1、cache基础
简单来说,cache快,内存慢,硬盘更慢。
L1速度> L2速度> L3速度> RAM
L1容量< L2容量< L3容量< RAM
L1 Cache也被划分成指令cachaL1i (i for instruction)和数据cacheL1d (d for data)两种专门用途的缓存。
2、cache组成
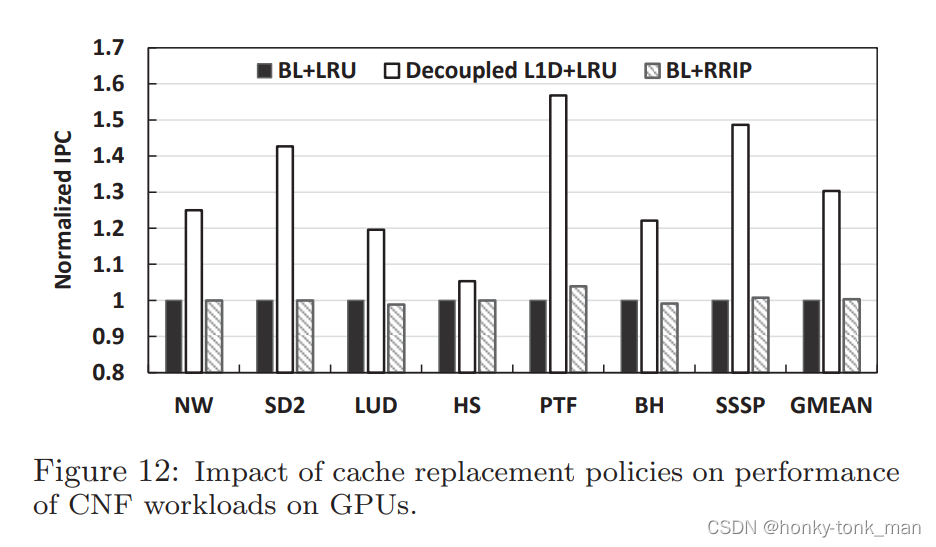
SET(组)、WAY(路)、TAG、INDEX,这几个概念是理解Cache的关键。
Cache Line可以简单的理解为CPU Cache中的最小缓存单位。把一个缓存按照N个Cache Line作为一路(WAY),多个WAY组成一组(SET),比如4路组,每个set包含4way,每个way包含N个cacha line。

目前主流的CPU Cache的Cache Line大小都是64Bytes,16KB的cache是4way的话,每个set包括4*64B,则整个cache分为16KB/64B/4 = 64set。就是说16KB的cache,有4way路,cache 是64B字节的,那每一路的话16KB/64B/4 = 64set组。
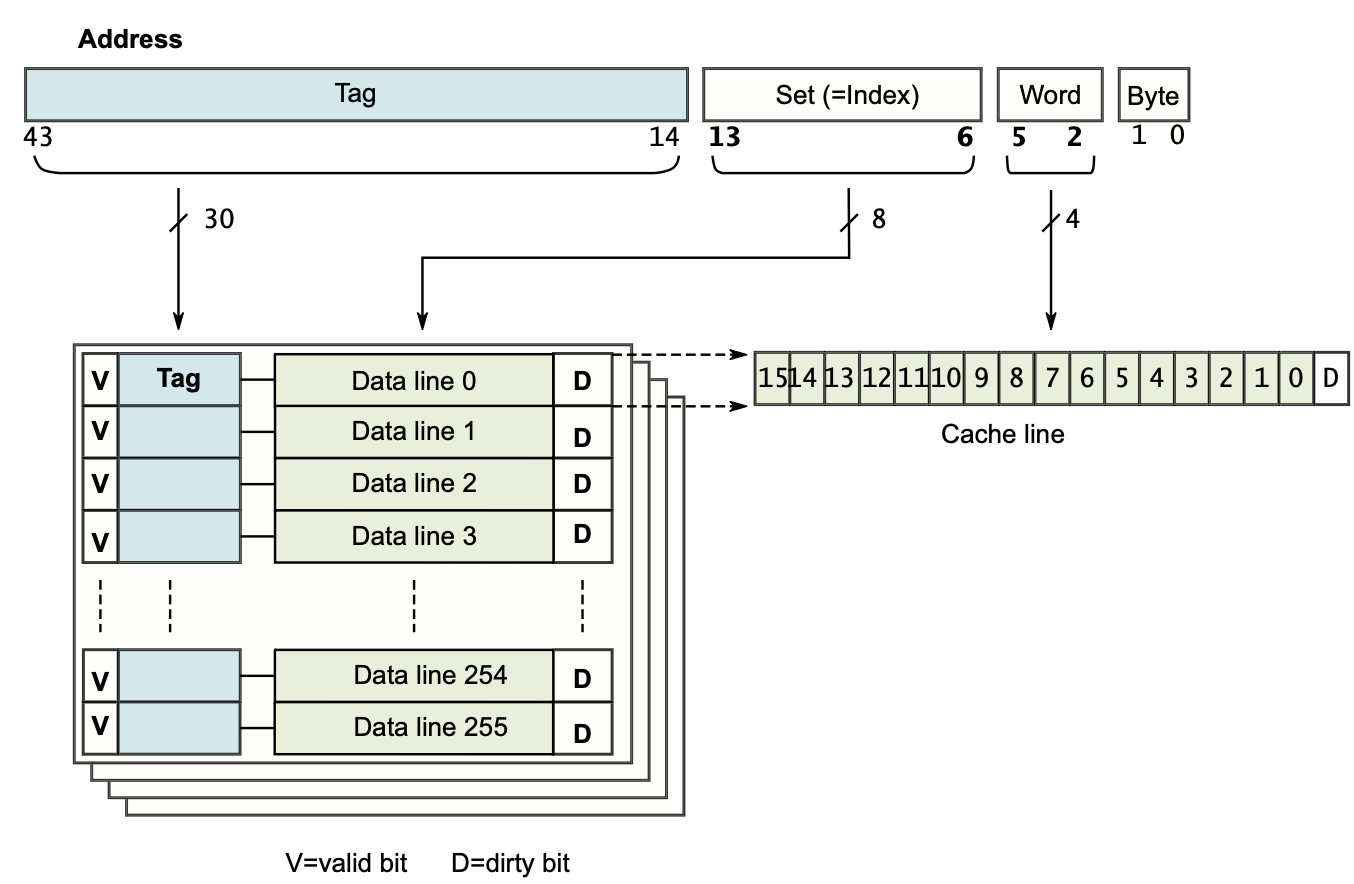
组(set):cache分成了几个大块,就是4个相同的数组。
索引域index:是用来索引块里面的cache line。块可以看成一个大的数组,数组的成员就是cache line,虚拟地址的索引域就是数组的下标。
标记tag:就是高速缓存地址用一部分的bit位(通常是虚拟地址的高位部分),他是用来判断高速缓存行的地址是否和处理器寻址地址一致。用来做匹配用的。
偏移offset:cpu是按照word,byte来访问的,cache line通常是32、64字节, 我们通过索引域找到cache line,通过标记来匹配cache line,叫做cache line命中,cpu需要4个字节就需要偏移来获得。
