大模型时代下做科研的四个思路
- 0. 视频来源:
- 1. 提高效率(更快更小)
- 1.1 PEFT介绍(parameter efficient fine tuning)
- 1.2 作者的方法
- 1.3 AIM效果
- 1.3.1AIM 在 K400 数据集上的表现
- 1.3.2AIM 在 Something-Something 数据集、K700 数据集和 Diving-48 数据集上的表现
- 2.调用已训练好的模型做应用
- 3.做即插即用的模块
- 4.构建数据集,做分析为主的文章,写一篇综述论文
0. 视频来源:
李沐读论文:大模型时代下做科研的四个思路
1. 提高效率(更快更小)
1.1 PEFT介绍(parameter efficient fine tuning)
视频理解方面论文:AIM: Adapting Image Models for Efficient Video Action Recognition
之前的工作粗略分为2类:
- 时间和空间分开处理
- 时空一起来做
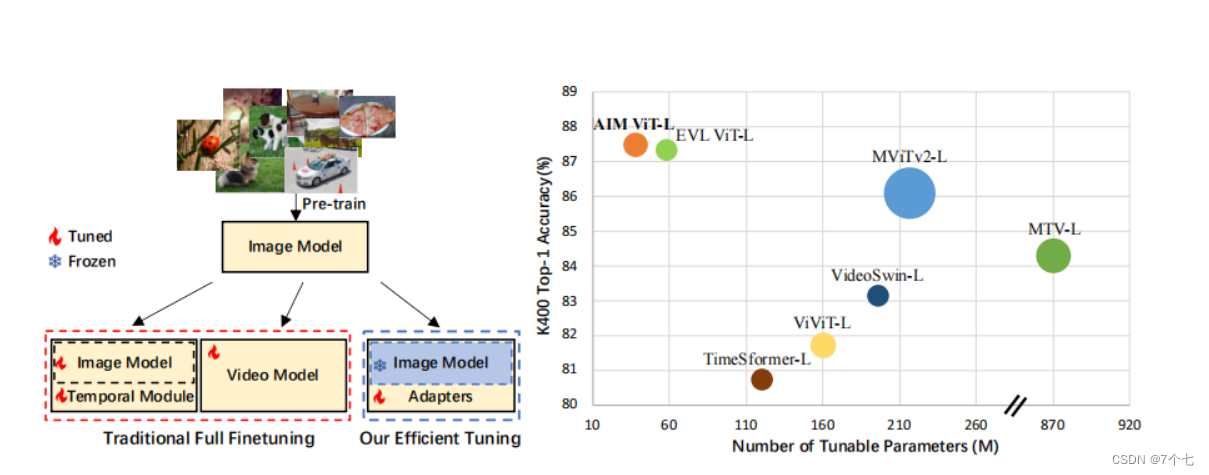
描述:将一个很大的数据集通过预训练得到一个image模型(例如imageNet 1K上训练一个res50的模型)
接下来
- 在已经与训练好的图片模型之上,单独地增加一个时序处理的模块,例如在TSM中将视频截成几段,然后将视频抽出来的特征进行加权平均
- 3D 网络,时间空间特征一起学,例如i3d,Video Swing。输入是3D的,模型也是3D的。
不足之处:
虽然效果很好,但是计算代价实在太大,这些模型都需要 Full Fine Tune,尤其是视频数据集非常大,训练cost太大。
论文动机来自Clip,证明了它自己即使直接 zero-shot 就会很好,而且它也说明了在视频方面的任务上:
- 从有效性方面来说,当有一个极其强大的的预训练好的图像模型后,我们可能不需要 fine-tune 的部分了
- 防止灾难性遗忘,如果有一个大模型,下游没有很好的数据集(或者说没有很多的数据),硬要 finetune 这个大模型的话,往往会做不好。
于是本文拿到一个好的图像模型后,直接把其参数锁住。然后通过修改周边的方式,来让这个模型具备时序建模的能力,来让图像模型能够直接做视频理解任务。
而 PEFT 有两个普遍的方法:
- adapter
论文:Parameter-Efficient Transfer Learning for NLP
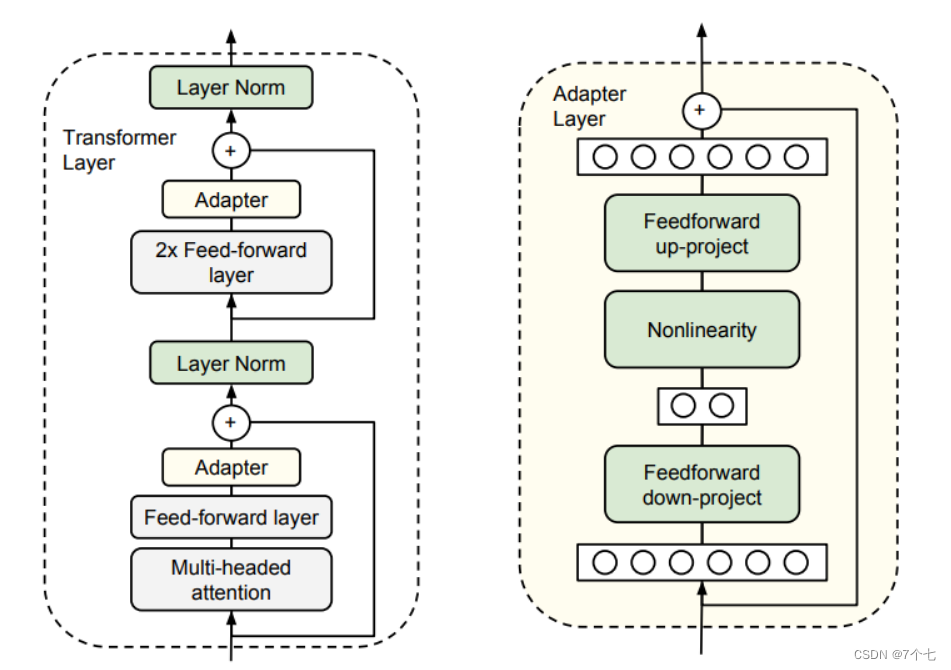
它是把 Adapter 可以随意地插入 TFM block 中,然后锁住原 TFM 的参数,只训练 Adapter。
这样由于 Adapter 相比 TFM 参数量很小,因此不是特别大
- prompt tuning
论文Learning to Prompt for Vision-Language Models
prompt指的是给模型一个提示,让模型去做你想做的事情。例如在CLIP当中,如果想做分类任务,把想要的class都给这个模型
tuning体现在prompt的可学习
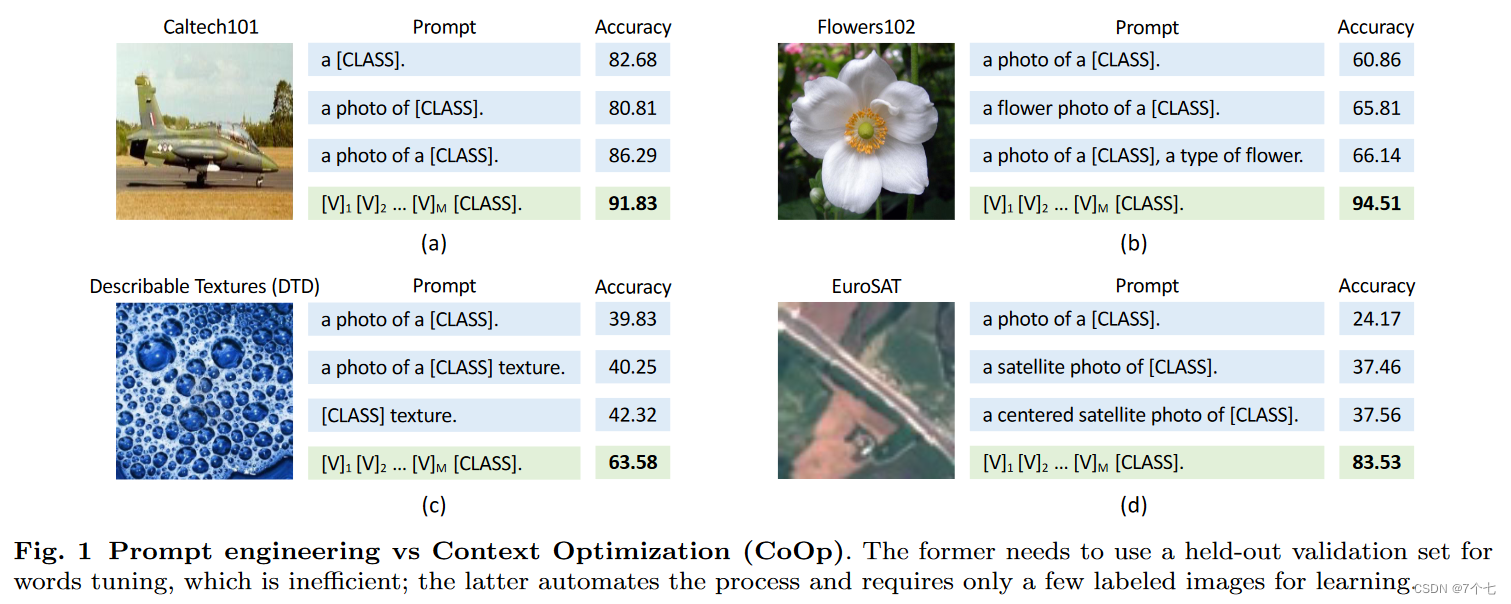
