基于《云计算原理与实践》

文章目录
- 云计算概述
- 云计算定义
- 云计算的计算模式演讲过程
- 云计算的优势
- 云计算的缺点
- 云计算的推动力
- 云计算的公共特征
- 云计算的分类
- 与云计算相关的技术
- 耦合
- 数据中心
- 云计算面临的挑战
- 大数据
- 云计算架构
- 云计算的本质
- 云计算的基石
- 云数据中心
- 云的工作负载模式
- 计算架构的进化
- 云栈和云体
- 云计算的三层架构和四层架构的区别
- 云计算的本质就是IT作为服务涵盖了基础设施即服务、平台即服务、软件即服务或任何X即服务。
- 分布式计算
- 分布式计算概述
- 分布式计算的理论基础
- 最终一致性
- 一致性散列算法
- 分布式系统的特性
- GFS架构
- GFS的设计思路
- 单一Master问题
- Master节点任务
- GFS的容错方法
- Hadoop
- MapReduce模型
- Apache Hadoop特性
- 分布式系统进阶
- 分布式存储系统大致分为5个子方向
- 典型的分布式系统
- 虚拟化技术
- 虚拟化定义
- 虚拟化技术的分类
- 服务器虚拟化
- 虚拟化的优点
- 虚拟化前景
- 虚拟化技术:
- KVM虚拟机技术
- Hyper-V虚拟化技术
- VMware ESX和ESXi虚拟化技术
- 虚拟化前后对比
- Docker容器
- Docker与VM之间的对比
- Docker特性
- Docker容器本质
- Docker三大概念
- Docker常用命令
- 1.docker run :创建一个新的容器并运行一个命令
- 2.docker start:启动一个或多个已经被停止的容器
- 3.docker kill:杀掉一个运行中的容器。
- 4.docker rm :删除一个或多个容器。
- 5.**docker pause** :暂停容器中所有的进程。
- 6.docker create :创建一个新的容器但不启动它
- 7.docker exec :在运行的容器中执行命令
- 8.**docker ps :** 列出容器
- 9.**docker inspect :** 获取容器/镜像的元数据。
- 10.docker top :查看容器中运行的进程信息,支持 ps 命令参数。
- 11.docker attach :连接到正在运行中的容器。
- 12.**docker events :** 从服务器获取实时事件。
- 13.**docker logs :** 获取容器的日志.
- 14.**docker wait :** 阻塞运行直到容器停止,然后打印出它的退出代码。
- 15.docker export :将文件系统作为一个tar归档文件导出到STDOUT。
- 16.docker port :列出指定的容器的端口映射,或者查找将PRIVATE_PORT NAT到面向公众的端口。
- 17.docker commit :从容器创建一个新的镜像。
- 18.docker cp :用于容器与主机之间的数据拷贝。
- 19.**docker diff :** 检查容器里文件结构的更改。
- 20.**docker login :** 登陆到一个Docker镜像仓库,如果未指定镜像仓库地址,默认为官方仓库 Docker Hub
- **docker logout :** 登出一个Docker镜像仓库,如果未指定镜像仓库地址,默认为官方仓库 Docker Hub
- 21.**docker pull :** 从镜像仓库中拉取或者更新指定镜像
- 22.**docker push :** 将本地的镜像上传到镜像仓库,要先登陆到镜像仓库
- 23.**docker search :** 从Docker Hub查找镜像
- 24.**docker images :** 列出本地镜像。
- 25.**docker rmi :** 删除本地一个或多个镜像。
- 26.**docker tag :** 标记本地镜像,将其归入某一仓库。
- 27.**docker build:** 用于使用 Dockerfile 创建镜像。
- 28.**docker history :** 查看指定镜像的创建历史。
- 29.**docker save :** 将指定镜像保存成 tar 归档文件。
- 30.**docker load :** 导入使用 docker save命令导出的镜像。
- 31.**docker import :** 从归档文件中创建镜像。
- 32.docker info : 显示 Docker 系统信息,包括镜像和容器数。
- 33.docker version :显示 Docker 版本信息。
- 分布式存储
- 分布式存储的定义
- 分布式存储系统的特性
- 分布式存储系统的技术挑战
- 分布式存储的分类
- 分布式文件系统
- 分布式键值(Key-Value)系统
- 分布式表系统
- 分布式数据库
- 分布式存储的发展历史
- 20世纪80年代的代表:AFS、NFS、Coda
- 20世纪90年代的代表:XFS、Tiger Shark、SFS
- 20世纪末的代表:SAN、NAS、GPFS、GFS、HDFS
- 21世纪的代表:Cassandra、HBase、MongoDB、DynamoDB
- 文件存储
- 单机文件系统
- 网络文件系统
- 并行文件系统
- 分布式文件系统
- 高通量文件系统
- 单机存储系统
- 1、硬件基础
- 2、存储引擎
- 3、数据模型
- 分布式文件系统
- 1、基本概念
- 2、性能分析
- 3、数据分布
- 4、复制
- 5、容错
- 6、可扩展性
- 7、分布式协议
- 云计算网络
- 计算机网络
- 概念
- 网络节点(Network Node)
- 网络终端(Network Endpoint)
- 交换机(Switch)
- 中间盒(MiddleBox)
- 网络链路(Network Link)
- 网络拓扑(Network Topology)
- 路径(Path)
- 信道(Channel)
- 数据平面(Data Plane)
- 控制平面(Control Plane)
- 管理平面(Management Plane)
- 网络功能(Network Function)
- 计算机网络的分类
- 按技术分类
- 按覆盖范围与规模分类
- 局域网的技术特点
- 局域网的应用领域
- 城域网的技术特点
- 广域网的技术特点
- 计算机网络的组成与结构
- 网络设备
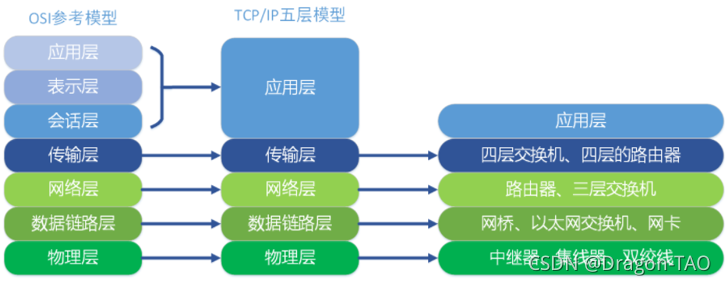
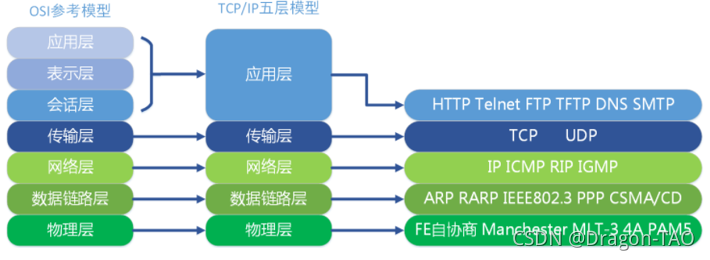
- OSI参考模型
- (1)应用层
- (2)表示层
- (3)会话层
- (4)传输层
- (5)网络层
- (6)数据链路层
- (7)物理层
- TCP/IP协议
- TCP/IP分层模型
- IP
- IP地址(IPV4)
- 如何理解TCP是一个面向连接的、可靠的、字节流式传输协议?
- TCP
- UDP
- ICMP
- 隔离技术
- 资源隔离技术
- 防火墙
- 覆盖网络
- GRE
- VLAN
- VXLAN
- NVGRE
- IPsec
- 大二层网络
- 租户网络
- 网络虚拟化
- 灵活控制:软件定义网络(SDN)
- 快速部署:网络功能虚拟化
- 负载均衡
- 负载均衡的工作方式
- 负载均衡的三个要素
- 四层负载均衡
- 七层负载均衡
- DNS负载均衡
- 重定向负载均衡
- 负载均衡服务
- 服务性能
- 如何提高效率
- 效率的分析方法
- 负载平衡
- 负载平衡点
- 负载平衡算法
- Web层的负载平衡
- EJB层的负载平衡
- 动态负载平衡技术
云计算概述
云计算定义
云计算:2009年提出;IT资源池
云计算是由横向云体与纵向云栈构成
定义:云计算实现了通过网络提供可伸缩的、廉价的分布式计算能力,用户只需要在具备网络接入条件的地方就可以随时随地获得所需的各种IT资源。
云计算是各种虚拟化、效用计算、服务计算、网格计算、自动计算等概念的混合演进并集大成之结果。
云计算的计算模式演讲过程
1、主机系统与集中运算:特点就是资源集中,计算、存储集中,这是集中计算模式的典型代表。
2、效用计算:目标是把服务器及存储系统打包给用户使用,按照用户实际使用的资源量对用户进行计费。与云计算相比,效用计算仅规定了IT资产的计费模式。
3、客户机/服务器模式:C/S;与云计算相比是服务器不同。
4、集群计算:服务器集群计算是有限度的分布式计算,集群计算并不考虑交互式的终端用户。
5、服务计算:服务计算一般仅限于软件即服务,而云计算将服务的概念推广到 了硬件和运行环境,囊括了基础设施即服务、平台即服务的概念。
6、个人计算机与桌面计算;
7、分布式计算:解决计算量。
8、网格计算:解决计算速度。
9、SaaS;
云计算的优势
1、按需供应的无线计算资源;
2、无须事先花钱就能使用的IT架构;
3、基于短期的按需付费的资源使用;
4、单机难以提供的事务处理环境;
5、提供了最可靠最安全的数据存储中心;
6、对用户端设备要求低,只需要一台能上网的电脑;
7、数据应用共享:icloud各种文件同步服务;
云计算的缺点
1、需要网络;
2、安全性和隐私问题;
3、SaaS的功能相对于本地软件的功能还是有一定差距的;
云计算的推动力
1、网络带宽的提升;
2、技术成熟度;
3、移动互联网的发展;
4、数据中心的演变;
5、经济因素;
6、大数据;
云计算的公共特征
1、弹性伸缩;
2、快速部署;
3、资源抽象;
4、按用量收费;
5、宽带访问;
云计算的分类
1、根据部署模式和云的使用范围进行分类
- 公共云
- 私有云(或称专属云)
- 社区云
- 混合云
- 行业云
- 其他云类型
2、针对云计算的服务层次和服务类型进行分类
- 基础设施即服务(Infrastructure as a Service,IaaS)
- 平台即服务(Platform as a Service,PaaS)
- 软件即服务(Software as a Service,SaaS)
与云计算相关的技术
1、并行计算
2、SOA:面向服务的体系结构(Service Oriented Architecture)
3、虚拟化:虚拟化是资源的逻辑表示,它不受物理限制的约束;
。。。。。。
耦合
指的是互相交互的系统彼此间的依赖。
数据中心
1、数据中心是云计算的重要载体,为云计算提供计算、存储、带宽等各种硬件资源,为各种平台和应用提供运行支撑环境。
2、云计算数据中心是一整套复杂的设施,包括服务器、宽带、网络连接、环境控制设备、监控设备以及各种安全装置。
3、软件定义数据中心是将虚拟化概念(如抽象,集中和自动化)扩展到所有数据中心资源和服务,以实现IT即服务(ITaaS)。
云计算面临的挑战
1、电力消耗;
2、带宽供给;
3、安全风险;
4、可靠性;
5、标准化;
6、服务关闭风险;
大数据
1、大数据:海量数据或巨量数据,其规模巨大到无法通过目前主流的计算机系统在合理时间内获取、存储、管理、处理并提炼以帮助使用者决策。
2、对三个维度数据进行分析:
- 分析已有数据;
- 对当下数据进行处理;
- 基于现有数据对未来趋势进行预测;
3、大数据的特征:4V+1C
- 价值密度低(value);
- 快速(velocity)
- 数据量大(volume)
- 多样(variety)
- 复杂度(complexity)
4、云计算与大数据的关系
- 提供IT资源
- 大数据是云计算的推动力之一
云计算架构
云计算的本质
XaaS:一切IT即服务。
云计算的基石
虚拟化
云数据中心
云数据中心的构造主要有两种模式,一种是传统模式,还有一种数据中心是基于集装箱的数据中心。
云的工作负载模式
-
模式1:时开时停模式
-
模式2:用量迅速增长模式
-
模式3:瞬时暴涨模式
-
模式4:周期性增减模式
计算架构的进化
1、中央集权架构
2、客户机/服务器(C/S)架构
3、中间层架构
4、浏览器/服务器(B/S)架构
5、C/S与B/S混合架构
6、面向服务的架构
云栈和云体
云体是云计算的物质基础,是云计算所用到的资源集合。云体就是数据中心。
云栈称为云平台,是在云上面建造的运行环境。
云计算的三层架构和四层架构的区别
三层模式:IaaS、PaaS、SaaS;其中基础设施即服务可称为效用计算,平台即服务可称为弹性计算,软件即服务可称为随需应用。

