快速排序
- 前言
- 图解
- 大致思路
- 对于hoare版本
- 对于挖坑法
- 对于前后指针法
- 实现方法
- 递归
- 非递归
- 快排的优化(基于递归的优化)
- 三数取中法
- 小区间优化
- 时间复杂度和空间复杂度

前言
快速排序,听名字就比较霸道,效率根名字一样,非常的快,但也还是O(N * logN)级别的。
我所学到的快排有三个版本:
- 原始版本hoare版本,也就是hoare这个人发明的
- 基于hoare版本改进的版本,挖坑法(还有别的叫法,我这里就说成挖坑法了)。
- 是跟上面两种方法不一样的方法,前后指针法。
这里讲之前跟我前面的博客一样,先给图解。
图解
首先hoare版本的:

挖坑法

前后指针法
大致思路
首先,快排讲的是一个分治的思想,什么叫分治呢,根二叉树的前序遍历一样,先处理根,再处理左树和右树。那么快排也就是这样,先处理当前的(定关键字key的位置),然后再处理左半边的,后右半边的。
那这里的关键字key是什么呢?其实就是每趟排序的时候,首先选出来的一个数(一般选择最左端或者最右端),这个数决定了你是从左往右排还是从右往左排,什么意思呢?
对于hoare版本
当你的key选取在最左端时,就先让R(right)先走,R找小,找到了之后再让L(L找大)走。
当你的key选取在最右端时,就先让L(left)先走,L找大,找到了之后再让R(R找小)走。
这样能够保证L能和R相遇
下面以key在最左端为例
此时会出现以下情况:当R找到小的了,L也找到大的了,就让两个位置上的数交换。再让R走,找小,找到了停,L找大,重复上述步骤。
当R和L相遇时,就将key位置上的数与相遇位置的数交换位置。本趟排序结束。
然后就开始递归,递归排序相遇位置的左边和相遇位置的右边。
对于挖坑法
当你的key选取在最左端时,就先让R(right)先走,R找小
当你的key选取在最右端时,就先让L(left)先走,L找大
此时key位置就是坑的位置
这样能够保证L能和R相遇,根hoare版本一样
下面以key在最左端为例
