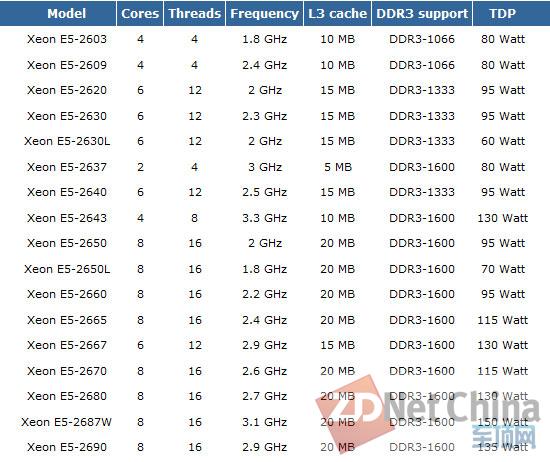
作为一名工程师,一名做技术的工程师,NUMA也是我的近期工作重点之一。在工作时间,在茶余饭后,也看了些NUMA的资料,学习了英特尔下一代Xeon处理器。这里就是我的一点小结,一点心得,和感兴趣的朋友分享分享。
因时间有限,每次就总结一部分,慢慢道来,欲知详情,下回分晓!
一、概述
从系统架构来说,目前的主流企业服务器基本可以分为三类:SMP (Symmetric Multi Processing,对称多处理架构),NUMA (Non-Uniform Memory Access,非一致存储访问架构),和MPP (Massive Parallel Processing,海量并行处理架构)。三种架构各有特点,本文将重点聊聊NUMA。
为了了解NUMA,我这里就介绍一下NUMA与其他两种Non-NUMA的主要区别。
1.SMP(Symmetric Multi Processing)
SMP是非常常见的一种架构。在SMP模式下,多个处理器均对称的连接在系统内存上,所有处理器都以平等的代价访问系统内存。它的优点是对内存的访问是平等、一致的;缺点是因为大家都是一致的,在传统的 SMP 系统中,所有处理器都共享系统总线,因此当处理器的数目增多时,系统总线的竞争冲突迅速加大,系统总线成为了性能瓶颈,所以目前 SMP 系统的处理器数目一般只有数十个,可扩展性受到很大限制。
2.MPP (Massive Parallel Processing)
MPP则是逻辑上将整个系统划分为多个节点,每个节点的处理器只可以访问本身的本地资源,是完全无共享的架构。节点之间的数据交换需要软件实施。它的优点是可扩展性非常好;缺点是彼此数据交换困难,需要控制软件的大量工作来实现通讯以及任务的分配、调度,对于一般的企业应用而言过于复杂,效率不高。
3.NUMA(Non-Uniform Memory Access)
NUMA架构则在某种意义上是综合了SMP和MPP的特点:逻辑上整个系统也是分为多个节点,每个节点可以访问本地内存资源,也可以访问远程内存资源,但访问本地内存资源远远快于远程内存资源。它的优点是兼顾了SMP和MPP的特点, 易于管理,可扩充性好;缺点是访问远程内存资源的所需时间非常的大。
在实际系统中使用比较广的是SMP和NUMA架构。像传统的英特尔IA架构就是SMP,而很多大型机采用了NUMA架构。
现在已经进入了多核时代,随着核数的越来越多,对于内存吞吐量和延迟有了更高的要求。正是考虑到这种需求,NUMA架构出现在了最新的英特尔下一代Xeon处理器中。
做为英特尔下一代的45nm Xeon处理器, 它会成为未来英特尔从台式机、笔记本到服务器全线产品的主流处理器。 比较前一代酷睿处理器平台,它的平台在对以前的系统架构和内存层次体系进行了重大改变的同时,对微架构也进行了全方位的细化, 主要改进表现在以下的特性:
> 新的核心架构,最大可扩展到每个接口4个核心
> 同步多线程(SMT) 技术最大允许每个处理器可以运行8个线程
> 最新的点到点直连架构:Intel® QuickPath Interconnect (Intel® QPI)技术
> Intel® QuickPath 集成内存控制器(IMC),DDR3接口
> 微架构功能的改进,包括增强的SSE4.2指令集,改进的锁定支持,循环流和分支预测等特性
> 更好的节能特性
下面详细介绍一下下一代Xeon处理器四大主要技术:
> Intel® QuickPath Interconnect (Intel® QPI)技术
使用QPI架构代替了原来的FSB架构,QPI是基于数据包传输,高带宽低延迟的点到点传输技术,速度可以达到6.4GT/s,对双向传输的QPI总线连接来说理论最大值可以达到25.6GB/s的数据传输,远远高于原来基于FSB架构的数据带宽。
> Intel® QuickPath 集成内存控制器(IMC)
