写在前面
- 工作中遇到,简单整理
- 个人很推荐这个算法,使用预训练模型,实际测试中发现
AdaFace确实很强大,特别适合远距离,小目标,图片质量低的人脸识别- 理解不足小伙伴帮忙指正
对每个人而言,真正的职责只有一个:找到自我。然后在心中坚守其一生,全心全意,永不停息。所有其它的路都是不完整的,是人的逃避方式,是对大众理想的懦弱回归,是随波逐流,是对内心的恐惧 ——赫尔曼·黑塞《德米安》
低质量人脸数据集中的识别具有挑战性,因为人脸属性被模糊和降级。基于裕量的损失函数的进步提高了嵌入空间中人脸的可辨别性。
此外,以前的研究已经研究了适应性损失的影响,以更加重视错误分类的(硬)例子。在这项工作中,我们介绍了损失函数自适应性的另一个方面,即图像质量。我们认为,强调错误分类样本的策略应根据其图像质量进行调整。具体来说,简单和硬样品的相对重要性应基于样品的图像质量。
我们提出了一种新的损失函数,该函数根据图像质量强调不同难度的样本。我们的方法通过用特征范数近似图像质量,以自适应裕量函数的形式实现这一点。大量的实验表明,我们的方法AdaFace在四个数据集(IJB-B,IJB-C,IJB-S和TinyFace)上提高了最先进的(SoTA)的人脸识别性能。
@inproceedings{kim2022adaface,title={AdaFace: Quality Adaptive Margin for Face Recognition},author={Kim, Minchul and Jain, Anil K and Liu, Xiaoming},booktitle={Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition},year={2022}
}
实际测试中发现,AdaFace 确实很强大,特别适合远距离,小目标,图片质量低的人脸识别。
https://github.com/mk-minchul/AdaFace
克隆项目,环境搭建
(base) C:\Users\liruilong>conda create -n AdaFace python==3.8
Solving environment: done
(base) C:\Users\liruilong>conda activate AdaFace(AdaFace) C:\Users\liruilong>cd Documents\GitHub\AdaFace_demo(AdaFace) C:\Users\liruilong\Documents\GitHub\AdaFace_demo>conda install scikit-image matplotlib pandas scikit-learn
Solving environment: done
。。。
(AdaFace) C:\Users\liruilong\Documents\GitHub\AdaFace_demo>pip install -r requirements.txt -i http://pypi.douban.com/simple/ --trusted-host pypi.douban.com
Looking in indexes: http://pypi.douban.com/simple/
没有GPU,所以我们需要修改原代码中部分为 CPU 可以执行
修改位置:\GitHub\AdaFace_demo\face_alignment\align.py
mtcnn_model = mtcnn.MTCNN(device='cuda:0', crop_size=(112, 112))
# 修改为
mtcnn_model = mtcnn.MTCNN(device='cpu', crop_size=(112, 112))
修改位置:\GitHub\AdaFace_demo\inference.py
statedict = torch.load(adaface_models[architecture])['state_dict']
# 修改为
statedict = torch.load(adaface_models[architecture], map_location=torch.device('cpu'))['state_dict']
之后需要下载对应的模型文件,可以做 github 看到。放到指定位置pretrained/adaface_ir101_webface12m.ckpt就可以执行了,这里不多讲
运行 Demo,3 张图片比较
(AdaFace) C:\Users\liruilong\Documents\GitHub\AdaFace_demo> python inference.py
C:\Users\liruilong\Documents\GitHub\AdaFace_demo\face_alignment\mtcnn_pytorch\src\matlab_cp2tform.py:90: FutureWarning: `rcond` parameter will change to the default of machine precision times ``max(M, N)`` where M and N are the input matrix dimensions.