此时会出现以下情况:当R找到小的了,就直接把R的值放到原坑中,R位置作为新的坑,再让L先走,找大,找到大的,将L的值放到原坑中,L位置作为新坑,不断重复上述步骤。
当R和L相遇,相遇位置的数放到原坑中,相遇位置作为新坑,将key的值放到新坑中。本趟排序结束
然后就开始递归,递归排序相遇位置的左边和相遇位置的右边。根hoare相似。
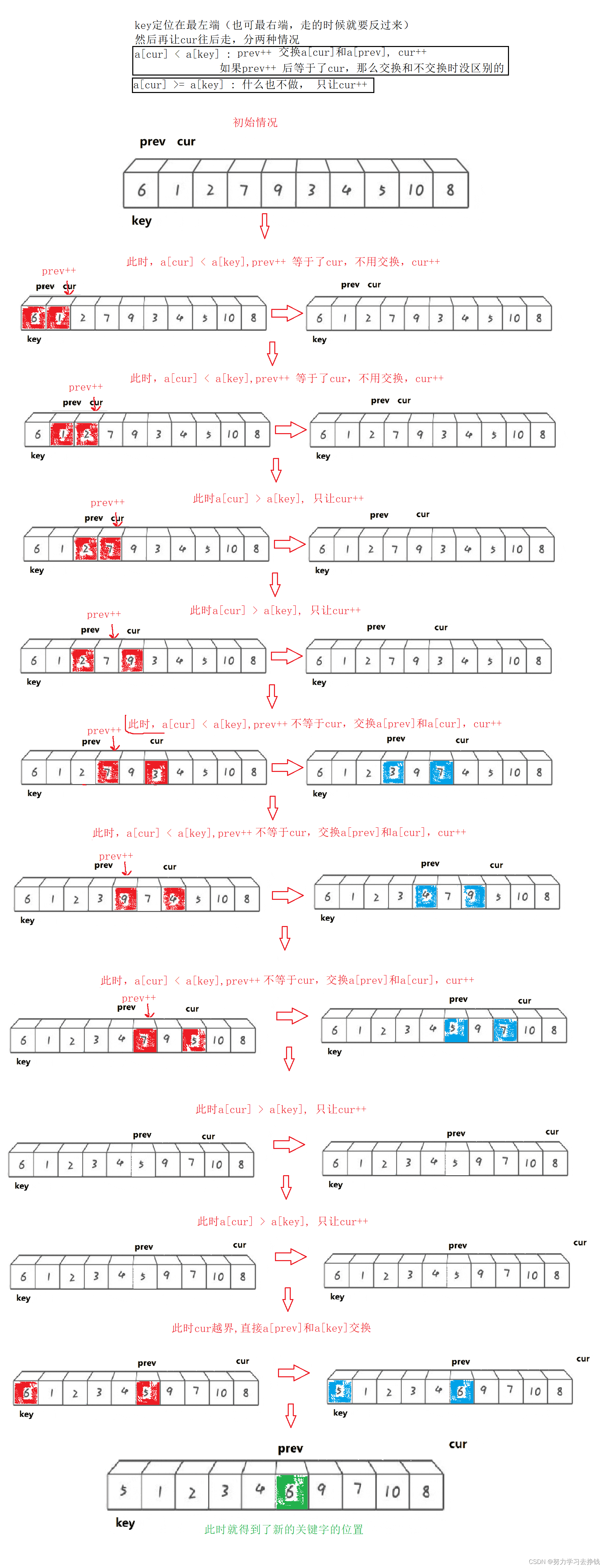
对于前后指针法
当你的key选取在最左端时,就让cur从左往右走
当你的key选取在最右端时,就让cur从右往左走
下面以key在最左端为例
此时会出现以下情况:当cur位置上的数小于key时,prev++,交换cur和prev上的数,cur++
当cur位置上的数大于等于key时,prev什么也不做,cur++
直至cur越界,再交换key和prev位置上的数。本趟排序结束。
记下cur越界时prev的位置。
然后就开始递归,递归排序该位置的左和该位置的右。
实现方法
递归
hoare版本的单趟
//hoare版本
int PartSort1(int* a, int left, int right)
{int keyi = left;while (left < right){//right找小 等于的时候也得走,不然程序会崩掉,这里是个易错点while (left < right && a[right] >= a[keyi]){right--;}//left找大 等于的时候也得走,不然程序会崩掉,这里是个易错点while (left < right && a[left] <= a[keyi]){left++;}//找到了就交换,或者二者相遇,同一个位置交换不交换都是一样的swap(&a[left], &a[right]);}//相遇swap(&a[left], &a[keyi]);keyi = left;//返回相遇的位置,keyi、left和right都可以return keyi;
}
挖坑法的单趟
//挖坑法
int PartSort2(int* a, int left, int right)