在每一个socket上集成了独立的DDR3内存控制器(IMC)供接口访问内存,较之非IMC的平台,大大提高了带宽(使用DDR3-1333可以达到32GB/s的峰值带宽,较之以前的平台具有四到六倍的带宽提升),显著地降低了内存延迟,从而提升了性能,为每个CPU提供了访问本地内存资源的快速通道。与前一代平台不同的是,内存访问采用NUMA架构,对于NUMA-aware的应用来说可以得到更大的性能提升。DDR3的IMC最大支持到每个CPU接口96GB的DDR3内存容量,将来最大容量可以达到144GB,为高端的企业运算提供了强有力的内存支持。
同志们,NUMA在这就闪亮登场了!
> 改进的电源管理
集成在芯片上的电源管理使得能耗的控制更加高效。
> 同步多线程技术(SMT)
同步多线程技术使得每个核心可以同时执行2个线程,所以对于4核的CPU来说,就可以在每个处理器芯片上达到最大8个逻辑处理器。
前面介绍了NUMA的很牛的架构,那目前系统层面上,软件对NUMA的支持怎么样呢?请见本文:NUMA架构软件支持栈
对于NUMA架构而言,经过了几十年的发展,目前的软件支持栈已经非常完备,从底层的操作系统,到之上的数据库、应用服务器,基本所有主流的产品均以为NUMA提供了充分的支持。
操作系统(Operating System)
目前,Windows Server 2003 和Windows XP 64-bit Edition, Windows XP等都是NUMA aware的,而Windows Vista则有了对Numa调度的支持。所有使用2.6版本以上kernel的Linux操作系统都能够支持NUMA。而Solaris,HP-Unix等UNIX操作系统也是充分支持NUMA架构的。
数据库(Database)
对于数据库产品来说,Oracle从8i开始支持NUMA,而之后的Oracle9i,Oracle10g,Oracle11g都能够支持NUMA。SQL Server 2005 和SQL Server 2008均有效的提供了对NUMA的支持。
中间件服务器(Middleware)
目前业界典型的受控程序主要是Java应用和.Net应用。由于内存分配,线程调度对于应用而言是透明的,完全是由虚拟机来处理。因此它们在NUMA环境下的性能表现主要取决于虚拟机的实现是否能充分利用到底层操作系统对NUMA的支持。
综上所述,目前的软件栈对NUMA架构均已经作了充分的支持。那么应用软件如何支持NUMA架构呢?请见下面章节的论述。
在传统SMP系统上,所有CPU都以同样的方式通过一个共享内存控制器来访问内存,各CPU之间也是通过它来进行交流,所以很容易造成拥堵。而一个内存控制器所能够管理的内存数量也是非常有限的。此外,通过唯一的hub访问内存造成的延迟也是非常高的。
在NUMA结构下,每个计算机不再只有唯一的内存控制器,而是把整个系统分成多个节点。每个节点分别有自己的处理器和内存。系统中所有的节点都通过全互联的方式连接。所以,每当在系统中增加新的节点,系统所能够支持的内存和带宽都会增加,具有非常好的扩展性。
下面就讲讲NUMA的内存组织
在NUMA系统中,每个CPU可以访问两种内存:本地内存(Local Memory)和远端内存(Remote Memory)。和CPU在同一个节点的内存称为本地内存,访问延迟非常低。和CPU在不同节点上的内存叫做远端内存,CPU需要通过节点互联方式访问,所以访问延迟要比访问本地内存长。
从软件的角度来看,远端内存和本地内存是以同样的方式访问的。理论上讲,NUMA系统可以被软件视为与SMP同样的系统,不区分本地和远端内存。但是如果追求更好的性能,这个区别还是需要被考虑的。
经实验,对于常规的内存操作,如清空(Memset),块复制(Memcpy),流读写(Stream),指针追溯(Pointer Chase)等操作来说,本地内存的访问速度要远远优于远端内存。