hard prompt(手工 prompt):由于手工写的 prompt 一旦写出来就写死了,这会隐含一个先验知识,可能会对最后的效果产生影响。比如下图中前三个蓝色的部分。
soft prompt:让论文自己学习 prompt,在模型的训练过程中模型的参数锁住不动,只训练prompt。如下图中绿色的部分。
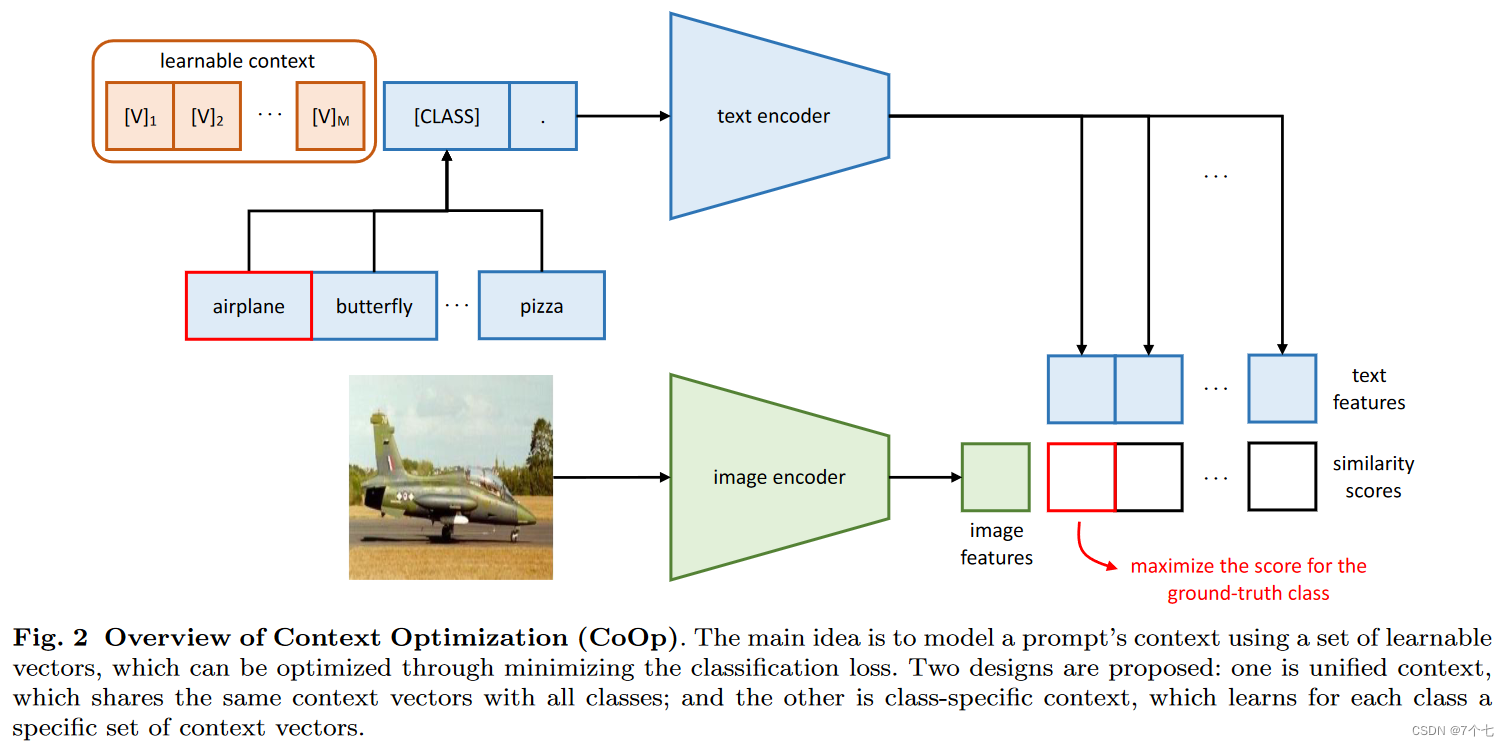
上面是文本的分支,和预测的 [CLASS] 一起进入文本编码器,得到文本的特征。
下面图片进入图片编码器,得到一个图像特征。然后这一个图像特征和文本特征做相似度,看哪个最高选哪个。
这里和 CLIP 的区别在于:prompt 变成了一个可以学习的上下文。
通过这种方式把原来的模型锁住,只学习 prompt,减少计算量。
这里只是对文本进行prompt,那么是否可以用在图像上呢?
也可以,例如论文:Visual Prompt Tuning
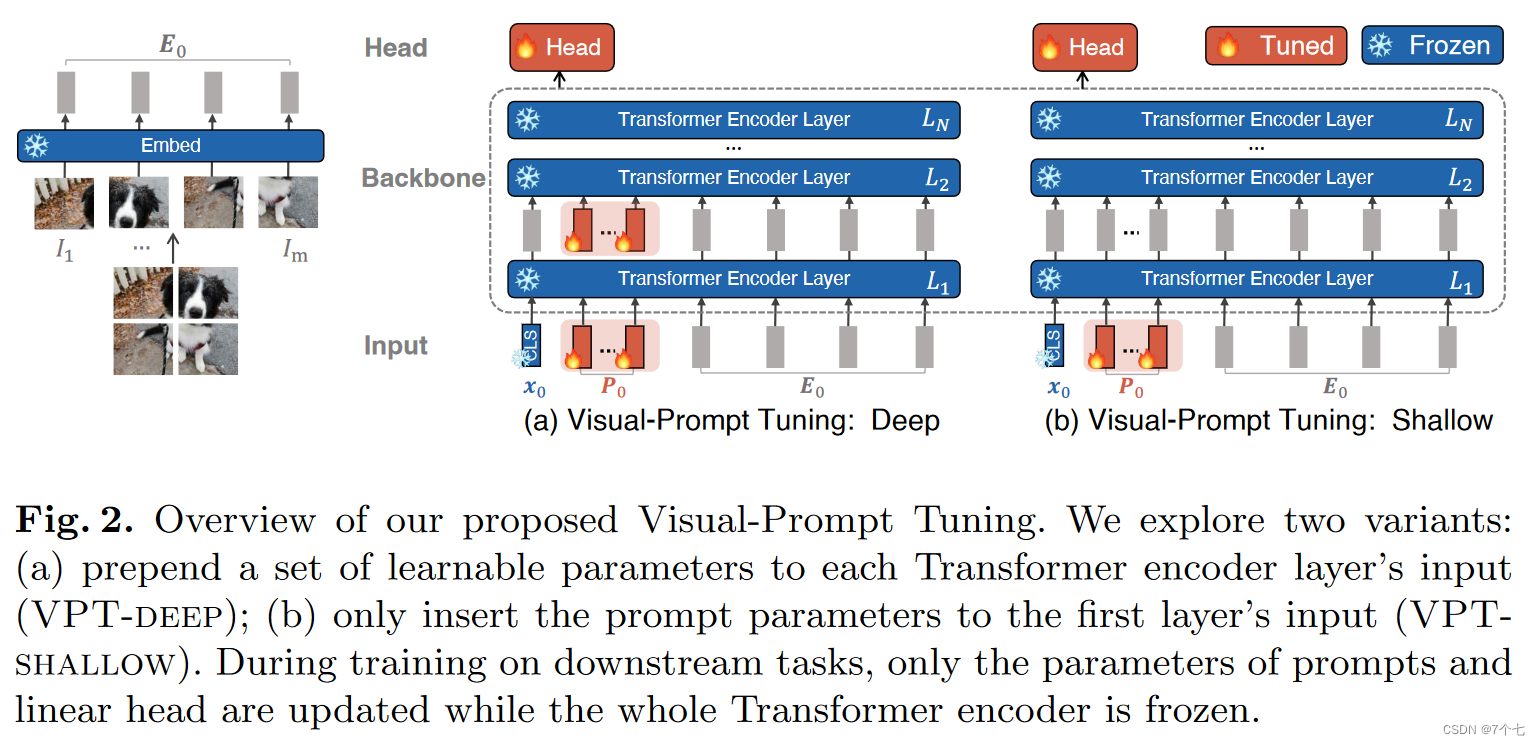
VPT论文提出2种方式:
- VPT Shallow
图片打成 patch 后先通过一些已经训练好并被冻结的层,得到了输入的sequence(E0),把他和可学习的 prompt 一起丢尽模型里,只训练P0 - VPT Deep
看懂了Shallow也就能看懂Deep
小结:PEFT是指当有一个训练好的大模型的时候,我们希望模型是锁住不动的,不光有利于训练还有利于部署,做下游任务的transfer,更重要的是性能不降,甚至反升。正因为非常实用,huggingface专门用来做PEFT的包,可以在github上找到。也有一篇类似综述的论文https://arxiv.org/pdf/2110.04366.pdf
