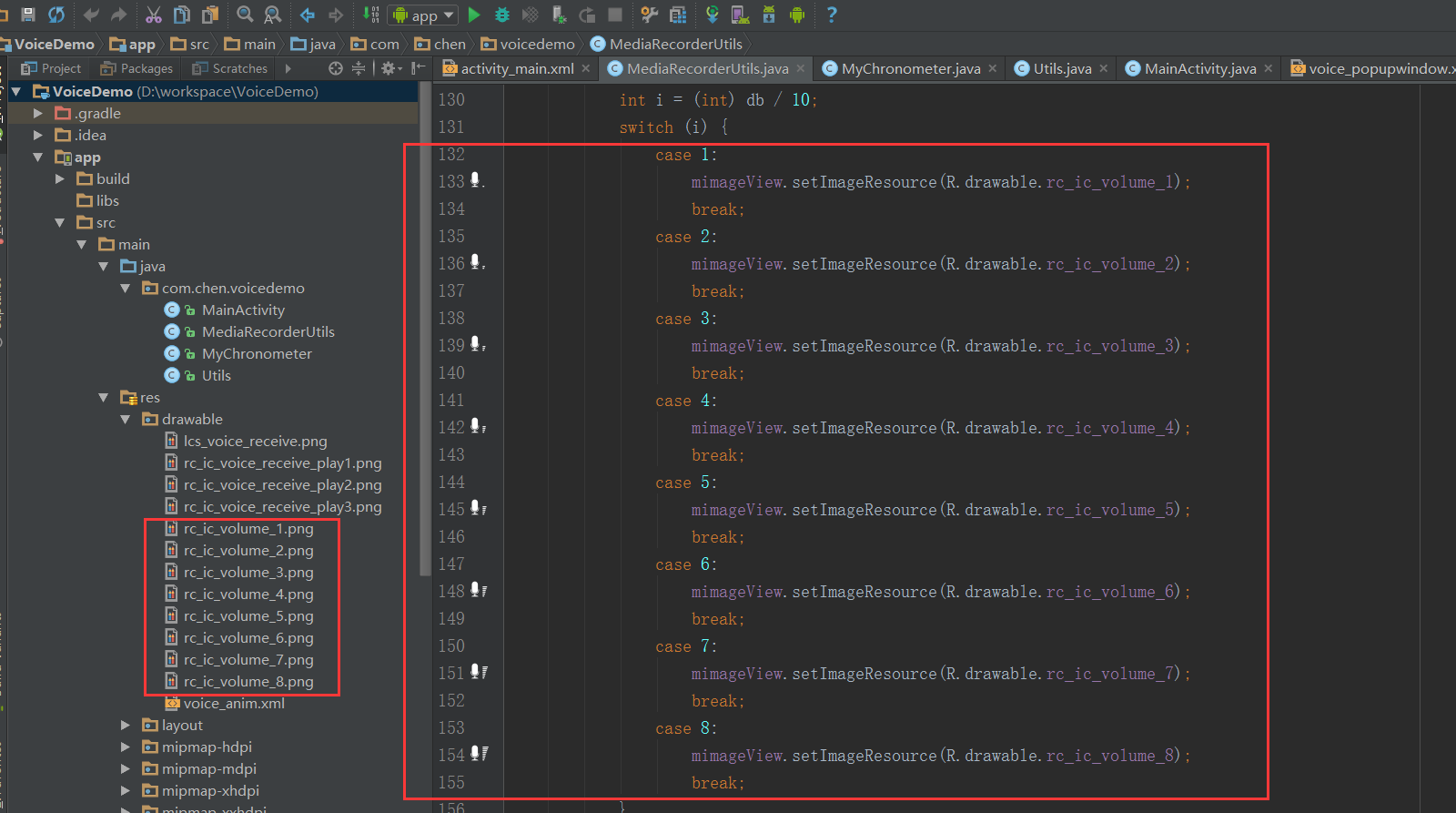
import numpy as np
from matplotlib import pyplot as plt
import pyaudio
import waveCHUNK=1024 #每个缓冲区的帧数
FORMAT = pyaudio.paInt16 #采样位数
fs = 16000
duration=2
channels = 1
n = duration * fs
t = np.arange(1,n) / fs
wave_output_file = 'record.wav'
print('这段音频有几秒:',duration)p = pyaudio.PyAudio()
stream = p.open(format=FORMAT,channels=channels,rate=fs,input=True,frames_per_buffer=CHUNK)
print('开始录制:')frames = []
for i in range(0,int(fs/CHUNK*duration)):data = stream.read(CHUNK)frames.append(data)print('录制结束')
stream.stop_stream()
stream.close()
p.terminate()wf = wave.open(wave_output_file,'wb') # 打开这个文件,以二进制写入的方式
wf.setnchannels(channels) #设置单声道
wf.setsampwidth(p.get_sample_size(FORMAT)) #设置采样位宽
wf.setframerate(fs) #设置采样率
wf.writeframes(b''.join(frames)) # 把所有的帧连成一段语音
wf.close()用上面这段是可以录制音频的,我运行代码,是没有问题的。但是由于我是在linux的服务器上运行的,服务器貌似没有声卡这个设备,所以录制不上去,会有输出文件,但是文件的频谱什么都没有。正常的笔记本在本地都配备声卡,我懒得再换了,换了还需要安装一堆包什么的。

这个是录制出来的音频文件,但是频谱是什么都没有,因为没有声卡,声音录制不上去。
拿Adobe看了一下,空空如也。

在服务器上用命令查了一下声卡设备和输出设备等等,什么都没有,应该是真的没有声卡设备。
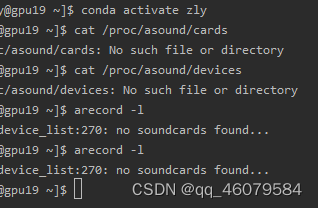
参照这篇博客看的
(1条消息) Linux 下查看麦克风或音频采集设备_唐传林的博客-CSDN博客_linux查看音频设备

![[2021.12.5]使用MediaRecorder录制音频和视频(Camera1)](/images/no-images.jpg)