文章目录
- ViLT: Vision-and-Language Transformer Without Convolution or Region Supervision
- 一. 简介
- 1.1 摘要
- 1.2 文本编码器,图像编码器,特征交互复杂度分析
- 1.2 特征交互方式分析
- 1.3 图像特征提取分析
- 二. 方法 Vision-and-Language Transformer
- 2.1.方法概述
- 2.2 预训练的目标任务
- Image Text Matching
- Masked Languange Modeling
- Whole Word Masking
- Image Augmentation
- 三. 实验
- 预训练数据集
- 视觉语言下游任务
- 实现细节
- 分类任务: VQAv2 and NLVR2
- 检索任务
- 消融实验
- 复杂度分析
- 可视化分析
ViLT: Vision-and-Language Transformer Without Convolution or Region Supervision
一. 简介
机构:韩国NAVER AILAB
代码:https://github.com/dandelin/vilt
会议: ICML 2021 long paper,截止2023.04,引用量500+
任务: 视觉语言预训练
特点: 快
方法: 视觉特征提取,无卷积,无region监督
1.1 摘要
视觉语言预训练任务已经提升了许多视觉语言下游任务的表现。现有的视觉语言预训练方法往往很依赖图像的特征提取过程,比如区域的监督(像目标检测)以及卷积的结构(像ResNet)。尽管在现有文献中这个问题并没有被重视,但是我们发现它在如下方面会存在问题:(1)效率/速度,单单在提取输入特征就需要比多模态交互步骤多更多计算。(2)表达能力,因为它是视觉潜入器以及其预定义视觉词汇表达能力的上限。在本文中,我们提出了一个更小的VLP模型,视觉语言transformer ViLT。它在处理视觉输入的时候,用到了与处理文本输入相同的无卷积的方式。我们证明ViLT比如以前VLP模型快数十倍,但是在下游的视觉语言下游任务上有与之匹敌的能力。
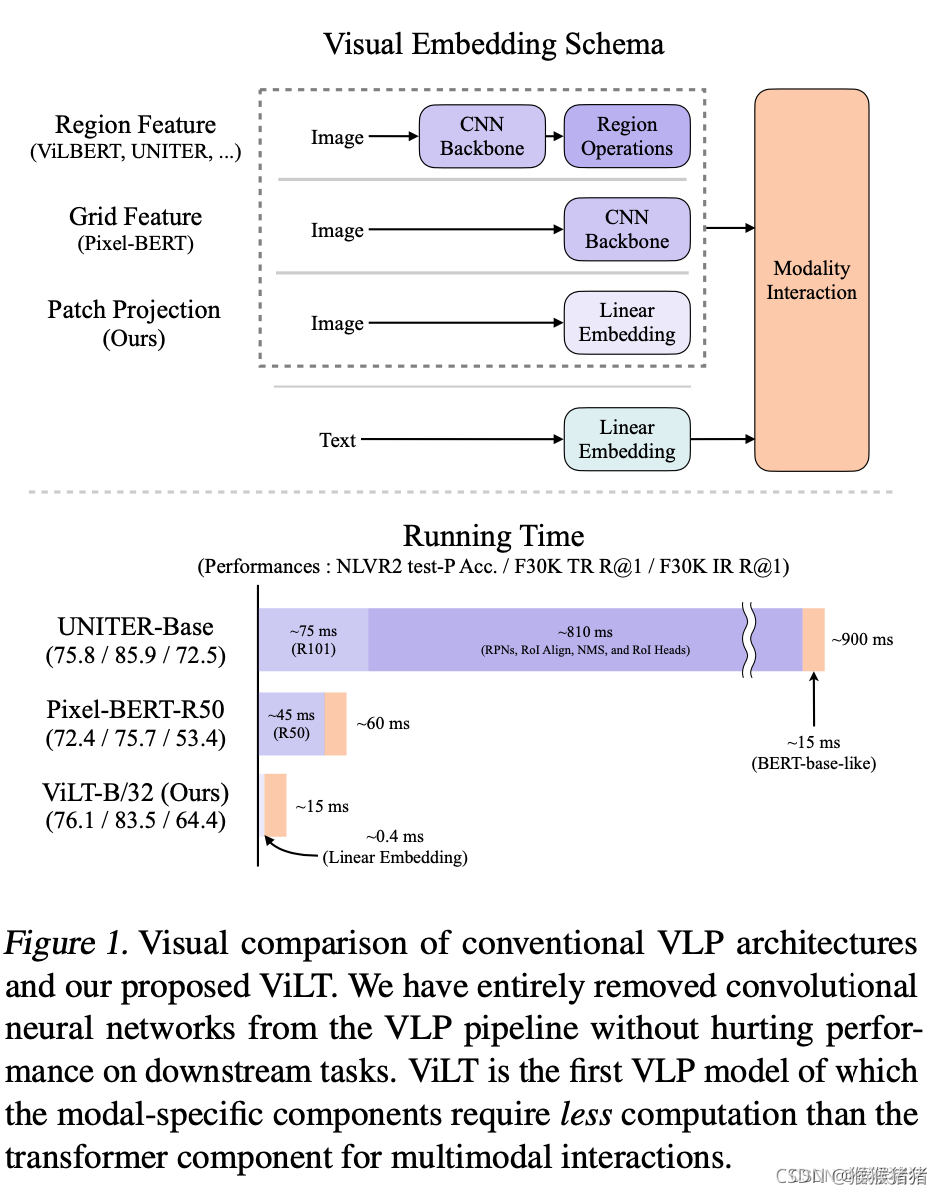
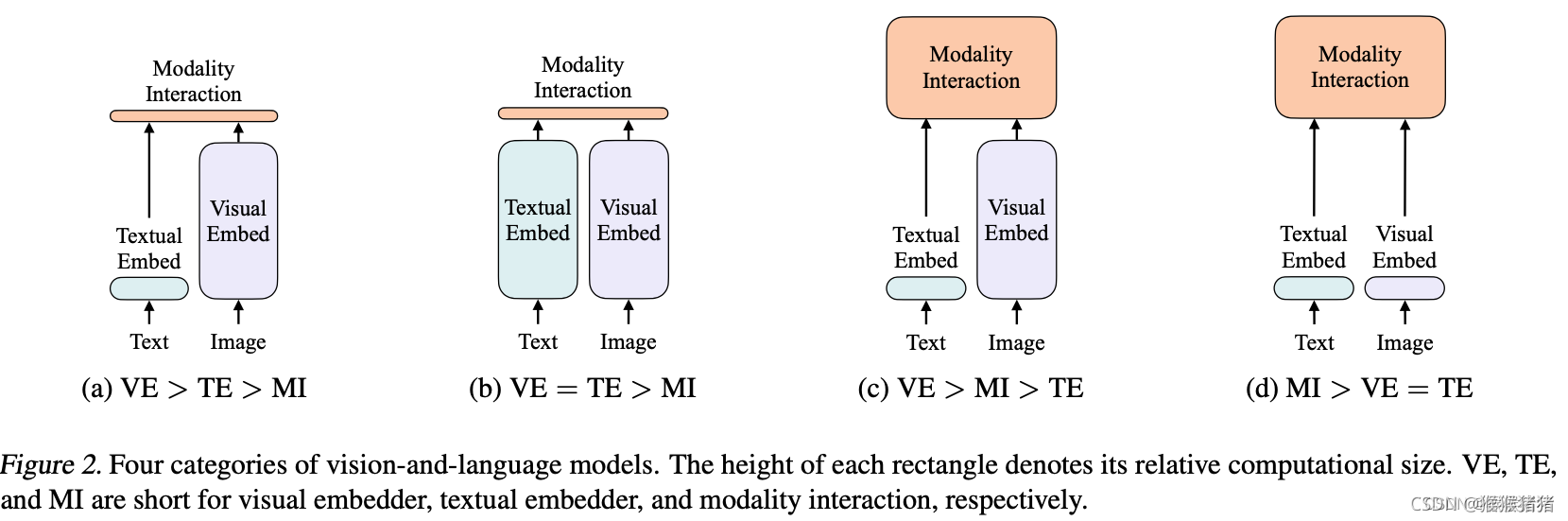
