目录
Apache Hadoop生态-目录汇总-持续更新
一:Flume 概述
二:Flume 基础架构
2.1:Agent
2.2:Source
2.3:Sink
2.4:Channel
1) Memory Channel
2) File Channel
3) Kafka Channel
2.5:Event
Apache Hadoop生态-目录汇总-持续更新
系统环境:centos7
Java环境:Java8
一:Flume 概述
Flume 是 Cloudera 提供的一个高可用的,高可靠的,分布式的海量日志采集、聚合和传输的系统。Flume 基于流式架构,灵活简单(实时增量添加到hdfs)。
Flume最主要的作用就是,实时读取服务器本地磁盘的数据,将数据写入到HDFS(只能识别文本文件)
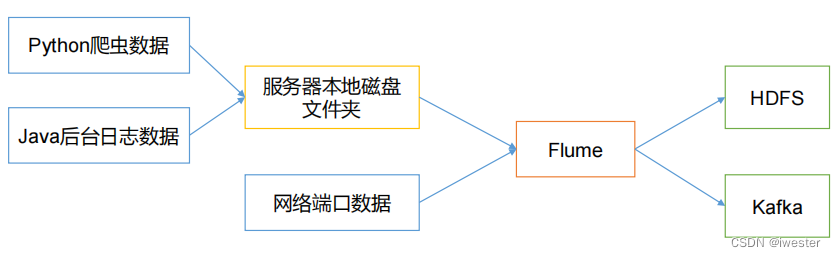
二:Flume 基础架构

2.1:Agent
Agent 是一个 JVM 进程,它以事件的形式将数据从源头送至目的。
Agent 主要有 3 个部分组成,Source、Channel、Sink。
2.2:Source
Source 是负责接收数据到 Flume Agent 的组件。
Source 组件可以处理各种类型、各种格式的日志数据,包括 avro、thrift、exec、jms、spooling directory(采集文件)、netcat(采集端口数据)、taildir、sequence generator、syslog、http、legacy
2.3:Sink
Sink 不断地轮询 Channel 中的事件且批量地移除它们,并将这些事件批量写入到存储或索引系统、或者被发送到另一个 Flume Agent。
Sink 组件目的地包括 hdfs、logger(常用语测试)、avro、thrift、ipc、file、HBase、solr、自定义。
2.4:Channel
Channel 是位于 Source 和 Sink 之间的缓冲区。因此,Channel 允许 Source 和 Sink 运作在不同的速率上。Channel 是线程安全的,可以同时处理几个 Source 的写入操作和几个Sink 的读取操。
Flume Channel:Memory Channel(内存) 和 File Channel(文件) 以及 Kafka Channel。
1) Memory Channel
Memory Channel 存储在内存是内存中的队列。Memory Channel 在不需要关心数据丢失的情景下适用
2) File Channel
File Channel 存储在磁盘。因此在程序关闭或机器宕机的情况下不会丢失数据
FileChannel底层原理
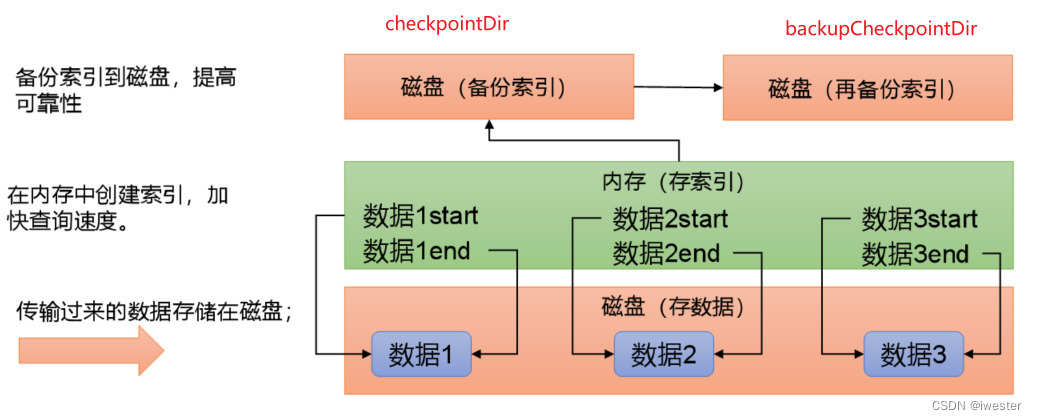
FileChannel优化
通过配置dataDirs指向多个路径,每个路径对应不同的硬盘,增大Flume吞吐量。
checkpointDir和backupCheckpointDir也尽量配置在不同硬盘对应的目录中,保证checkpoint坏掉后,可以快速使用backupCheckpointDir恢复数据。
3) Kafka Channel
Kafka Channel:数据存储在kafka里,存储在磁盘, 如果sink是kafka的情况,采用Kafka Channel会少一步sink
注意:
在Flume1.7以前,Kafka Channel很少有人使用,因为发现parseAsFlumeEvent这个配置起不了作用。也就是无论parseAsFlumeEvent配置为true还是false,都会转为Flume Event。这样的话,造成的结果是,会始终都把Flume的headers中的信息混合着内容一起写入Kafka的消息中
2.5:Event
面向任务的,每个任务开启对应的agent
Flume 数据传输的基本单元,以 Event的形式将数据从源头送至目的地。
Event 由 Header(标记区分) 和 Body(数据本身) 两部分组成,Header 用来存放该 event 的一些属性,为 K-V 结构,Body 用来存放该条数据,形式为字节数组。

实际工作中数据源的种类比较多, 比如一个文件中有订单,点击数据,支付数据,可以通过event设置不同的Header头,然后控制传输到不同的Channel往下执行
source对接数据源将数据读取过来,source将一行数据封装成一个event事件,传输到channel,sink拿到事件后会做解析(序列化)