SaaS的主要特点:
-
基于网络(一般为web模式)进行远程访问的商用软件;
-
集中式管理,而非分散在每个用户站点;
-
应用交付一般接近一对多模型,即所谓的单个实例多个租户架构;
-
按照用量计费(实际中一般按月或其他时间周期进行计费)
云计算的本质就是IT作为服务涵盖了基础设施即服务、平台即服务、软件即服务或任何X即服务。
分布式计算
分布式计算概述
①集中式计算
集中式计算完全依赖于一台大型的中心计算机的处理能力,这台中心计算机称为主机,与中心计算机相连的终端设备具有各不相同非常低的计算能力。实际上大多数终端完全不具有处理能力,仅作为输入输出设备使用。
②分布式计算
与集中式计算相反,分布式计算中,多个通过网络互联的计算机都具有一定的计算能力,它们之间互相传递数据,实现信息共享,协作共同完成一个处理任务。
分布式计算相对于其他算法的优点:
-
稀有资源可以共享
-
通过分布式计算可以在多台计算机平衡计算负载
-
可以把程序放在最适合运行它的计算机上。
分布式计算步骤:
1、设计分布式计算模型
2、分布式任务分配
3、编写并执行分布式程序
分布式计算的理论基础
ACID原则:是数据库事务正常执行的四个原则,分别指原子性、一致性、独立性及持久性
CAP理论:一个分布式系统最多只能同时满足一致性、可用性和分区容错性这三项中的两项。
BASE理论:是指基本可用、软状态、最终一致性。
(基本可用:指分布式系统在出现故障的时候,允许损失部分可用性,即保证核心可用。
软状态:指允许系统存在中间状态,而该中间状态不会影响系统整体可用性。
最终一致性:指允许系统中的所有数据副本经过一定时间后,最终能够达到一致的状态。)
最终一致性
强一致性(即时一致性):假如A先写入了一个值到存储系统,存储系统保证后续A、B、C的读取操作都将返回最新值。
弱一致性:假如A先写入了一个值到存储系统,存储系统不能保证后续A、B、C的读取操作能读取到最新值。
最终一致性是弱一致性 的一种特例。
一致性散列算法
容错性、扩展性、虚拟节点
分布式系统的特性
容错性、高可扩展性、开放性、并发处理能力和透明性。
GFS架构

