办公自动化
文章目录
- 办公自动化
- 文件与文件夹
- os模块
- 批量操作文件及文件夹
- 文件相关读写操作及临时文件
- 压缩和解压缩文件
- 案例
- **王者图片下载批量打包处理**
- 文件搜索工具
- 文件自动分类
- 一键自动清理重复文件
- 批量转换图片格式
- xlwings操作Excel
- **简单使用**
- 创建app对象
- 创建Book对象
- Sheet工作表
- 引用区域和单元格操作
- python-docx操作Word
- 标题、图片、表格添加
- word系统样式使用
- 对齐、缩进、段落间距
- 行间距、字体格式设置
- 案例
- 提取文字
- 提取表格
- 拆分pdf
- 合并pdf
- 旋转pdf
- 页码倒序排序
- 案例
- 添加水印
- 给pdf文件添加密码
- 解除密码
- 综合案例
- 提取图片
- PPT
文件与文件夹
os模块
getcwd
import os
print(os.getcwd())#输出当前代码所在模块的路径
#E:\Python\Python\python进阶\办公自动化\code
切换目录到web开发下:
os.chdir('E:\Python\Python\python进阶\web开发')print(os.getcwd())
#E:\Python\Python\python进阶\web开发
listdir
查看当前目录下的所有文件和文件夹,并判断是否是文件和文件夹
dir_lsit=os.listdir()
print(dir_lsit)
for d in dir_lsit:print(d,os.path.isdir(d),os.path.isfile(d))
scandir
遍历一个文件夹下面所有的文件

查看文件的信息
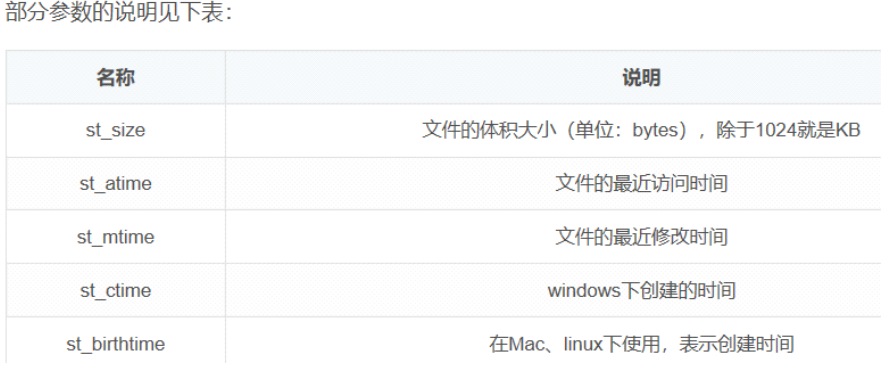
print(os.scandir())
for file in os.scandir():print(file,file.name,file.is_dir())print(file.stat())print(file.stat().st_size,file.stat().st_ctime)#结果:
<DirEntry 'axf_vue'> axf_vue True
os.stat_result(st_mode=16895, st_ino=0, st_dev=0, st_nlink=0, st_uid=0, st_gid=0, st_size=0, st_atime=1675142374, st_mtime=1674647728, st_ctime=1674647728)案例:
# 1.键盘输入一个路径
# 2.统计该路径下的文件和文件夹,以及分别的数量
# 3.统计当前路径下包含文件名中含demo的文件数量,注意不区分大小写
import ospath = input('输入一个路径')
os.chdir(path)file_list = []
dir_list = []
for file in os.scandir():if file.is_dir():dir_list.append(file.name)else:file_list.append(file.name)
print(f'文件夹的数量是:{len(dir_list)},文件夹是:{dir_list}')
print(f'文件的数量是:{len(file_list)},文件是:{file_list}')demo_list = []
for name in file_list:if 'demo' in name.lower():demo_list.append(name)
print(f'demo文件的数量是:{len(demo_list)},文件名是:{demo_list}')
walk
os模块的walk()函数,用来遍历目录树的,可以方便的遍历以输入的路径为root的所有子目录和其中的文件,
walk函数是一个生成器,调用方式是在一个for…in…循环中,walk生成器每次返回的是一个含有3个元素的tuple,分别是(dirpath, dirnames, filenames )
import osfor dirpath, dirname, files in os.walk('./'):print(dirpath, dirname, files)
glob搜索,匹配文件名
支持通配符操作,有“**”、“?”、“[]”这三个通配符,
-
“*”:代表0个或者多个字符;
-
“?”:代表一个字符;
-
“[]”:匹配指定范围内的字符,如[0-9]匹配数字;
glob模块的主要方法就是glob,该方法返回所有匹配的文件路径列表(list);该方法需要一个参数用来制定匹配的路径字符串(字符串可以为绝对路径也可以为相对路径), 其返回文件名只包括当前目录里的文件名,不包括子文件夹里的文件。
获取当前目录下d开头的文件,但不能获取子文件里的内容
import glob
t_lsit=glob.glob('d*')
print(t_lsit)
当规则与另一个参数recursive=True配合的时候,可以深入到路径的子目录中去匹配
t_list = glob.glob('**') # 获取当前目录的文件和文件夹
t_list1 = glob.glob('**/') # 获取当前目录的文件夹
t_list2 = glob.glob('**/*.py',recursive=True) # 可以遍历出所有的子目录
print(t_list)
print(t_list1)
print(t_list2)
案例:
# 键盘输入一个路径
# 所有该路径下文件大小超过50M的zip文件
# 搜索该路径下最后修改日期在30天前的文件
# 打印显示2,3的文件import os, datetime, globpath = input('输入要查询的路径:')
os.chdir(path)paths = glob.glob('**/*.zip', recursive=True)
for path in paths:file_size = os.stat(path).st_size / 1024 / 1024file_modify = datetime.datetime.fromtimestamp(os.stat(path).st_mtime)days = (datetime.datetime.now() - file_modify).daysif (file_size > 50) and (days > 30):print(f'压缩包的名称是:{path},文件大小是:{file_size}MB,修改时间:{days}天前')批量操作文件及文件夹
mkdir、makedirs
创建文件夹和多层文件夹
import os
if not os.path.exists('package01'):os.mkdir('package01')#创建多层文件夹
os.makedirs('package02/package03/package04')shutil
移动文件或者文件夹
复制/移动/删除文件夹需要借助于shutil模块
import shutil
import os
# 删除文件夹
shutil.rmtree('package02')
#删除文件
os.remove('文件名')
# 复制文件
shutil.copy('demo1.py', 'package01')
# 复制文件夹
shutil.copytree('src', 'package0/srcc')
#移动文件或文件夹
shutil.move('demo1.py','package0/')
案例:
# 键盘输入一个路径
# 获取里面所有的mp4文件
# 重命名mp4文件在每个文件前面加前缀,前缀就是文件最后修改的年月日
# 新建文件夹:最新视频
# 将重命名的视频批量移动到最新视频文件夹# D:\下载\Video
import os, shutil, glob, datetimepath = input('输入要查询的路径:')
os.chdir(path)
if not os.path.exists('最新视频'):os.mkdir('最新视频')
