源码基于:Linux 5.4
0. 前言
kmalloc()、vmalloc()、malloc() 这三个函数是常用的内存分配函数,但有着本质的区别。
kmalloc() 基于slab 分配器,是建立在一个物理地址连续的大内存块上,所以 kmalloc() 分配的内存物理是上连续的,而且 kmalloc() 映射的虚拟内存在线性区域,也是连续的。详细可以查看《slub 分配器之kmem_cache_alloc》一文第 5.1.2 节。
相比于 kmalloc(),vmalloc() 实现是为了虚拟内存连续,而物理内存可以不用连续。正是因为物理内存不连续,而虚拟内存需要连续,所以,需要对每一个页进行映射,因此vmalloc() 的效率不是很高,只会在不得已的时候使用(例如,需要使用大内存)。另外,vmalloc() 申请内存的过程中可以睡眠,因此不能用于中断上下文中。
相对于上面两个函数,malloc() 是用户层的内存分配函数,最终会通过 brk() 和 mmap() 进行系统调用。
1. vmalloc 初始化
init/main.cstatic void __init mm_init(void)
{...mem_init();kmem_cache_init();...vmalloc_init();...
}在 buddy初始化完成会进行slab 分配器的初始化,之后会通过 vmalloc_init() 对vmalloc 相关内存进行初始化:
mm/vmalloc.cvoid __init vmalloc_init(void)
{struct vmap_area *va;struct vm_struct *tmp;int i;/** Create the cache for vmap_area objects.*/vmap_area_cachep = KMEM_CACHE(vmap_area, SLAB_PANIC);for_each_possible_cpu(i) {struct vmap_block_queue *vbq;struct vfree_deferred *p;vbq = &per_cpu(vmap_block_queue, i);spin_lock_init(&vbq->lock);INIT_LIST_HEAD(&vbq->free);p = &per_cpu(vfree_deferred, i);init_llist_head(&p->list);INIT_WORK(&p->wq, free_work);}/* Import existing vmlist entries. */for (tmp = vmlist; tmp; tmp = tmp->next) {va = kmem_cache_zalloc(vmap_area_cachep, GFP_NOWAIT);if (WARN_ON_ONCE(!va))continue;va->va_start = (unsigned long)tmp->addr;va->va_end = va->va_start + tmp->size;va->vm = tmp;insert_vmap_area(va, &vmap_area_root, &vmap_area_list);}/** Now we can initialize a free vmap space.*/vmap_init_free_space();vmap_initialized = true;
}- 通过 KMEM_CACHE,创建 vmap_area 这个 slab cache 描述符,并存到全局变量 vmap_area_cachep 中;
- 遍历每个 CPU 的vmap_block_queue 和 vfree_deferred 变量进行初始化。其中vmap_block_queue 是非连续内存块队列管理结构,主要是队列以及对应的保护锁。而 vfee_deferred 是vmalloc 的内存延迟释放管理,除了队列初始化外,还创建了一个 free_work() 的工作队列用以异步释放内存;
- 将已经存在的 vmlist 链表中的各项,分别从 slab中分配内存并进行初始化,最终insert 到 vmap_area_root 红黑树和 vmap_area_list 这个全局链表中;
- 在初始化完成,需要将全局变量 vmap_initialized 这个变量设为 true;
2. vmalloc 的分配接口
2.1 vmalloc()
mm/vmalloc.cvoid *vmalloc(unsigned long size)
{return __vmalloc_node_flags(size, NUMA_NO_NODE, GFP_KERNEL);
}
EXPORT_SYMBOL(vmalloc);最终调用 __vmalloc_node_flags(),这里的 gfp_mask 为 GFP_KERNEL。
mm/vmalloc.cstatic inline void *__vmalloc_node_flags(unsigned long size,int node, gfp_t flags)
{return __vmalloc_node(size, 1, flags, PAGE_KERNEL,node, __builtin_return_address(0));
}最终调用的是 __vmalloc_node(),注意 prot 默认为 PAGE_KERNEL,详细看第 2.5 节。
2.2 vzalloc()
mm/vmalloc.cvoid *vzalloc(unsigned long size)
{return __vmalloc_node_flags(size, NUMA_NO_NODE,GFP_KERNEL | __GFP_ZERO);
}
EXPORT_SYMBOL(vzalloc);在 vmalloc 的基础上多了 __GFP_ZERO 的 gfp_mask 限制,即最终内存都会用 0 填充。
2.3 __vmalloc()
mm/vmalloc.cvoid *__vmalloc(unsigned long size, gfp_t gfp_mask, pgprot_t prot)
{return __vmalloc_node(size, 1, gfp_mask, prot, NUMA_NO_NODE,__builtin_return_address(0));
}
EXPORT_SYMBOL(__vmalloc);有些驱动更喜欢使用 __vmalloc() 这个接口,直接指定gfp_mask 和 prot,最终也还是会调用到 __vmalloc_node(),详细看第 2.5 节。
2.4 vmalloc_node()
mm/vmalloc.cvoid *vmalloc_node(unsigned long size, int node)
{return __vmalloc_node(size, 1, GFP_KERNEL, PAGE_KERNEL,node, __builtin_return_address(0));