1.2 作者的方法
作者的方法很简单,主要思路就是锁住模型参数,然后往模型里加 Adapter
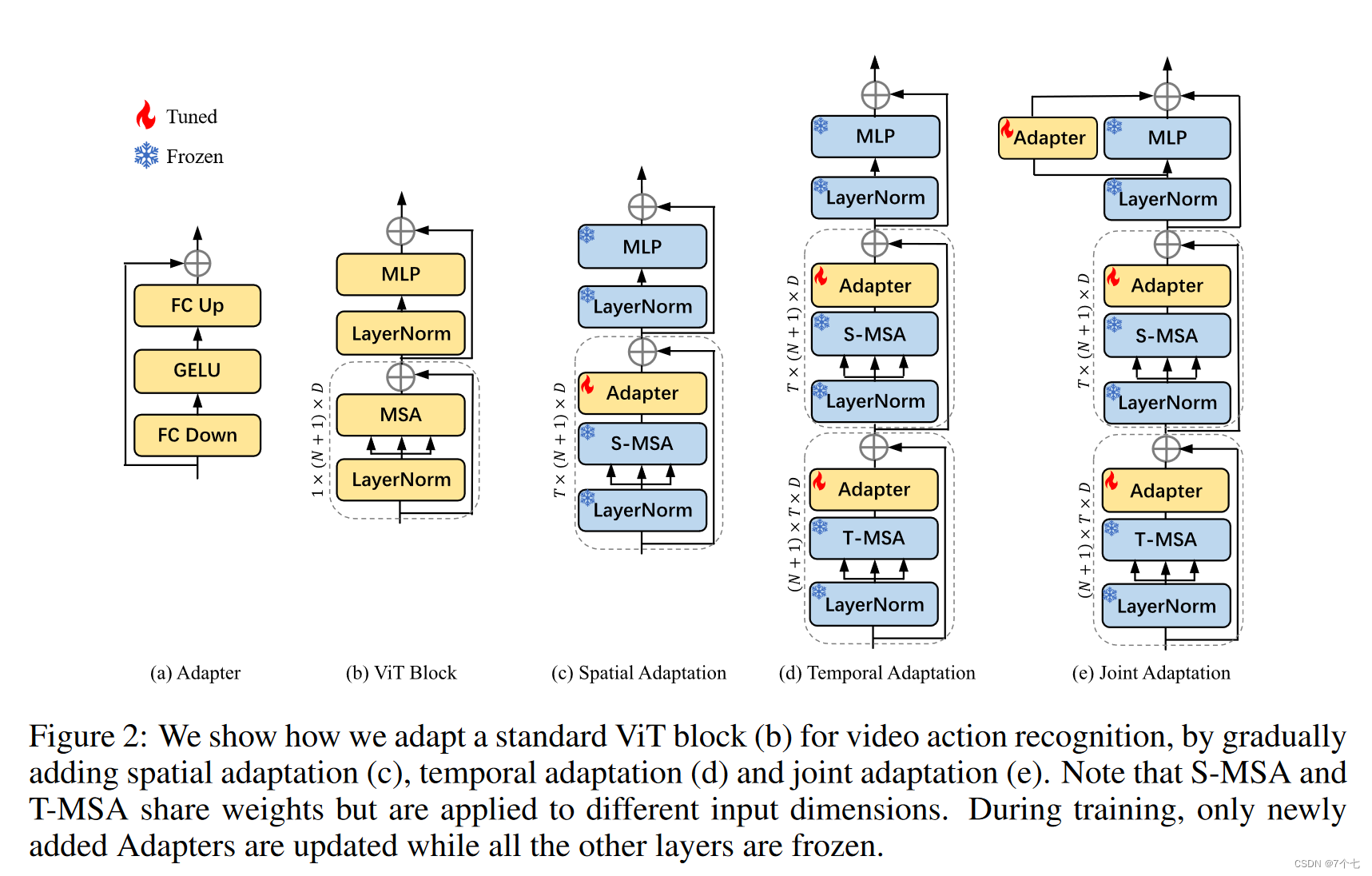
有以下方式进行修改:
- Spatial Adaptation:别的都锁住,只在 Self-Attention 后面加一层 Adapter。
作者认为其意义在于:
不给其添加什么视频理解的能力以及时序建模的能力,只给它加一些可以学习的参数,看看它能不能从图像学习到的特征迁移到视频数据集来,看看能不能解决领域之间有差距的问题。我们也可以对Spatial Adaptation添加时序建模能力,这里的方法五花八。
2.Temporal Adaptation
两个 self-attention 加一个 MLP,两个 attention 参数一样。第一个 T-attention 输入的矩阵先 reshape 一下,维度为 (N+1)×T×D,是在时序这个维度上做自注意力。第二个 S-attention 输入的矩阵再 reshape 回来,维度为 T×(N+1)×D
,在 sequence length 的维度上做自注意力。
我们在 T-attention 后面加了一个 adapter,S-attention 后面也加了一个。确保一个学 spatial 另一个学 temporal 。
3.Joint Adaptation
进一步修改在 MLP 旁边加上了 Adapter,希望三个 Adapter 各司其职,各自学各自该学的,最后这个模型结构其实就是 AIM 了。
