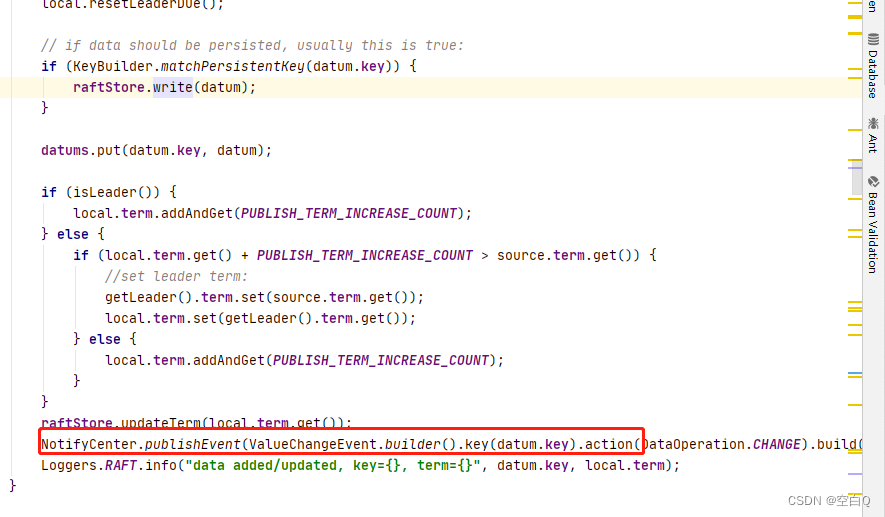
发布一个数据变动事件。

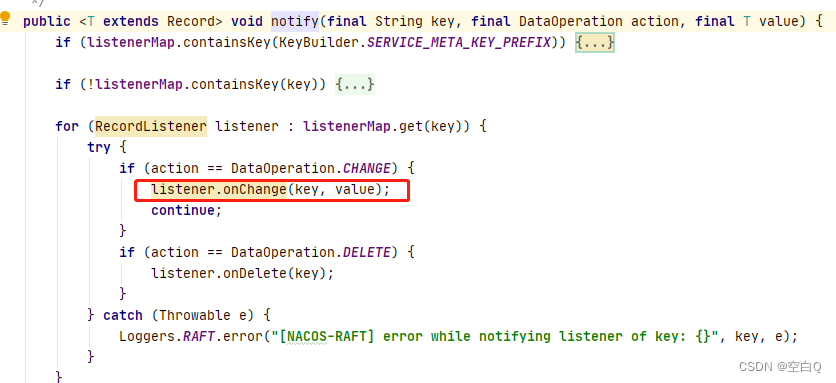
里面调用了listener.onChange方法,刷新内存。
然后再回到最外面的方法:
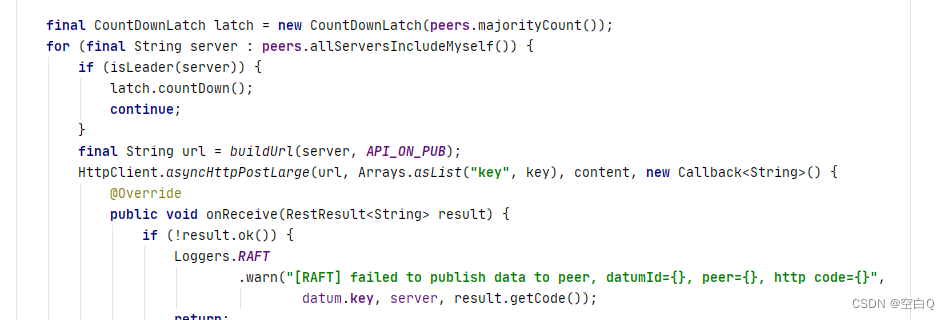
onPublish执行完成后,也就是leader执行执行完成后,创建了一个CountDownLatch,这个就是用来保证同步半数以上从节点。经典的半数以上写实现方式。
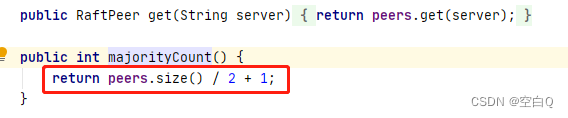
需要半数以上。
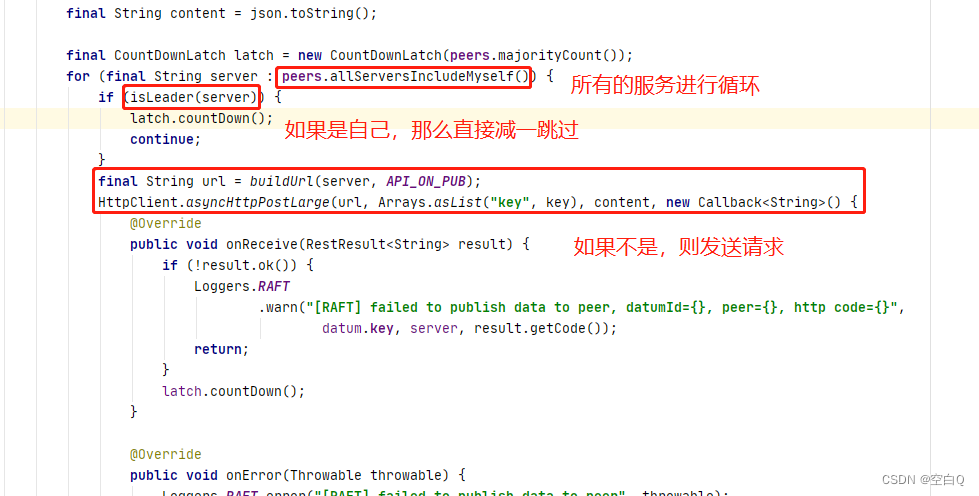
请求地址:

一步就直接提交,没有两阶段,所以这是简化版的raft算法。
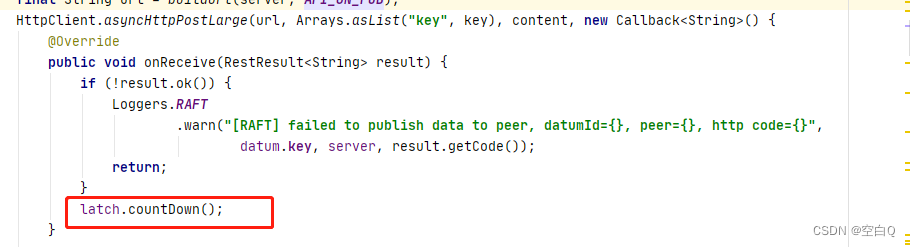
执行完成后latch减一。
最后等待执行完成就结束了。
Nacos CP架构leader是如何选举的呢?