}
EXPORT_SYMBOL(vmalloc_node);在特定的node 中申请内存,最终调用 __vmalloc_node(),注意 prot 默认为 PAGE_KERNEL,详细看第 2.5 节。
上面几个函数流程大致如下:

下面将重点分析 __vmalloc_node_range() 函数。
需要注意的是:通过这些函数调用到的 __vmalloc_node(),参数 align 默认为1,gfp_mask 默认为 GFP_KERNEL 或 GFP_KERNEL | __GFP_ZERO,prot 默认为 PAGE_KERNEL,node 默认为 -1,caller 默认为内建函数 __builtin_return_address()。
2.5 __vmalloc_node()
mm/vmalloc.cstatic void *__vmalloc_node(unsigned long size, unsigned long align,gfp_t gfp_mask, pgprot_t prot,int node, const void *caller)
{return __vmalloc_node_range(size, align, VMALLOC_START, VMALLOC_END,gfp_mask, prot, 0, node, caller);
}最终调用到的函数为 __vmalloc_node_range(),其中 start 为 VMALLOC_START,end 为VMALLOC_END,vm_flags 为 0。详细的 __vmalloc_node_range() 分析流程见下一节。
按照 VA_BITS=39,PAGE_SHIFT=12(4K) 来看下ARM64内存的内存布局:

内核空间内存分布如上图,其中专门给 vmalloc 分配一个区域(大概 250G),从 VMALLOC_START 到 VMALLOC_END。
dmesg 中还有虚拟地址的划分(4.16 版本之后这部分的打印被去掉,详细查看《内存与内存分布》一文第 6节):
[ 0.000000] Memory: 2669108K/2904448K available (19772K kernel code, 3026K rwdata, 14348K rodata, 3200K init, 21716K bss, 214860K reserved, 20480K cma-reserved)
[ 0.000000] Virtual kernel memory layout:
[ 0.000000] modules : 0xffffffc008000000 - 0xffffffc010000000 ( 128 MB)
[ 0.000000] vmalloc : 0xffffffc010000000 - 0xfffffffebfff0000 ( 250 GB)
[ 0.000000] .text : 0x(____ptrval____) - 0x(____ptrval____) ( 19776 KB)
[ 0.000000] .rodata : 0x(____ptrval____) - 0x(____ptrval____) ( 14528 KB)
[ 0.000000] .init : 0x(____ptrval____) - 0x(____ptrval____) ( 3200 KB)
[ 0.000000] .data : 0x(____ptrval____) - 0x(____ptrval____) ( 3027 KB)
[ 0.000000] .bss : 0x(____ptrval____) - 0x(____ptrval____) ( 21717 KB)
[ 0.000000] fixed : 0xfffffffefe5f9000 - 0xfffffffefea00000 ( 4124 KB)
[ 0.000000] PCI I/O : 0xfffffffefec00000 - 0xfffffffeffc00000 ( 16 MB)
[ 0.000000] vmemmap : 0xfffffffeffe00000 - 0xffffffffffe00000 ( 4 GB maximum)
[ 0.000000] 0xffffffff00002000 - 0xffffffff02e00000 ( 45 MB actual)
[ 0.000000] memory : 0xffffff8008080000 - 0xffffff80c0000000 ( 2943 MB)详细看《内存与内存分布》第 6 节。
3. __vmalloc_node_range()
这个函数是vmalloc() 系列的分配函数最终处理的核心,本节将细化剖析。
mm/vmalloc.cvoid *__vmalloc_node_range(unsigned long size, unsigned long align,unsigned long start, unsigned long end, gfp_t gfp_mask,pgprot_t prot, unsigned long vm_flags, int node,const void *caller)
{struct vm_struct *area;void *addr;unsigned long real_size = size; //暂存初始size,后续出错时打印需要//step1,//vmalloc申请的size 都按照页对齐size = PAGE_ALIGN(size);//检查size正确性,不能为0且不能大于totalram_pages,totalram_pages是bootmem分配器移交给//伙伴系统的物理内存页数总和if (!size || (size >> PAGE_SHIFT) > totalram_pages())goto fail;//step2,//vmalloc的核心处理函数之一//主要是创建vm_struct和vmap_area,并在VMALLOC区域找到一个可以包含请求大小的空位置,// 并使用该虚拟地址配置vmap_area 和 vm_struct 信息。area = __get_vm_area_node(size, align, VM_ALLOC | VM_UNINITIALIZED |vm_flags, start, end, node, gfp_mask, caller);if (!area)goto fail;//step3,//分配内存,建立页面映射关系addr = __vmalloc_area_node(area, gfp_mask, prot, node);if (!addr)return NULL;/** In this function, newly allocated vm_struct has VM_UNINITIALIZED* flag. It means that vm_struct is not fully initialized.* Now, it is fully initialized, so remove this flag here.*/clear_vm_uninitialized_flag(area);//kmemleak_vmalloc()记录分配信息kmemleak_vmalloc(area, size, gfp_mask);return addr;fail:warn_alloc(gfp_mask, NULL,"vmalloc: allocation failure: %lu bytes", real_size);return NULL;
