https://arxiv.org/pdf/0903.2693.pdf
这篇是论文的翻译加个人理解,就其中有些问题邮件询问了Kang Ning老师,得到的回复就是——Will update shortly。所以对计算机网络安全和DNA密码学感兴趣的或者对这篇文章有疑虑的但没有在这弄明白的筒子们可以关注一下此文短期内的更新。
DNA密码学是密码学研究中一个非常有前途的新方向。DNA可以在密码学中用于存储和传输信息,也可以用于计算。DNA密码学虽然处于原始阶段,但已被证明是非常有效的。目前,针对密码学、密码分析和隐写术中存在的一些问题,提出了几种DNA计算算法,它们在这些领域具有很强的应用前景。然而,使用DNA作为密码学的手段有很高的实验室技术要求和计算限制,以及目前的劳动密集型外推方法(the labor intensive extrapolation means,大概是需要有强度的人力来实施的意思)。这些使得DNA密码学在当今安全领域的有效使用变得困难。因此,在实际应用前需要进行更多的理论分析。
在这个项目中,不使用真正的DNA来执行加密过程;而是介绍一种新的基于分子生物学中心法则的密码学方法。该方法模拟了中心法则中的一些关键过程,是一种伪DNA密码方法。理论分析和实验表明,该方法在计算、存储和传输方面具有较高的效率;它对某些攻击非常强大。因此,这种方法可以在密码学中有许多用途,比如增强安全性和速度。该方法也有扩展和变化,增强了安全性、有效性和适用性。
刚看到这篇文章很奇怪DNA这种生物化学领域的东西怎么和网络安全中的密码学结合起来。因为密码学中公钥密钥的知识背景,就联想到化学反应中酶的反应。高中生物中,酶促反应中酶只作用于特定结构的底物,生成一种特定结构的产物。
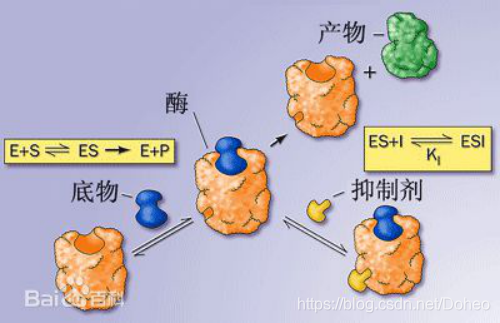
这种机制有点像公钥和密钥的角色。开个脑洞,DNA的生物学反应可以用于密码学,1981年发现的人类视觉机制也成功用于卷积神经网络的创建,那各种酶的(非)特异性反应是否也可以用于密码学,或者其他虚拟仿生技术呢?
介绍
随着一些现代密码学算法(如DES和最近的MD5)被击破,人们正在寻求信息安全的新方向来保护数据。在密码学和隐写术领域使用DNA计算的概念是一种可能的技术,它可能为强大的、甚至不可破解的算法带来新的希望。
Adleman的开创性工作[Adleman, 1994]为生物计算研究的新领域奠定了基础。他的主要想法是用实际的化学来解决传统计算机无法解决或者需要大量的计算的问题。通过DNA计算,可以打破数据加密标准(DES)的加密协议[Boneh, et. al, 1995]。DNA链一次一密密码学和DNA隐写术(在DNA中隐藏信息)的研究见[Gehani, et. al, 2000]。
然而,DNA密码学的研究人员仍然更多地着眼于理论而非实际。其受实验室高技术要求和计算限制的限制,结合劳动密集型外推手段。因此,阻止DNA计算在当今安全世界的有效使用。
在这个项目中,我们并不打算使用真正的DNA计算,而是使用分子生物学中心教条中的原理思想来开发这个方法。该方法只模拟中心教条的转录、剪接和翻译过程;因此,它是一种伪DNA密码方法。结果表明,对于长度为n的信息,该方法的蛮力攻击时间复杂度为O(2^n)。实验还表明,该方法在计算、存储和传输方面具有很高的效率。
尽管这个方法有很高效率,面对具体的攻击也非常强大。但是密码文本中包含了部分信息使该方法不那么强。因此,该方法目前只作为其他加密方法的加强(这里的意思是把其它加密方法的密码文本作为DNA方法的明文文本吧?)但是,我们提出了几个扩展和变形,可以用来增强这个方法。这些方法的优化(比如多轮使用)有很大机会获得更好的性能。由于这是一种新的密码学方法,只包含了一些原始的思想,但在此基础上还有很多要改进。
文献调查
DNA计算(分子计算)利用DNA固有的组合特性进行大规模并行计算。这个想法是,通过适当的设置和足够的DNA,一个人可以通过搜索解决巨大的数学问题。因此,目前的DNA计算主要依赖于DNA的海量存储和并行计算。
Ashish Gehani、Thomas LaBean和John Reif发表了一篇论文[Gehani, et. al, 2000],提出DNA计算的高计算能力和令人难以置信的紧凑信息存储介质,有可能实现基于一次一密的DNA加密。虽然目前基于一次一密的密码系统的实际应用仅限于传统电子媒体,但他们认为,少量DNA就可以满足一个用于公钥基础设施(PKI)的一次一密。
----------------------------------------分割线:下面是个人BB -------------------------------
首先什么是PKI,什么又是基于DNA的一次一密加密?
公钥基础设施(PKI):Public key infrastructure。在电子交易中,互联网用户面临很大的安全问题。①保密性,②完整性,③身份认证和授权等等。它利用公钥加密技术为电子商务建立了一套安全基础平台的技术和规范。
所以PKI只是个应用场景,重点在什么是DNA的一次一密。
首先人工合成长度为N(N>40)的DNA单链,组成一次一密密码本。长这个样子。

