文章目录
- 1. 自定义数据集
- 1.0 整理数据集为特定格式
- 1.1 持久化运行(用文件定义)
- 1.2 运行时生效(直接运行时定义一个class)
- 1.3 注意事项
- 2. 配置文件
- 3. 运行训练和测试
- X. 其他语义分割数据集
视频链接:MMSegmentation代码课
教程链接:MMSegmentation_Tutorials/20230612
1. 自定义数据集
参考文档:https://mmsegmentation.readthedocs.io/en/main/advanced_guides/add_datasets.html
1.0 整理数据集为特定格式
── data
│ ├── my_dataset
│ │ ├── img_dir # 这个名字最好也改成一样的,因为config里data_root那些也用的是这个
│ │ │ ├── train
│ │ │ │ ├── xxx{img_suffix}
│ │ │ │ ├── yyy{img_suffix}
│ │ │ │ ├── zzz{img_suffix}
│ │ │ ├── val
│ │ ├── ann_dir
│ │ │ ├── train
│ │ │ │ ├── xxx{seg_map_suffix}
│ │ │ │ ├── yyy{seg_map_suffix}
│ │ │ │ ├── zzz{seg_map_suffix}
│ │ │ ├── val
1.1 持久化运行(用文件定义)
主要对两个文件进行操作:
- 自定义一个数据集类,比如要对西瓜进行语义分割,则可以创建一个
watermelon.py类,要放在mmsegmentation/mmseg/datasets/watermelon.py,里面要实现一个WatermelonDataset(BaseSegDataset)类,继承mmcv里的默认base数据集类 - 对
mmsegmentation/mmseg/datasets/__init__.py进行修改,把刚刚定义的那个WatermelonDataset索引到这里面 - 保证把这两个文件放到对应的位置,
- 如果是在本地等比较方便的地方操作,可以直接文件管理器操作;
- 如果是jupyter环境等不太方便可视化操作的远程环境,可以
# 使用三组双引号,就是保留这个字符串里所有格式(包括回车),所以三组双引号里的内容会被原样写入文件中watermelon = """ watermelon.py文件里的内容 """watermelon_save_path = "/content/mmsegmentation/mmseg/datasets/watermelon.py"with open(watermelon_save_path,'w') as f:f.write(watermelon) # 同理,__init__文件也是initModified=""" __init__.py文件里的内容 """init_path = "/content/mmsegmentation/mmseg/datasets/__init__.py" with open(init_path,'w') as f:f.write(initModified)
"""
文件内容举例,西瓜语义分割,
红色:瓜瓤;绿色:瓜皮;白色:里面的靠近瓜皮的那些白瓤;白色种子;黑色种子;tabBlue(除西瓜之外的背景部分),是unlabeled的
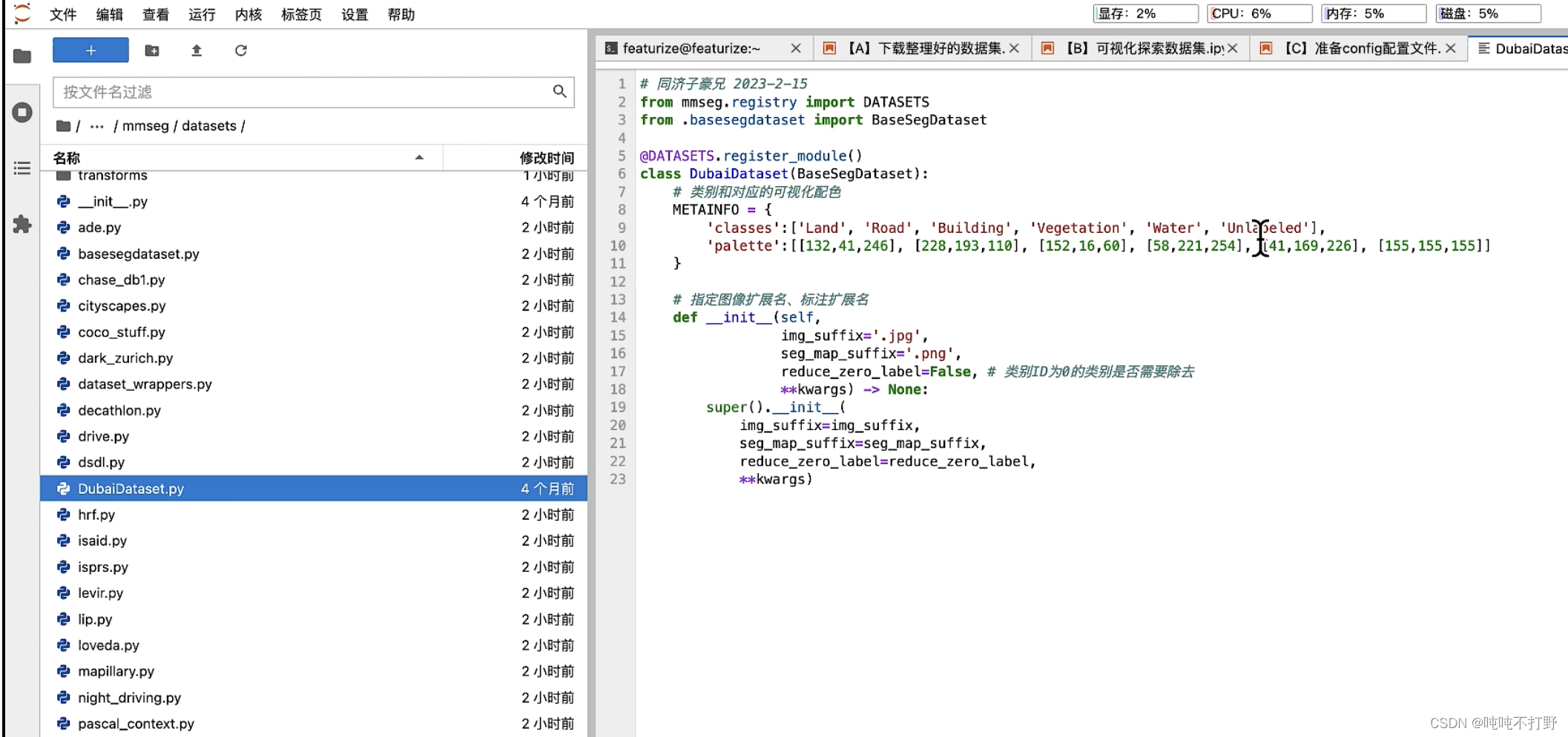
"""<!----mmsegmentation/mmseg/datasets/watermelon.py------>from .basesegdataset import BaseSegDataset
from mmseg.registry import DATASETS
@DATASETS.register_module()
class WatermelonDataset(BaseSegDataset):METAINFO = dict(# 注意,unlabeled放最后classes=('red', 'green', 'white','seed-black', 'seed-white', 'tabBlue'),# 颜色是RGB顺序的palette=[[214, 39, 40], [44, 160, 44], [255, 255, 255],[0, 0, 0], [255, 255, 255], [31, 119, 180]])def __init__(self,img_suffix='.jpg', # 图像的后缀seg_map_suffix='.png', # mask语义分割标签的后缀reduce_zero_label=False, # 是否要移除ID为0的标签**kwargs) -> None:super().__init__(img_suffix=img_suffix,seg_map_suffix=seg_map_suffix,reduce_zero_label=reduce_zero_label,**kwargs)<!-------mmsegmentation/mmseg/datasets/__init__.py>
# 添加import
from .watermelon import WatermelonDataset