for dirpath, dirname, files in os.walk('./'):for file in os.scandir(dirpath):if file.name.endswith('.mp4'):tm = datetime.datetime.fromtimestamp(file.stat().st_mtime)new_file = str(tm.year) + '_' + str(tm.month) + "_" + str(tm.day) + "_" + file.nameos.rename(dirpath + "/" + file.name, new_file)# 批量移动
fiel_lsit = glob.glob('*.mp4')
for name in fiel_lsit:shutil.move(name, '最新视频/')
print('Over!!!!')文件相关读写操作及临时文件
读
f=open('a.txt',mode='tr')
#print(f.read()) #读取所有
print(f.read(2)) #读取两个字节
f.close() #上下文管理器,自动释放资源,不需要close()
with open('a.txt', mode='tr') as f:context = f.read()print(context)
写
with open('b.txt', mode='w') as f: #文件存在,写入内容,文件不存在,自动创建文件,f.write('Hello world')#每次写入内容都会覆盖原有的内容,with open('b.txt', mode='a') as f: #追加内容,如果文件不存在,也会自动创建文件再写入内容f.write('Python')
临时文件的创建和读取
创建临时文件或者文件夹需要使用tempfile模块
temp文件夹就是用来存储文件操作过程中产生的临时文件的,比如:常用的办公软件和其他应用程序通常会临时保存用户的工作结果,以防止意外情况造成损失,即使用户没有保存正在处理的文件,许多程序也会保存已被用户删除、移动和复制的文本。
在windows系统,c:/windows/temp文件夹中,经常会有一些后缀名为temp的文件,在该文件夹中的这些文件其实都是临时文件,有的大小甚至是0kb的大小,它们可能是系统被误关机或者其他程序没有删除而生的
该模块这种TemporaryFile方法是tempfile最常用的方法之一,其目的就在于提供一个统一的临时文件调用接口,读写临时文件,并且保证临时文件的隐形性,这个类的构造方法和一般的文件对象很类似:
#源码分析
def TemporaryFile(mode='w+b', buffering=-1, encoding=None,newline=None, suffix=None, prefix=None,dir=None, *, errors=None):#默认的打开模式是w+b,
#NamedTemporaryFile方法是在TemporaryFile基础上,加了一个delete参数,默认值为True,当此参数为True时和TemporaryFile方法完全一致,如果是False,那么临时文件对象在被关闭时不会删除def NamedTemporaryFile(mode='w+b', buffering=-1, encoding=None,newline=None, suffix=None, prefix=None,dir=None, delete=True, *, errors=None):
创建临时文件夹
from tempfile import TemporaryDirectory,TemporaryFile
with TemporaryDirectory() as temp_dir:print('文件夹已经创建',temp_dir)
#结果如下:创建了一个随机的文件夹,名为:tmpcfnpigqb
文件夹已经创建 C:\Users\31812\AppData\Local\Temp\tmpcfnpigqb
创建临时文件
from tempfile import TemporaryDirectory,TemporaryFilewith TemporaryFile(mode='w+') as temp_file:temp_file.write('我是文件搬运工')temp_file.seek(0) #指针指向文件的开头data=temp_file.read() #从文件的开头开始读数据print(data)
压缩和解压缩文件
压缩文件
压缩包的处理使用zipfile模块,创建一个压缩包文件
import os, zipfiledir_list=os.listdir()
with zipfile.ZipFile(file='mypyfile.zip',mode='w') as zopobj:for file in dir_list:if file.endswith('.py'):zopobj.write(file)
如果没有这个压缩包,直接创建的话使用w,如果已经存在了,要想压缩包里添加内容,将w换成a即可,否则系统会报错
读取压缩文件
读取或者查看一个zip文件中的内容
import zipfilewith zipfile.ZipFile(file='mypyfile.zip',mode='r') as zopobj:print(zopobj.namelist())
有中文名的文件夹在输出结果时,会出现乱码的问题,解决如下:
with zipfile.ZipFile(file='mypyfile.zip',mode='r') as zopobj:for file_name in zopobj.namelist():print(file_name.encode('cp437').decode('utf-8'))
解压缩文件
解压单个文件 .extract(压缩包内解压的文件名,解压到哪个位置)
with zipfile.ZipFile(file='mypyfile.zip',mode='r') as zopobj:zopobj.extract('demo3.py','D:/桌面')
解压多个文件.extract(path=解压到哪个位置)
with zipfile.ZipFile(file='mypyfile.zip',mode='r') as zopobj:zopobj.extractall(path='./files/')
案例:
# 1.找出指定目录下所有距离上次修改时间超过15天的md文件
# 2.将所有文件重命名,再原本文件名开头加上最后修改日期
# 3.创建一个新的文件夹:长期未使用
# 4.将所有文件移动到长期未使用文件夹下
# 5.对长期未使用文件夹进行压缩处理,并在名字上加上今天日期import os, shutil, datetime, zipfile# D:\桌面\demo
path = input("请输入路径:")
os.chdir(path)
# 创建文件列表,遍历当前路径的文件
file_list = []
for dirpath, dirname, files in os.walk('./'):# 获取每个文件夹中的文件for file in os.scandir(dirpath):if not file.is_dir():# 如果不是文件夹则获取文件的创建时间file_time = file.stat().st_mtimefile_datetime = datetime.datetime.fromtimestamp(file_time)datetime_detail = datetime.datetime.now() - file_datetime# 获取是md文件并且是大于15天的文件if datetime_detail.days >= 15 and file.name.endswith('.md'):# 构造新的名字new_name = f'{file_datetime.strftime("%Y-%m-%d")}-{file.name}'# 对文件进行重命名os.rename(dirpath + '/' + file.name, new_name)# 并将重命名的文件追加到file_list列表file_list.append(new_name)print(file_list)# 创建一个新的文件夹
if not os.path.exists('长期未使用'):os.mkdir('长期未使用')# 将所有文件移动到长期未使用文件夹下