每条DNA单链的前20个碱基和后20个碱基分别为前引物序列和后引物序列,中间为密钥序列。每条DNA单链的前引物和后引物组成该DNA链的引物对。
需满足(1)任意两条DNA单链的引物对不完全相同;(2)任意两条DNA单链的密钥序列不完全相同。
加密过程:
首先将明文转换为碱基序列,转换表即编码方式可以是这样:

即若明文长度为L/3,则其对应的碱基序列长度为L。将明文(碱基序列)分为S段,
每一段长度为N-40个碱基,即将明文分为与密钥序列一样长的一段段,最后一段会小于等于N-40。
分完段后,选择S组引物对,进行密钥分配。密钥分配通过PCR和测序实现。
为什么需要引物?因为DNA聚合酶智能将游离的脱氧核苷酸添加到已有的脱氧核苷酸链上。也就是要在已有的链的基础上将其进行延伸。而不能把纯粹游离的脱氧核苷酸缩合起来,所以一定要用引物。
举个栗子:现有待加密信息“DNA Cryptography”。

明文长度为15个英文字母,根据表1, L=45。S=2。

然后选择2个引物对。表3中的引物序列呢是随机生成的,就是人工合成一对引物。扔到大池子里,这个大池子(一次一密密码本)里有许多DNA单链和游离的脱氧核苷酸。然后引物对与单链在首尾处互补结合,通过引物吸纳游离的脱氧核苷酸(碱基),与DNA单链进行全链完整的互补。然后通过某些技术吧DNA互补链提取然后进行中间40个碱基的测序,得到密钥序列。这个DNA单链因为进行了互补配对,形成了双链结构,已不能再使用,相当于密码本中的一条code被用了,无法再用。所以是一次一密。
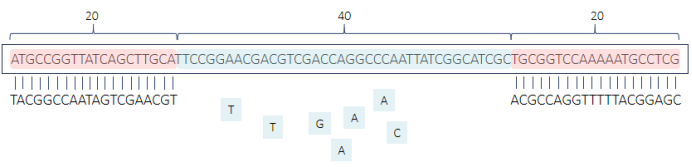
A与B、C进行异或得到D。其中第二段因为只有10个二进制,与C前10位进行异或,得到D。
![]()
异或算法如下:
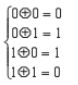
加解密过程总结如下图:

攻击者知道D(密文)是80位的二进制数,80位的二进制数有2^80个。攻击者可能知道每次PCR(就是选密钥)所用的引物序列。但是,攻击者没有一次一密密码本。
如何实现一次一密的呢?每条DNA单链的引物对不同;每条DNA单链的密钥不同;每对引物只使用一次,只要引物对不同,就实现了一次一密加密。
------------------------------------------------分割线:上面是个人BB---------------------------------------
[Gehani, et. al ., 2000]解释了他们的一次一密的DNA加密方案。他们认为,DNA可以满足大容量的一次一密,用于公钥基础设施(PKI)。将DNA密码学注入到公共PKI场景中,这些研究人员认为他们有能力遵循相同的PKI固有模式,但使用DNA键的固有大规模并行计算特性来执行公钥和私钥的加密和解密。实际上,事务中使用的加密算法现在可能比传统加密方法中使用的加密算法复杂得多。
公钥和私钥是什么?
公钥和私钥是成对的,它们互相解密。
公钥加密(锁),私钥解密(钥匙)。
私钥数字签名(锁),公钥验证(钥匙)。
[Gehani, et. al, 2000]提出的基于DNA的密码学方案之一是使用基于芯片的微阵列技术,一般可以表示为:
加密:
· 取一个或多个DNA链(作为明文)作为输入。
· 向它们添加一个或多个随机构造的“密钥”链。
· 由此产生的“标记明文”DNA链,明文隐藏在含有许多其他“干扰物”DNA链中,这种DNA链也可以随机构建。
解密:
· 已知“密钥”链的信息。
· DNA链的分辨可以通过一些已知的重组DNA分离方法解密:
明文链可以通过与“秘密密钥”链的互补物杂交分离出来,这些“秘密密钥”链可以放置在磁珠或准备好的表面上的固体支撑中。
这些分离步骤可以与扩增步骤和/或PCR相结合。该过程如下图所示
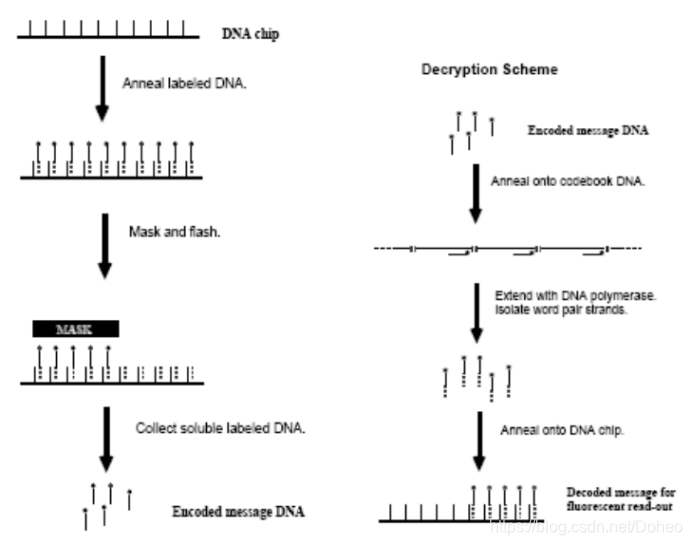
这个过程用于2D图像的加密。它们也被考虑将DNA计算用于信息隐写术。很容易看出,DNA计算只是经典的计算,尽管高度并行和大规模存储。因此,这种形式的DNA计算在密码学领域面临着巨大的风险。此外,这种技术目前很难在实验室之外使用,无论是获取DNA链,还是提取结果。
到这里是不是完全不明白图1讲的啥?作者在这里讲了一下Gehani这个人用DNA芯片加密解密2D图像的过程,但是讲嘛也不讲清楚(用这么点篇幅也讲不清楚...)翻了一下Gehani的“DNA-Based Cryptography”。大致看明白了。
区别于这篇文章说的不利用真正的DNA来进行加解密,Gehani的方法用真正的DNA来加解密二维图像,个人觉得挺神奇。以下:
首先,我们知道加密的手段可以是替换,像上面提到的DNA单链的互补法则,一条单链的互补链就能直接作为密文,规则就是A-T,C-G的替换,但这非常容易被破译。同理,如果把替换的规则制定地更复杂一些,比如A-AGCTCG,T-ACGCGTTACTCG,G-TACCAGCTCG,C-AGGGGCTTTA。当然了,这样还得保证某一较长序列的前缀不能和其他对应规则链相同。如果更复杂一点,ATCG-CGTA,CGGC-CTGA....我们能建立很多很多这样的替换对,所有的替换对组合起来形成一个字典。这很形象,我们拿到密文,想知道各个单词是什么意思,就查“字典”。但是这个释义是我们人为定义的,如果某一单词,比如ATCG-CCCA的替换对是这样的,由于排列组合以及单词长度的变化还有可行的替换,我们能得到许多的“字典”。所有字典放在一起叫library。就很形象有没有!对比前面的一次一密的加密原理,library就是一次一密密码本。我们要加密一条信息,就选择一本“字典”(一条code),进行加密(替换)。
看一下这个“字典”的样子:

“字典”中呢,左右的单词和释义连接排列,P表示明文,C表示对应密文。~P是P的互补链。到这里先理解“字典”就可以了。
上面讲的一次一密密码本是随机生成的,而这里的字典不是。如果按英文单词数量来“制作”字典,那么它的大小将在10,000到25,000个单词对之间。但是出于实验条件限制,需要更小的字典,那么我们可以用ASCII字符表,从而单词对大小为128。字典的体积减小会带来加密性能降低,不知道现在有没有折中的,更好的实现方法。反正确定好单词的映射关系之后,可以在长基因链上进行克隆。长基因链可以看做是包含了所有碱基组合方式的一条长长长长的链——相当于你随意写一串基因码,你总能在这条长链上找到它。刚刚说了单词-释义之间是很随机的定义,我们可以在这条长基因链上顺着单词编码的方向定义它的释义,从而能构成一个Ci-Pi。
好现在我们有:
1、待加密数据(一张二维图像);
2、带有固定DNA链的芯片;
3、在长基因链上编码得到的library。
这个带有DNA链的芯片如下图:
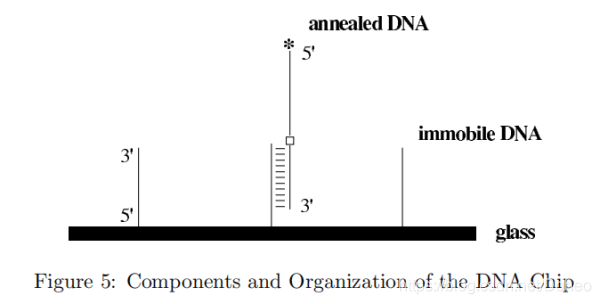
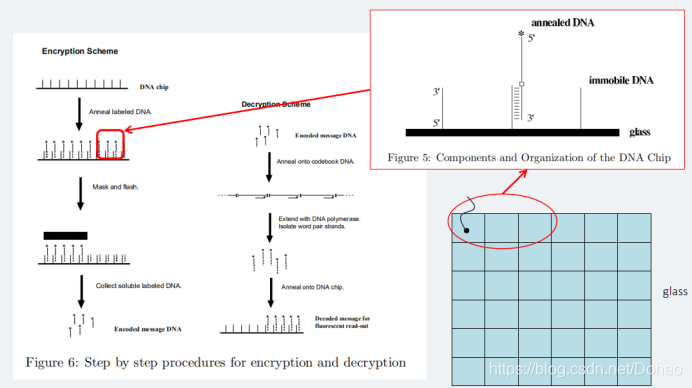
根据目前使用的技术,固定的DNA链以可寻址网格的顺序位于芯片的玻璃基板上。这样的DNA芯片目前已经可以在市场上买到,而构建定制变体的化学方法也得到了很好的发展。这个glass可以认为是一张网格,每个格子里的immobile DNA看做对应的像素。不同的immobile DNA标记着不同的像素位置。
其中与immobile DNA部分配对的这个荧光标记的(带星号)单词-释义链,也就是图1 中的one-tiem pad unit是提前按照字典制备的。其中5’端是明文单词的补码(注意是补码),也就是图1中没有讲到的~P。3’端是对应密文的补码。中间的白色方块是一个可光分裂的基本模拟物,能够分裂寡核苷酸的主干。然后这个带荧光标记的密文—明文字对链退火到immobile DNA链。这样所有的网格(像素)的固定DNA链都配对上了。