cache line是32字节是offset就是0~4位,cache line是64字节的话,就是0~5位
对于一个地址来讲,从索引域就可以找到4个cache line,每个数组一个cache line,这4个索引域相同的找到的cache line就组成了一个组。一个组里面的cache line他们的索引域是相同的。
为什么需要组的概念???
如果cache只分成一个大块,那么一个索引值只能对应一个cache line。那如果cpu访问2个地址,假设两个地址的索引值是一样的。那么cache就要把前面那个cache line给踢出来了,再访问第二个索引值相同的地址的话,就需要把前面的cache line给踢出去,然后才能读进新的数据来。 如果cpu很频繁的访问这两个地址的话,那么这个cache line就会把频繁的踢来踢去,造成性能的低下。====》这个就叫cache 的颠簸。
如果一个组里有4个cache line就足够多个相同索引域的地址的访问。
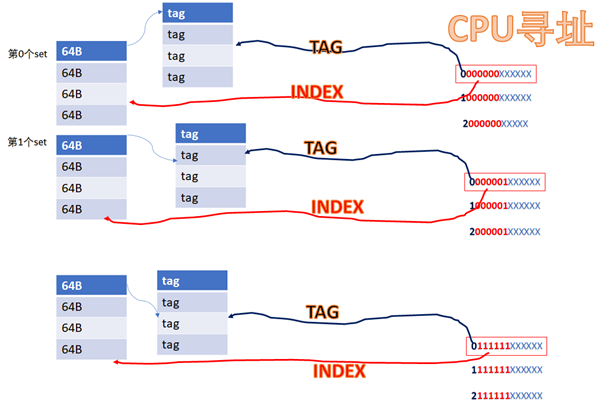
比如CPU访问地址
0 000000 XXXXXX 或者 1 000000 XXXXXX或者YYYY 000000 XXXXXX
由于它们红色的6位都相同,所以他们全部都会找到第0个set的cacheline。第0个set里面有4个way,之后硬件会用地址的高位如0,1,YYYY作为tag,去检索这4个way的tag是否与地址的高位相同,而且cacheline是否有效,如果tag匹配且cacheline有效,则cache命中。
所以地址YYYYYY000000XXXXXX全部都是找第0个set,YYYYYY000001XXXXXX全部都是找第1个set,YYYYYY111111XXXXXX全部都是找第63个set。每个set中的4个way,都有可能命中。
参考文档:
宋宝华:深入理解cache对写好代码至关重要
阅读ARM Memory(L1/L2/MMU)笔记
关于CPU Cache -- 程序猿需要知道的那些事