for file1 in file_list:shutil.move(file1, '长期未使用')os.chdir('长期未使用/')
zipfile_list = os.listdir('./')zip_filename = f"{datetime.datetime.now().strftime('%Y-%m-%d')}_长期未使用.zip"
with zipfile.ZipFile(zip_filename, mode='w') as zipobj:for file in zipfile_list:zipobj.write(file)
案例
王者图片下载批量打包处理
#1.下载王者荣耀高清壁纸图片
#2.将不同人物的图片分别保存到临时文件夹
#3.将不同人物的图片打包压缩成zip文件
#4.移动图片到pictures文件夹
文件搜索工具
pathlib内置库
# 1.输入要查找的文件
# 2.支持模糊查询
# 3.将匹配的文件信息存放到一个列表中
# 4.打印所有符合的文件信息from pathlib import Pathwhile True:folder = input('搜索文件的路径:')folder = Path(folder.strip())if folder.exists() and folder.is_dir():breakelse:print('输入的路径不存在或者不准确,重新输入!!')search = input('输入文件或者文件夹的名字:')
result = list(folder.rglob(f'*{search}*'))
if not result:print(f'在{folder}下未找到关键字名称是{search}的文件或者文件夹')
else:result_folder = []result_file = []for i in result:if i.is_dir():result_folder.append(i)else:result_file.append(i)if result_folder:print(f'查找的包含关键字{search}的文件夹有:')for i in result_folder:print(i)if result_file:print(f'查找的包含关键字{search}的文件有:')for i in result_file:print(i)文件自动分类
import os, shutil, globsrc_path = './'
new_path = './分类文件夹'if not os.path.exists('分类文件夹'):os.mkdir(new_path)
file_num = 0
dir_num = 0
for file in glob.glob(f'{src_path}/**/*', recursive=True):if os.path.isfile(file):filename = os.path.basename(file)if '.' in filename:suffix = filename.split('.')[-1]else:suffix = 'others'if not os.path.exists(f'{new_path}/{suffix}'):os.mkdir(f'{new_path}/{suffix}')dir_num += 1shutil.copy(file, f'{new_path}/{suffix}')file_num += 1
print(f'整理完成!有{file_num}个文件和{dir_num}个文件夹!!!')
一键自动清理重复文件
import os, glob, filecmpdir_path = input('要处理文件的文件夹')
file_list = []
for i in glob.glob(dir_path + '/**/*', recursive=True):if os.path.isfile(i):file_list.append(i)
for x in file_list:for y in file_list:if x != y and os.path.exists(x) and os.path.exists(y):if filecmp.cmp(x, y):os.remove(y)
from pathlib import Path
from filecmp import cmpsrc_folder = Path('./分类文件夹')
dest_folder = Path('./repeat')
if not dest_folder.exists():dest_folder.mkdir(parents=True)file_list = []
result = list(src_folder.rglob('*'))
for i in result:if i.is_file():file_list.append(i)
for m in file_list:for n in file_list:if m != n and m.exists() and n.exists():if cmp(m, n):m.replace(dest_folder / m.name)m.unlink()
批量转换图片格式
from pathlib import Path
from PIL import Imagesrc_folde = 'D:\图片\Saved Pictures'
dest_folder = 'D:\图片\格式转换'src_folde = Path(src_folde)
dest_folder = Path(dest_folder)
if not dest_folder.exists():dest_folder.mkdir(parents=True)
file_list = list(src_folde.glob('*.jpg'))
for i in file_list:dest_file = dest_folder / i.namedest_file = dest_file.with_suffix('.png')Image.open(i).save(dest_file)print(f'{i.name}成功完成转换')
xlwings操作Excel
官网地址
在我们操作之前可以先了解下,如下内容:
- 新建:创建一个不存在的工作薄或者工作表
- 打开:打开一个已经存在的工作薄
- 引用:就是告诉程序,你要操作哪个对象。比如你打开了A、B、C三个工作薄,现在你想操作A工作薄,就要
先引用A - 激活:我们可以同时打开多个工作薄,但是一次只能操作一个工作薄,我们正在操作的这个工作薄称为*当前
活动工作薄。
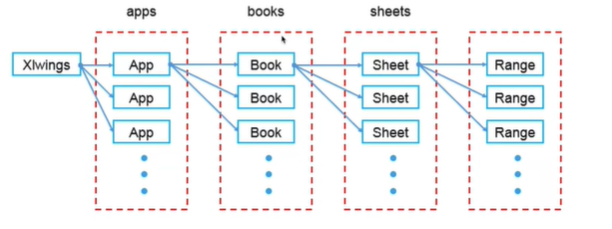
在xlwings中
- Excel程序用App来表示,多个Excel程序集合用Apps表示:
- 单个工作簿用B00k表示,工作簿集合用Bo0ks表示:
- 单个工作表用Sheet表示,工作表集合用Sheets表示:
- 区域用Range表示,既可以是一个单元格,也可以是一片单元格区域。
import xlwings as xw
xw.App 打开一个excel应用
xw.Book 创建一个工作簿
xw.Sheet 创建一个工作表简单使用
#先安装
pip install xlwings
import xlwings as xw# 打开excel,参数visible表示处理过程是否可视,add_book表示是否打开新的Excel程序
with xw.App(visible=True, add_book=False) as app:# 创建一个工作簿book = app.books.add()# 工作簿中创建一个sheet表sht = book.sheets.add()# 向表格A1单元格写入‘Hello Python’sht.range('A1').value = 'Hello Python'# 保存book.save('./ext.xlsx')创建app对象
import xlwings as xw创建app应用对象
app=xw.App()
pid=app.pid #获取应用的pid号
print(pid)app=xw.App()
pid=app.pid
print(pid)apps=xw.apps
print(apps.count) #查看一共有多少个应用.