然后用一个MASK即掩模,这个掩模对应图4中图片的黑色部分。那么得到一个具有透明(白色)和不透明(黑色)区域的芯片,进行闪光。没有掩模保护下的网格上的密文明文链发生分解。也就是说,3’的密文的补码还在固定DNA链上,5’的带荧光标记的明文互补链就游离在了溶液中。这个游离的DNA链代表了特定网格位置。
随后我们收集这些游离的带标记的DNA链,如图4的PanelB。这就是加密后的信息,我们怎么从加密后的信息还原图像呢。
我们将这些带荧光标记的DNA退火到字典上。将原来的单词-释义链补全。在退火到相同的DNA芯片上。这时候这些带荧光的链只与原先不被MASK遮挡的即白色区域的DNA固定链配对。在解密过程中,荧光标签仍然是必需的,但光不稳定的基础是不必要的。解密的最后一步包括将改造后的单词对链绑定到DNA芯片上,并通过荧光显微镜读取信息。
DNA隐写术还有其他乱七八糟的内容插播:
隐写术是将通常未加密的文本或者图形完全地隐藏在其它的通过电子传输的文本或者图形中的一种加密方式。
在隐写术加密中,携带秘密信息的载体的数量越大,攻击者从这些载体中恢复出秘密信息的难度就越大。因此,为了提高隐写术的安全性,需要大量的高密度载体,而DNA的特征正好符合这一要求。 1999年,Celland等人发表提出世界上第一个利用DNA实现信息保密的方法。信息写入的方式是合成具有特定引物的DNA序列,解密的方式是利用PCR扩增之后测序。
隐写术可以分为两种加密方式:
第一种是明文串的加密。将明文串与其他DNA串混合在一起进行加密,这样能够防止通过排序读出明文串。其它的这些DNA分子串,我们叫伪串。为了确保该方法的安全性,伪串应该同消息串具有相同的组成形式。解密的时候需要确认附着在明文信息上的唯一的识别序列(即密钥序列)。这个序列可以在串的终端,正常情况下位于起始序列的位置。因此,解密时通过使用相应的密钥序列作为PCR反应的引物来读出明文消息。这种技术的安全性需要保证伪串的随机性或者使得所有的DNA串的出现具有相同的频率。(将密钥作为引物?利用了引物的特殊性?只能是特定引物?是在不/无法测序的条件下吧这,如果已有DNA单链形式的密文,利用生物手段不就可以直接破译了吗?)
第二种是图形明文的加密。是将明文串和大量的包含相同密钥序列的伪串混合加密。在这种方式下,密钥序列再也不具有用作解密过程的唯一特性。取而代之,解密的密钥是加密使用的整个伪串池。
PCR中,退火指模板双链DNA经热变性、双螺旋解开成单链后,通过缓慢冷却到55度左右,使引物(具有互补碱基的RNA片段)与该模板DNA单链重新配对,形成新的双链分子的过程。退火能在互补的DNA或RNA之间形成双链DNA分子、双链RNA分子或RNA-DNA杂交分子,受温度、时间、DNA浓度、DNA顺序的复杂性等因素的影响。
动机和方法
伪DNA密码方法不同于基于DNA计算的DNA密码方法。该方法并不真正使用DNA序列(或寡核苷酸),而是只使用DNA功能的机制;因此,该方法是一种伪DNA密码方法。该方法的密码/破译过程基于分子生物学的中心法则,其过程类似于真实生物体的DNA转录、剪接和RNA翻译。
生物知识
分子生物学的中心法则如下图所示。