具体摘要所述的内容就如下图所示,突出的就是一个图像单支没有用CNN结构,以及没有用region的信息(可以发现之前的方法,耗时大部分在CNN以及region,即紫色的部分),用简单的linear embedding,就能实现图像的特征抽取,将更多重心关注在modality interaction这一个部分,既保证了效果,又提升了速度。
1.2 文本编码器,图像编码器,特征交互复杂度分析
论文根据visual encoder, text encoder, modality interactioin的复杂度将视觉语言模型的设计分为四种类别:
- VE > TE > MI 文本轻,视觉重,交互轻:像visual semantic embedding (VSE) models,such as VSE++ (Faghri et al., 2017) and SCAN (Lee et al., 2018),用分别的编码器处理图像和文本,但前者会更重一些,最终用简单的点乘或者浅的注意力层来表示提取的两种特征的相似度。
- VE = TE > MI 文本重,视觉重,交互轻:CLIP (Radford et al., 2021) 用分别的但是同样重的transformer编码器来处理两个模态。但是所提特征的交互依旧使用简单的点乘来实现的。尽管CLIP在图文检索上zero shot效果可以,但是在NLVR2任务上MLP表现不佳,因为作者推测,在复杂的图文任务上,仅仅依赖单边模态良好的特征提取能力是不足够的,还需要更好的特征交互。
- VE > MI > TE 文本轻,视觉重,交互重:Pixel-bert更多地考虑了交互的复杂度,但是复杂的视觉编码器依旧比较笨重。
- MI > VE = TE 文本轻,视觉轻,交互重:本文方法,图像文本特征提取的方式都比较shallow,更关注所提取的两种特征的交互。
1.2 特征交互方式分析
对于交互这一块,根据交互的方式(Modality Interaction Schema),一般将方法分为两类:
- single stream: Visual- BERT: (Li et al., 2019), UNITER (Chen et al., 2019),layers collectively operate on a concatenation of image and text inputs。本文的ViLT方法在交互层面上是属于single stream,因为dual stream会引入额外的参数。
