文章目录
- python爬虫--爬取91看剧网电视剧
- 爬取视频必备知识
- 思路
- 代码
- 合并视频
python爬虫–爬取91看剧网电视剧
爬取视频必备知识
https://www.91kanju.com/vod-play/54812-1-2.html
思路
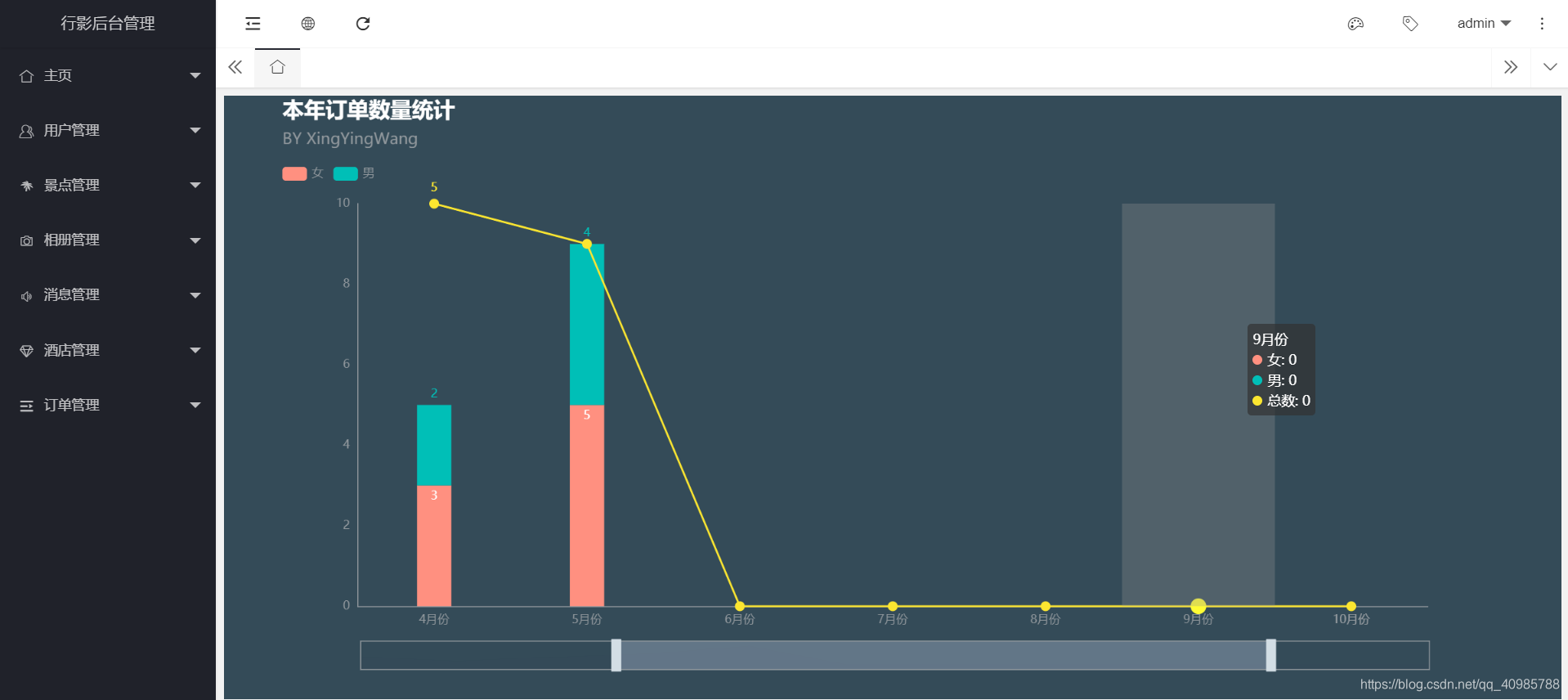
查看网页源代码;发现m3u8的URL

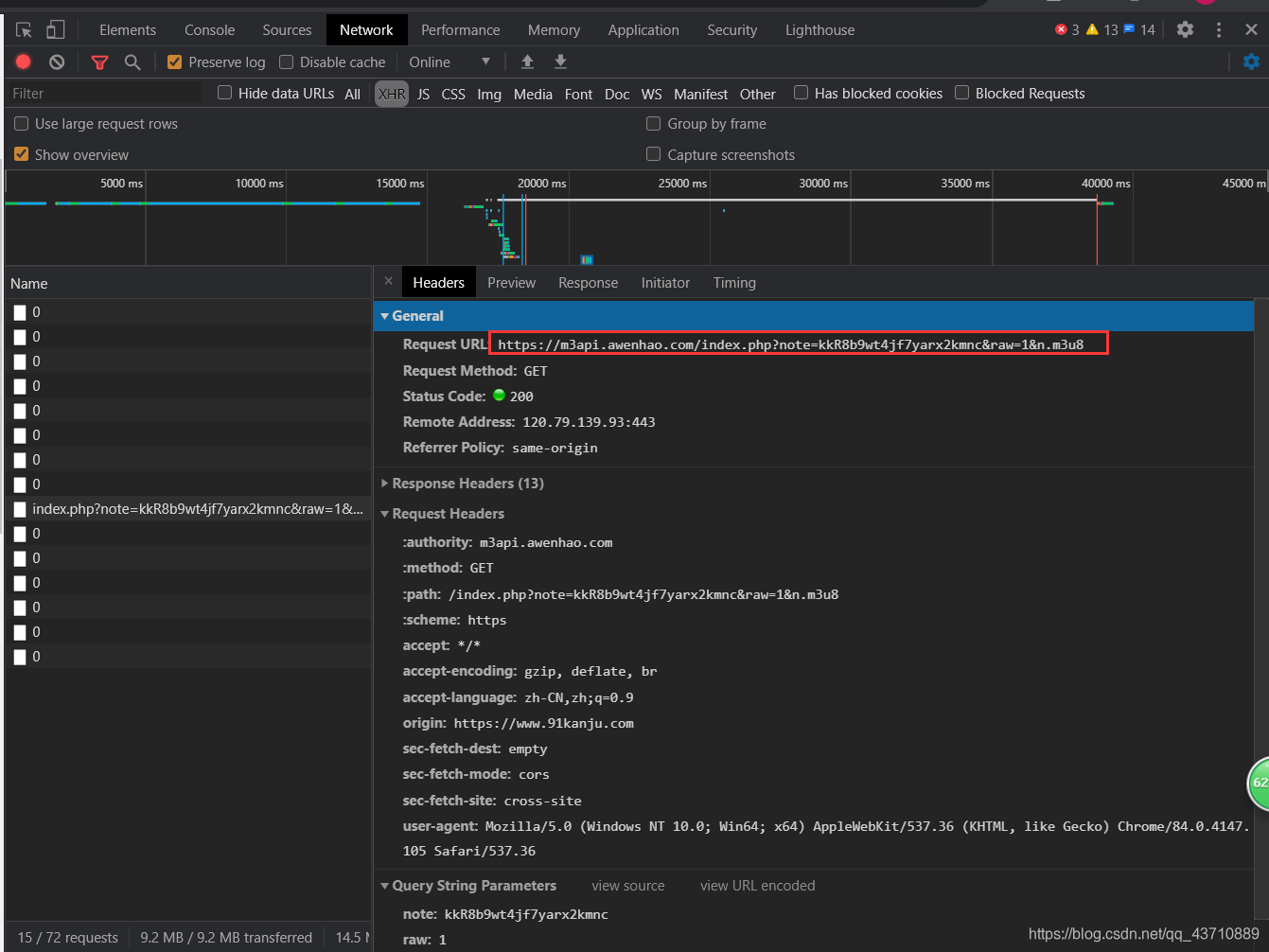
找到ts文件存在的位置:

代码
import requests
import re
#
# obj = re.compile(r"url: '(?P<url>.*?)',",re.S)
# url = 'https://www.91kanju.com/vod-play/54812-1-2.html'
#