}这里重点流程归纳为:
- step1,要求分配的内存大小按照页对齐,且申请大小不能超过最大值;
- step2,__get_vm_area_node() 在vmalloc 区域找到一个包含请求大小的子区域,并使用vm_struct 和 vmap_area 进行配置保存,详细看第 4 节;
- step3,__vmalloc_area_node() 进行实际的页面分配,并建立页表映射,更新页表 cache,详细看第 5 节;
注意:
对于 vmalloc() 调用,在进入 __get_vm_area_node() 时,会将 vm flags 添加上 VM_ALLOC | VM_UNINITIALIZED,并最终保存到 vm_struct 结构体中的 flags 成员中。
3.1 数据结构和宏定义
3.1.1 vmalloc() 中的flag
include/linux/vmalloc.h#define VM_IOREMAP 0x00000001 /* ioremap() and friends */
#define VM_ALLOC 0x00000002 /* vmalloc() */
#define VM_MAP 0x00000004 /* vmap()ed pages */
#define VM_USERMAP 0x00000008 /* suitable for remap_vmalloc_range */
#define VM_DMA_COHERENT 0x00000010 /* dma_alloc_coherent */
#define VM_UNINITIALIZED 0x00000020 /* vm_struct is not fully initialized */
#define VM_NO_GUARD 0x00000040 /* don't add guard page */
#define VM_KASAN 0x00000080 /* has allocated kasan shadow memory */3.1.2 struct vm_struct
include/linux/vmalloc.hstruct vm_struct {struct vm_struct *next;void *addr;unsigned long size;unsigned long flags;struct page **pages;unsigned int nr_pages;phys_addr_t phys_addr;const void *caller;
};对于 vmalloc() 分配的一段连续的虚拟地址空间区域,都会用一个 vm_struct 结构来管理。
- next:用于串联一个vm_struct 的链表使用;
- addr:存放该虚拟地址空间的起始地址,与size 可知该区域的大小;
- size:虚拟地址空间区域的大小;
- flags:存储了该内存区域的内存类型;
- pages:指向一个指针数组,该数组中的每个指针都表示一个映射到该虚拟区域的物理page;
- nr_pages:存储 pages指向的指针数组的成员个数,即物理页面数目;
- phys_addr:仅当使用 ioremap 映射了由物理地址描述的物理内存区域时才需要;
- caller:调用vmalloc() 函数的函数地址;
从 /proc/vmallocinfo 中:
130|shift:/ # cat /proc/vmallocinfo
0x0000000000000000-0x0000000000000000 8192 bpf_jit_binary_alloc+0x94/0x1f4 pages=1 vmalloc
0x0000000000000000-0x0000000000000000 8192 bpf_jit_binary_alloc+0x94/0x1f4 pages=1 vmalloc
0x0000000000000000-0x0000000000000000 8192 bpf_jit_binary_alloc+0x94/0x1f4 pages=1 vmalloc
0x0000000000000000-0x0000000000000000 8192 bpf_jit_binary_alloc+0x94/0x1f4 pages=1 vmalloc
0x0000000000000000-0x0000000000000000 8192 bpf_jit_binary_alloc+0x94/0x1f4 pages=1 vmalloc
0x0000000000000000-0x0000000000000000 8192 bpf_jit_binary_alloc+0x94/0x1f4 pages=1 vmalloc
0x0000000000000000-0x0000000000000000 8192 bpf_jit_binary_alloc+0x94/0x1f4 pages=1 vmalloc我们可以看到 vmalloc 区域大小都是页的整数倍,pages 表示使用了多少个物理页,显示的数目要 +1,例如pages为4,表示占用了 5个物理页。
当使用 ioremap 映射了由物理地址描述的物理内存区域时,会将物理地址保存在 phys_addr 成员中,ioremap 是把 IO 地址映射到内核空间,也就是不会使用系统 RAM 中的内存,也就不会调用 buddy 中的alloc_pages(),这部分不属于buddy,因此在 /proc/vmallocinfo 中看不到 pages 成员信息:
0x0000000000000000-0x0000000000000000 8192 jlq_pll_sha_setup+0x13c/0x380 phys=0x0000000034510000 ioremap
0x0000000000000000-0x0000000000000000 8192 jlq_pll_sha_setup+0x16c/0x380 phys=0x0000000034500000 ioremap
0x0000000000000000-0x0000000000000000 8192 jlq_clk_get_base+0xf8/0x2a8 phys=0x0000000034103000 ioremap