- dual-stream: ViLBERT (Lu et al., 2019), LXMERT (Tan & Bansal, 2019),the two modalities are not concatenated at the input level.
1.3 图像特征提取分析
现在表现好的视觉语言预训练模型,往往用的文本编码器都是一样的,即预先训练好的BERT,因此方法间差异比较多的是对视觉的编码,视觉的编码也是先有的视觉语言预训练模型的瓶颈。
根据视觉编码的方式(Visual Embedding Schema),一般也有如下的几种代表性的方式
- Region Feature. 这种特征也被叫做bottom-up features (Anderson et al., 2018). 即用先有的目标检测器来提取region features,因此其性能往往取决于目标检测的几个重要的部分,backbone,NMS,ROI head。一方面比较笨重,另一方面限制了视觉语言的能力。
- Grid Feature. 可以理解为CNN(比如ResNet)输出的 N ∗ N ∗ d N * N * d N∗N∗d特征,其中 N ∗ N N * N N∗N就表示多个格子,虽然比基于region的方式简单,一些方法验证了它的表现,但是从图1还是可以看到,这部分卷积操作,在整个过程当中还是相对比较占据时间的。
- Patch Projection. 类似ViT一样,直接对图像的patch进行映射,本文用的32 * 32 patch projection。仅仅需要2.4M参数,相比于ResNet以及检测的各个part,这个运行的时间几乎可以忽略不计。
二. 方法 Vision-and-Language Transformer
2.1.方法概述
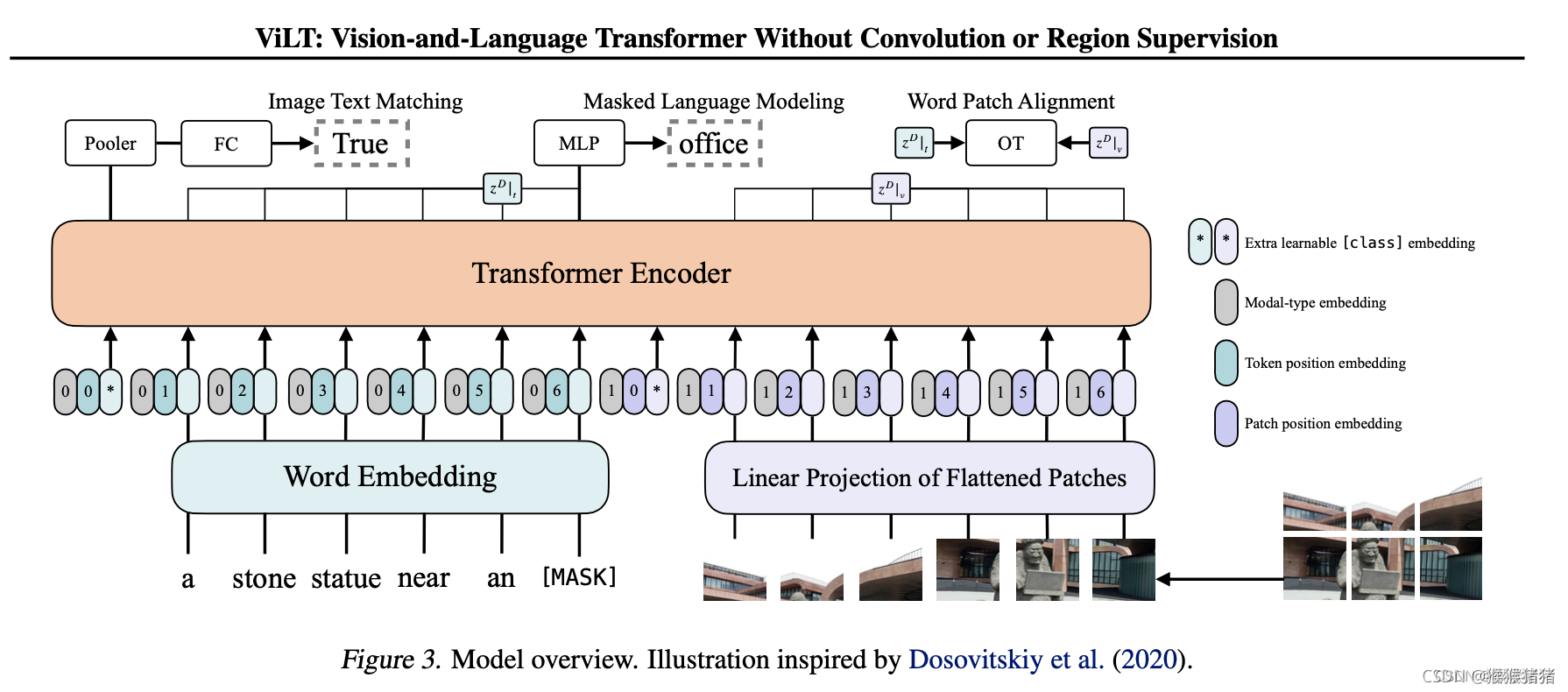
如上文所言,ViLT是一个拥有最小化视觉编码pipeline的VLP模型,融合的策略是single-stream。在融合部分的transformer,用预训练的ViT的参数进行初始化,而不是BERT的参数。这样一种初始化,能够在缺乏一个单独的较深的视觉编码器的情况下,让交互层有足够的能力来处理视觉的特征。(作者在批注里面也提到:尝试用BERT的参数来初始化interaction层,用ViT来初始化patch projection,但是并不work)
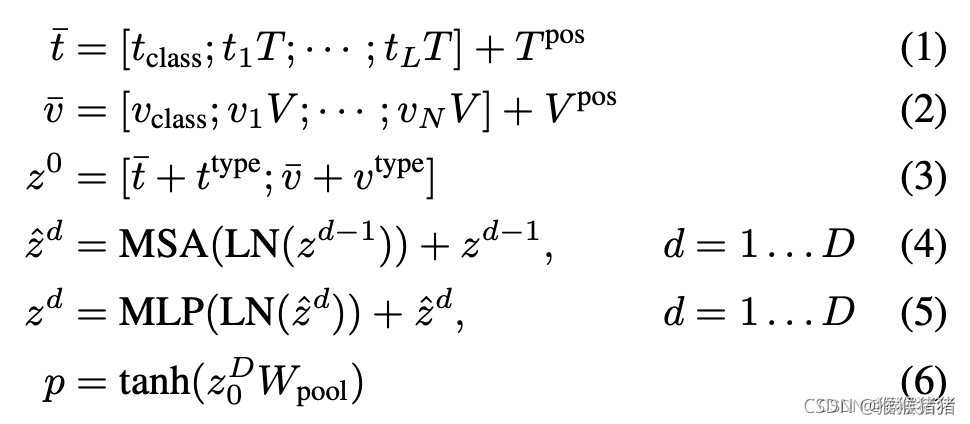