To use the future default and silence this warning we advise to pass `rcond=None`, to keep using the old, explicitly pass `rcond=-1`.r, _, _, _ = lstsq(X, U)
inference.py:25: UserWarning: Creating a tensor from a list of numpy.ndarrays is extremely slow. Please consider converting the list to a single numpy.ndarray with numpy.array() before converting to a tensor. (Triggered internally at C:\actions-runner\_work\pytorch\pytorch\builder\windows\pytorch\torch\csrc\utils\tensor_new.cpp:248.)tensor = torch.tensor([brg_img.transpose(2,0,1)]).float()
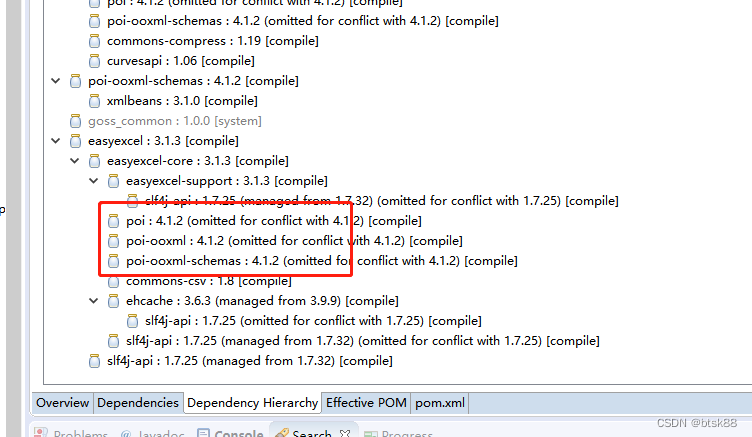
tensor([[ 1.0000, 0.7329, -0.0794],[ 0.7329, 1.0000, -0.0087],[-0.0794, -0.0087, 1.0000]], grad_fn=<MmBackward0>)
这里的矩阵表示,每张图片相互比较,矩阵为3*3,三行三列,第一张图片跟第一张图片的相似度为 1 (自己和自己比),然后第一张图片跟第二张图片对比的相似度为 0.7329,第一张图片跟第三张图片对比的相似度为 -0.0794,对角都为自己和自己比较所以是1.
我们通过上面余弦相似度得分可以区分是否是一个人,在具体的人脸识别应用中。
- 需要预先通过上面的模型把人脸库每张照片的特征向量保存到文本里,生成特征向量集
Ax={A1,A2,A3,....Ai}(i=n) - 需要识别的时候,通过模型获取要识别照片的特征向量
B1,用特征向量集Ax中的每个向量Ai和识别照片的特征向量B1获取余弦相似度得分 - 对于获取的相似得分最大值,和阈值判断,或者取大于阈值内的数据,判断是否为一个人,从而实现人脸识别。
- 相似度得分是一个接近 小于等一,大于等于 -1 的值,越大相识度越高,等于1 即是确定同一个人,-1 即完全不是一个人, 实际识别中,给相似得分一个阈值,在这个范围内我们确定为一个人。
下面为结合作者代码的 Demo
build_vector_pkl用于生成特征文件(需要准备一个照片数据集)read_vector_pkl用于加载特征文件到内存find用于需要识别的人脸和人脸库比对,返回识别结果- 这里检测代码中作者做了限制,多张人脸只那第一个人脸。
import net
import torch
import os
from face_alignment import align
import numpy as np
import pandas as pdadaface_models = {'ir_101': "pretrained/adaface_ir101_webface12m.ckpt",}def load_pretrained_model(architecture='ir_101'):# load model and pretrained statedictassert architecture in adaface_models.keys()model = net.build_model(architecture)statedict = torch.load(adaface_models[architecture], map_location=torch.device('cpu'))['state_dict']model_statedict = {key[6:]: val for key,val in statedict.items() if key.startswith('model.')}model.load_state_dict(model_statedict)model.eval()return modeldef to_input(pil_rgb_image):tensor = Nonetry:np_img = np.array(pil_rgb_image)brg_img = ((np_img[:, :, ::-1] / 255.) - 0.5) / 0.5tensor = torch.tensor([brg_img.transpose(2, 0,1)]).float()except Exception :return tensor return tensordef read_vector_pkl(db_path, adaface_model_name):"""@Time : 2023/06/16 12:10:47@Author : liruilonger@gmail.com@Version : 1.0@Desc : 读取特征向量文件Args:Returns:df"""import picklefile_name = f"representations_adaface_{adaface_model_name}.pkl"file_name = file_name.replace("-", "_").lower()with open(f"{db_path}/{file_name}", "rb") as f:representations = pickle.load(f)df = pd.DataFrame(representations, columns=["identity", f"{adaface_model_name}_representation"])return dfdef build_vector_pkl(db_path, adaface_model_name='adaface_model'):"""@Time : 2023/06/16 11:40:23@Author : liruilonger@gmail.com@Version : 1.0@Desc : 构建特征向量文件Args:Returns:void"""import timefrom os import pathfrom tqdm import tqdmimport pickleif os.path.isdir(db_path) is not True:raise ValueError("Passed db_path does not exist!")file_name = f"representations_adaface_{adaface_model_name}.pkl"file_name = file_name.replace("-", "_").lower()if path.exists(db_path + "/" + file_name):passelse:employees = []for r, _, f in os.walk(db_path):for file in f:if ((".jpg" in file.lower())or (".jpeg" in file.lower())or (".png" in file.lower())):exact_path = r + "/" + fileemployees.append(exact_path)if len(employees) == 0:raise ValueError("没有任何图像在 ",db_path," 文件夹! 