GFS的设计思路
1、将文件划分为若干块(Chunk)存储
-每个块固定大小(64M)
2、通过冗余来提高可靠性
-每个数据块至少在3个数据块服务器上冗余
-数据块损坏概率?
3、通过单个master来协调数据访问、元数据存储
-结构简单,容易保持元数据一致性
4、无缓存
单一Master问题
GFS的解决办法:性能瓶颈问题
1、尽可能减少数据存取中Master的参与程度
2、不使用Master读取数据,仅用于保存元数据
3、客户端缓存元数据
4、数据修改顺序交由Primary Chunk Server完成
Master节点任务
1、存储元数据
2、文件系统目录管理与加锁
3、与ChunkServer进行周期性通信
发送指令,搜集状态,跟踪数据块的完好性
4、数据块创建、复制及负载均衡
对ChunkServer的空间使用和访问速度进行负载均衡,平滑数据存储和访问请求的负载
对数据块进行复制、分散到ChunkServer上
一旦数据块冗余数小于最低数,就发起复制操作。
5、垃圾回收
在日志中记录删除操作,并将文件改名隐藏
缓慢地回收隐藏文件
与传统文件删除相比更简单、更安全
6、陈旧数据块删除
探测陈旧的数据块,并删除
GFS的容错方法
1、GFS的容错机制
①Master容错
三类元数据:命名空间(目录结构)、Chunk与文件名的映射以及Chunk副本的位置信息
前两类通过日志提供容错,Chunk副本信息存储于Chunk Server,Master出现故障时可恢复
Chunk Server容错
每个Chunk有多个存储副本(通常是3个),分别存储于不通的服务器上
每个Chunk又划分为若干Block(64KB),每个Block对应一个32bit的校验码,保证数据正确(若某个Block错误,则转移至其他Chunk副本)
Hadoop
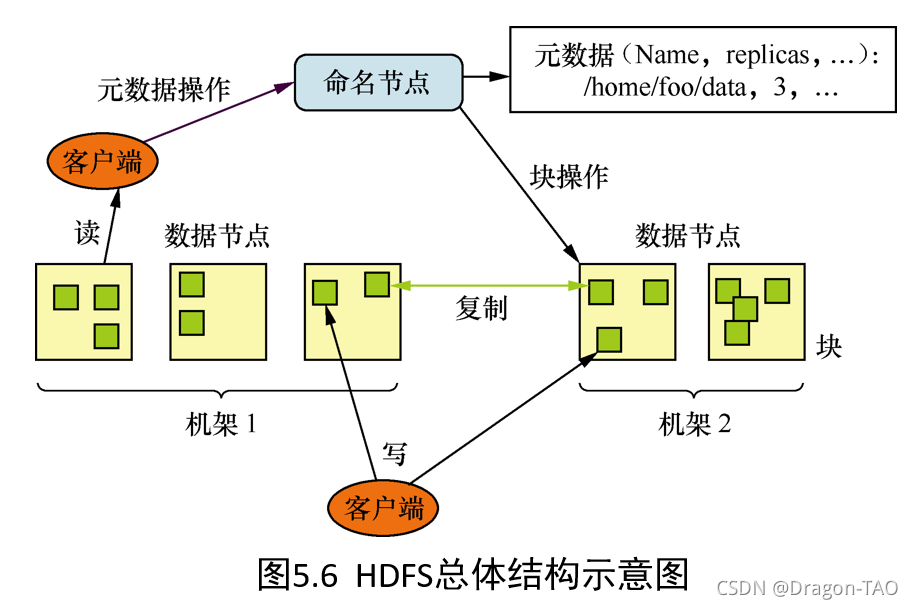
Hadoop由两个模块组成:一个是Hadoop分布式文件系统(Hadoop Distributed File System),另一个是MapReduce系统。
Hadoop分布式文件系统是一个主从式的分布式文件系统,HDFS 集群由一个NameNode和多个DataNode组成,除此之外还有用于热备份的Secondary NameNode,防止集群出现单点故障。
MapReduce模型
MapReduce工作流

Apache Hadoop特性
①高可靠性
②高可扩展性
③高效性
④高容错性
⑤低成本
分布式系统进阶
分布式存储系统大致分为5个子方向
①结构化存储
②非结构化存储
③半结构化
④In-memory存储
⑤NewSQL
典型的分布式系统
网格系统、P2P系统、透明计算、区块链系统
虚拟化技术
虚拟化定义
虚拟化是资源的逻辑表示,它不受物理限制的约束。
虚拟化技术的分类
1、服务器虚拟化
2、网络虚拟化
3、桌面虚拟化
4、软件定义的存储
服务器虚拟化
一需多:实现服务器虚拟化后,多个操作系统可以作为虚拟机在单台物理服务器上运行,并且每个操作系统都可以访问底层服务器的计算资源,从而解决了效率低下问题。
多需一:将服务器集群聚合为一项整合资源,可以提高整体效率并降低成本。服务器虚拟化还可以加快工作负载部署速度、提高应用性能并改善可用性。
四大特点:封装、隔离、分区、相对于硬件独立。(标准接口,广泛兼容)
必备的是对三种硬件资源的虚拟化:CPU、内存、设备与IO。
为了实现更好的动态资源整合,当前服务器虚拟化支撑实时迁移。
虚拟化软件层的两种架构:裸金属架构、寄居架构


服务器虚拟化的三种技术:
-
全虚拟化(二进制翻译技术BT)
-
半虚拟化(准虚拟化):虚拟机系统和虚拟化软件层通过交互来改善性能和效率
半虚拟化不支持未经修改的操作系统,它的兼容性和可移植性较差
-
硬件辅助虚拟化

虚拟化的优点
1、提高资源利用率
2、提高劳动生产率
3、节约了大量成本
4、硬件整合
5、改进IT架构的兼容性
虚拟化前景
1、快速部署
2、兼容遗留软件
3、系统隔离
4、灾难恢复
虚拟化技术:
1、在线资源扩展
2、自动负载均衡
3、业务不间断维护
4、高可用性
5、工作量的资源管理
KVM虚拟机技术
可以在全虚拟化模式下运行,也能够为部分操作系统提供准虚拟化(半虚拟化)支持
Hyper-V虚拟化技术
是准虚拟化(半虚拟化)的监视器
VMware ESX和ESXi虚拟化技术
ESX和ESXi是全虚拟化产品
虚拟化前后对比

Docker容器
容器:为了实现轻量级,操作系统级的虚拟化
Docker与VM之间的对比

Docker特性

Docker容器本质
它本质上是宿主机上的一个进程,通过namespace实现了资源隔离,通过cgroups实现了资源限制,通过写时复制技术实现了高效的文件操作。
Docker三大概念
镜像、容器、仓库
Docker常用命令
1.docker run :创建一个新的容器并运行一个命令
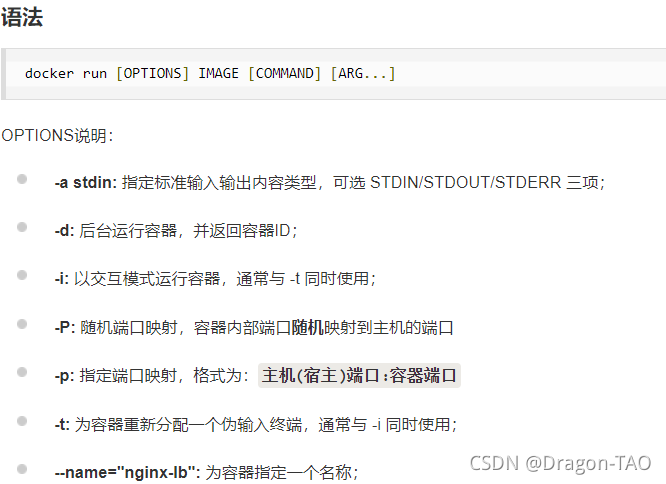
2.docker start:启动一个或多个已经被停止的容器
docker stop :停止一个运行中的容器
docker restart :重启容器

3.docker kill:杀掉一个运行中的容器。

4.docker rm :删除一个或多个容器。
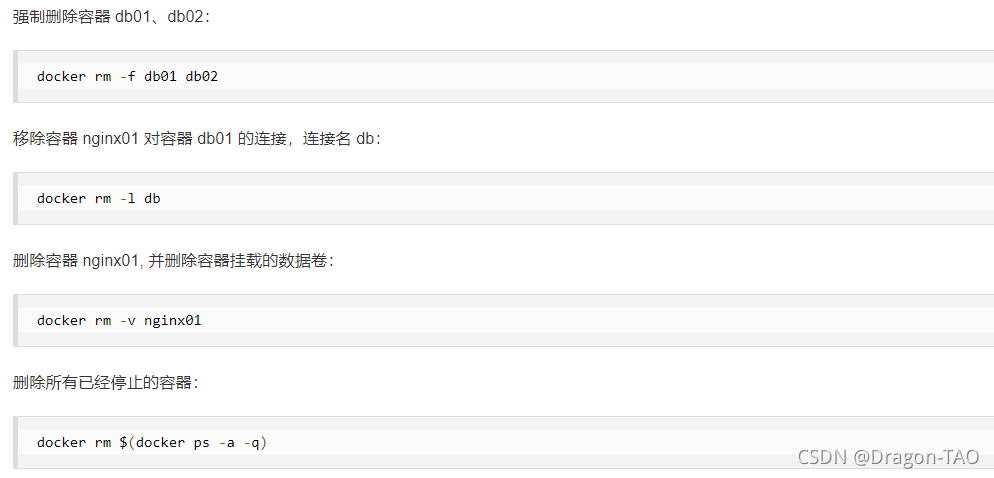
5.docker pause :暂停容器中所有的进程。
docker unpause :恢复容器中所有的进程。
6.docker create :创建一个新的容器但不启动它

7.docker exec :在运行的容器中执行命令

8.docker ps : 列出容器



9.docker inspect : 获取容器/镜像的元数据。


10.docker top :查看容器中运行的进程信息,支持 ps 命令参数。

11.docker attach :连接到正在运行中的容器。
12.docker events : 从服务器获取实时事件。
13.docker logs : 获取容器的日志.