app对象获取及内容添加
app1 = xw.apps[12000] # 根据pid号打开
app1.activate() # 激活,相当于打开应用
wb = app1.books.add() # 添加工作簿
sht=wb.sheets['Sheet1'] #工作表对象
sht.range('A1').value='Hello Python123'
wb.save()#保存,默认保存当前目录
wb.close()#关掉工作簿
app1.kill()创建Book对象
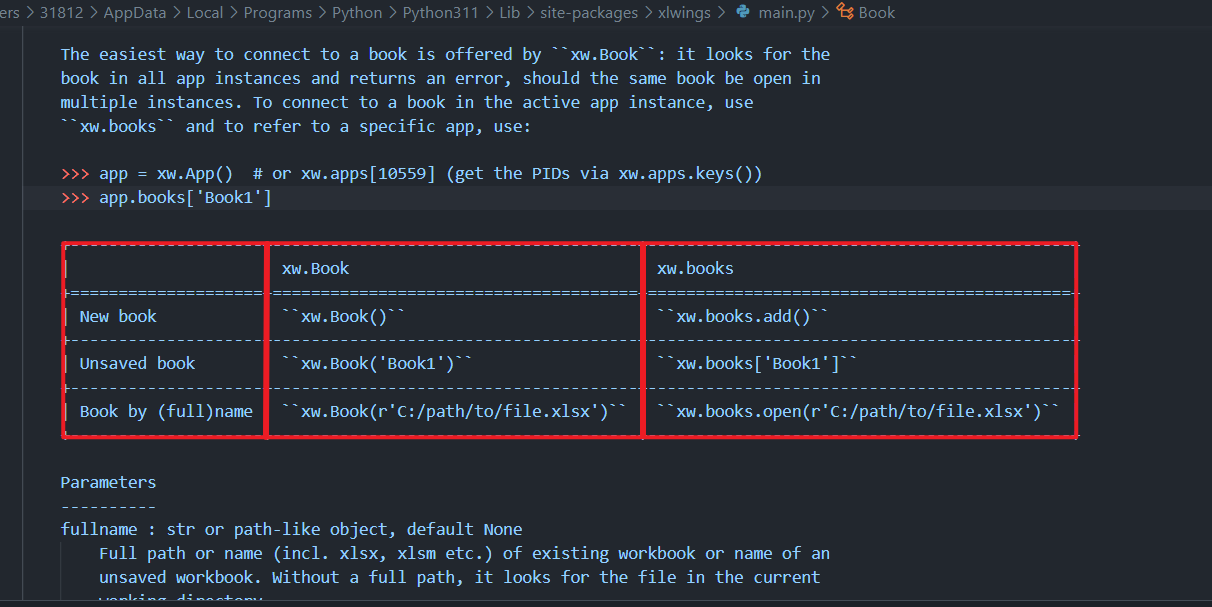
方式1是创建一个新的App,并在新的App中新建一个Book,方式2是在当前App下创建Book
如果是打开一个已经存在的则使用:
wb=app.books.open('绝对路径或者相对路径的excel文件')
或者
wb=xw.Book('绝对路径或者相对路径的excel文件')
激活与保存
wb.activate()
#如果steal_focus=True,则把窗口显示到最上层,并且把焦点从Python切换到Excel
保存工作簿
wb.save()
wb.save('存储路径')
关闭
wb.close()只是关闭不会保存,所以在关闭之前要save()一下,可以考虑使用with搭建上下文,实现关闭资源。
import xlwings as xw
#创建book对象
book=xw.Book('./ext.xlsx')#打开已有的工作簿
sht=book.sheets['Sheet1']
sht.range('A2').value='我学Python'
book.save()#保存
book.close()
import xlwings as xw
#创建book对象
book=xw.Book() #打开一个空白的工作簿,底层源码会自动创建app
sht=book.sheets['Sheet1']
sht.range('A6').value='人生苦短'
sht.range('B1').value='我学Python'
book.save('./ext.xlsx')#保存
book.close()
Sheet工作表
创建与查看
sht=wb.sheets.add()
#或者
sht=wb.sheet.add('test',after='sheet2')
#test为工作表名称,省略的话为Excel默认名称,第二个参数为插入位置,可选before或者after
若想引用某一个sheet,可以通过
sht=wb.sheets('sheet1')#指定名称或者sheet工作表
sht=wb.sheets(1)#根据序号获取
sht=wb.sheets.active#获取当前活动的工作表
使用:
import xlwings as xw
app=xw.App(visible=True,add_book=False)
app.display_alerts=False #打开屏幕更新
app.screen_updating=False #filepath='./test1.xlsx'
wb=app.books.open(filepath)sht1=wb.sheets.add('Sheet4',after='Sheet1')
sht2=wb.sheets.add('Sheet5',before='Sheet2')print(wb.sheets.count) #打印工作表的个数wb.save('test2.xlsx')
wb.close()
app.quit()#退出import xlwings as xw
app=xw.App(visible=True,add_book=False)
app.display_alerts=False #打开屏幕更新
app.screen_updating=False #filepath='./test2.xlsx'
wb=app.books.open(filepath)# sht=wb.sheets('Sheet4')#访问Sheet4
# sht.range('A1').value ='自动化'sht=wb.sheets(2) #按照序号,从左往右顺序
sht.range('B2').value='Hello!!'