# 把WatermelonDataset加到__all__数组的最后
__all__ = ['BaseSegDataset', 'BioMedical3DRandomCrop', 'BioMedical3DRandomFlip','CityscapesDataset', 'PascalVOCDataset', 'ADE20KDataset','PascalContextDataset', 'PascalContextDataset59', 'ChaseDB1Dataset','DRIVEDataset', 'HRFDataset', 'STAREDataset', 'DarkZurichDataset','NightDrivingDataset', 'COCOStuffDataset', 'LoveDADataset','MultiImageMixDataset', 'iSAIDDataset', 'ISPRSDataset', 'PotsdamDataset','LoadAnnotations', 'RandomCrop', 'SegRescale', 'PhotoMetricDistortion','RandomRotate', 'AdjustGamma', 'CLAHE', 'Rerange', 'RGB2Gray','RandomCutOut', 'RandomMosaic', 'PackSegInputs', 'ResizeToMultiple','LoadImageFromNDArray', 'LoadBiomedicalImageFromFile','LoadBiomedicalAnnotation', 'LoadBiomedicalData', 'GenerateEdge','DecathlonDataset', 'LIPDataset', 'ResizeShortestEdge','BioMedicalGaussianNoise', 'BioMedicalGaussianBlur','BioMedicalRandomGamma', 'BioMedical3DPad', 'RandomRotFlip','SynapseDataset', 'REFUGEDataset', 'MapillaryDataset_v1','MapillaryDataset_v2', 'WatermelonDataset'
]例如:
也可以直接去这里看:
https://github.com/open-mmlab/mmsegmentation/blob/main/mmseg/datasets/cityscapes.py
,这个文件夹中所有支持的数据集都是以上面类似的格式定义的。
注意:
- 这里虽然也是
METAINFO,和之前MMPretrain里属性名称一样,但是MMPretrain只需要在py文件里写上这个属性,不需要额外定义一个数据集类,是因为其提供了一个自定义数据集类。 - 而MMSegmentation需要自己提供数据集类,两个库并不一样。MMPretrain是针对分类任务的,MMSegmentation是语义分割任务
1.2 运行时生效(直接运行时定义一个class)
直接在代码中运行以下内容:
# 只有第一行引用的时候变了
from mmseg.datasets.basesegdataset import BaseSegDataset
from mmseg.registry import DATASETS@DATASETS.register_module()
class WatermelonDataset(BaseSegDataset):METAINFO = dict(classes=('red', 'green', 'white','seed-black', 'seed-white','tabBlue'),palette=[[214, 39, 40], [44, 160, 44], [255, 255, 255],[0, 0, 0],[255, 255, 255],[31, 119, 180],])def __init__(self,img_suffix='.jpg',seg_map_suffix='.png',reduce_zero_label=False,**kwargs) -> None:super().__init__(img_suffix=img_suffix,seg_map_suffix=seg_map_suffix,reduce_zero_label=reduce_zero_label,**kwargs)
1.3 注意事项
①记得用的时候要注册:
from mmengine.runner import Runner
from mmseg.utils import register_all_modules# register all modules in mmseg into the registries
# do not init the default scope here because it will be init in the runner
register_all_modules(init_default_scope=False)
②确认环境:
一般认为有两种安装方式,git源码安装,pip/mim安装
git clone https://github.com/open-mmlab/mmsegmentation.git -b dev-1.x
cd mmsegmentation && pip install -v -e .pip install "mmsegmentation>=1.0.0"