14.docker wait : 阻塞运行直到容器停止,然后打印出它的退出代码。
15.docker export :将文件系统作为一个tar归档文件导出到STDOUT。
16.docker port :列出指定的容器的端口映射,或者查找将PRIVATE_PORT NAT到面向公众的端口。
17.docker commit :从容器创建一个新的镜像。

18.docker cp :用于容器与主机之间的数据拷贝。
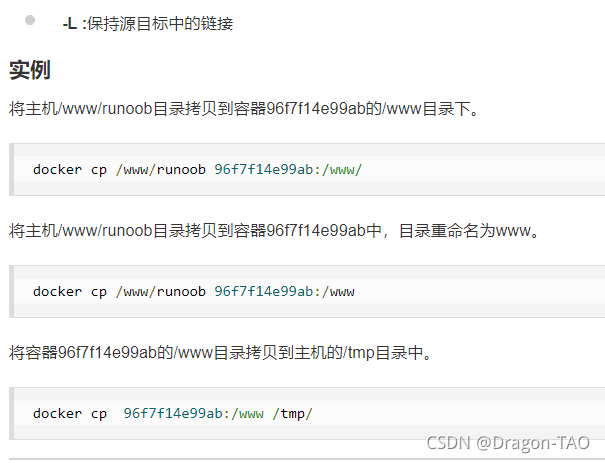
19.docker diff : 检查容器里文件结构的更改。

20.docker login : 登陆到一个Docker镜像仓库,如果未指定镜像仓库地址,默认为官方仓库 Docker Hub
docker logout : 登出一个Docker镜像仓库,如果未指定镜像仓库地址,默认为官方仓库 Docker Hub

21.docker pull : 从镜像仓库中拉取或者更新指定镜像

22.docker push : 将本地的镜像上传到镜像仓库,要先登陆到镜像仓库

23.docker search : 从Docker Hub查找镜像

24.docker images : 列出本地镜像。

25.docker rmi : 删除本地一个或多个镜像。
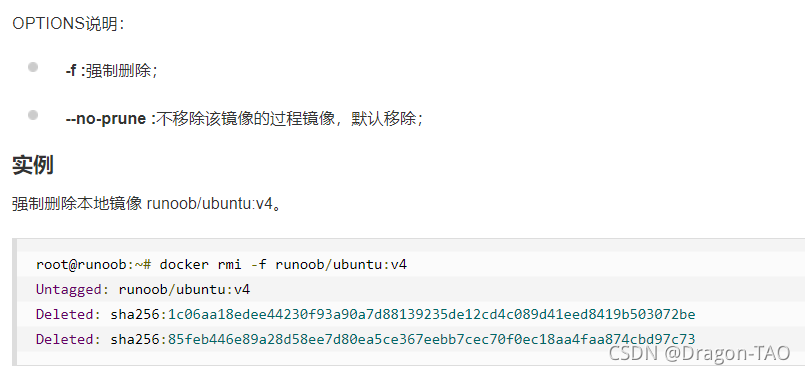
26.docker tag : 标记本地镜像,将其归入某一仓库。

27.docker build: 用于使用 Dockerfile 创建镜像。
28.docker history : 查看指定镜像的创建历史。

29.docker save : 将指定镜像保存成 tar 归档文件。

30.docker load : 导入使用 docker save命令导出的镜像。
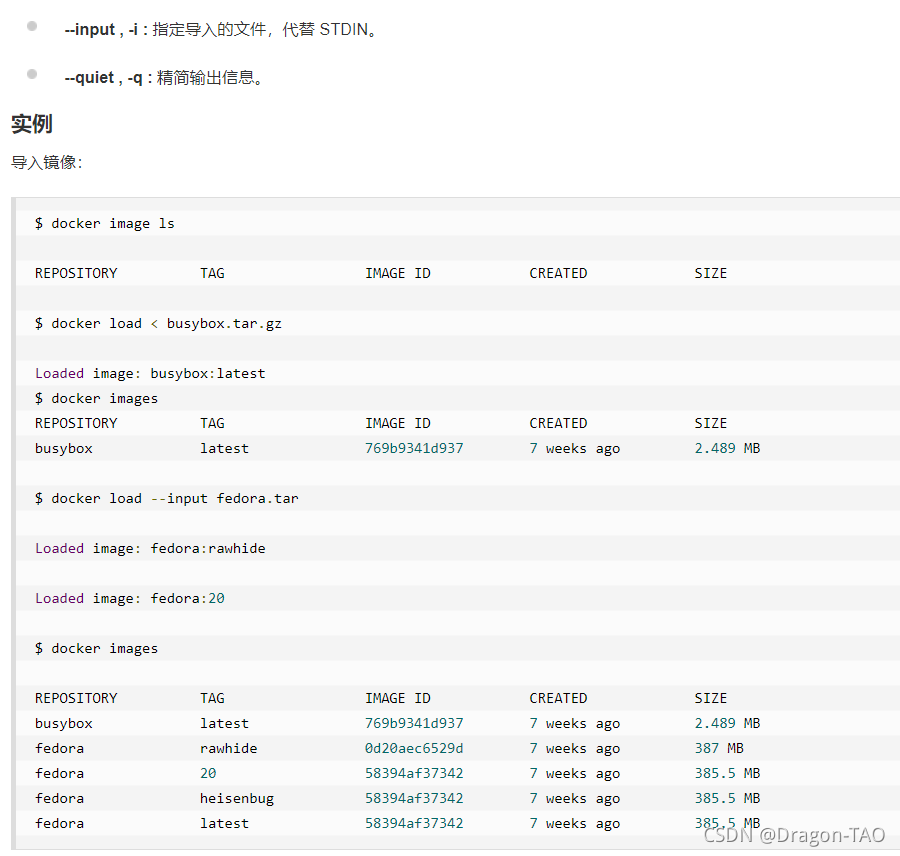
31.docker import : 从归档文件中创建镜像。