{int key = a[left];while (left < right){//right找小while (left < right && a[right] >= key){right--;}//找到了把数放到原坑,right做新坑,相遇的时候也不影响a[left] = a[right];//left找大while (left < right && a[left] <= key){left++;}//找到了把数放到原坑,left做新坑,相遇的时候也不影响a[right] = a[left];}//相遇的位置放keya[left] = key;//返回相遇的位置return left;
}
前后指针法的单趟
//前后指针法
int PartSort3(int* a, int left, int right)
{int keyi = left;int previ = left;int curi = previ + 1;while (curi <= right){//小了并且previ+1不等于curi再交换if (a[curi] < a[keyi] && ++prev != curi))swap(&a[previ], &a[curi]);curi++;}swap(&a[previ], &a[keyi]);return previ;
}
全趟排序
上面三个的代码只是单趟的排序,还要放到整体的排序中:
//快排
void QuickSort(int* a, int begin, int end)
{if (begin >= end)return;//hoare//int keyi = PartSort1(a, begin, end);//挖坑法//int keyi = PartSort2(a, begin, end);//前后指针法int keyi = PartSort3(a, begin, end);QuickSort(a, begin, keyi - 1);QuickSort(a, keyi + 1, end);
}
上面的就是三种方法的代码了。
非递归