由于会对具体文件进行操作,所以其实建议走git源码安装,如果运行报错这个数据类没有注册,考虑一下自己现在运行的是git源码安装的环境,还是pip/mim安装的环境
2. 配置文件
一般都是基于预训练模型对应的配置文件进行修改
from mmengine import Config
raw_config_path ="/content/mmsegmentation/configs/pspnet/pspnet_r18-d8_4xb4-80k_potsdam-512x512.py"
cfg = Config.fromfile(raw_config_path)
①可以利用代码进行修改
cfg.train_dataloader.dataset.type='WatermelonDataset'
cfg.val_dataloader.dataset.type='WatermelonDataset'
cfg.test_dataloader.dataset.type='WatermelonDataset'cfg.train_dataloader.dataset.data_root='/content/Watermelon87_Semantic_Seg_Mask'
cfg.val_dataloader.dataset.data_root='/content/Watermelon87_Semantic_Seg_Mask'
cfg.test_dataloader.dataset.data_root='/content/Watermelon87_Semantic_Seg_Mask'cfg.test_dataloader = cfg.val_dataloader
②保存成文件再修改
- 由于MMengine的config都是继承的,所以上面原始的config文件里都是引用其它文件的内容,想要查看完整的配置,可以
from mmengine import Config
# 查看完整的配置文件(包括继承的)
print(cfg.pretty_text)config_file_path = '/content/drive/MyDrive/OpenMMLab/Exercise_4/pspnet-watermelon_20230618.py'
cfg.dump(config_file_path)
- 然后直接在保存的有完整配置的那个py文件里进行修改
3. 运行训练和测试
可以用脚本模式,也可以用提供的API
可以
# 使用脚本命令行,看起来要稍微复杂一点
# 测试精度评估
!python /content/mmsegmentation/tools/test.py \
/content/drive/MyDrive/OpenMMLab/Exercise_4/pspnet-watermelon_20230618.py\
/content/drive/MyDrive/OpenMMLab/workdir/PSPNet/iter_1000.pth\
--work-dir /content/drive/MyDrive/OpenMMLab/workdir/PSPNet# 测试速度评估
!python /content/mmsegmentation/tools/analysis_tools/benchmark.py \
/content/drive/MyDrive/OpenMMLab/Exercise_4/pspnet-watermelon_20230618.py\
/content/drive/MyDrive/OpenMMLab/workdir/PSPNet/iter_1000.pth\
--work-dir /content/drive/MyDrive/OpenMMLab/workdir/PSPNet
也可以
from mmengine import Configconfig_file_path = '/content/drive/MyDrive/OpenMMLab/Exercise_4/pspnet-watermelon_20230618.py'
cfg = Config.fromfile(config_file_path)from mmengine.runner import Runner
from mmseg.utils import register_all_modules
register_all_modules(init_default_scope=False)
runner = Runner.from_cfg(cfg)
# 这步其实就会打印出配置信息,创建work_dirs文件夹了,
# 同时这步就会把数据文件路径那些读进来,所以如果数据有问题,就要从这步重新开始执行runner.train() # 训练
runner.test() # 直接使用上面runner的训练结果权重进行test,config也是同一个
X. 其他语义分割数据集
- kaggle:Glomeruli (HuBMAP external) 1024x1024-小鼠肾小球组织病理切片语义分割
- kaggle:Semantic segmentation of aerial imagery-迪拜卫星航拍多类别语义分割
- 所以kaggle不仅有竞赛,也有没有竞赛的单纯的数据集。。。
![即时通讯技术文集(第17期):社交软件红包技术专题 [共12篇]](/images/no-images.jpg)