由于 NUMA 同时使用本地内存和远端内存,因此,访问某些内存区域的时间会比访问其他内存区域的要长。本地内存和远端内存通常用于引用当前正在运行的线程。本地内存是指与当前正在运行线程的 CPU 位于同一节点上的内存。任何不属于当前正在运行的线程所在的节点的内存均为远端内存。访问远端内存的开销与访问本地内存的开销比率称为 NUMA 比率。如果 NUMA 比率为 1,则它是对称多处理 (SMP)。比率越高,访问其他节点内存的开销就越大。不支持 NUMA 的 应用程序有时在 NUMA 硬件上的执行效果非常差。
由于访问本地内存和远端内存的开销是有区别的,所以在NUMA模式下,如果每个线程更多的是访问本地内存,那么性能相比而言会有一定提升。
多谢各位的参与和支持,让我更有动力去把这个系列写好。前面有同学问起了QPI,我这里就详细解释一下,而QPI也是下一代Xeon处理器的特性之一。
QPI全称Intel® QuickPath Interconnect,是直接连接同一台机器的不同CPU之间的传输通道,使得各个核(CORE)之间的数据传输更快:如果数据在cache里,就可以直接用QPI来传输,而不用再访问内存了。
下一代Xeon处理器使用QPI架构代替了原来的FSB架构,QPI是基于数据包传输,高带宽低延迟的点到点传输技术,速度可以达到6.4GT/s,远远高于原来基于FSB架构的数据带宽。当然,具体平台的实现中QPI连接数目可以根据目标市场和系统复杂性而有所不同,表现出极大的灵活性和扩展性。
又有同学可能要问,那同一个CPU内的不同的核怎么交换数据呢?这就更简单了。下一代Xeon处理器的不同核是存在cache共享的,这样如果数据在cache里,那就直接共享了,不用再到内存里找,简单吧,呵呵
接下来讲讲NUMA策略,也就是为了更好的利用NUMA来给咱们干活:
为描述在NUMA架构下针对内存访问的优化,我们可以引入NUMA策略的概念。NUMA策略(NUMA Policy)即是指在多个节点上合理的进行内存分配的机制。对于不同软件设计要求,策略的目标可能会不同:有一些设计可能强调低延迟访问,另一些则可能更加看重内存的访问带宽。
对于强调低延迟访问的设计,基本的分配方式就是尽量在线程的本地内存上为其进行分配, 并尽量让线程保持在该节点上。这被称为线程的节点亲和性(Node affinity)。这样既充分利用了本地内存的低延迟, 同时也能有效降低节点间的通信负担。
NUMA架构的一个优势是,即便是在拥有大量CPU的大规模系统中,我们也可以保证局部内存访问的低延迟。通常来讲,CPU的处理速度是远大于内存的存取速度的。在读写内存时,CPU常常需要花大量的时钟周期来等待。降低内存访问的延迟因而能够有效的提升软件性能。
另外,为SMP设计的操作系统通常会有缓存亲和性(Cache Affinity) 的优化措施。缓存亲和性机制可以让数据尽量长时间的保留在某一个CPU的缓存中,而不是来回在多个CPU的缓存里换来换去。操作系统通常是通过优化进行线程/进程调度来保证这一点:在线程被重新调入时,调度器会尽量让线程在之前运行的同一个CPU上运行,从而保证缓存利用率。这一机制显然是和NUMA系统尽量利用本地内存的策略是一致的,有利于面向SMP系统的程序向NUMA架构移植。
但缓存亲和性机制同NUMA系统的节点亲和性又是有区别的:首先,同一个节点间多个CPU或者核的线程迁移并不影响该线程的节点亲和性;其次,当线程被迫迁移到其他节点时,他所拥有的内存是不会跟着迁移的, 仍然保留在原来位置。这个时候,本地内存就变成了远端内存,对它的访问既慢又占用节点通信带宽。相对的,线程在迁移之后能够以较小的代价迅速建立起新的缓存,并继续在新CPU上体现缓存的亲和优势。 因此,NUMA系统对于节点亲和性的依赖更大。
操作系统的调度器同时也不能仅仅为保证节点亲和性做优化。因为通常相对于频繁访问远端内存来说,让CPU空闲带来的性能损失更大。如果特定应用系统的性能受内存访问的影响远大于CPU的利用率,这个时候程序员或者管理员则可采用特别的NUMA策略来强调节点的亲和性,从而提升性能。