sht.range('B3').value='Python!!'wb.save('test2.xlsx')
wb.close()
app.quit()#退出sheet对象常用方法
#清楚工作表的所有内容和样式
sht.clear()
#清楚工作表的所有内容但是还保留原有格式
sht.clear_contents()
#删除工作表
sht.delete()
#自动调整行高列宽
sht.autofit('c')
#在活动工作簿中选择
sht.select()
可以通过属性获取工作表的名称,所有单元格的区域对象,当前动作表的索引值
sht.name sht.cells shet.index sht.names
引用区域和单元格操作
在操作区域或者单元格之前,首先要引用它们,就是表明要操作的工作区域或者单元格是哪些,可以认为区域是多个单元格
引用区域的方式:
xw.Range('A1:D4')
xw.Range((1,1),(4,4))
xw.Range(xw.Range('A1'),xw.Range('D4'))
xw.Range(xw.Range('A1:E6'),xw.Range('C3:D7'))xw.Range('NamedRange')
app.range("Al")#注意是小写的range
sht.range('Al')
xw.books ['MyBook.x1sx'].sheets[0].range('A1')
sht['A1']
sht['A1:D4']
sht[0,5]
sht[:5,:5]
区域管理方式:
range.offset(row_offset=5,column_offset=2)
表示偏移,row.offset行偏移量(正数表示向下偏移,负数相反),column_offset列偏移量(正数表示向右偏移,负数相反)
#注意:是将选区范围进行偏移,内容不进行偏移range.expand(mode='down') 扩展区域,参数可选'down','right','table',类似我们使用向下、向右或者下右方的区域扩展操作。range.resize(row_size=4,column_size=2)表示调整选中区域的大小,参数表示调整后区域的行、列的数
量。
range.current_region 表示全选 类似Ctrl+A
- 存储数据
import xlwings as xwapp=xw.App(visible=True,add_book=False)
app.display_alerts=False
app.screen_updating=Falsefilepath='./text1.xlsx'
wb=app.books.open(filepath)sht1=wb.sheets('Sheet1')#单个内容的添加
sht1.range('A1').value ='Hello'
#多个内容的添加
sht1.range('C1').value =[100,200,300]
#扩展区域添加
sht1.range('A5').options(transpose=True).value =['AAA','BBB','CCC']
#down right rable
sht1.range('B8').options(expand='table').value=[(1,2),(3,4)]wb.save()
wb.close()
app.kill()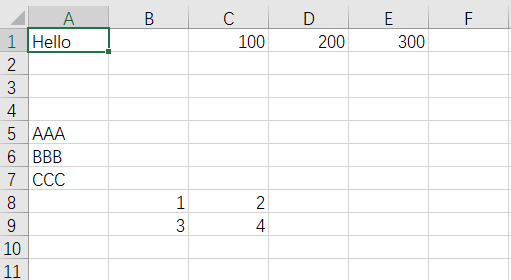
- 读取数据
import xlwings as xwapp=xw.App(visible=True,add_book=False)
app.display_alerts=False
app.screen_updating=Falsefielpath='./text1.xlsx'
wb=app.books.open(fielpath)sht1=wb.sheets['Sheet1']
a1=sht1.range('A1').value
print(f'A1: {a1}')
v=sht1.range((9,3)).value
print(f'v: {v}')r=sht1.range('B8:C9').options(ndim=2).value
print(f'B8:C9的值为 : {r}')r2=sht1.range((8,2),(9,3)).options(ndim=2).value
print(f'B8:C9的值为 : {r2}')wb.save()
wb.close()
app.quit()

- 格式设置与清除
# 获取颜色
print(sheet.range('C1').color)
# 设置颜色
sheet.range('C1').color = (255, 0, 120)
# 清除颜色
sheet.range('C1').color = None
import xlwings as xwapp = xw.App(visible=True, add_book=False)
app.display_alerts = False
app.screen_updating = Falsefilepath = './text1.xlsx'
wb = app.books.open(filepath)sht = wb.sheets('Sheet2')# 合并
sht.range('B2:C2').api.merge() # unmerge()取消合并# 设置
# 字体设置
rng = sht.range('D4')
rng.api.Font.Color = 0xffff00 # 字体颜色
# rng.api.Font.ColorIndex=17#字体颜色
rng.api.Font.Size = 25 # 字体大小
rng.api.Font.Blod = True
rng.api.Font.Name = '微软雅黑'# 对齐方式
# -4108 水平居中 -4131 靠左 -4152 靠右
# -4108 水平居中(默认) -4160 靠上 -4107 靠下 -4130 自动换行对齐
rng.api.HorizontalAlignment = -4108
rng.api.VerticalAlignment = -4130# 边框设置
rng.api.Borders(7).LineStyle = 1 # 1指的的是实线,7指的是左边框
rng.api.Borders(7).Weight = 3rng.api.Borders(10).LineStyle=2 #10指的是右边框
rng.api.Borders(10).Weight = 5#数字格式
rng.api.NumberFormat="0.00"wb.save()
wb.close()
app.quit()- 行和列的删除
import xlwings as xwapp=xw.App(visible=True,add_book=False)
app.display_alerts=False
app.screen_updating=Falsefilepath='./text1.xlsx'
wb=app.books.open(filepath)
sht=wb.sheets["Sheet3"]#单元格删除
#删除行
# sht.range('2:2').delete() #删除第二行
# sht.range('B2').api.EntireRow.Delete() #删除B2这一行
#删除列
# sht.range('B:B').delete() #删除B列
# sht.range('B2').api.EntireColumn.Delete() #删除B2这一行#删除单元格内容
# sht.range('B2').clear_contents()
#删除单元格样式和内容
sht.range('B2').clear()
wb.save()
wb.close()
app.quit()案例:批量修改数据格式
import random
import xlwings as xw
app =xw.App()
workbook=app.books.open('data.xlsx')
shts=workbook.sheets
for sht in shts:row_num=sht['A1'].current_region.last_cell.row #获取A1单元格最后一行的行号#print(row_num)sht['A2:A{}'.format(row_num)].number_format ='m/d'sht['B2:B{}'.format(row_num)].number_format='0.0'#行设置sht['A1:D1'].api.Font.Size=15sht['A1:D1'].api.Font.Name='宋体'sht['A1:D1'].api.Font.Bold=Truer=random.randint(0,255)g=random.randint(0,255)b=random.randint(0,255)sht['A1:D1'].api.Font.Color=xw.utils.rgb_to_int((r,g,b))sht['A1:D1'].color=xw.utils.rgb_to_int((255,255,0))sht['A1:D1'].api.HorizontalAlignment=xw.constants.HAlign.xlHAlignCentersht['A1:D1'].api.VerticalAlignment=xw.constants.HAlign.xlHAlignCenterfor cell in sht['A1'].expand('table'):for b in range(7,12):cell.api.Borders(b).LineStyle=1cell.api.Borders(b).Weight=2workbook.save('data2.xlsx')
app.quit()
案例:批量读写数据
import xlwings as xwwb=xw.Book()
sht=wb.sheets.active
#向表中写入数据
for i in range(1,11):for j in range(1,6):sht.range(i,j).value='{}-{}'.format(i,j)
#读取数据
res=sht.range((1,1),(5,5)).expand('table').value
print(res)
wb.save('auto.xlsx')
wb.close()python-docx操作Word
官网
安装
pip install python-docx
基本使用
from docx import Document
# 文档结构:Document(xxx.docx) Paragraph(段落) Run(文字块)
#创建文档对象,添加段落内容# document=Document() #创建一个空的docx文件
# document.save('doc01.docx') #保存document=Document(docx='doc02.docx') #参数就是已经存在的文件名
#添加段落
paragraph1=document.add_paragraph('我要学数据分析')
paragraph2=document.add_paragraph('正在学习办公自动化')
paragraph3=paragraph2.insert_paragraph_before('正在努力学习!')