1.3 AIM效果
1.3.1AIM 在 K400 数据集上的表现

- Frozen space-only:也是常说的 LinearProbe,整个 backbone 锁住,只去 tune 最后的 head
- Finetuned space-only:正常的模型 Finetune,没有考虑时序信息
- Finetuned space-time:TimesFormer 本身,是一个 Video 的 FullFineTuning 的过程
- Frozen space-only + spatial adaptation:加上了 spatial adaptation 后,可以发现和 Finetuned space-only 差不多,但是训练参数量只有 3.7 M
- Frozen space-only + temporal adaptation:加上 temporal adaptation 后,效果直接翻一倍,甚至比Finetuned space-time的59.5还要高,说明模型的优化在视频理解问题中是非常重要的问题。
- Frozen space-only + joint adaptation adaptation:还能再提升一点点
- AIM:再把预训练模型从 IN-21K 换成 CLIP,于是还有提升
1.3.2AIM 在 Something-Something 数据集、K700 数据集和 Diving-48 数据集上的表现
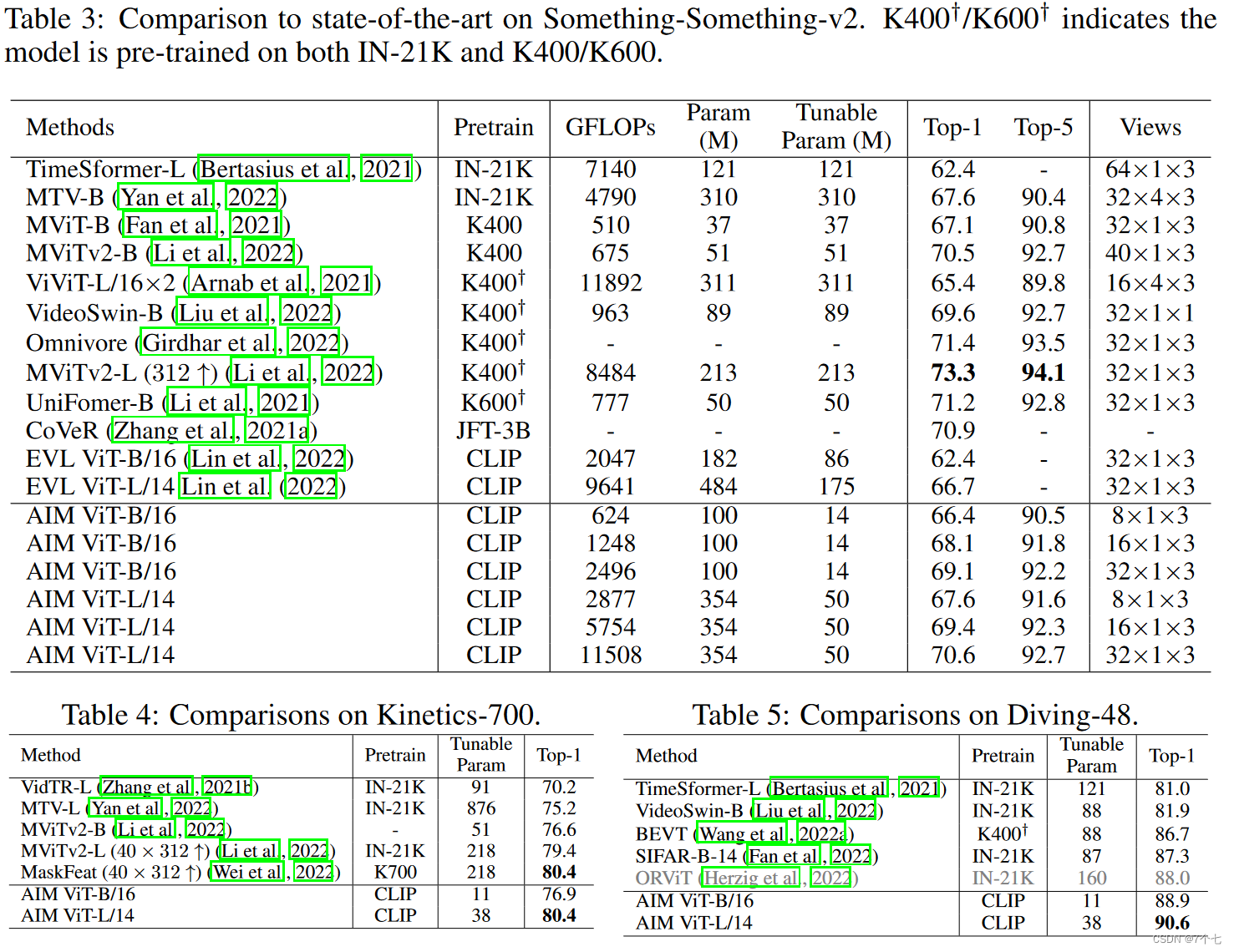