另外, 尽管大部分应用会因为优化响应时间而收益,还有一部分应用则对内存带宽比较敏感。为了提升内存带宽,NUMA架构下的多个内存控制器可以并行使用。这类似于RAID阵列通过并行处理磁盘IO来提升读写性能。通过适当的软件或者硬件机制,NUMA架构可以使内存控制单元在各个内存控制器上交替的分配内存。这意味着分配得到的连续内存页面会水平地分布到各个节点上。当应用程序对内存进行流式读写时,各个内存控制器的带宽就相当于累加了。此机制获得性能提升决定于NUMA架构的实现。对于远端内存访问延迟严重的架构,该提升往往会比较明显。在一些NUMA系统中,系统硬件本身提供了节点交织分配机制;而在没有硬件提供节点交织的系统中,可由操作系统来实现该机制。
下面是一些NUMA策略控制工具
NUMACTL 是设定进程NUMA策略的命令行工具。对于那些无法修改和重新编译的程序,它可以进行非常有效的策略设定。Numactl使管理员可以通过简单的命令行调用来设定进程的策略, 并可以集成到管理脚本中。
Numactl的主要功能包括:
1. 设定进程的内存分配基本策略
2. 限定内存分配范围,如某一特定节点或部分节点集合
3. 对进程进行节点或节点集合的绑定
4. 修改命名共享内存,tmpfs或hugetblfs等的内存策略
5. 获取当前策略信息及状态
6. 获取NUMA硬件拓扑
下面是使用numactl设定进程策略的实例:
numactl --cpubind=0 --membind=0,1 program
其意义为:在节点0上的CPU运行名为program的程序,并且只在节点0,1上分配内存。Cpubind的参数是节点编号,而不是cpu编号。在每个节点上有多个CPU的系统上,编号的定义顺序可能会不同。
下面是使用numactl更改共享内存段的分配策略的实例:
numactl --length=1G --file=/dev/shm/interleaved --interleave=all
其意义为: 对命名共享内存interleaved进行设置,其策略为全节点交织分配,大小为1G。
NUMASTAT 是获取NUMA内存访问统计信息的命令行工具。对于系统中的每个节点,内核维护了一些有关NUMA分配状态的统计数据。numastat命令会基于节点对内存的申请,分配,转移,失败等等做出统计,也会报告NUMA策略的执行状况。这些信息对于测试NUMA策略的有效性是非常有用的。
下面介绍NUMA策略的实现方式和策略
在最新的通用操作系统, 如Windows和linux上, 都不同程度的提供了面向NUMA架构的系统控制和API支持。下面以linux为例,对该类接口进行说明。
Linux下的NUMA API
版本为2.5之后的linux内核在进程调度,内存管理等方面对NUMA系统做了大量优化。同时,基于2.6内核版本的各主要linux发行版,如Redhat,SUSE等均包括了面向用户空间的numautils工具包,提供对NUMA系统内存策略的监控功能,并开放面向用户空间程序的API接口。该接口习惯上称为NUMA API。
NUMA API主要任务是管理NUMA的内存策略。NUMA策略通过几个子系统的协同工作来实现。内核管理进程的内存分配机制以及特殊的内存映射。NUMA API通过新引入的3个内核系统调用来实现这一点。在用户空间中,NUMA API通过libnuma库提供了统一的接口供用户空间程序使用。相对于系统调用,libnuma接口更加清晰易用。同时NUMA API还提供了命令行工具numactl和numastat来帮助系统管理员实现进程级别的策略管理。
在Linux上NUMA API支持四种内存分配策略:
- 缺省(default) - 总是在本地节点分配(分配在当前线程运行的节点上)
- 绑定(bind) - 分配到指定节点上