# paragraph3=paragraph2.insert_paragraph_after('正在努力学习!')
document.save('doc03.docx')标题、图片、表格添加
# 文档内容:标题、段落、文字块、图片和表格添加
# 标题添加: add_heading("标题名称"、level=标题等级)
# 段落添加: add_paragraph("段落文字内容")
# 文字块添加: 段落对象.add_run("文字内容")
# 添加图片: add_picture("图片地址"[,width=宽度,height=高度])
# 添加表格:add_table(rows=行数,cols=列数,表格形式)
# 文字块对象.add_break() 换行 add_page_break() 添加分页from docx import Document
from docx.oxml import OxmlElement
from docx.oxml.ns import qn
from docx.shared import Cmdoc = Document()# doc.add_heading("标题0",0)
# doc.add_heading("标题1------1111",1)
# doc.add_heading("标题2",2)
# doc.add_heading("标题3",3)
# doc.save('标题.docx')# paragraph = doc.add_paragraph("段落文字内容")
# paragraph.add_run('测试111')
# paragraph.add_run('测试222')
# paragraph.add_run('测试333').add_break()
# paragraph.add_run('测试444')
# doc.save('段落和文字块.docx')# doc.add_picture('rose.jpeg',width=Cm(13), height=Cm(9))
# doc.save('图片.docx')#自定义函数
def set_cell_border(cell, **kwargs):"""Set cell`s borderUsage:set_cell_border(cell,top={"sz": 12, "val": "single", "color": "#FF0000", "space": "0"},bottom={"sz": 12, "color": "#00FF00", "val": "single"},left={"sz": 24, "val": "dashed", "shadow": "true"},right={"sz": 12, "val": "dashed"},)"""tc = cell._tctcPr = tc.get_or_add_tcPr()# check for tag existnace, if none found, then create onetcBorders = tcPr.first_child_found_in("w:tcBorders")if tcBorders is None:tcBorders = OxmlElement('w:tcBorders')tcPr.append(tcBorders)# list over all available tagsfor edge in ('left', 'top', 'right', 'bottom', 'insideH', 'insideV'):edge_data = kwargs.get(edge)if edge_data:tag = 'w:{}'.format(edge)# check for tag existnace, if none found, then create oneelement = tcBorders.find(qn(tag))if element is None:element = OxmlElement(tag)tcBorders.append(element)# looks like order of attributes is importantfor key in ["sz", "val", "color", "space", "shadow"]:if key in edge_data:element.set(qn('w:{}'.format(key)), str(edge_data[key]))list1 = [["姓名", "性别", "家庭地址"],["李雷", "男", "湖北省"],["韩梅梅", "女", "北京市"],["夏洛特", "男", "广东省"],["马冬梅", "女", "湖南省"]
]table = doc.add_table(rows=5, cols=3)
for row in range(len(list1)):cells = table.rows[row].cellsfor col in range(len(list1[0])):cells[col].text = str(list1[row][col])set_cell_border(cells[col],top={"sz": 0.5, "val": "single", "color": "#000000", "space": "0"},bottom={"sz": 0.5, "val": "single", "color": "#000000", "space": "0"},left={"sz": 0.5, "val": "double", "color": "#000000", "space": "0"},right={"sz": 0.5, "val": "double", "color": "#000000", "space": "0"})
doc.save('表格.docx')word系统样式使用
from docx import Document
from docx.enum.style import WD_STYLE_TYPE
document=Document()
styles=document.styles# for s in styles:
# print(s)# paragraph_syles=[s for s in styles if s.type ==WD_STYLE_TYPE.] #WD_STYLE_TYPE.TABLE
# for style in paragraph_syles:
# print(style)
# table_syles=[s for s in styles if s.type ==WD_STYLE_TYPE.TABLE] #WD_STYLE_TYPE.TABLE
# for style in table_syles:
# print(style)for s in styles:if s.type ==WD_STYLE_TYPE.TABLE:document.add_paragraph('表格样式 : ' + s.name)table=document.add_table(3,3,style=s)heading_cells=table.rows[0].cellsheading_cells[0].text = '第一列内容'heading_cells[1].text = '第二列内容'heading_cells[2].text = '第三列内容'document.add_paragraph('\n')
document.save('所有表格样式.docx')
对齐、缩进、段落间距
#对齐
from docx import Document
from docx.enum.text import WD_PARAGRAPH_ALIGNMENT
document=Document()paragraph=document.add_paragraph()
print(paragraph.alignment)paragraph_format=paragraph.paragraph_format
print(paragraph_format.alignment)paragraph.alignment=WD_PARAGRAPH_ALIGNMENT.CENTER
print(paragraph.alignment)
paragraph.add_run('这是一个段落,请看对齐方式')
document.save('修改段落对齐.docx')#缩进
from docx import Document
from docx.enum.text import WD_PARAGRAPH_ALIGNMENT
from docx.shared import Inches
from docx.shared import Ptdocument=Document()
paragraph=document.add_paragraph()
paragraph_format=paragraph.paragraph_format
print(paragraph_format.left_indent)paragraph_format.left_indent=Inches(0.5)
print(paragraph_format.left_indent.inches)paragraph.add_run("段落缩进演示1")
paragraph.add_run("段落缩进演示2")
document.save('段落缩进.docx')
#间距
from docx import Document
from docx.shared import Ptdocument=Document()
paragraph1=document.add_paragraph('第一个段落')
paragraph2=document.add_paragraph('第二个段落')
paragraph1.paragraph_format.space_before=Pt(24) #段前间距
paragraph1.paragraph_format.space_after=Pt(24) #断后间距paragraph2.paragraph_format.space_before=Pt(30) #段前间距
paragraph2.paragraph_format.space_after=Pt(10)document.save('修改段落间距.docx')行间距、字体格式设置