我们可以看到AIM 在K400的数据集上达到87.5Accuracy,可训练参数量显著的低,在Something-Something表现不是最好的,作者给出的解释是可能数据集更加 Temporal Heavy,更注重时序信息,而且很细粒度(把什么东西从左移到右,又把把什么东西从右移到左),这时光是reshape input方式就不太适用,需要一个更强大的时序建模框架
2.调用已训练好的模型做应用
- 直接利用预训练好的模型,不去做预训练,只去做funting,去扩展到各个不同的领域。
- 尽量选新的方法或者新的topic去做,因为这里可能没有成熟的数据集和 Benchmark,因此数据和 Setting 都可以自己选,不用担心比不过别人。例如In-Context Learning:上下文学习,Chain-of-thought prompting:思维链提示,Causal learning:因果学习
下面介绍一个使用自监督的目标中心表示的无监督语义分割的论文
论文:Unsupervised Semantic Segmentation with Self-supervised Object-centric Representations
方向是无监督语义分割方向,具体使用方法是Self-supervised Object-centric Representations,利用已经训练好的DINO网络和DeepUSPS和BASNet网络,这些抽特征的网络都是与训练好的。
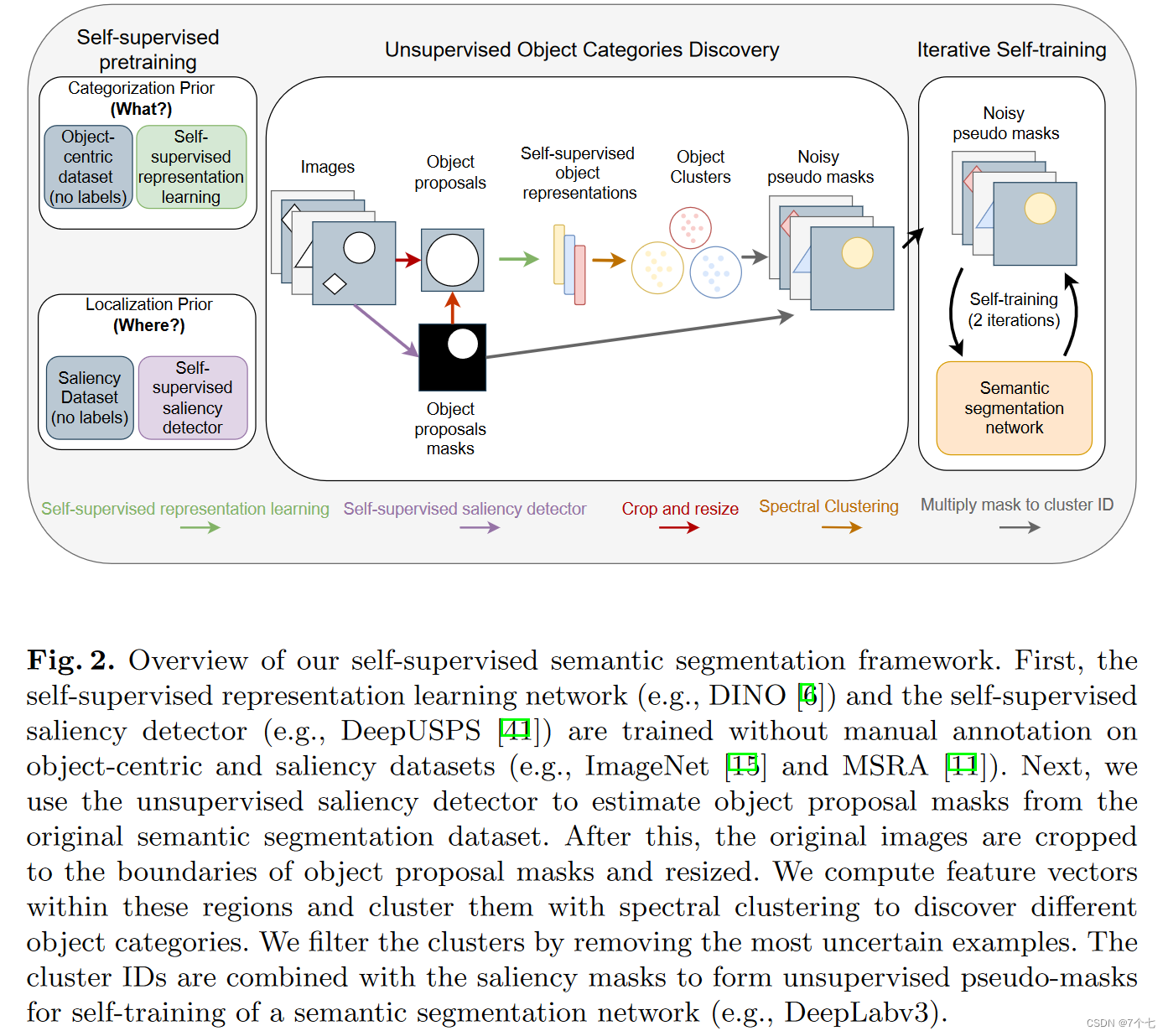
主要流程在于怎么样能让这个模型在无监督的情况下找到新的物体?