ViT是由stacked blocks组成,每一个block包含多头自注意力层(MSA)以及一个全连接层。ViT与BERT唯一的不同之处在于LN的位置,在BERT中LN的位置在MSA和MLP层之后(也被叫做"post norm"),而在ViT中,其位于两者之前(也被叫做"pre-norm")。
输入的文本 t ∈ R L × ∣ V ∣ t \in \mathbb R^{L \times |V|} t∈RL×∣V∣,被一个词编码矩阵 T ∈ R V × ∣ H ∣ T \in \mathbb R^{V \times |H|} T∈RV×∣H∣ 以及位置编码矩阵 T p o s ∈ R ( L + 1 ) × ∣ H ∣ T^{pos} \in \mathbb R^{(L + 1) \times |H|} Tpos∈R(L+1)×∣H∣编码成一个新的特征 t ‾ ∈ R L × H \overline t \in \mathbb R^{L \times H} t∈RL×H。
输入的图像 I ∈ R C × H × W I \in \mathbb R^{C \times H \times W} I∈RC×H×W被分成多个patches,并被展平为 v ∈ R N × ( P 2 × C ) v \in \mathbb R^{N \times (P^2 \times C)} v∈RN×(P2×C),其中 P × P P \times P P×P是patch的分辨率, N = H W / P 2 N = HW / P^2 N=HW/P2。在经过线性映射 V ∈ R ( P 2 . C ) . H V \in \mathbb R^{(P^2.C).H} V∈R(P2.C).H以及位置编码 V p o s ∈ R ( N + 1 ) × H V^{pos} \in \mathbb R^{(N + 1) \times H} Vpos∈R(N+1)×H之后,被编码为 v ‾ ∈ R N × H \overline v \in \mathbb R^{N \times H} v∈RN×H。
文本和图像的特征会与标示模态的特征 t t y p e , v t y p e ∈ R H t^{type}, v^{type} \in \mathbb R ^H ttype,vtype∈RH相加,然后两者拼接得到一个combined的序列特征 z 0 z^0 z0。这个上下文化的特征 z z z会经过 D D D层的transformer结构,然后得到最终的序列特征 z D z^D zD。 p p p是整个多模态输入的池化特征,具体而言,是对序列 z D z^D zD的第一个位置的特征,过一个线性的映射层 W p o o l ∈ R H × H W_{pool} \in \mathbb R ^{H \times H} Wpool∈RH×H以及tanh激活函数得到。