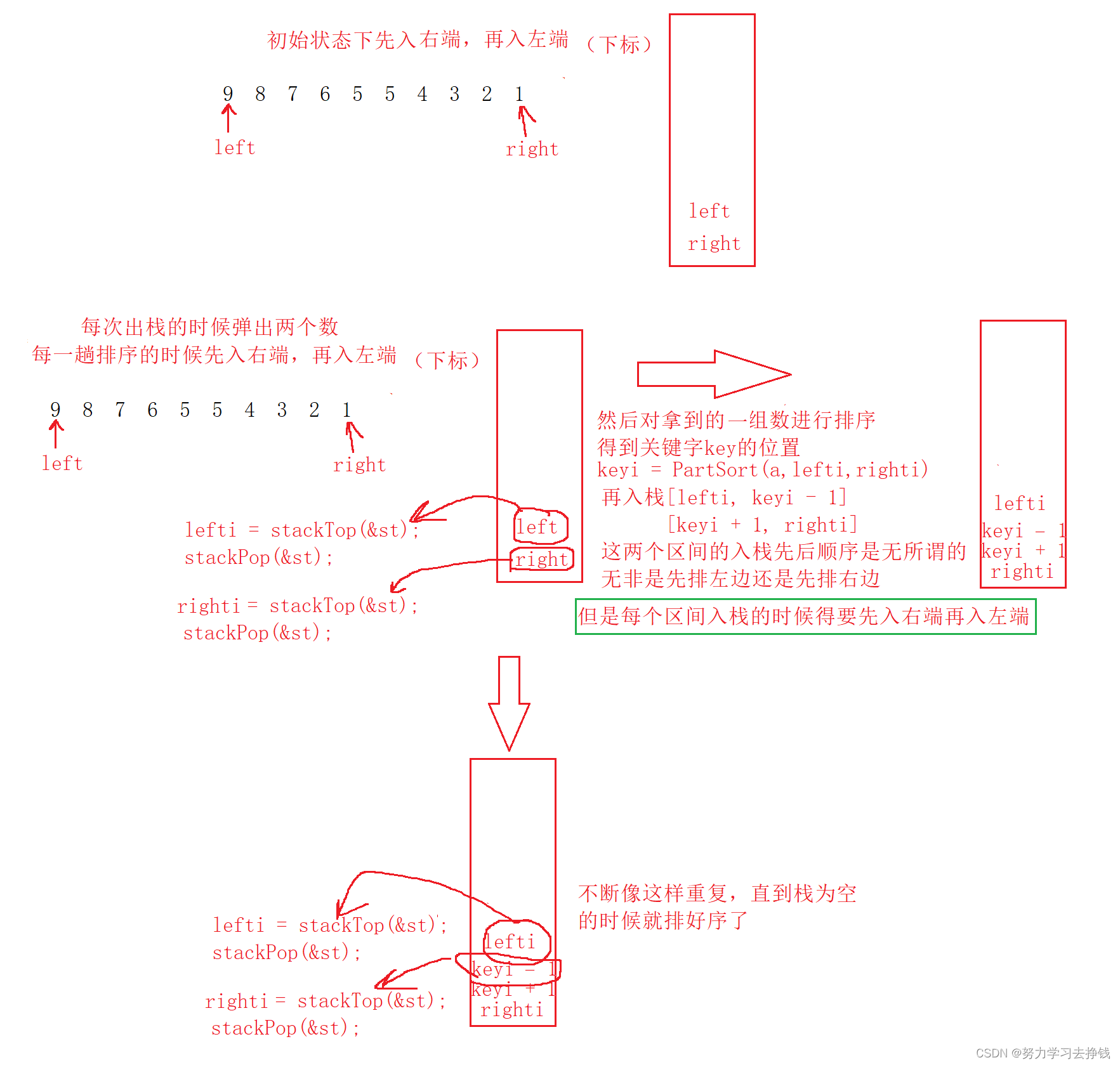
非递归的话,得要用到栈。
图解:
代码实现:
//快排非递归
//快排非递归
void QuickSortNonR(int* a, int begin, int end)
{Stack st;StackInit(&st);//初始情况下就入左右两端//先入右边再入左边StackPush(&st, end);StackPush(&st, begin);//栈不为空才继续循环while (!StackEmpty(&st)){//取左int lefti = StackTop(&st);StackPop(&st);//取右int righti = StackTop(&st);StackPop(&st);//得关键字位置int keyi = PartSort3(a, lefti, righti);//区间存在才入栈if (lefti < keyi - 1){//先入右边再入左边StackPush(&st, keyi - 1);StackPush(&st, lefti);}//区间存在才入栈if (righti > keyi + 1){//先入右边再入左边StackPush(&st, righti);StackPush(&st, keyi + 1);}}}
快排的优化(基于递归的优化)
三数取中法
上面递归的三个单趟排序其实是可以再优化一下的(以升序为例),因为当数组有序的时候每次选择key时,选出来的都是最小值,这时候key最终放的位置就是最左端,而递归的时候需要把key的左端和key的右端继续排,然而此时key处于最左端,那么递归排别的段的时候就只能排key的右端了,这个时候就相当于是排一次去处一个数,那么就变成了N,N-1,N-2,…2,1,时间复杂度就会变成O(N^2),就相当于是冒泡排序了。这样的话快排就排的不快了。
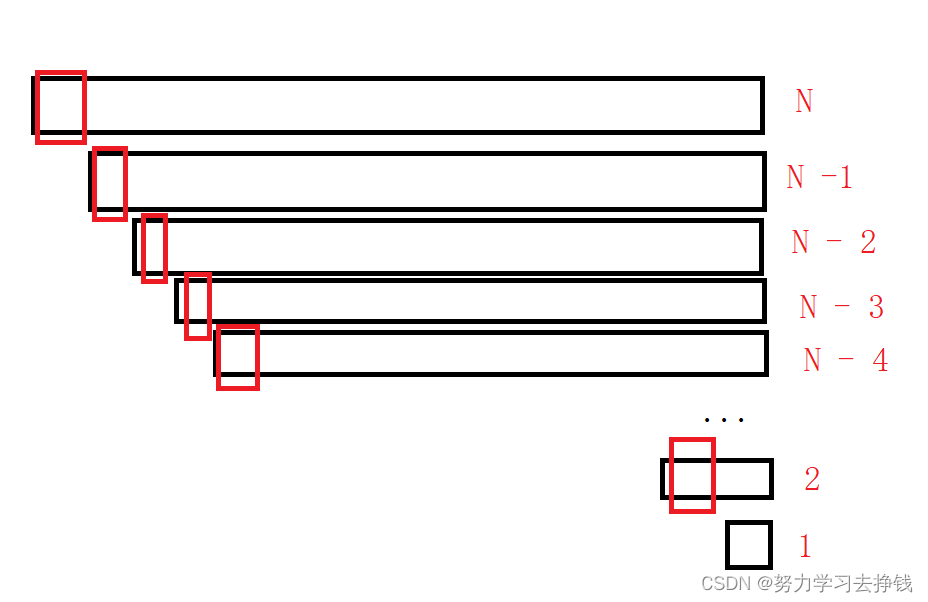
但我们所希望的是这样的:
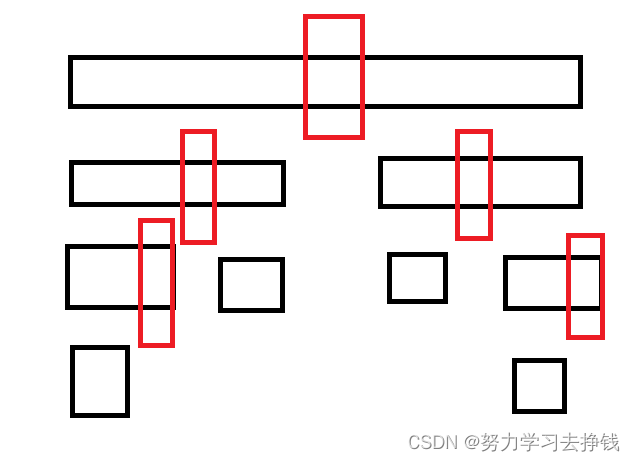
怎么做呢?