32.docker info : 显示 Docker 系统信息,包括镜像和容器数。
33.docker version :显示 Docker 版本信息。
分布式存储
分布式存储的定义
分布式存储系统是将为数众多的普通计算机或服务器通过网络进行连接,同时对外提供一个整体的存储服务。
分布式存储系统的特性
高性能、可扩展、低成本、易用性
分布式存储系统的技术挑战
数据和状态信息的持久化、数据的自动迁移、系统的自动容错、并发读写的数据的一致性等方面。
分布式存储的分类
根据数据类型,可以将其分为非结构化数据、结构化数据、半结构化数据三类。
不同的分布式存储系统适合处理不同类型的数据,因此可以将分布式存储系统分为四类:
分布式文件系统
分布式文件系统存储三种类型的数据:Blob对象、定长块以及大文件。
分布式键值(Key-Value)系统
用于存储关系简单的半结构化数据
它提供基于主键的CRUD(Create/Read/Update/Delete)功能,即根据主键创建、读取、更新或者删除一条键值记录。典型的系统有Amazon Dynamo。
分布式表系统
用于存储半结构化数据
相对于分布式键值系统,分布式表系统不仅仅支持简单的CRUD操作,而且支持扫描某个主键范围
以表格为单位组织数据
分布式数据库
存储大规模的结构化数据
采用二维表格组织数据
分布式存储的发展历史
20世纪80年代的代表:AFS、NFS、Coda
20世纪90年代的代表:XFS、Tiger Shark、SFS
20世纪末的代表:SAN、NAS、GPFS、GFS、HDFS
SAN:通过将磁盘存储系统和服务器直接相连的方式提供一个易扩展、高可靠的存储环境,高可靠的光纤通道交换机和光纤通道网络协议保证各个设备间链接的可靠性和高效性。设备间的连接接口主要是采用FC或者SCSI。
NAS:通过基于TCP/IP的各种上层应用在各工作站和服务器之间进行文件访问,直接在工作站客户端和NAS文件共享设备之间建立连接,NAS隐藏了文件系统的底层实现,注重上层的文件服务实现,具有良好的扩展性。
GPFS:是一个并行的磁盘文件系统,它保证在资源组内的所有节点可以并行访问整个文件系统。GPFS允许客户共享文件,而这些文件可能分布在不同节点的不同硬盘上。它同时还提供了许多标准的UNIX文件系统接口,允许应用不需修改或者重新编辑就可以在其上运行。
GFS:

HDFS:
21世纪的代表:Cassandra、HBase、MongoDB、DynamoDB
文件存储
划分为单机文件系统、网络文件系统、并行文件系统、分布式文件系统和高通量文件系统
单机文件系统
使用树型结构来组织文件、目录以及访问控制
它包括四个模块:引导块、超级块、索引节点和数据块。
为解决UNIX文件系统I/O性能低的问题,先后出现了1984年的快速文件系统(Fast File System,FFS)和1992年的日志结构文件系统(Log-Structured File,LFS)。
网络文件系统
NFS和AFS
并行文件系统
BFS、CFS、PVFS、Lustr
分布式文件系统
高通量文件系统
高通量文件系统是为大型数据中心设计的文件系统,它将数据中心中大量低成本的存储资源有效地组织起来,服务于上层多种应用的数据存储需求和数据访问需求。
大型数据中心在数据存储和数据访问方面有着与先前的应用非常不同的需求特征,主要包括:数据量庞大、访问的并发度高、文件数量巨大、数据访问语义和访问接口不同于传统的文件系统、数据共享与数据安全的保障越来越重要等。
单机存储系统
1、硬件基础
2、存储引擎

3、数据模型
存储系统的数据模型主要包括三类:文件、关系以及键值模型。
传统的文件系统和关系数据库系统分别采用文件和关系模型。关系模型描述能力强,生态好。
新产生的键值模型、关系弱化的表格模型等,因为其可扩展性、高并发以及性能上的优势。
分布式文件系统
1、基本概念
异常、超时、一致性、衡量指标(性能、可用性、一致性、可扩展性)
2、性能分析
判断设计方案是否存在瓶颈点,需要通过性能优化方法找出系统中的瓶颈点并逐步消除。
3、数据分布
方式:散列分布、顺序分布
4、复制
5、容错
6、可扩展性
7、分布式协议
两阶段提交协议、Paxos协议
云计算网络
计算机网络
概念
计算机网络是用通信设备和线路将分散在不同地点的有独立功能的多个计算机系统互相连接起来,并按照网络协议进行数据通信,实现资源共享的计算机集合。
多个计算机:为用户提供服务
一个通信子网:通信设备和线路
一系列协议:保证数据通信
网络节点(Network Node)
在计算机网络基础设施中,不是所有物理设备都充当网络的节点。这些节点主要根据它们在网络中的位置与 所担任的角色,可划分为以下几种类型。
网络终端(Network Endpoint)
位于网络边缘,可以作为网络通信端点的设备,包括服务器主机、用户的桌面计算机、笔记本、智能手 机等设备。
交换机(Switch)
作为网络中间节点一类网络设备,负责将网络数据包在不同端口间转发。可工作在 OSI 模型的第2层或第3层。
路由器(Router):工作于网络层,负责将数据包从源IP向目的IP转发的网络设备。
中间盒(MiddleBox)
一切位于网络传输的非端点,负责将信息在网络终端之间传输的设备,包括网络交换机、路由器、网关服务器等。
网络链路(Network Link)
连接相邻的网络节点之间的设备。可以是同轴线缆、双绞线、光纤等有线介质,也可以是无线传输的抽象链路。
网络拓扑(Network Topology)
由网络节点和网络链路构成的有向图称为该网络的拓扑。
路径(Path)
有时也称为路由(Route),数据包从源网络终端发出到达目的网络终端的过程中所经过的所有网络节点和链路。
信道(Channel)
网络终端之间建立的逻辑上的网络连接。
数据平面(Data Plane)
网络系统中承载数据流量的抽象组件。
控制平面(Control Plane)
构建于数据平面之上,网络系统中负责流量转发的逻辑控制的抽象组件。
管理平面(Management Plane)
构建于数据平面与控制平面之上,网络系统中直接面向网络管理人员操作的抽象接口组件。
网络功能(Network Function)
网络系统中提供功能性服务的组件。通常具有定义良好的外部接口和明确的功能行为。实际应用中经常 指网络中间盒所提供的逻辑功能。
计算机网络的分类
按技术分类
广播式网络(Broadcast Networks)
点对点网络(Point-to-Point Networks)
按覆盖范围与规模分类
局域网(LAN)
城域网(MAN)
广域网(WAN )
局域网的技术特点
覆盖有限的地理范围,它适用于公司、机关、校园、工厂等有限范围内的计算机、终端与各类信息处理设备连网的需求;
提供高数据传输速率(10Mb/s~10Gb/s)、低误码率的高质量数据传输环境;
一般属于一个单位所有,易于建立、维护与扩展;
从介质访问控制方法的角度,局域网可分为共享介质式局域网与交换式局域网两类。
局域网的应用领域
个人计算机局域网
大型计算设备群的后端网络
存储区域网络
办公室与实验室的网络
企业与学校的主干网
城域网的技术特点
城域网是介于广域网与局域网之间的一种高速网络;
城域网设计的目标是要满足几十公里范围内的大量企业、机关、公司的多个局域网互连的需求;
实现大量用户之间的数据、语音、图形与视频等多种信息的传输功能;
城域网在技术上与局域网相似。
广域网的技术特点
广域网也称为远程网;
覆盖的地理范围从几十公里到几千公里;
覆盖一个国家、地区,或横跨几个洲,形成国际性的远程网络;
通信子网主要使用分组交换技术;
它将分布在不同地区的计算机系统互连起来,达到资源共享的目的。
计算机网络的组成与结构
计算机网络要完成数据处理与数据通信两大基本功能。
早期计算机网络主要是广域网,它从逻辑功能上分为资源子网和通信子网两个部分:
资源子网—负责数据处理的主计算机与终端;
通信子网—负责数据通信处理的通信控制处理机与通信线路。
网络设备
网络设备及部件是连接到网络中的物理实体。不论是局域网、城域网还是 广域网,在物理上通常都是由网卡、集线器、交换机、路由器、网线、RJ45接头等网络连接设备和传输介质组成的。
第一层设备:计算机连网的基础,在这一层,数据 还没有被组织。例如:集线器
第二层设备:控制网络层与物理层之间的通信。例
如:交换机
第三层设备:将网络地址翻译成对应的物理地址。 例如:路由器、三层交换机
集线器:集线器只是对数据的传输起到同步、放大和整形的作用,对数据传输中的短帧、碎片等无法有效处理,不能保证数据传输的完整性和正确性。
交换机:交换机可以识别连在网络上的节点的网卡MAC地址,并把它们放到一个叫做MAC地址表的地方。
路由器:路由器属于网络层互联设备,用于连接多个逻辑上分开的网络。路由器有自己的操作系统,运行各种网络 层协议(如IP协议、IPX协议、AppleTalk协议等),用于实现网络层的功能。
三层交换机:三层交换机是将传统交换器与传统路由器结 合起来的网络设备,它既可以完成传统交换机的端口交换功能,又可完成部分路由器的路由功能。
OSI参考模型