验证此路径中是否存在.jpg或.png文件。",)representations = []pbar = tqdm(range(0, len(employees)),desc="生成向量特征文件中:😍😊🔬🔬🔬⚒️⚒️⚒️🎢🎢🎢🎢🎢",)for index in pbar:employee = employees[index]img_representation = get_represent(employee)instance = []instance.append(employee)instance.append(img_representation)representations.append(instance)with open(f"{db_path}/{file_name}", "wb") as f:pickle.dump(representations, f)def get_represent(path):"""@Time : 2023/06/16 11:54:11@Author : liruilonger@gmail.com@Version : 1.0@Desc : 获取脸部特征向量Args:Returns:void"""feature = Nonealigned_rgb_img = align.get_aligned_face(path)bgr_tensor_input = to_input(aligned_rgb_img)if bgr_tensor_input is not None:feature, _ = model(bgr_tensor_input)else:print(f"无法提取脸部特征向量{path}") return featuredef findCosineDistance(source_representation, test_representation):"""@Time : 2023/06/16 12:19:27@Author : liruilonger@gmail.com@Version : 1.0@Desc : 计算两个向量之间的余弦相似度得分Args:Returns:void"""import torch.nn.functional as Freturn F.cosine_similarity(source_representation, test_representation)def demo1():model_name = "test"build_vector_pkl(test_image_path,model_name)df = read_vector_pkl(test_image_path, model_name)for index, instance in df.iterrows():source_representation = instance[f"{model_name}_representation"]#distance = findCosineDistance(source_representation, target_representation)print(source_representation)features.append(source_representation)similarity_scores = torch.cat(features) @ torch.cat(features).T print(similarity_scores)def find(test_image_path,threshold=0.5):"""@Time : 2023/06/16 14:02:52@Author : liruilonger@gmail.com@Version : 1.0@Desc : 根据图片在人脸库比对找人Args:Returns:void"""test_representation = get_represent(test_image_path)if test_representation is not None:reset = {}for index, instance in df.iterrows():source_representation = instance[f"{model_name}_representation"]ten = findCosineDistance(source_representation,test_representation)reset[ten.item()]= instance["identity"] cosine_similarity = max(reset.keys()) print(f"💝💝💝💝💝💝💝💝💝💝 {cosine_similarity} 💝💝💝💝💝{threshold}")return cosine_similarity > threshold ,reset[cosine_similarity]else:return False,0def marge(m1,m2):from PIL import Imageimport uuid# 打开第一张图片image1 = Image.open(m1)# 打开第二张图片image2 = Image.open(m2)# 获取第一张图片的大小width1, height1 = image1.size# 获取第二张图片的大小width2, height2 = image2.size# 创建一个新的画布,大小为两张图片的宽度之和和高度的最大值new_image = Image.new("RGB", (width1 + width2, max(height1, height2)))# 将第一张图片粘贴到画布的左侧new_image.paste(image1, (0, 0))# 将第二张图片粘贴到画布的右侧new_image.paste(image2, (width1, 0))# 保存拼接后的图片new_image.save(str(uuid.uuid4()).replace('-', '')+"new_image.jpg")if __name__ == '__main__':import imutils from imutils import pathsimport cv2import uuidmodel = load_pretrained_model('ir_101')# 需要识别的图片位置test_image_path = 'face_alignment/ser'features = set()model_name = "test_img"build_vector_pkl("face_alignment/test",model_name)df = read_vector_pkl("face_alignment/test", model_name)for path in paths.list_images(test_image_path):b, r = find(path,0.25)if b:if r not in features:features.add(r)marge(r,path)else:img = cv2.imread(path)cv2.imwrite('__not' + str(uuid.uuid4()).replace('-', '')+".jpg", img)博文部分内容参考
© 文中涉及参考链接内容版权归原作者所有,如有侵权请告知,这是一个开源项目,如果你认可它,不要吝啬星星哦 😃
AdaFace: Quality Adaptive Margin for Face Recognition(AdaFace:用于人脸识别的质量自适应裕量): https://arxiv.org/abs/2204.00964
https://github.com/mk-minchul/AdaFace
© 2018-2023 liruilonger@gmail.com, All rights reserved. 保持署名-非商用-相同方式共享(CC BY-NC-SA 4.0)