基因表达知识补充:
基因表达是指基因指导下的蛋白质合成过程。
转录:
在RNA聚合酶的催化下,以DNA为模板合成mRNA的过程称为转录。在双链DNA中,作为转录模板的链称为模板链;而不作为转录模板的链称为编码链。编码链和模板链互补,它与转录产物的差异仅次于DNA中T变为RNA中的U。
在含有许多基因的DNA双链中,每个基因的模板链并不总在同一条链上,亦即可作为某些基因模板链的一条链,同时也可以是另外一些基因的编码链。
剪接:
一个基因的外显子(编码区)和内含子(非编码区)都转录在一条原始转录物RNA分子中,称为前mRNA。因此前mRNA分子既有外显子序列又有内含子序列,另外还包括编码区前面及后面非翻译序列。这些内含子序列必须除去而把外显子序列连接起来,才能产生成熟的有功能的mRNA分子,这个过程称为RNA剪接(RNA splicing)。剪切发生在外显子的3’末端的GT和内含子3’末端与下一个外显子交界的AG处。
翻译(蛋白质生成过程):
以mRNA作为模板,tRNA作为运载工具,在有关酶、辅助因子和能量的作用下将活化氨基酸在核糖体上装配为蛋白质多肽链。在翻译过程中,核糖体从特定的三个碱基开始读取片段,然后核糖体从mRNA中一次读取三个碱基(一个密码子),并将它们翻译成一个氨基酸;翻译的结尾也有一定的三碱基。
原理
伪DNA密码方法由两个部分组成,类似于翻译/剪接和转录过程。
为了使密文难以破译,我们对原剪接过程作了一些修改。最初,内含子的特征是它们的起始码和结束码,这使得对内含子的猜测相对容易。我们将其更改为另一种方案,其中开始代码和模式代码指定了内含子。模式代码是非连续的模式,它定义要删除框架的哪些部分,以及保留哪些部分。这使得对内含子的猜测变难,因为它们现在是间隔的内含子。由于起始码和模式码可以决定内含子的长度,所以不需要结束码。
非正式地,让Alice作为信息的发送者,Bob作为接收者。在Alice看来,信息以二进制形式存储,可以转换成DNA形式(A表示00,C表示01,G表示10,T表示11)。Alice还知道起始代码(表明内含子的开始)和模式代码(代码定义哪些部分被删除,和哪些部分保留),所以Alice知道内含子在信息的DNA形式中的位置以及那些部位的去留。因此,这两部分可以简单描述如下:
- Alice扫描信息的DNA形式,找出内含子;她记录了内含子的位置,并按照指定的模式将内含子裁剪出来。所以数据的DNA形式被翻译成数据的mRNA形式。
- Alice根据遗传密码表(61个密码子到20种氨基酸),将mRNA形式的数据转换为蛋白质形式的数据。这里有人可能会有疑问,一共有64种密码子,其中3中是stop类型的密码子,但是这是伪DNA方法,是不是stop密码子有什么关系?是有关系的,最后有个详细的加密解密的栗子,中间对应遗传密码表,因为stop密码子不表达。但是翻译中如果有stop的三碱基组成怎么办???遗传密码表如下:

蛋白质形式的数据然后被传送给Bob。内含子的起始和模式编码,内含子的地方,删除了的间隔的内含子,密码子-氨基酸匹配来的蛋白质是解密的关键形式的数据,并通过一个安全通道传给Bob(或者由Bob的公钥加密,然后传给Bob)。
在Bob这边,他通过安全通道从Alice接收密钥(或者使用公钥协议与Alice通信来接收密钥)。当Bob接收到蛋白质形式的数据和密钥时,他使用密钥从蛋白质形式的数据中恢复mRNA形式的数据,然后恢复DNA形式的信息,与Alice加密信息的顺序相反。然后他可以恢复二进制形式的信息,最后得到Alice发送给他的信息。
该方法的方案如下图所示:

大致上,方案可以用一下公式概括(M和C分别表示明文和密文)
*加密密钥E1 =(内含子的起始码和模式码,内含子的位置)
*加密密钥E2 =(蛋白-氨基酸配对)
*解密密钥D1 =E2
*解密密钥D2 =E1
*C’ = E1(M), C = E2(C’)
*M’ = D1(C), M = D2(M’)
该方案主要是一个对称密钥算法,发送方最初只有部分密钥,然后生成其余的密钥。很明显,这种方案本质上是一个2步替换过程,尽管它们是一般意义上的替换(不是逐字母替换)。
文章最后面有个栗子:
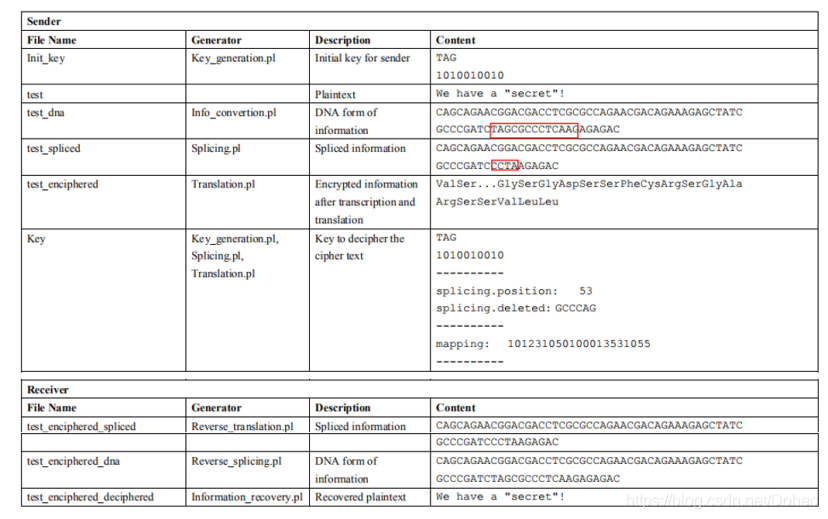
从“We have a “secret”!”到DNA形式的信息应该没有问题,从DNA form到spliced form也就是红框标出的变化是怎么操作的呢。
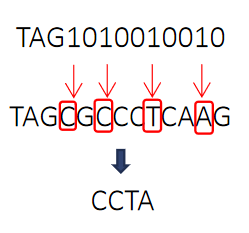
其中“TAG”表示start code,不是标签的意思(肯定有人跟我一样这么理解过orz)。做了一张图,如下,是不是秒懂!
从spliced form到encrypted form 是先进行DNA到mRNA的转录,即中间作者省去了一步