(1)应用层
这是OSI模型的最高层。它是应用进程访问网络服务的窗口。这一层直接为网络用户或应用程序提供各种各样的网络服务,它是计算机网络与最终用户间的界面。应用层提供的网络服务包括文件服务、打印服务、报文服务、目录服务、网络管理以及数据库服务等。
(2)表示层
表示层保证了通信设备之间的互操作性。该层的功能使得两台内部数据表示结构都不同的计算机能实现通信。它提供了一种对不同控制码、字符集和图形字符等的解释,而这种解释是使两台设备都能以相同方式理解相同的传输内容所必需的。表示层还负责为安全性引入的数据提供加密与解密,以及为提高传输效率提供必需的数据压缩及解压等功能。
(3)会话层
会话层是网络对话控制器,它建立、维护和同步通信设备之间的交互操作,保证每次会话都正常关闭而不会突然断开,使用户被挂起在一旁。会话层建立和验证用户之间的连接,包括口令和登录确认;它也控制数据的交换,决定以何种顺序将对话单元传送到传输层,以及在传输过程的哪一点需要接收端的确认。
(4)传输层
传输层负责整个消息从信源到信宿(端到端)的传递过程,同时保证整个消息无差错、按顺序地到达目的地,并在信源和信宿的层次上进行差错控制和流量控制。
(5)网络层
网络层负责数据包经过多条链路、由信源到信宿的传递过程,并保证每个数据包能够成功和有效率地从出发点到达目的地。为实现端到端的传递,网络层提供了两种服务:线路交换和路由选择。线路交换是在物理链路之间建立临时的连接,每个数据包都通过这个临时链路进行传输;路由选择是选择数据包传输的最佳路径。在这种情况下,每个数据包都可以通过不同的路由到达目的地,然后再在目的地重新按照原始顺序组装起来。
(6)数据链路层
数据链路层从网络层接收数据,并加上有意义的比特位形成报文头和尾部(用来携带地址和其他控制信息)。这些附加信息的数据单元称为帧。数据链路层负责将数据帧无差错地从一个站点送达下一个相邻站点,即通过一些数据链路层协议完成在不太可靠的物理链路上实现可靠的数据传输。
(7)物理层
物理层是OSI的最低层,它建立在物理通信介质的基础上,作为系统和通信介质的接口,用来实现数据链路实体间透明的比特(bit)流传输。为建立、维持和拆除物理连接,物理层规定了传输介质的机械特性、电气特性、功能特性和过程特性。
在上述七层中,上五层一般由软件实现,而下面的两层是由硬件和软件实现的。
TCP/IP协议
传输层(TCP和UDP) ● TCPTCP协议,即传输控制协议,是一个可靠的、面向连接的协议。它允许在Internet上两台主机间信息的无差错传输。 ●UDP无连接方式,即UDP方式,当源主机有数据时,就发送。它不管发送的数据包是否到达目标主机,数据包是否出错,收到数据包的主机也不会告诉发送方是否正确收到了数据,因此,这是一种不可靠的数据传输方式。


为什么上图中的A在TIME-WAIT状态必须等待2MSL时间呢?
第一,为了保证A发送的最后一个ACK报文能够到达B。这个ACK报文段有可能丢失,因而使处在LAST-ACK状态的B收不到对已发送的FIN+ACK报文段的确认。B会超时重传这个FIN+ACK报文段,而A就能在2MSL时间内收到这个重传的FIN+ACK报文段。如果A在TIME-WAIT状态不等待一段时间,而是在发送完ACK报文段后就立即释放连接,就无法收到B重传的FIN+ACK报文段,因而也不会再发送一次确认报文段。这样,B就无法按照正常的步骤进入CLOSED状态。
第二,A在发送完ACK报文段后,再经过2MSL时间,就可以使本连接持续的时间所产生的所有报文段都从网络中消失。这样就可以使下一个新的连接中不会出现这种旧的连接请求的报文段。
TCP/IP分层模型
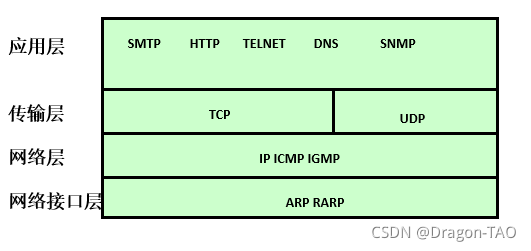
IP
IP协议是TCP/IP协议族中至关重要的一个协议
借助于IP协议,使得互联网上的异构计算机系统(包括不同类型的计算机和不同操作系统)能够连接成为一个网络。
IP协议实现两个基本功能:寻址和分段
(1)寻址:IP协议可以根据数据报报头中包括的目的地址将数据报传送到目的地址
(2)分段:如果有些网络内只能传送小数据报,IP协议支持将数据报重新组装并在报头域内注明。

16位标识:标识字段用于IP包的分段与重组。
3位标志(Flag):Flag字段的作用是用来表示IP包被分割的情况。其三位的含义分别为:不允许IP包分割(do not fragment)、IP包已被分割和其后尚有被分割的IP包(more fragment)。
TTL:生存时间,即路由器的跳数,每经过一个路由器,该TTL 减一,因此路由器需要重新计算IP报文的校验和。
8位协议标识(Protocol):该字段用来标识所传递的数据是上层的何种协议。例如:0x06表示TCP、0x11表示UPD、0x01表示ICMP等。
首部校验和:IP header校验和,接收端收到报文进行计算如果校验和错误,直接丢弃。
32位源IP地址(Source IP address)和32位目的IP地址:该字段包含发送方和接收方的IP地址。
选项(Option):传送方可以根据需求在IP包中额外加入一些字段,例如:路由记录(record route)、源路由(source route)、时戳(timestamp)等。
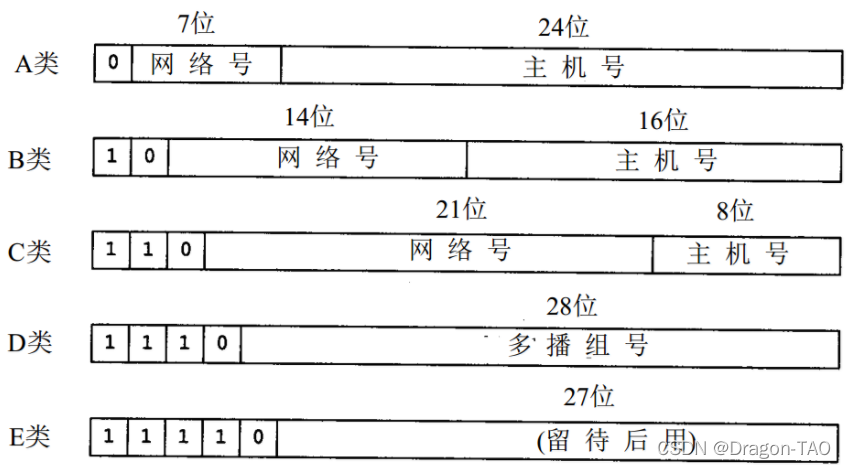
IP地址(IPV4)
在Internet中,每一台主机都有一个唯一的地址,网关常常有不止一个的地址。地址由两部分组成:网络号和主机号。这种组合是唯一的,以使每一个IP地址表示Internet中的唯一一台主机。所有IP地址都是32位长。
IP地址分为五类,平常使用的是A,B,C三类地址 。
如何理解TCP是一个面向连接的、可靠的、字节流式传输协议?
面向连接:在应用TCP协议进行通信之前双方通常需要通过三次握手来建立TCP连接,连接建立后才能进行正常的数据传输,因此广播和多播不会承载在TCP协议上。
可靠性:TCP处于多跳通信的IP层之上,而IP层并不提供可靠的传输,因此在TCP层看来就有四种常见传输错误问题,分别是比特错误(packet bit errors)、包乱序(packet reordering)、包重复(packet duplication)、丢包(packet erasure或称为packet drops),因此可靠性需要TCP协议具有超时与重传管理、窗口管理、流量控制、拥塞控制等功能。
字节流式:应用层发送的数据会在TCP的发送端缓存起来,统一分片或者打包发送,到接收端的时候接收端也是直接按照字节流将数据传递给应用层。
TCP