0x0000000000000000-0x0000000000000000 8192 jlq_clk_get_base+0x1fc/0x2a8 phys=0x00000000340ea000 ioremap
0x0000000000000000-0x0000000000000000 8192 jlq_clk_get_base+0xc4/0x2a8 phys=0x0000000030340000 ioremap
0x0000000000000000-0x0000000000000000 8192 jlq_clk_get_base+0x194/0x2a8 phys=0x0000000030090000 ioremap
0x0000000000000000-0x0000000000000000 8192 jlq_clk_get_base+0x1c8/0x2a8 phys=0x0000000030501000 ioremap
0x0000000000000000-0x0000000000000000 8192 jlq_clk_get_base+0x12c/0x2a8 phys=0x0000000030621000 ioremap
0x0000000000000000-0x0000000000000000 8192 jlq_clk_get_base+0x160/0x2a8 phys=0x0000000034459000 ioremap3.1.3 vmap_area
include/linux/vmalloc.hstruct vmap_area {unsigned long va_start;unsigned long va_end;struct rb_node rb_node; /* address sorted rbtree */struct list_head list; /* address sorted list *//** The following three variables can be packed, because* a vmap_area object is always one of the three states:* 1) in "free" tree (root is vmap_area_root)* 2) in "busy" tree (root is free_vmap_area_root)* 3) in purge list (head is vmap_purge_list)*/union {unsigned long subtree_max_size; /* in "free" tree */struct vm_struct *vm; /* in "busy" tree */struct llist_node purge_list; /* in purge list */};
};- va_start:vmalloc区域中的子区域的起始地址;
- va_end:与va_start 配对,指定该子区域的结束地址;
- rb_node:用以插入红黑树使用;
- list:用以插入list 链表使用;
- union:一个vmap_area 对象总是处于三种状态中的一种,用以记录当前的状态值;
4. __get_vm_area_node()
mm/vmalloc.cstatic struct vm_struct *__get_vm_area_node(unsigned long size,unsigned long align, unsigned long flags, unsigned long start,unsigned long end, int node, gfp_t gfp_mask, const void *caller)
{struct vmap_area *va;struct vm_struct *area;//vmalloc 不能再中断中被调用BUG_ON(in_interrupt());//vmalloc 要求页对齐size = PAGE_ALIGN(size);if (unlikely(!size))return NULL;if (flags & VM_IOREMAP)align = 1ul << clamp_t(int, get_count_order_long(size),PAGE_SHIFT, IOREMAP_MAX_ORDER);//step1//使用 kmalloc 分配一个vm_struct内存area = kzalloc_node(sizeof(*area), gfp_mask & GFP_RECLAIM_MASK, node);if (unlikely(!area))return NULL;//step2//如果vmalloc 没有设置VM_NO_GUARD这个flag,表示需要多加一页为安全区间if (!(flags & VM_NO_GUARD))size += PAGE_SIZE;//step3//申请一个vmap_area并将其插入vmap_area_root中//注意,通过ioremap申请时,align需要单独计算va = alloc_vmap_area(size, align, start, end, node, gfp_mask);if (IS_ERR(va)) { //----如果获取区域失败,则将slab area 进行free掉kfree(area);return NULL;}//step4//填充vmalloc描述符vm_struct中的成员setup_vmalloc_vm(area, va, flags, caller);return area;
}重点有四个逻辑处理:
- step1,kzalloc_node():最终会通过 kmalloc() 从slab 中分配一个vm_struct 的内存,最终也会将该内存作为 vmalloc() 描述符进行返回;
- step2,如果vmalloc() 的flag 没有指定VM_NO_GUARD,都会多分配一个PAGE;
- step3,alloc_vmap_area():申请一个vmap_area,详细见第 4.1 节;
- step4,setup_vmalloc_vm():对vmalloc() 描述符vm_struct 进行填充,详细见第 4.2 节;
4.1 alloc_vmap_area()
mm/vmalloc.cstatic struct vmap_area *alloc_vmap_area(unsigned long size,unsigned long align,unsigned long vstart, unsigned long vend,int node, gfp_t gfp_mask)