很多人认为直接通过一个图片抽一个特征其实不太合理,我们认在看东西的时候会有一个聚焦的人或者物体,再看其交互,预判即将发生什么,如果还能 Unsupervised,会更完美。
如果想学习一个 Segmentation 的网络,那么需要某种程度上的 Mask information。
那么最初始的 Mask information 从哪来?这篇论文借助了之前 Saliency Detection(显著性检测)的工作,直接用了 DeepUSPS ,很多之前无监督 Segmentation 工作用的也是它。
- 给定一张图,给你显著物体的 mask。然后就可以借助这个 mask 把图片中的物体给抠出来。
- 把它抠出来后,resize一下,扔给 DINO 这个网络去抽它的特征Glob-representations。
- 用这些特征然后做聚类(Clustering),然后就能无监督地判断物体是什么 id,暂时还无法确定这些物体是什么,因此这里称作 Noisy pseudo masks,但变相的有了Mask Label,于是可以直接训练一个Semantic Segmentation Network(语义分割)
- 另外一个图片可能有多个物体,所以加一个 self-training,多次轮回。
3.做即插即用的模块
- 这个模块既可以是模型上的一个模块比如Non-Local Modual,在已有的resnet后面加一个Non-Local
- 或者是一个目标函数把loss换成focal loss
- 数据增强的方法,比如Mixup
论文:MixGen: A New Multi-Modal Data Augmentation
作者在研究多模态模型的时候,发现它们都没有使用数据增强。 - 比如 CLIP 只用了基础的数据增强方法 Random Resized Crop,解释是图片文本对已经足够多,所以不需要数据增强
- 在ALBEF 和 BLIP中,虽然用了很好的数据增强,比如 Auto Augment,但是把 Auto Augment里的Color Jittering(对颜色的数据增强:图像亮度、饱和度、对比度变化;彩色变换) 和Random Flip(随机翻转) 去掉了,解释是如果做了这些数据增强,图片的信息会丢失,文本和图片就不一定匹配了。