TCP源端口(Source Port):16位的源端口其中包含发送方应用程序对应的端口。源端口和源IP地址标示报文发送端的地址。
TCP目的端口(Destination port):16位的目的端口域定义传输的目的。这个端口指明报文接收计算机上的应用程序地址接口。
TCP的源端口、目的端口、以及IP层的源IP地址、目的IP地址四元组唯一的标识了一个TCP连接,一个IP地址和一个端口号的组合叫做一个endpoint或者socket。
序列号:32位,标识了TCP报文中第一个byte在对应方向的传输中对应的字节序号。
确认号:32位;用于标识接收方期待发送方发送的字节序列。
序列号/确认号的作用:解决可靠传输问题
数据偏移:4位包括TCP头大小,指示TCP头的长度,即数据从何处开始。
URG(Urgent):该标志位置位表示紧急(The urgent pointer) 标志有效。
ACK(Acknowledgment):取值1代表Acknowledgment Number字段有效,这是一个确认的TCP包,取值0则不是确认包。
PSH(Push):该标志置位时,一般是表示发送端缓存中已经没有待发送的数据,接收端不将该数据进行队列处理,而是尽可能快将数据转由应用处理。在处理 telnet 或 rlogin 等交互模式的连接时,该标志总是置位的。
RST(Reset):用于复位相应的TCP连接。通常在发生异常或者错误的时候会触发复位TCP连接。
SYN(Synchronize):同步序列编号(Synchronize Sequence Numbers)有效。该标志仅在三次握手建立TCP连接时有效。它提示TCP连接的服务端检查序列编号,该序列编号为TCP连接初始端(一般是客户端)的初始序列编号。
FIN(Finish):带有该标志置位的数据包用来结束一个TCP会话,但对应端口仍处于开放状态,准备接收后续数据。当FIN标志有效的时候我们称呼这个包为FIN包。
窗口大小(Window Size):16位,该值指示了从Ack Number开始还愿意接收多少byte的数据量,也即用来表示当前接收端的接收窗还有多少剩余空间。用于TCP的流量控制。
校验位(Checksum):16位TCP头。发送端基于数据内容计算一个数值,接收端要与发送端数值结果完全一样,才能证明数据的有效性。接收端checksum校验失败的时候会直接丢掉这个数据包。CheckSum是根据伪头+TCP头+TCP数据三部分进行计算的。另外对于大的数据包,checksum并不能可靠的反应比特错误,应用层应该再添加自己的校验方式。
优先指针(紧急,Urgent Pointer):16位,指向后面是优先数据的字节,在URG标志设置了时才有效。如果URG标志没有被设置,紧急域作为填充。加快处理标示为紧急的数据段。
选项(Option):长度不定,但长度必须以是32bits的整数倍。常见的选项包括MSS、SACK、Timestamp等等。
UDP
A)是无连接的。相比于TCP协议,UDP协议在传送数据前不需要建立连接,当然也就没有释放连接。
B)是尽最大努力交付的。也就是说UDP协议无法保证数据能够准确的交付到目的主机。也不需要对接收到的UDP报文进行确认。
C)是面向报文的。也就是说UDP协议将应用层传输下来的数据封装在一个UDP包中,不进行拆分或合并。因此,运输层在收到对方的UDP包后,会去掉首部后,将数据原封不动的交给应用进程。
D)没有拥塞控制。因此UDP协议的发送速率不送网络的拥塞度影响。
E)UDP支持一对一、一对多、多对一和多对多的交互通信。
F)UDP的头部占用较小,只占用8个字节。
ICMP
ICMP是TCP/IP中重要的协议之一,用于在IP主机、路由器之间传递控制消息。
ICMP使用与IP相同的首部格式,在首部之后,在IP数据包的数据部分,ICMP加入一个ICMP类型字段,ICMP余下的格式依赖于ICMP类型字段。
ICMP的类型:响应应答(0)、目的不可到达(3)、源抑制(6)、重定向(5)、响应(8)、超时(11)、参数问题(12)、时间戳(13)、时间戳应答(14)、消息请求(15)、消息应答(16)。
隔离技术
隔离技术是通过对具有不同安全需求的应用系统进行分类保护,从而有助于将风险较大的应用系统与其它应用系统隔离,达到安全保护的目的。
隔离技术一般通过隔离设备来实现。
隔离设备可以是网络设备,也可以是专门的隔离设备。
资源隔离技术
什么是资源隔离?
资源隔离是将不同的资源划归为同一个安全区域。
什么是安全区域(Secure Zone)?
安全区域是属于同一个物理或者逻辑组织的一组资源集合。
划分安全区域的目的是:更好的规划和设计安全策略
什么是资源?
物理设备:网络设备、主机设备、电子设备等。
应用和程序:Web服务器,Mail服务器等。
数据:文档,数据库等。
为什么需要进行资源隔离?
资源隔离的主要目的是将入侵行为带来的影响控制在特定的区域。
资源隔离有助于更好的实施安全策略。
资源隔离有助于实施管理。
防火墙
防火墙是在两个网络之间执行访问控制策略的一个或一组系统,包括硬件和软件,目的是保护网络不被他人侵扰。本质上,它遵循的是一种允许或阻止业务来往的网络通信安全机制,也就是提供可控的过滤网络通信,只允许授权的通信。
通常,防火墙就是位于内部网或Web站点与因特网之间的一个路由器或一台计算机,又称为堡垒主机。其目的如同一个安全门,为门内的部门提供安全,控制那些可被允许出入该受保护环境的人或物。就像工作在前门的安全卫士,控制并检查站点的访问者。
防火墙是由管理员为保护自己的网络免遭外界非授权访问但又允许与因特网联接而发展起来的。从网际角度,防火墙可以看成是安装在两个网络之间的一道栅栏,根据安全计划和安全策略中的定义来保护其后面的网络。由软件和硬件组成的防火墙应该具有以下功能。
(1)所有进出网络的通信流都应该通过防火墙。
(2)所有穿过防火墙的通信流都必须有安全策略和计划的确认和授权。
(3)理论上说,防火墙是穿不透的。
内部网需要防范的三种攻击有:
间谍:试图偷走敏感信息的黑客、入侵者和闯入者。
盗窃:盗窃对象包括数据、Web表格、磁盘空间和CPU资源等。
破坏系统:通过路由器或主机/服务器蓄意破坏文件系统或阻止授权用户访问内部网 (外部网)和服务器。
从逻辑上讲,防火墙是分离器、限制器和分析器。从物理角度看,各站点防火墙物理实现的方式有所不同。通常防火墙是一组硬件设备,即路由器、主计算机或者是路由器、计算机和配有适当软件的网络的多种组合。
防火墙的基本功能
(1)防火墙能够强化安全策略
(2)防火墙能有效地记录因特网上的活动
(3)防火墙限制暴露用户点
(4)防火墙是一个安全策略的检查站
附加功能:
NAT(Network Address Translation)网络地址转换
VPN(Virtual Personal Network )虚拟专用网
RM(Route Management)路由管理
防火墙的不足之处
(1)不能防范恶意的知情者
(2)防火墙不能防范不通过它的连接
(3)防火墙不能防备全部的威胁
(4)防火墙不能防范病毒
覆盖网络
覆盖网络(Overlay Network)是一种在原有网络基础上构建网络连接抽象及管理的技术。简单说来覆盖网络就是应用层网络,它是面向应用层的,不考虑或很少考虑网络层,物理层的问题。覆盖网络中的节点可以被认为是通过虚拟或逻辑链接相连,其中每个链接对应一条路径(Path)。节点之间也可能通过下、 层网络中的多个物理连接实现相连。例如P2P网络或Client/Server应用 这类分布式系统都可视为覆盖网络,因为它们的节点都运行在因特网之上。覆盖网络通常的实现方法是在原有网络的基础上构建隧道。目前常 用于构建隧道的网络协议有GRE、VLAN、VXLAN、NVGRE、IPSEC。
