【AI实战】开源可商用的中英文大语言模型baichuan-7B,从零开始搭建
- baichuan-7B 简介
- baichuan-7B 中文评测
- baichuan-7B 搭建
- 参考

baichuan-7B 简介
baichuan-7B 是由百川智能开发的一个开源可商用的大规模预训练语言模型。基于 Transformer 结构,在大约1.2万亿 tokens 上训练的70亿参数模型,支持中英双语,上下文窗口长度为4096。在标准的中文和英文权威 benchmark(C-EVAL/MMLU)上均取得同尺寸最好的效果。
-
GitHub:
https://github.com/baichuan-inc/baichuan-7B -
Hugging Face:
https://huggingface.co/baichuan-inc/baichuan-7B/tree/main
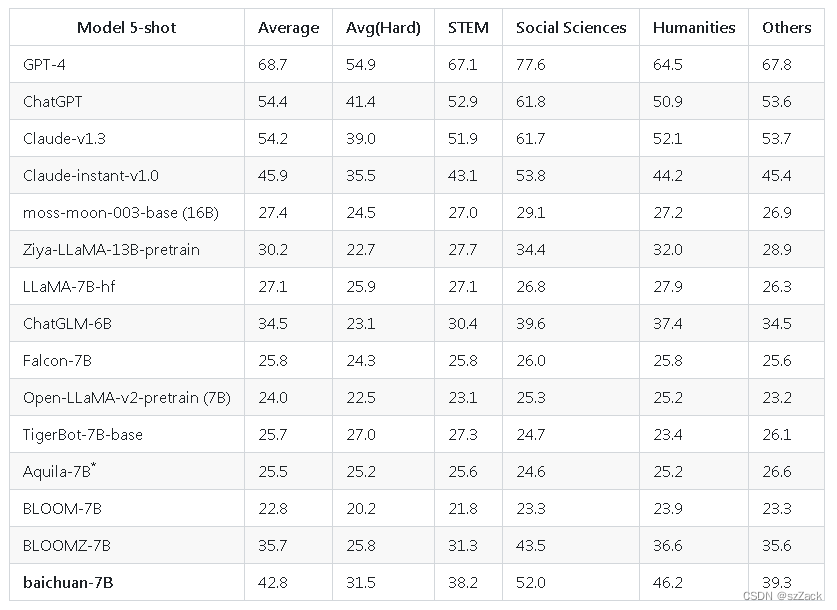
baichuan-7B 中文评测
-
C-Eval
-
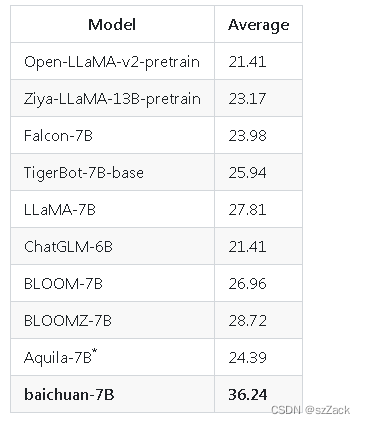
Gaokao
baichuan-7B 搭建
-
1、拉取docker镜像
docker pull nvcr.io/nvidia/pytorch:21.08-py3【】需要 cuda 11.1 及以上版本
-
2、创建docker
nvidia-docker run -it -d \--name baichuan_llm \-v /llm:/notebooks \-e TZ='Asia/Shanghai' \--shm-size 16G \nvcr.io/nvidia/pytorch:21.08-py3进入容器内:
docker exec -it baichuan_llm env LANG=C.UTF-8 /bin/bash -
3、下载代码
cd /notebooks/ git clone https://github.com/baichuan-inc/baichuan-7B.git -
4、下载模型权重文件
cd baichuan-7B/ git clone https://huggingface.co/baichuan-inc/baichuan-7B -
5、按照依赖库
pip install -r requirements.txt -
6、推理
from transformers import AutoModelForCausalLM, AutoTokenizertokenizer = AutoTokenizer.from_pretrained("baichuan-7B", trust_remote_code=True) model = AutoModelForCausalLM.from_pretrained("baichuan-7B", device_map="auto", trust_remote_code=True) inputs = tokenizer('登鹳雀楼->王之涣\n夜雨寄北->', return_tensors='pt') inputs = inputs.to('cuda:0') pred = model.generate(**inputs, max_new_tokens=64,repetition_penalty=1.1) print(tokenizer.decode(pred.cpu()[0], skip_special_tokens=True))-
输出

-
-
7、训练
-
准备数据
用户将训练语料按总rank数的倍数均匀切分成多个 UTF-8 文本文件,放置在语料目录(默认为 data_dir )下。各个rank进程将会读取语料目录下的不同文件,全部加载到内存后,开始后续训练过程。以上是简化的示范流程,建议用户在正式训练任务中,根据需求调整数据生产逻辑。 -
配置 DeepSpeed
修改 config/hostfile ,如果是多机多卡,需要修改 ssh 中各个节点的 IP 配置。 -
训练
sh scripts/train.sh
-
参考
https://huggingface.co/baichuan-inc/baichuan-7B/tree/main
https://github.com/baichuan-inc/baichuan-7B