那么怎么最大程度将原有的信息保留起来?
-
图像:Mixup,将2张图片线性的差值在一起,虽然人眼看起来比较诡异,但是信息没有丢失
-
文本:
-
Mixup
-
Random erasing
-
Random Insertion
-
Back Translation
-
作者的思想是把句子直接拼接在一起
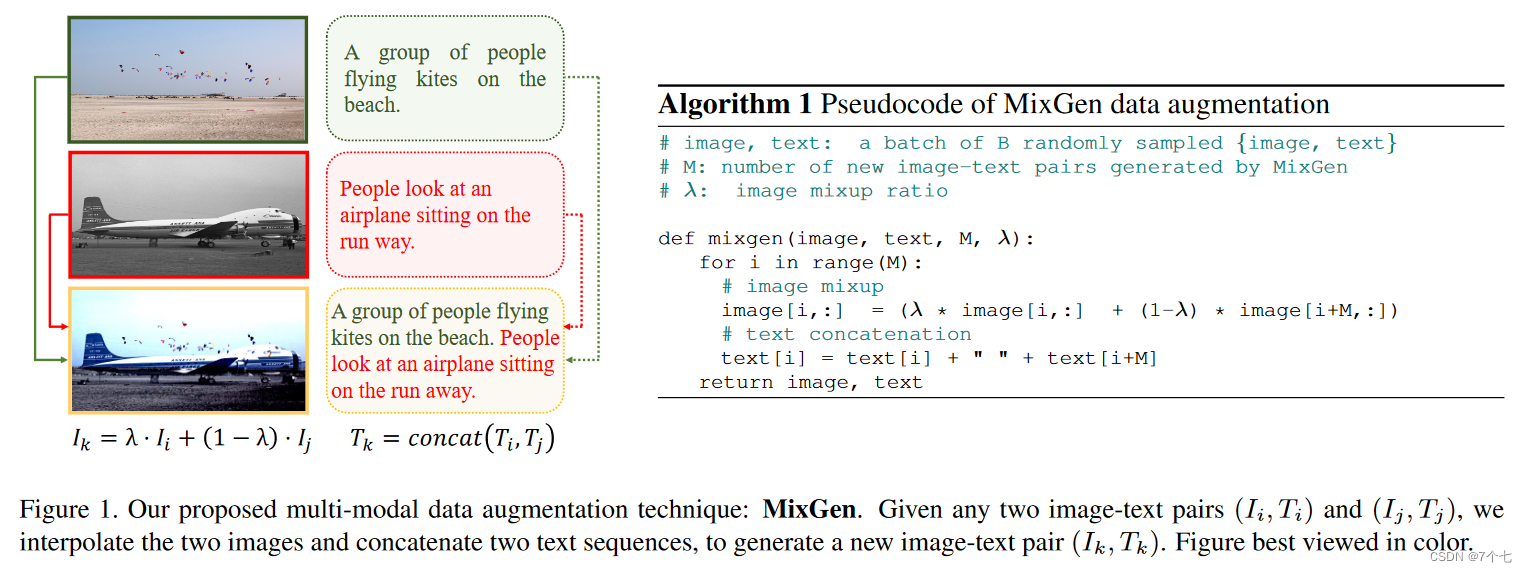
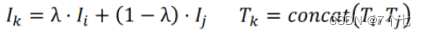
通过上述方式得到一个全新的样本,尽管这样的方式会形成一些很别扭的数据,但从整体信息量来说, 最大程度将之前的信息保留起来了。
下面是效果:
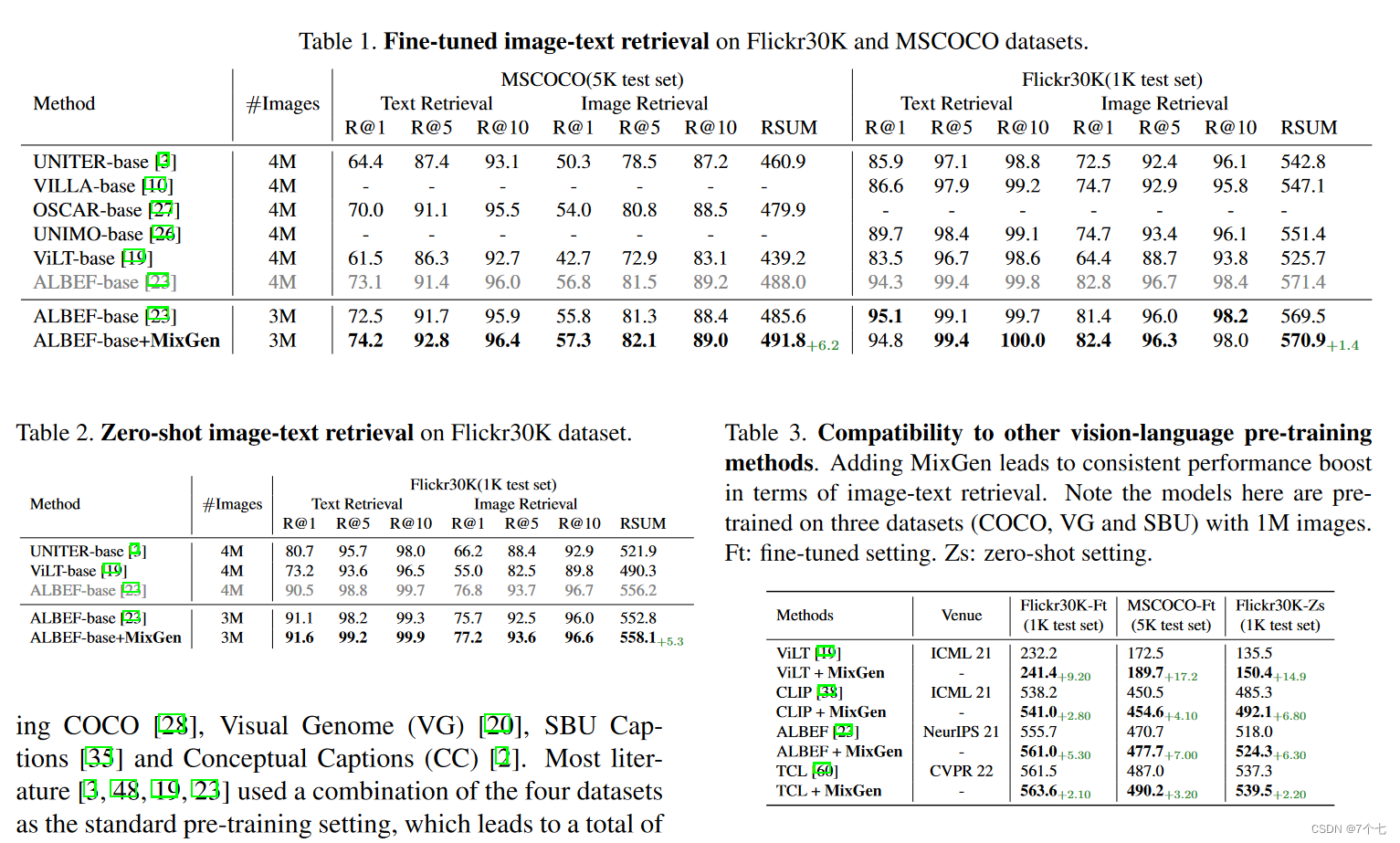
不足之处:
审稿人们觉得这个方法过于简单,一投没过,一个审稿人提出了建设性的意见:数据增强是在没有那么多数据的时候才会去做的选择,但是在多模态的预训练里面,由于已经有大量的数据存在,所以预训练过程没什么用。但是在 Finetuning 过程中,由于下游数据集的数据不多,因此这个方法大概可以应用于 Finetuning 过程中。
4.构建数据集,做分析为主的文章,写一篇综述论文
构建数据集:
论文:BigDetection: A Large-scale Benchmark for Improved Object Detector Pre-training
本论文是把 LVIS,OpenImages 和 Object 365 结合到了一起。这里不是简单的合到一起,而是需要重新分布数据里的类,并且根据任务的需求,决定物体类别有多细粒度。
该数据集有600 类、3.4e6 的训练图片,且有 3.6e7 的目标检测框及注释。
综述论文:
论文:A Comprehensive Study of Deep Video Action Recognition
这是视频动作检测的综述论文,这些论文往往不需要那么多的计算资源,evaluation有时候只要做inference,就算要训练,更多的时候也只需要fine tuning,写这类论文更需要的写作能力,在4个方法中最不需要计算机资源。