在公式(1)-(6)中体现了上面所述的全部流程。
在本文中,用的是在ImageNet上预训练好的ViT-B/32的权重,因此名字也叫做ViT-B/32。其中隐藏层的尺寸是768,层深是12,patch size是32,MLP的维度是3072,注意力头的数目是12。
2.2 预训练的目标任务
本文用了两种常用的VLP任务,即图文匹配(ITM)以及掩码语言建模(MLM)。
Image Text Matching
对于成对的图文对,用0.5的概率将图像替换。然后一个ITM head将上面提到的池化特征(可以理解为多模态的全局特征)映射为一个2分类的logits,然后负对数似然来当作ITM的损失函数。
除此之外,受到现有的文献启发,也设计了一个word patch alignment模块(WPA),用于计算两个子集的对齐得分,即textual subset以及visual subset,用的是IPOT方法(inexact proximal point method for optimal transports)。设置IPOT的超参数为( β = 0.5 , N = 50 \beta = 0.5, N = 50 β=0.5,N=50),并且在ITM损失的基础上加了一项:近似的wassersteion距离 * 0.1。
Masked Languange Modeling
这个任务的目标是根据上下文特征 z m a s k e d D ∣ t z^D_{masked} |_t zmaskedD∣t预测gt中被掩码的文本tokens t m a s k e d t_{masked} tmasked,其中掩码的概率是0.15。使用了两层的MLP MLM头来将 z m a s k e d D ∣ t z^D_{masked} |_t zmaskedD∣t映射为vocabulary的logits,然后用负对数似然来计算masked tokens的损失。
Whole Word Masking
whole word masking指的是掩码连续的subword tokens,然后组成一整个单词,在Pre-training with whole word masking for chinese bert.中被证明是有限的。在这儿,作者做的一个假设是,whole word masking在VLP当中是很重要的,如果你想要充分利用另一种模态的信息来预测掩码的单词。在这,它举了一个例子:
对于单词"giraffe"而言,会被分词器(如果是预训练好的bert-base-uncases tokenizer的话)切分为三个word piece的tokens[“gi”, “##raf”,“##fe”],如果不是所有的tokens都被masked的情况下,很容易依赖两个临近的tokens[“gi”, “##fe”]预测出masked的token “##raf”,而不是用来自image的信息来预测。文中也是用0.15的概率来进行 mask the whole words。
Image Augmentation
图像增强往往能够提升视觉模型的泛化性,基于ViT基础上的模型DeiT(Touvron et al., 2020) 也实验了多种增强的方式,发现它们有利于ViT的训练,然而对于VLP模型而言,图像的增强还没有被探索过,本文中用了RandAugment(除了color inversion和cutout,因为文本中可能有颜色的信息,以及cutout可能会切掉一些小但是重要的目标),超参数了N = 2, M =9。
三. 实验
预训练数据集
用了四个数据集MSCOCO, VG, GCC, SBU

视觉语言下游任务
- 分类:VQAV2, NLVR2
- 检索:MSCOCO以及Flickr30
实现细节
| 优化器 | AdamW |
| 初始化学习率 | 1 0 − 4 10^{-4} 10−4 |
| weight decay | 1 0 − 2 10^{-2} 10−2 |
| lr warm up | 前10%的steps warmup,然后后面线性衰减到0 |
值得注意的是,如果对下游的任务定制化超参数,按理效果会更好。
| 图像预处理 | 最短边到384,最长边<= 640,保持长宽比,最多 12 × 20 = 240 12 \times 20 = 240 12×20=240个pacthes,sample 200 patches,padding patches for bacth training, V p o s V^{pos} Vpos差值去匹配图像尺寸 |
| 分词器 | bert-base-uncased |
| BERT | 从头学textual embedding-related parameters t c l a s s t_{class} tclass, T T T, and T p o s T^{pos} Tpos,直接用预训练的BERT参数在VLP任务上可能效果还更差 |