因为DNA到RNA原来的3端变成5端,所以从右边开始翻译。
然后来聊一聊这种方法的优缺点:
伪DNA密码学方法有很多优点,如下:
- 发送方易于对信息进行加密,不需要很多信息就能进行加密。换句话说,sender最初拥有部分密钥,然后生成密钥的其他部分。
2、几乎不需要通过安全通道(只有密钥)进行通信。密钥大小与明文大小来说,比例较小。
3、蛋白质形式的信息可以通过公共渠道传递,蛋白质形式的信息的大小一般小于原始信息的大小。
4、一次一密可以作为密钥使用,提供足够的存储空间,因为几乎一个密钥对应一条(次)信息。
缺点:
- 由于发送方无法控制内含子的位置,所以存在部分可用信息,其中确实包括一些明文。可以使用多轮来缓解这个问题。
- 分析(如差分分析)可能会破译密文的部分信息。一种解决方案是将重要的文本放在内含子中(通过选择合适的内含子开始和结束模式),密码文本也通过其他加密方法进行加密。因此,伪DNA密码方法可以看作是传统密码方法的一种补充。
- 可能有不好的内含子开始和结束来切割内含子。一种解决方案是发送方准备许多内含子的起始和结束代码,并选择一对可能导致适当切断的内含子。
- 密钥越复杂,解密过程就越复杂。
方法分析
假设信息的DNA形式长度为n,有k个内含子,内含子的平均长度为m,那么信息的mRNA形式长度为n-k*m。由于一个密码子(由3个核酸组成)一般可以翻译成一个氨基酸,所以信息D”的蛋白质形式长度为(n-k*m)/3。
对于发送者Alice,她只需要扫描一次信息的DNA形式,然后切断内含子就可以得到数据的mRNA形式,时间为O(n)。之后,她可以根据遗传密码表执行翻译过程,生成蛋白质形式的数据,也是线性时间。因此,Alice的加密过程的时间复杂度为O(n)。
对于接收方Bob,他可以使用Alice发送给他的密钥来执行反向操作。由于所有的遗传密码映射和内含子的位置都是已知的,所以他也可以在O(n)时间内执行解密过程(只需对蛋白质和mRNA形式的信息进行两次扫描)。
如果Eve和窃听者能够监听到Alice和Bob的通信,并且他还得到了蛋白质形式的信息,让我们看看他有多么努力地试图破解加密的信息。
如果Eve试图使用蛮力攻击,那么这对他来说是一个非常困难的计算问题。在蛋白质到mRNA的步骤中,由于有61个编码密码子,而只有20个氨基酸,平均有3个密码子被映射到相同的氨基酸上,所以蛋白质形式的数据解密回mRNA大约是3^(n-k*m)/3种。在逆转录过程中,如果使用连续内含子方案,那么插入内含子的位置可能有2^n-k*m个组合。即使内含子已知,从数据的mRNA形式恢复数据的DNA形式的时间复杂度为O(k*2^n-k*m)。如果使用间隔内含子方案,时间复杂度可以是O(2^kx2^n-k*m)。所以总时间复杂度至少可以是O(3^(n-k*m)/3x2^n-k*m)。如果仔细控制,k*m大约是0.35n(即log23/(log23+3)*n),那么上面的复杂度是O(2^n)。k*m越小,这样的时间复杂度可以增加,但是会暴露更多的部分信息,这使得它对于其他攻击来说是值得尊敬的。因为n通常是1M位的,所以这种蛮力攻击方法对Eve来说是一场灾难(不实用)。
然而,该方法对选择的明文攻击没有那么强的抵抗力。了解该方法的机理,对关键字(起始和模式内含子)一无所知;内含子的地方;删除间隔的内含子;遗传密码映射);如果给定足够的明文和计算量,攻击者Eve可以获得部分或全部的密钥信息,并且具有很高的概率。他破解钥匙的一种方法是一种类似于差分攻击的技术。攻击者一次可以选择2个明文,而这2个明文只在1个或2个地方不同。然后攻击者可以用伪DNA加密方法对两个明文进行加密,得到相应的两个密码文本。通过对密码文本的比较和分析,攻击者可以获得一些起始和模式内含子的信息,以及内含子的位置和删除的间隔内含子。比较不同但相似的基因对可以揭示更多关于这些信息的信息,以及一些遗传密码映射信息。因此,攻击者使用的明文对越多,他恢复密钥的可能性就越大。
假设信息的DNA形式D长度为n,内含子有k个,内含子的平均长度为m,那么差分攻击可以在较短的时间内用足够的明文破解密钥。在最理想的情况下,攻击者可以“预测”内含子的位置,然后他可以一次破坏一个内含子;此外,他还可以使用统计分析(如果存在这样的统计特性)恢复密文。在这种情况下,攻击者可以为每个内含子测试选择2^2m-1明文,并以非常高的概率恢复该内含子。因此,攻击者将总共选择k*2^2m-1明文来破解密钥。关于时间,他需要k*2^2m-1*m的时间来恢复内含子,以及线性或二次的时间来恢复遗传密码映射。因此,在最优情况下,攻击者可以在O(k*22m-1*m)时间内破坏密钥。这比蛮力攻击者所使用的O(2n)时间要短得多,特别是在一般情况下为n>>m的情况下。虽然一些最优假设(如统计分析和已知的内含子位置)普遍不满足,但很明显,差分攻击能够在相对较短的时间和足够的明文条件下,以较高的概率恢复密钥信息。使用多轮或更复杂的拼接和映射规则,可能使该方法更强地抵御这些明文攻击。
侧通道密码分析也适用于伪DNA密码方法,因为未优化的操作时间(或能量)与明文内容和关键特征(起始和模式内含子)高度相关;内含子的地方;删除间隔的内含子)。在实现中引入噪声可以保护该方法免受某些此类攻击。
这种方案本质上是一个两步替换过程。在这种方案中,主要采用置换(很少置换)。因此,理论上[Shannon, 1949],主要是混乱,而很少扩散的明文可以实现。这使得方案不那么强,而这种情况可以通过多轮来部分缓解。更实际的应用是将其用作其他加密方法的增强,因为它可以极大地提高安全性,特别是针对蛮力攻击。而且,当采用多轮方法时,完全可以肯定会引入更多的换位,安全性会大大提高。
尽管有这些分析,我们必须承认,关于这种方法已经发现了一些其他的关键问题,我们已经列出了其中一些在方法部分的优点和缺点。
实验和结果
我们已经实现了我们已经解释过的伪DNA加密方法。实验表明,该方法是有效的;理论分析表明,该算法具有一定的抗攻击能力。
这些程序是为发送方和接收方设计的。通常,接收方的程序执行与发送方程序相同的反向进程。
在发送方,发送方首先需要他的初始密钥,其中包括启动内含子和模式代码。这些代码可以由生成器程序随机生成,也可以由用户自己生成。用户还需要对明文进行加密。他首先使用信息转换程序将明文翻译成DNA形式的信息。然后用相应的程序模拟中心教义的剪接、转录和翻译过程。在这些过程中,出于兼容性的原因,还实现了必要的填充。通过这些步骤,将内含子的起始码和模式码、被删除的内含子的位置、被删除的间隔的内含子以及蛋白质的密码子-氨基酸映射添加到密钥文件中,并创建加密信息。这两个文件可以通过不同的通道传输给接收者(加密文件通过公共通道传输,密钥文件通过安全通道传输)。
在接收端,他从不同的通道接收加密的信息和密钥文件,然后使用密钥文件中的密钥信息来解码加密的信息。他首先使用各自的程序以及密钥进行反向翻译、反向转录和反向剪接过程。经过这些处理,他可以得到DNA形式的信息,然后他可以使用恢复明文。通过这些方法,接收者最终得到了发送者想要告诉他的信息。
该加密方法的实现图如下图所示。