{struct vmap_area *va, *pva;unsigned long addr;int purged = 0;//进行一些提前判定,如果出错,则会进入panic//size不能为0//size不是以页对齐//align不是2的整数次幂BUG_ON(!size);BUG_ON(offset_in_page(size));BUG_ON(!is_power_of_2(align));//vmap是否已经初始化过if (unlikely(!vmap_initialized))return ERR_PTR(-EBUSY);might_sleep();//从 vmap_area_cachep 这个slab cache中分配出一个vmap_area 的内存va = kmem_cache_alloc_node(vmap_area_cachep,gfp_mask & GFP_RECLAIM_MASK, node);if (unlikely(!va))return ERR_PTR(-ENOMEM);/** Only scan the relevant parts containing pointers to other objects* to avoid false negatives.*/kmemleak_scan_area(&va->rb_node, SIZE_MAX, gfp_mask & GFP_RECLAIM_MASK);retry:/** Preload this CPU with one extra vmap_area object to ensure* that we have it available when fit type of free area is* NE_FIT_TYPE.** The preload is done in non-atomic context, thus it allows us* to use more permissive allocation masks to be more stable under* low memory condition and high memory pressure.** Even if it fails we do not really care about that. Just proceed* as it is. "overflow" path will refill the cache we allocate from.*/preempt_disable();if (!__this_cpu_read(ne_fit_preload_node)) {preempt_enable();pva = kmem_cache_alloc_node(vmap_area_cachep, GFP_KERNEL, node);preempt_disable();if (__this_cpu_cmpxchg(ne_fit_preload_node, NULL, pva)) {if (pva)kmem_cache_free(vmap_area_cachep, pva);}}spin_lock(&vmap_area_lock);preempt_enable();//分配 vmap_area,并在虚拟地址范围内找到映射空间//如果分配失败,则返回 vendaddr = __alloc_vmap_area(size, align, vstart, vend);if (unlikely(addr == vend))goto overflow;//分配成功,addr就是该区域的起始地址va->va_start = addr;va->va_end = addr + size;va->vm = NULL;//将该vmap_area插入到红黑树vmap_area_root和全局链表vmap_area_list中insert_vmap_area(va, &vmap_area_root, &vmap_area_list);spin_unlock(&vmap_area_lock);//确认起始地址是否符合align对齐方式BUG_ON(!IS_ALIGNED(va->va_start, align));//起始地址不能比VMALLOC_START小BUG_ON(va->va_start < vstart);//同样,区域的结尾地址不能比VMALLC_END 大BUG_ON(va->va_end > vend);return va;overflow:spin_unlock(&vmap_area_lock);if (!purged) {purge_vmap_area_lazy();purged = 1;goto retry;}if (gfpflags_allow_blocking(gfp_mask)) {unsigned long freed = 0;blocking_notifier_call_chain(&vmap_notify_list, 0, &freed);if (freed > 0) {purged = 0;goto retry;}}if (!(gfp_mask & __GFP_NOWARN) && printk_ratelimit())pr_warn("vmap allocation for size %lu failed: use vmalloc=<size> to increase size\n",size);kmem_cache_free(vmap_area_cachep, va);return ERR_PTR(-EBUSY);
}如上面代码注释,主要是从 vmalloc区域找到匹配该大小的子区域,成功找到就返回虚拟空间的起始地址,如果失败则返回 vend。
4.1.1 __alloc_vmap_area()
mm/vmalloc.cstatic __always_inline unsigned long
__alloc_vmap_area(unsigned long size, unsigned long align,unsigned long vstart, unsigned long vend)
{unsigned long nva_start_addr;struct vmap_area *va;enum fit_type type;int ret;va = find_vmap_lowest_match(size, align, vstart);if (unlikely(!va))return vend;if (va->va_start > vstart)nva_start_addr = ALIGN(va->va_start, align);elsenva_start_addr = ALIGN(vstart, align);/* Check the "vend" restriction. */if (nva_start_addr + size > vend)return vend;/* Classify what we have found. */type = classify_va_fit_type(va, nva_start_addr, size);if (WARN_ON_ONCE(type == NOTHING_FIT))return vend;/* Update the free vmap_area. */ret = adjust_va_to_fit_type(va, nva_start_addr, size, type);if (ret)return vend;#if DEBUG_AUGMENT_LOWEST_MATCH_CHECKfind_vmap_lowest_match_check(size);