| 训练设置 | 64 V100机器, batch_size 4096,训练步数 100K or 200K,下游任务,batch_size 256 for VQAV2/检索任务,batch_size 128 for NLVR2 |
分类任务: VQAv2 and NLVR2
VQAV2常把它转化为一个anwer集是3129类的分类问题,NLVR2的问题定义是一个二分类问题,但是是一个三元组(image1, image2, question),因此这儿有两张图像,与方法的设置不一样,故将三元组分为两个pair,(question, image1),(question,image2),然后过两遍ViLT,然后把各自的池化特征p相拼接,来进行二分类。
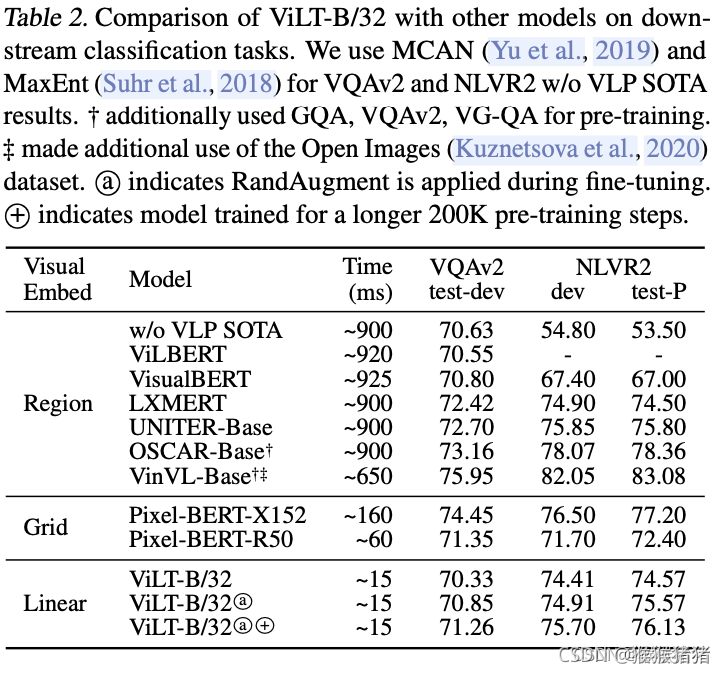
从上表可以看出,在保持精度可比的条件下,速度大大提升,因为VQAv2往往针对object提问,因为基于region的重量视觉编码器的方法略好。从自己的baseline基线对比,可以看出,randaug有轻微提升,更长的预训练步数也有轻微提升。
检索任务
在检索任务上finetune的时候,是采样15个随机的文本当作负例,然后用交叉熵损失最大化正例的得分。
文中报告了zero-shot以及finetuned的结果

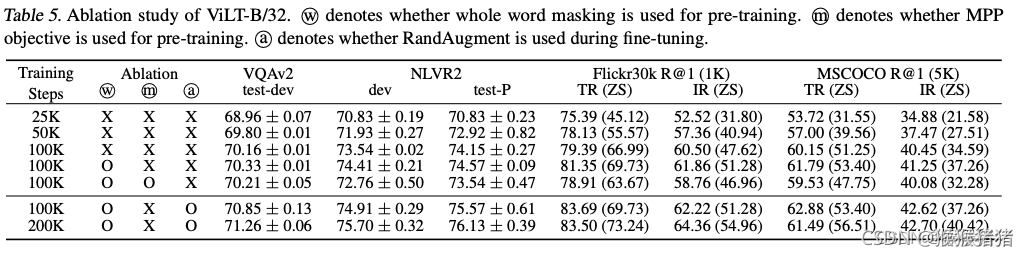
消融实验
- 更长的预训练步数,有益
- finetune做图像增强,有益
- whole word masking,有益
- 引入额外的训练目标:Mask Region Modeling,有弊(The patch v is masked with the probability of
0.15, and the model predicts the mean RGB value of the masked patch from its contextualized vector z m a s k e d D ∣ v z^D_{masked}|_v zmaskedD∣v.)
复杂度分析
注意文中对图像尺寸,以及token数量的讨论

可视化分析

文末对scalability,masked modeling for visual inputs和增强策略,做了一下future work的展望。