我们从init()来看看源码:
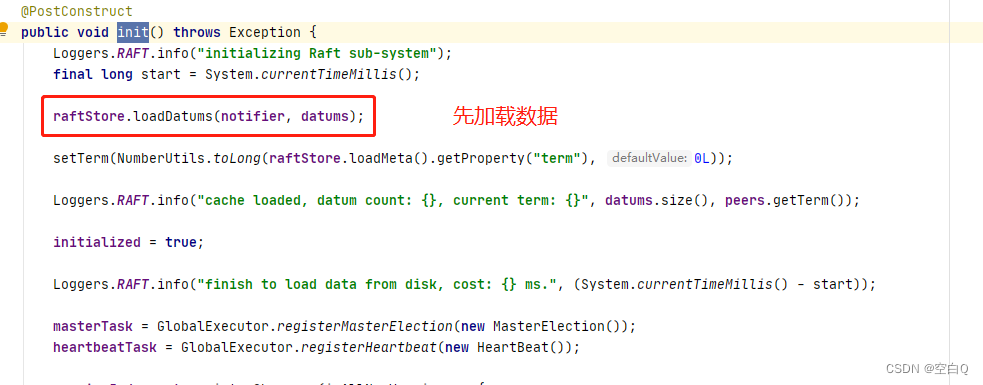
再往下是两个任务,第一个是主节点的选举,第二个是心跳任务。
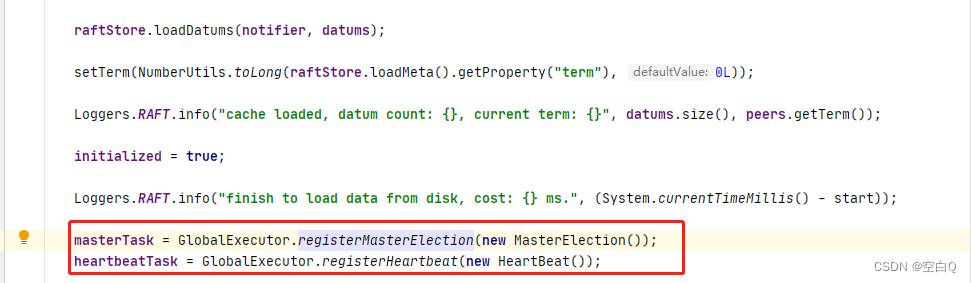
先看第一个主节点选举任务。

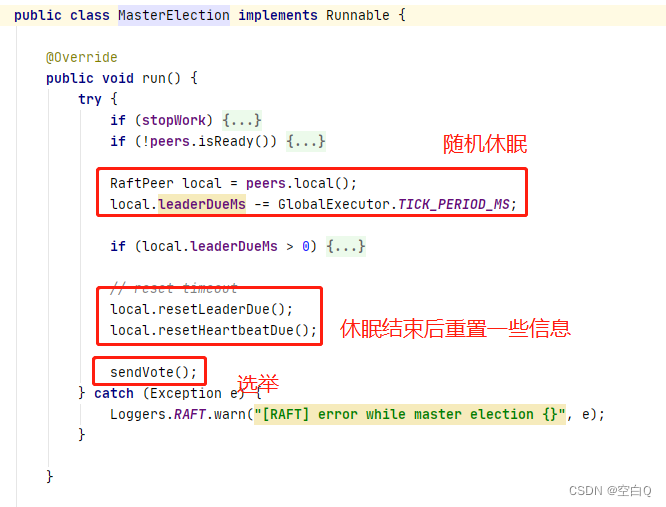
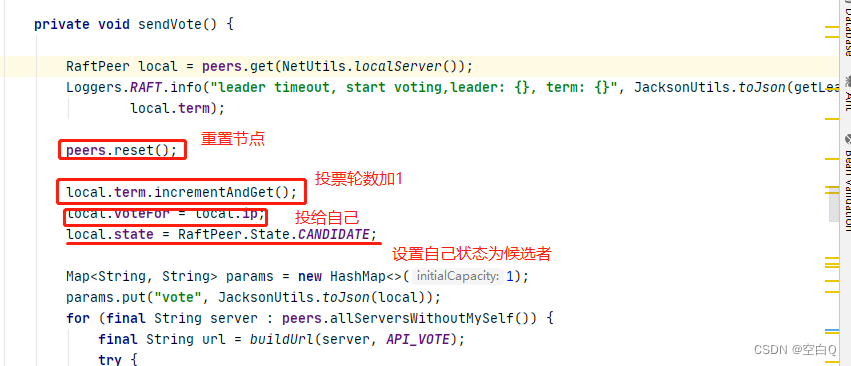
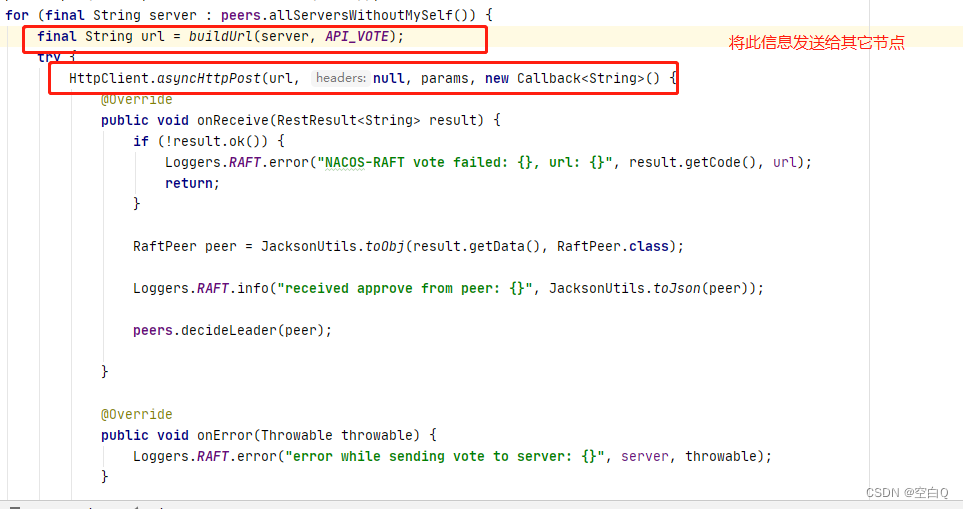
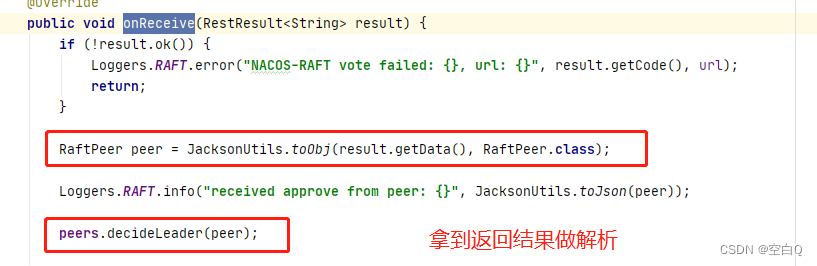
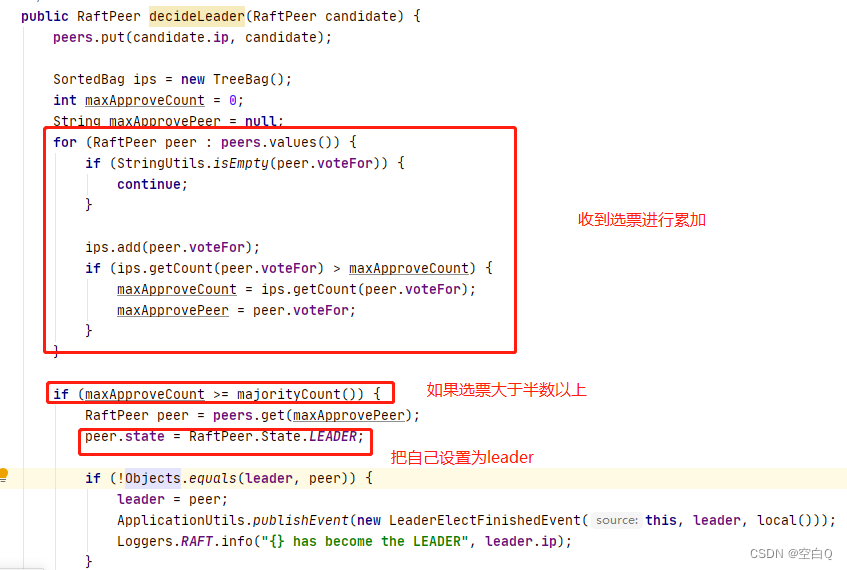
再看一下peers.decideLeader(peer);方法:
然后再回头看一下刚刚的HTTP请求:
final String url = buildUrl(server, API_VOTE);String API_VOTE = UtilsAndCommons.NACOS_NAMING_CONTEXT + "/raft/vote";
public synchronized RaftPeer receivedVote(RaftPeer remote) {if (stopWork) {throw new IllegalStateException("old raft protocol already stop work");}if (!peers.contains(remote)) {throw new IllegalStateException("can not find peer: " + remote.ip);}RaftPeer local = peers.get(NetUtils.localServer());// 如果收到的候选节点的term小于本节点的termif (remote.term.get() <= local.term.get()) {String msg = "received illegitimate vote" + ", voter-term:" + remote.term + ", votee-term:" + local.term;Loggers.RAFT.info(msg);// 则更新votefor为本节点,也就是说本节点更适合做leaderif (StringUtils.isEmpty(local.voteFor)) {local.voteFor = local.ip;}return local;}// 否则,更新重置选举时间local.resetLeaderDue();// 设置状态为followlocal.state = RaftPeer.State.FOLLOWER;// 投票给该候选节点local.voteFor = remote.ip;local.term.set(remote.term.get());Loggers.RAFT.info("vote {} as leader, term: {}", remote.ip, remote.term);// 然后将本地节点作为http结果返回return local;}
之后就是刚刚的后续操作,拿到后遍历查看票数,如果大于半数,设置自己为leader。
这块代码在高版本就被启用了,引入了jraft,所以简单了解这块思想就好。