#endifreturn nva_start_addr;
}4.2 setup_vmalloc_vm()
mm/vmalloc.cstatic void setup_vmalloc_vm(struct vm_struct *vm, struct vmap_area *va,unsigned long flags, const void *caller)
{spin_lock(&vmap_area_lock);vm->flags = flags;vm->addr = (void *)va->va_start;vm->size = va->va_end - va->va_start;vm->caller = caller;va->vm = vm;spin_unlock(&vmap_area_lock);
}该函数主要是用来配置 vm_struct,同时将 vm_struct 和 vmap_area 进行关联。
5. __vmalloc_area_node()
mm/vmalloc.cstatic void *__vmalloc_area_node(struct vm_struct *area, gfp_t gfp_mask,pgprot_t prot, int node)
{struct page **pages;unsigned int nr_pages, array_size, i;const gfp_t nested_gfp = (gfp_mask & GFP_RECLAIM_MASK) | __GFP_ZERO;const gfp_t alloc_mask = gfp_mask | __GFP_NOWARN;//当 gfp_mask没有指定 DMA 或DMA32时,设置为__GFP_HIGHMEM,优先使用高端内存const gfp_t highmem_mask = (gfp_mask & (GFP_DMA | GFP_DMA32)) ?0 :__GFP_HIGHMEM;//确认申请的实际size,不包括guard pagenr_pages = get_vm_area_size(area) >> PAGE_SHIFT;//pages 数组的空间大小array_size = (nr_pages * sizeof(struct page *));//如果pages数组占用空间超过PAGE_SIZE,则使用vmalloc区域的虚拟地址(一个page大概64字节,也就是申请超过256KB)//如果pages数组占用的空间没有超过,则使用kmalloc 从slab中申请if (array_size > PAGE_SIZE) {pages = __vmalloc_node(array_size, 1, nested_gfp|highmem_mask,PAGE_KERNEL, node, area->caller);} else {pages = kmalloc_node(array_size, nested_gfp, node);}//如果没有多余空间了,那么此次的vmalloc申请就此结束if (!pages) {remove_vm_area(area->addr);kfree(area);return NULL;}//成功申请到了pages数组的内存,进一步初始化vmap_areaarea->pages = pages;area->nr_pages = nr_pages;for (i = 0; i < area->nr_pages; i++) {struct page *page;//直接通过alloc_page()一次申请一个页面if (node == NUMA_NO_NODE)page = alloc_page(alloc_mask|highmem_mask);elsepage = alloc_pages_node(node, alloc_mask|highmem_mask, 0);if (unlikely(!page)) {/* Successfully allocated i pages, free them in __vunmap() */area->nr_pages = i;atomic_long_add(area->nr_pages, &nr_vmalloc_pages);goto fail;}area->pages[i] = page;if (gfpflags_allow_blocking(gfp_mask|highmem_mask))cond_resched();}//申请到的虚拟页面数量atomic_long_add(area->nr_pages, &nr_vmalloc_pages);//建立页面映射,该函数会调用到vmap_page_range_noflush()遍历页表和填充对应的页表if (map_vm_area(area, prot, pages))goto fail;return area->addr;fail:warn_alloc(gfp_mask, NULL,"vmalloc: allocation failure, allocated %ld of %ld bytes",(area->nr_pages*PAGE_SIZE), area->size);__vfree(area->addr);return NULL;
}5.1 map_vm_area()
mm/vmalloc.cint map_vm_area(struct vm_struct *area, pgprot_t prot, struct page **pages)
{unsigned long addr = (unsigned long)area->addr;unsigned long end = addr + get_vm_area_size(area);int err;err = vmap_page_range(addr, end, prot, pages);return err > 0 ? 0 : err;
}这里映射的是实际的分配大小,最终通过 vmap_page_range():
mm/vmalloc.cstatic int vmap_page_range(unsigned long start, unsigned long end,pgprot_t prot, struct page **pages)
{int ret;ret = vmap_page_range_noflush(start, end, prot, pages);flush_cache_vmap(start, end);return ret;