- 交织(interleave) - 在所有节点或者指定的节点上交织分配
- 优先(preferred) - 在指定节点上分配,失败则在其他节点上分配
绑定和优先的区别是,在指定节点上分配失败时(如无足够内存),绑定策略会报告分配失败,而优先策略会尝试在其他节点上进行分配。强制使用绑定有可能会导致前期的内存短缺,并引起大量换页。在libnuma库中,优先和绑定是组合在一起的。通过对线程调用uma_set_strict函数,可以在两种策略间切换。缺省的策略是更加普适的优先策略。
策略可以基于进程或内存区域设定。进程策略对整个进程内的内存分配都有效,而内存区域策略作用于指定的内存区域,其优先级比进程策略要高。
进程策略 作用于所有由内核分配的内存页,包括malloc, 系统调用中使用的内核级的分配以及文件缓冲区等。唯一的例外是,中断中分配的内存总是在当前节点中。当子进程Fork时,会继承父进程的进程策略。
内存区域策略 又称为VMA策略,它允许一个进程为自己地址空间里的一块内存设置策略。内存区域策略比进程策略具有更高的优先级。它的主要优点在于能够在分配发生前进行设置。目前,内存区策略只支持一部分内存机制,如:SYSV共享内存,shmem和tmpfs文件映射,以及hugetlbfs文件系统。在共享内存段或文件映射被删除前,共享内存的区域策略会一直有效。
Linux系统提供命令行及编程API两级用户空间工具来对策略进行控制。
libnuma -- NUMA策略的应用程序编程接口
尽管numactl能够用作进程级别的内存控制,但其缺点也很明显:分配策略作用于整个进程,无法指定到线程或者特定内存区域。Libnuma为更加精细的控制提供了API接口。
应用程序只需在代码中引用numa.h头文件, 并在连接时如下连接libnuma的共享库即可方便使用libnuma:
#include <numa.h>
….
cc ... -lnuma
在开始使用NUMA API更改策略或分配内存之前, 首先需要调用numa_available()函数。 之后, 则可以使用libnuma的接口对进程策略进行更改,或分配内存。Libnuma库的函数包括以下几组:
1. 环境信息 – 包括一组用于获取系统内存和CPU拓扑信息的函数,如系统节点数目,特定节点的内存大小等等。
2. 进程策略 – 包括一组用于获取,设定和更改进程级策略的函数;
3. 内存区域策略 – 包括一组用于设定特定内存区域策略的函数;
4. 节点绑定 - 将线程绑定到指定节点或节点组的函数;
5. 分配函数 - 忽略当前进程策略,直接使用特定的策略进行分配的一组函数;
6. 其他辅助函数
通过使用这些接口,程序员可以非常灵活的配置程序内存分配的方式和策略, 以达到优化性能的目的。通常的基于NUMA的内存分配流程为:
1. 使用numa_available()判定系统是否支持NUMA
2. 使用进程策略函数定义进程的整体策略
3. 使用节点绑定函数合理绑定线程
4. 使用普通的分配函数(如malloc)进行普通分配
5. 对于特定性能需求的代码, 使用NUMA分配函数做指定分配
6. 对于内存区域,使用内存区域策略函数设定其分配策略
前面说了NUMA的总总特点,有朋友问了这么一个问题:要是我的程序就是乱序的访问内存,也不太可能改了,那怎么办呢?是不是就注定被NUMA欺负了?也不是。
在英特尔下一代Xeon处理器平台中,BIOS里有一个NUMA 选项,可以指定怎么映射内存。以两颗CPU为例。如果指定NUMA mode,那么前一半内存空间被指定到直接连接CPU0, 后一半内存空间被指定到直接连接CPU1,换句话说就是我们说的NUMA方式;如果指定Non NUMA,那么就是奇数页面被指定到直接连接CPU0,偶数页面被指定到直接连接CPU1,也就是页面奇偶交错分布,用户体验上就跟传统方式类似,虽然没有了NUMA的好处,但也没被NUMA伤了。