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.105 Safari/537.36'}
#
# resp = requests.get(url=url,headers=headers).text
#
# m3u8_url = obj.search(resp).group("url")
#
# print(m3u8_url)
#
# #下载m3u8文件
#
# resp2 = requests.get(url=m3u8_url,headers=headers)
# with open("哲仁王后.m3u8",mode='wb') as fp:
# fp.write(resp2.content)
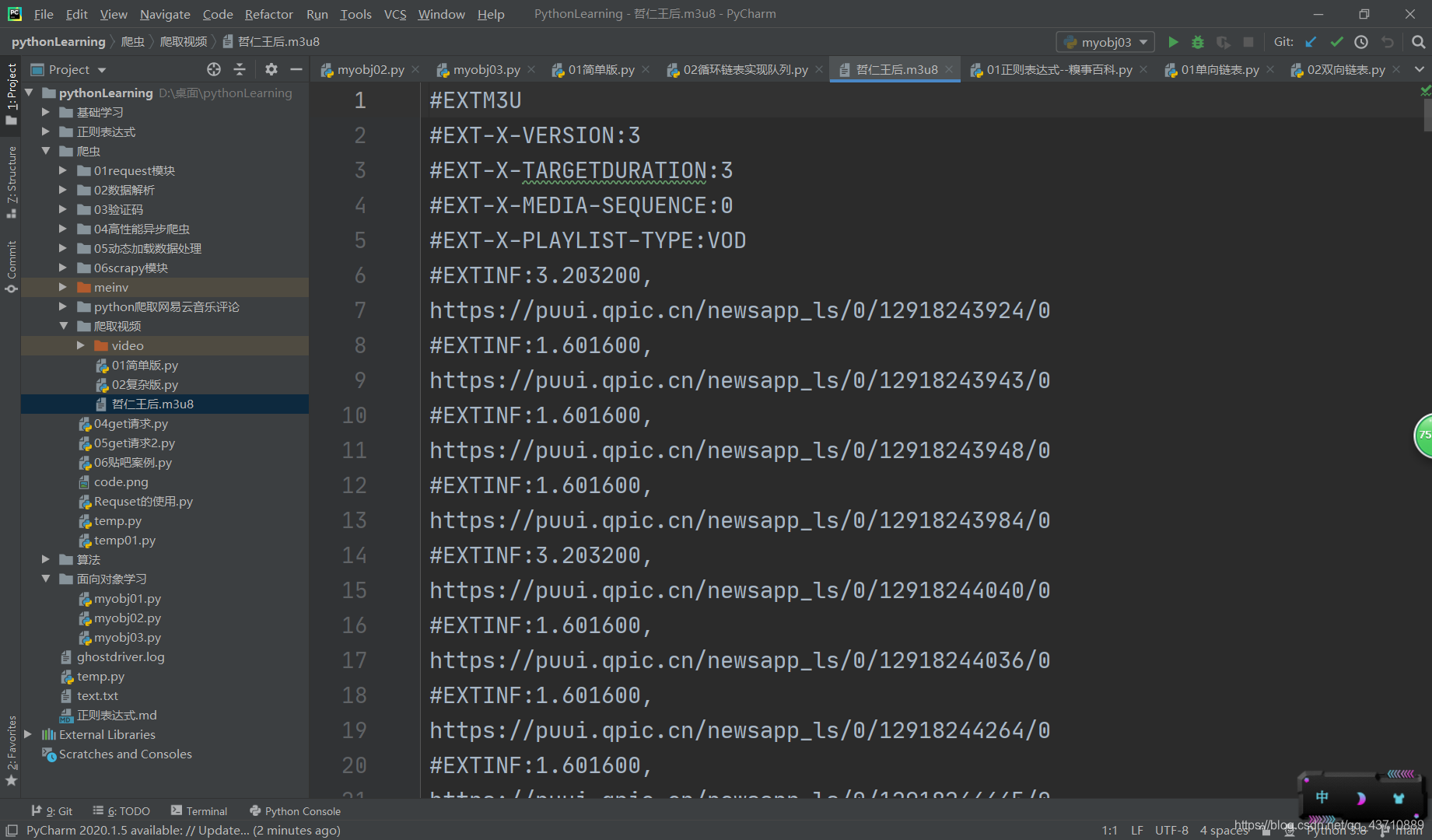
#本地缓存到m3u8文件后将上面注释掉
n = 1
with open("哲仁王后.m3u8",mode='r',encoding='utf-8') as fp:for line in fp:line = line.strip()if line.startswith("#"):continueif n<10:temp = '0' + '0' + str(n)elif 10<=n<100:temp = '0' + str(n)resp3 = requests.get(url=line,headers=headers)f = open(f"video/{temp}.ts",mode='wb')f.write(resp3.content)f.close()resp3.close()n+=1print(temp)
合并视频
可以使用第三方软件。片段少的话可以使用window自带的合并功能。
打开CMD
例子:
copy/b D:\video\*.ts D:\new.mp4