#间距
from docx import Document
from docx.shared import Length
from docx.shared import Ptdocument=Document()
paragraph=document.add_paragraph()
paragraph_format=paragraph.paragraph_formatprint(paragraph_format.line_spacing)#获取默认行间距
paragraph.add_run('获取默认行间距').add_break()
paragraph.add_run('获取默认行间距获取默认行间距获取默认行间距获取默认行间距').add_break()paragraph_format.line_spacing=Pt(30)
print(paragraph_format.line_spacing.pt)
paragraph.add_run('设置后的行间距').add_break()
paragraph.add_run('设置后的行间距设置后的行间距设置后的行间距设置后的行间距').add_break()
document.save('行间距.docx')
#字体格式
from docx import Document
from docx.shared import RGBColor, Pt
from docx.enum.dml import MSO_THEME_COLOR_INDEX
from docx.enum.text import WD_UNDERLINEdocument = Document()
paragraph = document.add_paragraph()
run1 = paragraph.add_run('字体颜色设置')font = run1.font# font.color.rgb=RGBColor(200,100,100)
font.color.theme_color = MSO_THEME_COLOR_INDEX.ACCENT_1
font.size = Pt(20) # 1英寸 =2.54厘米 =72磅
font.italic = True # 倾斜
font.bold = True # 加粗
# font.underline = True # 下划线
font.underline = WD_UNDERLINE.DOUBLE # 下划线
document.save('格式设置.docx')案例
# 读取Excel批量制作准考证import xlwings as xw
from datetime import timedelta, datetime
from docx import Document
from docx.shared import Inches, Pt, Cm
from docx.oxml.ns import qn
from docx.enum.table import WD_TABLE_ALIGNMENT
from docx.enum.text import WD_PARAGRAPH_ALIGNMENT, WD_LINE_SPACINGdef chg_font(obj, fontname='微软雅黑', size=None):# 设置字体函数obj.font.name = fontnameobj.element.rPr.rFonts.set(qn('w:eastAsia'), fontname) # 只设置中文字体if size and isinstance(size, Pt):obj.font.size = size# 以默认模板建立文档对象
document = Document()
# 添加标题,并修改字体样式
head = document.add_heading(0)
run = head.add_run('班级准考证')
chg_font(run, fontname='黑体', size=Pt(18))
head.alignment = WD_PARAGRAPH_ALIGNMENT.CENTER
# 日期部分
p = document.add_paragraph()
t = datetime.today()
t1 = t.strftime('%Y年%m月%d日')
t2 = t + timedelta(days=3)
t3 = t2.strftime('%Y年%m月%d日')
run = p.add_run(f'{t1}到{t3}进行考试')
chg_font(run, size=Pt(14))
p.alignment = WD_PARAGRAPH_ALIGNMENT.RIGHT# 读取表格数据
wb = xw.Book('data.xlsx')
sheet = wb.sheets['Sheet1']
all_data = sheet.range('A2').expand('table').value
# 创建表格
tab = document.add_table(rows=len(all_data), cols=2)
tab.alignment = WD_TABLE_ALIGNMENT.CENTER
tab.autofit = True # 自适应
# 填充数据
for r in range(len(all_data)):cells = tab.rows[r].cellsfor index, cell in enumerate(cells):if index == 0:# 学生信息cell.paragraphs[0].paragraph_format.alignment = WD_PARAGRAPH_ALIGNMENT.RIGHTrun = cell.paragraphs[0].add_run('准考证')chg_font(run, size=Pt(20))run.add_break()p1 = cell.add_paragraph()p1.paragraph_format.alignment = WD_PARAGRAPH_ALIGNMENT.LEFTrun0 = p1.add_run(f'姓名:{all_data[r][1]}')chg_font(run0, size=Pt(14))run0.add_break()run1 = p1.add_run(f'学号:{all_data[r][0]}')chg_font(run1, size=Pt(14))run1.add_break()run2 = p1.add_run(f'性别:{all_data[r][2]}')chg_font(run2, size=Pt(14))run2.add_break()run3 = p1.add_run(f'考点:{all_data[r][3]}')chg_font(run3, size=Pt(14))run3.add_break()else:# 图片run=cell.paragraphs[0].add_run()run.add_break()run.add_break()run.add_break()run.add_break()run.add_picture('rose.jpeg',width=Cm(3),height=Cm(4))cell.paragraphs[0].paragraph_format.alignment = WD_PARAGRAPH_ALIGNMENT.LEFT# 保存数据
document.save('准考证.docx')
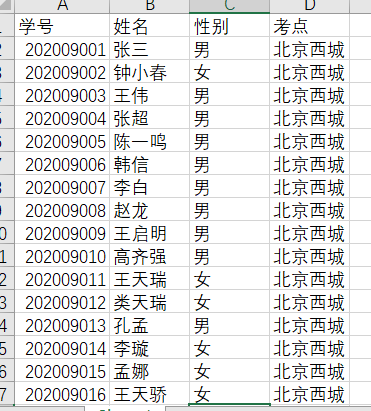
制作成后

pip install pypdf2
pip install pdfplumber
提取文字
#提取单页
import pdfplumber路径 = '../练习文件/文字.pdf'
with pdfplumber.open(路径) as pdf:page = pdf.pages[0] # 第一页text = page.extract_text() #对指定页提取文本file=open('../提取后/1.txt',mode='w',encoding='utf-8')file.write(text)#提取多页
import pdfplumber路径 = '../练习文件/文字.pdf'
with pdfplumber.open(路径) as pdf:# page = pdf.pages[0] # 第一页# text = page.extract_text() #对指定页提取文本# file=open('../提取后/1.txt',mode='w',encoding='utf-8')# file.write(text)for page in pdf.pages:text=page.extract_text()file=open('../提取后/2.txt',mode='a',encoding='utf-8')file.write(text)
提取表格
#提取到csv文件中
import pdfplumber
import pandaspath = '../练习文件/表1.pdf'
with pdfplumber.open(path) as pdf:for page in pdf.pages:for table in page.extract_tables():data = pandas.DataFrame(table[1:], columns=table[0])data.to_csv('../提取后/1.csv', mode='a', encoding='utf-8')#提取到excel中
import pdfplumber
import pandaspath = '../练习文件/表1.pdf'
count = 1
with pdfplumber.open(path) as pdf:with pandas.ExcelWriter('../提取后/1.xlsx') as writer:for page in pdf.pages:for table in page.extract_tables():data = pandas.DataFrame(table[1:], columns=table[0])data.to_excel(writer, sheet_name=f'sheet{count}')count += 1拆分pdf