}----> vmap_page_range_noflush()
mm/vmalloc.cstatic int vmap_page_range_noflush(unsigned long start, unsigned long end,pgprot_t prot, struct page **pages)
{pgd_t *pgd;unsigned long next;unsigned long addr = start;int err = 0;int nr = 0;BUG_ON(addr >= end);pgd = pgd_offset_k(addr);do {next = pgd_addr_end(addr, end);err = vmap_p4d_range(pgd, addr, next, prot, pages, &nr);if (err)return err;} while (pgd++, addr = next, addr != end);return nr;
}- 有vm_struct 区域的起始地址 start 通过 pgd_offset_k() 可以找到 PGD页表项,然后遍历 PGD页表。
- vmap_p4d_range() 函数中,由 p4d_alloc() 函数找到 P4D页表项,然后遍历 P4D;
- vmap_pud_range() 函数中,由pud_alloc() 函数找到 PUD 页表项,然后遍历PUD;
- vmap_pmd_range() 函数中,由 pmc_alloc() 函数知道哦啊哦PMD 页表项,然后遍历PMD;
- vmap_pte_range() 函数中,由pte_alloc_kernel() 宏函数找到 PTE页表项,然后根据 area->pages 保存的每个物理页面来创建页表项。mk_pte() 宏利用刚分配的页面和页面属性prot 来生成一个页表项。最后通过 set_pte_at() 函数设置到实际的 PTE 中。
6. vmalloc() 的分配流程

7. vfree()
mm/vmalloc.cvoid vfree(const void *addr)
{BUG_ON(in_nmi());kmemleak_free(addr);might_sleep_if(!in_interrupt()); //如果不是在中断上下文中调用//则sleepif (!addr) //如果传入的虚拟地址为NULL,则不做任何处理return;__vfree(addr); //最终调用__vfree()接口
}
EXPORT_SYMBOL(vfree);7.1 __vfree()
mm/vmalloc.cstatic void __vfree(const void *addr)
{if (unlikely(in_interrupt()))__vfree_deferred(addr);else__vunmap(addr, 1);
}如果处于中断中调用 __vfree_deferred(),如果没有则调用 __vunmap() 进行回收。
在分析 __vunmap() 函数之前,需要了解 vmap() 和 vunmap()函数,这是一对用来对连续虚拟内存的分配、回收。
vmap() 与 vmalloc() 的操作,大部分的逻辑是一样的,例如从 VMALLOC_START ~ VMALLOC_END 区域查找并分配 vmap_area,例如对虚拟地址和物理页框进行映射管理的建立。不同之处,在于 vmap() 的参数是直接将 pages传入,而 vmalloc() 需要通过 alloc_page()向 buddy 申请。
vmap() 和vunmap() 下面会继续剖析,这里着重看下在中断处理中调用时的 __vfree_deferred():
mm/vmalloc.cstatic inline void __vfree_deferred(const void *addr)
{/** Use raw_cpu_ptr() because this can be called from preemptible* context. Preemption is absolutely fine here, because the llist_add()* implementation is lockless, so it works even if we are adding to* nother cpu's list. schedule_work() should be fine with this too.*/struct vfree_deferred *p = raw_cpu_ptr(&vfree_deferred);if (llist_add((struct llist_node *)addr, &p->list))schedule_work(&p->wq);
}当通过中断处理程序调用时,映射的连续虚拟地址内存无法立即释放,因此在工作队列中注册 free_work() 函数添加到每个 CPU vfree_deferred 中以进行延迟处理。
free_work() 这部分的设置是 vmalloc_init() 中完成,详细看第 1 节。
8. vmap()
mm/vmalloc.cvoid *vmap(struct page **pages, unsigned int count,unsigned long flags, pgprot_t prot)
{struct vm_struct *area;unsigned long size; /* In bytes *///如果有任务紧急请求重新安排作为抢占点,则需要休眠might_sleep();//如果请求的页数比total的页数多,则放弃处理并返回 NULLif (count > totalram_pages())return NULL;size = (unsigned long)count << PAGE_SHIFT;area = get_vm_area_caller(size, flags, __builtin_return_address(0));if (!area)return NULL;if (map_vm_area(area, prot, pages)) {vunmap(area->addr);return NULL;}return area->addr;
}
EXPORT_SYMBOL(vmap);经历了 vmalloc() 的分配流程,我们看到 vmap() 会将 page 指针数组通过参数的形式直接传入。
- pages:页面指针数组,同 struct vm_struct 中的 pages 成员;
- count:需要映射的页面数量,同 struct vm_struct 中的 nr_pages 成员;
- flags:同 struct vm_struct 中的 flags 成员;
- prot:为映射进行页面保护,同 __vmalloc() 中的 prot;
8.1 get_vm_area_caller()