由于我们在方法部分的优点和缺点中已经指出,部分信息的存在使方法本身不那么强大;除了一些攻击,如蛮力攻击,其他攻击可以相对容易地破解当前密码文本。因此,我们将只从理论上检验程序的能力。在实验部分,我们关注的是程序的效率和可靠性,我们也检查了程序的性能,在存储和传输效率方面。结果表明,该方法的程序计算效率高、鲁棒性好,并具有良好的存储和传输性能。
实验是在Linux环境下进行的,使用了许多Linux控制台工具(s.a.时间)。这些程序是由Perl编写的,目的是为了清晰和高效,并且可以在UNIX兼容系统(不需要任何配置)和Windows系统下执行这些程序(Perl安装在windows系统中)。测试数据从Internet上随机选择不同的数据源,并存储在本地机器上进行处理。我们所选择的明文具有高度的娱乐性。它们包括短文本和长文本、纯字母文本以及结合字母和许多其他字符的文本。目的是测试程序在不同类型信息上的性能。
针对文本长度的差异,我们选择了4个明文(增加它们的长度)。检查原始明文大小、生成的密码文本大小和密钥大小;以及加密和解密时间。这些特征是检验程序计算、存储和传输效率的关键特征。
每个明文的长度都是前者的10倍,从10开始(第一个文本是10)。对于每个纯文本,我们还计算了以ASCII格式存储纯文本所需的比特数,ASCII格式是纯文本长度的8倍。对于密文,我们列出了密文的长度,并计算了相应的位。因为一个氨基酸可以用3个字母序列表示,64个氨基酸可以用6位来区分;密文中每个字母只需要2位来表示。因此,每个密码文本所需的比特数是密码文本长度的2倍。对于密钥的大小,列出的数字包括冗余。冗余就是接收者会知道的相应信息的标签和分隔符。实际的密钥的大小依赖于内含子的起始码和模式码的大小;但是一般来说,它的大小大约是包含冗余的大小的一半。
还列出了每个数据集的加密时间和解密时间。在Linux系统下,每个加密和解密过程执行5次,得到并列出平均系统时间。这使得时间的评估是公平的。
结果如下表:

应用程序的性能也可以通过下面的图来解释。


如上两图所示。密码文本的长度与相应的明文长度成正比。实际上,当实际的位被认为是,存储密文的所需空间大致是明文所需的 ¾。这表明该方法在存储方面是有效的,因为密文比明文需要更少的存储空间。另一个观察结果是,即使在冗余程度很高的情况下,密钥的大小也随着明文大小的增加而增加。通常,冗余密钥的大小是明文大小的5.0倍左右(从10.0到4.5倍不等,当明文长度增加时,接近5.0倍)。如果删除冗余,并选择密钥文件中信息的适当表示(例如,2位表示核酸,而不是用ASCII表示),那么密钥大小将急剧减小到明文大小的一小部分。因此,密文可以通过公共信道快速传输(甚至比传输明文还要快),小密钥也可以通过安全信道快速传输。因此,该方法在存储和传输方面都是有效的。
加密和解密时间表明,该程序具有较高的计算效率。相对表和图显示,不同明文长度的加密和解密时间的增长速度慢于明文长度的变化。这表明即使对于相对较长的明文,处理时间也可以非常快。因此,计算效率是明显的。这表明了多轮方法的潜在适用性。
针对文本的不同内容,我们选择了5种不同内容的明文。目的是检验程序的鲁棒性。
选择纯文本数据集,使它们非常具有代表性。一个纯文本只包含字母和数字字符,一个纯文本只包含非字母和数字字符,其他3个纯文本包含几个不同寻常情况下的字符组合。通过这种方法,可以对鲁棒性进行高置信度的检验。

通过对不同内容的明文进行实验,验证了该程序的鲁棒性,结果表明,该程序几乎可以处理所有字符及其组合,具有较高的精度和效率,证明了该程序的鲁棒性。我们目前所做的实验是为了解释这种方法。因此,关键数据存在冗余;信息的DNA、RNA和蛋白质形式(包括密码文本和密钥)不是二进制形式。使用二进制表示信息的程序越优雅、越真实,再加上密钥文件的更好组织,必将增强这种加密方法的有效性和鲁棒性。这些东西,连同一些扩展和变化的方法,正在仔细调查,他们将在稍后准备好。
总结和未来工作
在本课题中,我们提出了一种基于分子生物学中心法则的伪DNA密码方法。该方法模拟了中心教义的转录和翻译过程;它还添加了一些人工特性,使生成的密码文本难以破解。理论分析表明,该方法对某些攻击具有较强的抵抗能力,特别是对蛮力攻击。实验表明,该方法不仅具有较强的计算能力,而且在存储和传输方面具有较高的效率和鲁棒性。
但是,由于该方法还处于初级阶段,还存在一些缺陷,需要进一步改进。最严重的问题是部分信息的存在,使得攻击者只需一些努力就可以推断出整个信息。在这种情况下,甚至连间隔的内含子都被引入了。其原因可能是由于对明文的混淆不够全面,使得密文统计与明文统计之间的关系不那么复杂。一种解决方案是对明文进行多轮加密以获得密文。其他问题与方法的扩散程度和混淆程度有关;以及破译的复杂性。该密码学系统目前也存在一些实现缺陷,但可以通过更好地表示文件中的信息和数据组织来克服这些缺陷。今后将对这些问题进行理论分析,并进行相关实验来检验其性能。
由于这个方法现在仍然是原始的,所以它有很大的范围可以进行一些扩展和变化。许多这些扩展和变化来自对中心教条原则的修改。这些变化总是可以产生更安全的方法来抵御攻击。
基于这种伪DNA密码方法的变异是有趣的。其中一种变化是人为地修改密码子-氨基酸的映射,使其更加复杂,例如,一个蛋白质映射到3个以上的氨基酸。通过这种方法,可以潜在地增加映射的组合,并使蛮力攻击更加困难。另一个变化是使拼接规则更加灵活,这可以增强混淆效果。这些变化的影响,连同其他一些变化,将在今后加以审查。
对于方法的扩展,上面提到要使用多轮方法,尝试解决部分信息问题。这是密码学的一个基本概念,关于它的实验将在后面进行。
我们提出的伪DNA密码学方法并不局限于加密解密领域,还包括按摩认证等领域。实际上,如果将该方法用作生成消息身份验证代码的散列函数,则该方法的加密过程可以非常强大和有效。通过这种方法,只需要初始密钥,并且加密过程可以很快。如果使用多发子弹,安全性也可能令人满意。问题是生成的MAC的长度很难控制,解决这个问题的方法之一是进行多轮处理,加上填充以获得具有固定长度的MAC。如果使用真实的DNA数据,可以实现隐写术,尤其是图像隐写术。将来还将研究如何使用这种方法进行消息验证,以及它的其他用途。
这种基于中心法则的方法在软件和硬件应用中都有其本质上的优势。由于在明文的编码和解码过程中只涉及4个核苷酸,因此基于C语言或汇编语言的原始代码可以使程序变得非常高效。基于这些简单的原则,硬件实现可以很容易,而且也可以非常高效。在当今先进的硬件技术下,多回合可以轻松实现,安全性也相对合理。这些优点表明,该方法非常适合于软件和硬件的实现。对这些因素的进一步分析和实验是今后工作中非常有趣的课题。