from PyPDF2 import PdfReader, PdfWriterpath = '../练习文件/表格.pdf'readpdf = PdfReader(path)
for page in range(len(readpdf.pages)): # readpdf.getNumPages()获取读取到的pdf的总页数writerpdf = PdfWriter()writerpdf.add_page(readpdf.pages[page])with open(f'../提取后/{page + 1}.pdf', mode='wb') as f:writerpdf.write(f)合并pdf
from PyPDF2 import PdfReader, PdfWriterwriterpdf = PdfWriter()
for page in range(1, 4):readpdf = PdfReader(f'../提取后/{page}.pdf')for pg in range(len(readpdf.pages)):writerpdf.add_page(readpdf.pages[pg])
with open('../提取后/合并后.pdf', mode='wb') as f:writerpdf.write(f)旋转pdf
from PyPDF2 import PdfReader,PdfWriter
read=PdfReader('../练习文件/表1.pdf')
write=PdfWriter()
# page=read.pages[0].rotate(90) #顺时针
page=read.pages[0].rotate(-90) #逆时针write.add_page(page)with open('../提取后/旋转1.pdf',mode='wb') as f:write.write(f)页码倒序排序
from PyPDF2 import PdfReader, PdfWriterreadppdf = PdfReader('../练习文件/笔记.pdf')
writepdf = PdfWriter()
# 倒序
for page in range(len(readppdf.pages) - 1, -1, -1): # 一共有67页,range(66,-1)就是66到0页writepdf.add_page(readppdf.pages[page])
with open('../提取后/倒序排列.pdf',mode='wb') as f:writepdf.write(f)案例
(1)打开文件"笔记.pdf"
(2)分割奇数页(第1、3、5…页)
(3)倒序保存页面
(4)生成“新.pdf”文件from PyPDF2 import PdfReader, PdfWriter
#分割奇数页
readPdf = PdfReader('../练习文件/笔记.pdf')
for page in range(0, len(readPdf.pages), 2):writePdf = PdfWriter()writePdf.add_page(readPdf.pages[page])with open(f'../提取后/新笔记{page + 1}.pdf', 'wb') as f:writePdf.write(f)
#倒序排版汇总
writePdf = PdfWriter()
for page in range(len(readPdf.pages), 0, -2):readPdf = PdfReader(f'../提取后/新笔记{page}.pdf')for page in range(len(readPdf.pages) - 1, -1, -1):writePdf.add_page(readPdf.pages[page])
with open('../提取后/新.pdf', 'wb') as f:writePdf.write(f)添加水印
from PyPDF2 import PdfReader, PdfWriter
from copy import copyreadwmpdf = PdfReader('../练习文件/水印.pdf')
watermark = readwmpdf.pages[0]
readpdf = PdfReader('../练习文件/笔记.pdf')
writepdf = PdfWriter()for page in range(len(readpdf.pages)):watermark_page=readpdf.pages[page] #要加水印的每一页new_page=copy(watermark)new_page.merge_page(watermark_page) #在文字层的下面添加水印writepdf.add_page(new_page)
with open('../提取后/带水印的笔记.pdf','wb') as f:writepdf.write(f)给pdf文件添加密码
from PyPDF2 import PdfReader, PdfWriterreadpdf = PdfReader('../提取后/带水印的笔记.pdf')
writepdf = PdfWriter()
for page in range(len(readpdf.pages)):writepdf.add_page(readpdf.pages[page])
writepdf.encrypt('1234')
with open('../提取后/加密.pdf', 'wb') as f:writepdf.write(f)解除密码
from PyPDF2 import PdfReader, PdfWriterreadpdf = PdfReader('../提取后/加密.pdf')
readpdf.decrypt('1234')
writepdf = PdfWriter()
for page in range(len(readpdf.pages)):writepdf.add_page(readpdf.pages[page])
with open('../提取后/解密.pdf', 'wb') as f:writepdf.write(f)综合案例
from PyPDF2 import PdfReader, PdfWriter
from copy import copyreadpdf = PdfReader('../练习文件/笔记.pdf')
watermark = PdfReader('../练习文件/水印.pdf').pages[0] # 指定水印在第几页
writepdf = PdfWriter()
for page in range(len(readpdf.pages)):watermark_page = readpdf.pages[page]new_page = copy(watermark)new_page.merge_page(watermark_page)writepdf.add_page(new_page)
writepdf.encrypt('1234')
with open('../提取后/综合案例.pdf','wb') as f:writepdf.write(f)提取图片
# 导入相关库
import fitz
import re
import os# 使用正则表达式查找PDF中的图片
def find_imag(path, img_path): # PDF的路径和图片保存的路径checkXO = r"/Type(?= */XObject)"checkIM = r"/Subtype(?= */Image)"pdf = fitz.open(path)img_count = 0len_XREF = pdf._getXrefLength()print("文件名:{}, 页数: {}, 对象: {}".format(path, len(pdf), len_XREF - 1))for i in range(1, len_XREF):text = pdf._getXrefString(i)isXObject = re.search(checkXO, text)# 使用正则表达式查看是否是图片isImage = re.search(checkIM, text)# 如果不是对象也不是图片,则continueif not isXObject or not isImage:continueimg_count += 1# 根据索引生成图像pix = fitz.Pixmap(pdf, i)new_name = path.replace('\\', '_') + "_img{}.png".format(img_count)new_name = new_name.replace(':', '')# 如果pix.n<5,可以直接存为PNGif pix.n < 5:pix.writePNG(os.path.join(img_path, new_name))else:pix0 = fitz.Pixmap(fitz.csRGB, pix)pix0.writePNG(os.path.join(img_path, new_name))pix0 = Nonepix = Noneprint("提取了{}张图片".format(img_count))if __name__ == '__main__':pdf_path = r'笔记.pdf'img_path = r'图片'if os.path.exists(img_path):print("文件夹已存在,请重新创建新文件夹!")raise SystemExitelse:os.mkdir(img_path)m = find_imag(pdf_path, img_path)#只需要修改 main函数的:#pdf_path = r'笔记.pdf' # pdf的路径#img_path = r'图片' #文件夹的名称
PPT
安装
pip install python-pptx
创建ppt,写入标题与副标题
from pptx import Presentation文件 = Presentation()
样式 = 文件.slide_layouts[0]
幻灯片 = 文件.slides.add_slide(样式)
标题 = 幻灯片.shapes.title
副标题=幻灯片.placeholders[1]
标题.text='学习Python'
副标题.text='Python办公自动化'
文件.save('../保存至/1.pptx')