虽然我们不能取到所有有序的数中最中间的数,但是我们可以取到所有无序的数中位于最中间的数,每次排序前把这个数和左右两端的数比较以下,求出值为三者中不大也不小的那个数,然后再把这个数放到最前面,就可以实现类似于图二的方法,虽然做不到完全二分,但是也比图一强。
三数取中
int GetMid(int* a, int left, int right)
{int mid = (left + right) / 2;if (a[left] < a[mid]){if (a[right] > a[mid])return mid;else if (a[right] < a[left])return left;elsereturn right;}else//a[left] >= a[mid]{if (a[right] > a[left])return left;else if (a[right] < a[mid])return mid;elsereturn right;}
}然后把这个函数放在每一个单趟排序函数的最前面就行。
hoare版本的优化
//hoare版本
int PartSort1(int* a, int left, int right)
{//三数取中优化int mid = GetMid(a, left, right);swap(&a[left], &a[mid]);int keyi = left;while (left < right){//right找小 等于的时候也得走,不然程序会崩掉,这里是个易错点while (left < right && a[right] >= a[keyi]){right--;}//left找大 等于的时候也得走,不然程序会崩掉,这里是个易错点while (left < right && a[left] <= a[keyi]){left++;}//找到了就交换,或者二者相遇,同一个位置交换不交换都是一样的swap(&a[left], &a[right]);}//相遇swap(&a[left], &a[keyi]);keyi = left;//返回相遇的位置,keyi、left和right都可以return keyi;
}
挖坑法的优化
//挖坑法
int PartSort2(int* a, int left, int right)
{//三数取中优化int mid = GetMid(a, left, right);swap(&a[left], &a[mid]);int key = a[left];while (left < right){//right找小while (left < right && a[right] >= key){right--;}//找到了把数放到原坑,right做新坑,相遇的时候也不影响a[left] = a[right];//left找大while (left < right && a[left] <= key){left++;}//找到了把数放到原坑,left做新坑,相遇的时候也不影响a[right] = a[left];}//相遇的位置放keya[left] = key;//返回相遇的位置return left;
}
前后指针法的优化
//前后指针法
int PartSort3(int* a, int left, int right)
{//三数取中优化int mid = GetMid(a, left, right);swap(&a[left], &a[mid]);int keyi = left;int previ = left;int curi = previ + 1;while (curi <= right){//小了并且previ+1不等于curi再交换if (a[curi] < a[keyi] && ((previ + 1) != curi))swap(&a[previ], &a[curi]);curi++;}swap(&a[previ], &a[keyi]);return previ;
}
小区间优化
小区间优化的作用在于当数据量比较大时,递归可能会导致栈溢出。
而快排递归的时候是类似于二叉树的,所以最后一层递归所开辟的空间基本上要占用总空间的一半(完全二分的情况下),这个时候如果我们控制一下最后一层,不让这一层的数递归排序,就可以很好地避免栈溢出的问题。
怎么做呢。很简单,判断一下当递归某一区间段的时候(右端下标 - 左端下标 < X(X可取10~20之间的数)),这时候就可以用一下别的排序,而10~20的数据量还是很小的,所以不需要用比较复杂的排序,用一个N^2级别的排序就可以了,而N^2级别的排序中插入排序就是最好的,所以这时候替换成插入排序就可以了。
小区间优化
//快排
void QuickSort(int* a, int begin, int end)
{if (begin >= end){return;}else if (end - begin + 1 <= 10){//小区间优化InsertSort(a + begin, end - begin + 1);}else{//int keyi = PartSort1(a, begin, end);//int keyi = PartSort2(a, begin, end);int keyi = PartSort3(a, begin, end);QuickSort(a, begin, keyi - 1);QuickSort(a, keyi + 1, end);}}
时间复杂度和空间复杂度
我这里之说优化之后的。
时间复杂度就是O(N* logN),空间复杂度是O(logN)。
就说一下空间复杂度,因为快排是基于分治思想的,而且递归排序的过程类似于二叉树的前序遍历,所以在栈上开辟空间时就要不断的堆栈,然后当函数递归达到最大深度(二叉树的最下面一层)的时候,也就是logN,函数返回,最深层的函数系统就会自动回收空间,这时候就不会再开辟更大的空间了,而且开辟的空间是慢慢的缩小再增大,再减少,再增大。。。直到排序结束。所以空间开辟的时候最大也就开辟logN大小的空间。
到此结束。。。