mm/vmalloc.cstruct vm_struct *get_vm_area_caller(unsigned long size, unsigned long flags,const void *caller)
{return __get_vm_area_node(size, 1, flags, VMALLOC_START, VMALLOC_END,NUMA_NO_NODE, GFP_KERNEL, caller);
}同 vmalloc() 流程,同样指定从 VMALLOC_START ~ VMALLOC_END 中分配连续虚拟地址,gfp_mask 同样为 GFP_KERNEL。
函数 __get_vm_area_node() 详细见第 4 节。
8.2 map_vm_area()
详见上文第 5.1 节。
8.3 比较vmalloc()和vmap()
通过流程剖析之后我们发现 vmalloc() 和vmap() 的流程基本上是一样的。
- 需要经过 __get_vm_area_node() 创建 struct vm_struct 和 struct vmap_area,并从 VMALLOC区域根据 size 查找到一个空的子区域;
- 需要经过map_vm_area() 对连续虚拟地址和物理地址进行映射;
不同点在于:
- vmalloc() 需要从 buddy 系统每次申请 1个页面,放进struct vm_struct 中pages成员中;
- vmap() 参数自带pages,无需从 buddy 中申请;
9. vunmap()
mm/vmalloc.cvoid vunmap(const void *addr)
{BUG_ON(in_interrupt());might_sleep();if (addr)__vunmap(addr, 0);
}
EXPORT_SYMBOL(vunmap);vunmap() 执行的是跟 vmap() 相反的过程,从 vmap_area_root / vmap_area_list 中查找 vmap_area 区域,取消页表映射,再从 vmap_area_root / vmap_area_list 中删掉 vmap_area,页面返回给 buddy 系统。由于映射关系有改动,因此还需要进行 TLB 的刷新,频繁的 TLB 刷新会降低性能,因此将其延迟进行处理,称为 lazy tlb。
注意,
- vunmap() 是不允许在中断处理程序中调用。
- vunmap() 进行回收时,无需释放物理页面,而vfree() 是需要释放页面的;
9.1 __vunmap()
mm/vmalloc.cstatic void __vunmap(const void *addr, int deallocate_pages)
{struct vm_struct *area;if (!addr)return;if (WARN(!PAGE_ALIGNED(addr), "Trying to vfree() bad address (%p)\n",addr))return;//从vmap_area_root红黑树中查到vmap_area,从而获取vm_structarea = find_vm_area(addr);if (unlikely(!area)) {WARN(1, KERN_ERR "Trying to vfree() nonexistent vm area (%p)\n",addr);return;}debug_check_no_locks_freed(area->addr, get_vm_area_size(area));debug_check_no_obj_freed(area->addr, get_vm_area_size(area));//去掉映射关系的核心函数vm_remove_mappings(area, deallocate_pages);//对于 vfree,需要将vmalloc时申请的内存释放掉if (deallocate_pages) {int i;for (i = 0; i < area->nr_pages; i++) {struct page *page = area->pages[i];BUG_ON(!page);__free_pages(page, 0);}atomic_long_sub(area->nr_pages, &nr_vmalloc_pages);kvfree(area->pages);}//释放vm_struct所占用的内存kfree(area);return;
}该函数是vunmap() 和vfree() 函数的实现函数,主要分四个部分:
- 通过find_vm_area() 函数,根据虚拟地址从 vmap_area_root 红黑树中查询到该子区域 vmap_area,并根据该子区域得到 vm_struct;
- 通过vm_remove_mappings() 函数,解除一切关系。如映射关系、vmap_area_root / vmap_area_list 中的区域印记等;
- 通过变量 deallocate_pages,确认源头是从vunmap() 还是 vfree(),进而确认是否将area->pages 内存释放,对于 vfree() 调用,是需要释放内存的;
- 释放 vm_struct 所占用内存;
10. vunmap()释放流程
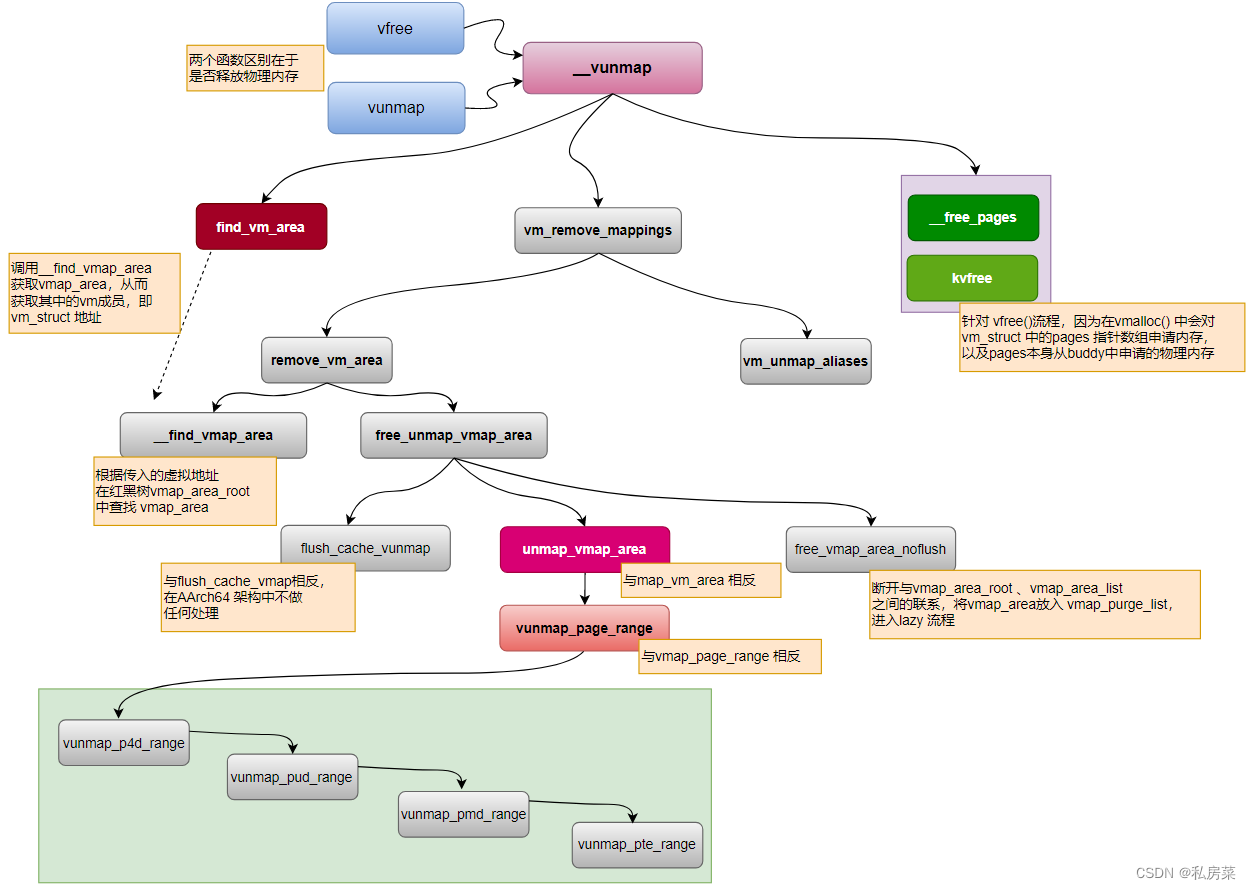
至此,vmalloc 分配、释放流程已基本剖析完成,下面来总结下:
- vmalloc() 与 kmalloc() 性质不同的两种分配内存的函数,kmalloc() 基于 slab分配器,分配的内存物理地址连续,虚拟地址也连续;而vmalloc() 是从 VMALLOC_START ~ VMALLOC_END 区域中选择一个适合 size 的空的子区域,虚拟地址连续而物理地址不连续(每次物理page只能申请1个);
- vmalloc() 是页对齐申请内存,通过alloc_page()向buddy申请内存时的order 为0;
- kmalloc() 可以申请物理连续内存,且映射是线性的,所以分配的速度上会更快,但是这样会造成碎片化问题,让碎片化管理变得困难;而 vmalloc() 是虚拟内存连续,所以每次需要跟物理page 一页一页的进行映射,造成vmalloc() 的效率不是很高;
- kmalloc() 一般在小内存时使用,vmalloc() 一般在大内存是使用;
- vmalloc() 分配过程中可以睡眠,因此不能用于中断上下文中;
- vmalloc() 与 vmap() 相比只多了个向buddy 申请物理page的过程,而vmap() 是将物理pages作为参数带入;
- 因为vmalloc() 与 vmap() 申请的流程有所差异,所以vfree() 和 vunmap() 的流程略微有区别,主要是体现在vfree() 需要对从buddy 申请来的pages 进行释放;