GRE
通用路由封装协议(GRE)是一种对不同网络层协议数据包进行封装,通过IP路由的隧道协议,其标准 定义于RFC 2784中。GRE是作为隧道工具开发的,旨在通过IP网络传输任意的OSI模型第3层协议
GRE的实质是创建一个类似于虚拟专用网络(VPN)的专用点对点网络连接。GRE通过在外部IP数据包内封装有效载荷(即需要传递到目标网络的内部数据包)来工作。GRE隧道端点经由中间IP网络路由封装的分组通过GRE隧道发送有效载荷,沿途的其他IP路由器不解析有效载荷(内部数据包),它们仅在外部IP数据包转发给GRE隧道端点时才解析外部IP数据包。到达隧道端点后,GRE封装将被移除,并将有效负载转发到其最终目的地。与IP到IP隧道不同,GRE隧道可以在网络之间传输多播和IPv6流量
GRE隧道的优势有以下几点。GRE隧道通过单协议骨干网封装多种协议;GRE隧道为有限跳数的网络 提供解决法;GRE隧道连接不连续的子网络;GRE隧道允许跨越广域网(WAN)的VPN。虽然GRE提 供了无状态的专用连接,但它并不是一个安全协议,因为它不使用RFC 2406定义的IPsec协议封装加 密有效负载(ESP)等加密技术。
VLAN
通用虚拟局域网(VLAN)是一种对局域网(LAN)进行抽象隔离的隧道协议。VLAN可能包含单个交 换机上的端口子集或多个交换机上的端口子集。默认情况下,一个VLAN上的系统不会看到与同一网络 中其他VLAN上的系统关联的流量。
VLAN允许网络管理员对其网络进行分区,以匹配其系统的功能和安全要求,而无须运行新电缆或对当 前网络基础架构进行重大更改。IEEE 802.1Q是定义VLAN的标准,VLAN标识符或标签由以太网帧中 的12位组成,在局域网上创建了4096个VLAN的固有限制。
交换机上的端口可以分配给一个或多个VLAN,从而允许将系统划分为逻辑组。例如,基于它们与哪个 部门相关联,以及关于如何允许分离组中的系统进行彼此间的通信。这些内容既简单实用(一个VLAN 中的计算机可以看到该VLAN上的打印机,但该VLAN外部的计算机不能),又合乎规则(例如,交易 部门中的计算机不能与零售银行中的计算机交互)。
VXLAN
虚拟可扩展局域网(VXLAN)是一种封装协议。它的提出是为了用于在现有的OSI 3层网络基础架构上 构建覆盖网络。VXLAN可以使网络工程师更轻松地扩展云计算环境,同时在逻辑上隔离云应用和租户。 对于一个多租户的网络环境,每个租户都需要自己的逻辑网络,而这又需要自己的网络标识。传统上, 网络工程师使用虚拟局域网(VLAN)在云计算环境中隔离应用程序和租户,但VLAN规范只允许在任 何给定时间分配多达4096个网络ID,这可能不足以满足大型云计算环境。 VXLAN的主要目标是通过添加24位段ID,并将可用ID增加到1600万个来扩展虚拟LAN(VLAN)地址 空间。每个帧中的VXLAN段ID区分了各个逻辑网络,因此数百万个隔离的第2层VXLAN网络可以共存 于公共第3层基础架构上。与VLAN一样,同一逻辑网络内只有虚拟机(VM)可以相互通信。
NVGRE
使用通用路由封装的网络虚拟化(NVGRE)是一种网络虚拟化方法,它使用封装和隧道为子网创建大 量虚拟LAN(VLAN),这些子网可以跨分散的数据中心和第2层(数据链路层)和第3层(网络层)。 其目的是启用可在本地和云环境中共享的多租户和负载平衡网络。
NVGRE旨在解决由IEEE 802.1Q规范支持的VLAN数量有限而导致的问题,这些问题不适用于复杂的 虚拟化环境,并且难以在分散的数据中心所需的长距离上扩展网段。
NVGRE 标准的主要功能包括识别用于解决与多租户网络相关问题的24位租户网络标识符(TNI),并 使用通用路由封装(GRE)创建可能被限制隔离的虚拟第2层网络,到单个物理第2层网络或跨越子网 边界。NVGRE还通过在GRE报头中插入TNI说明符来隔离各个TNI。
NVGRE规范由微软、英特尔、惠普和戴尔提出。NVGRE与另一种封装方法VXLAN(虚拟可扩展LAN) 存在竞争。
IPsec
IPsec是用于网络或网络通信的分组处理层的一组安全协议的框架,通常和VPN等隧道技术结合进行报 文的隐私保护。
早期的安全方法已经在通信模型的应用层插入了安全性。IPsec对于实现虚拟专用网络和通过拨号连接 到专用网络的远程用户访问很有用。IPsec的一大优势是可以在不需要更改个人用户计算机的情况下处 理安全性安排。思科一直是提议IPsec作为标准(或标准和技术的组合)的领导者,并且在其网络路由 器中包含对IPsec的支持。
IPsec提供了两种安全服务选择:基本上允许数据发送者认证的认证报头(AH),支持发送者认证和数 据加密的封装安全有效负载(ESP)。IPsec与这些服务中的每一个相关联的特定信息被插入IP包头后 的头中的包中,可以选择单独的密钥协议,例如ISAKMP/Oakley协议。
大二层网络
租户网络
网络虚拟化
灵活控制:软件定义网络(SDN)
构成网络的核心是交换机、路由器以及诸多的网络中间盒。而这些设 备的制造规范大多为Cisco、Broadcom等通信厂商所垄断,并不具 有开放性与扩展性。因此,长期以来,网络设备的硬件规范和软件规 范都十分闭塞。尤其是对于路由协议等标准的支持,用户并没有主导 权。对于新的网络控制协议的支持,需要通过用户与厂商沟通之后, 经过长期的生产线流程,才能形成最终可用的产品。尽管对于网络的 自动化管理,已有SNMP等规范化的协议来定义,但这些网络管理协 议并不能直接对网络设备的行为,尤其是路由转发策略等进行控制。
为了能够更快速地改变网络的行为,软件定义网络的理念便应运而生。
快速部署:网络功能虚拟化
SDN并不会为网络引入新的网络功能,SDN的主要功能是解决如何让网 络的控制逻辑更好地控制网络中交换机和路由器的行为。而事实上,大 多数企业网络的关键却在于丰富而日益增长的网络功能。
传统的网络功能,如防火墙、深度包检测、流量负载局衡器等,在各种 类型的服务器操作系统上也都带有相关软件实现。然而,为了使其性能 足够适用于大规模的企业网络或软件/内容服务提供商的网络,大多采用 的是定制的高性能网络设备进行硬件实现,而非软件实现。这些提供各 种网络功能的专有硬件便是我们常说的网络中间盒。
负载均衡
负载均衡的作用:把不同的客户端的请求通过负载均衡策略分配到不同的服务器上去。
负载均衡的工作方式
通过更改请求的目的地址对请求进行转发作用,在服务器返回数据包的时候,更改返回数据包的源地址,保证客户端请求的目的和返回包是同一个地址。
负载均衡的三个要素
1、分发策略:
即负载均衡设备根据什么样的策略把请求分发到不同的后台服务器上。最简单的算法就是轮询,把用户的请求依次分配到服务器上。
2、会话保持:
在大部分的应用中都会涉及到服务器Session控制。而且这些Session通常不会在服务器之间进行复制的。也就是说一个用户在登录的时候,如果分配到了某一台服务器上,则最基本的要求就是这个用户后续的请求都分配到这台服务器上。如果分配到其他的服务器上则可能不认识这个用户的请求,而造成请求失败。
最简单的会话保持策略是源地址会话保持,也就是负载均衡设备认为同一个源地址过来的所有请求都是发自于同一个客户端。在源地址会话保持的情况下,一个客户端的第一个请求会按照负载均衡策略进行分配,一旦分配了一台服务器之后,后续的请求都会发到这台服务器。当然,对于一些应用如新闻、图片等静态的内容就不需要会话保持了。
3、健康检查:
负载均衡设备必须检测后台服务器是否在正常工作。如果发现某一台服务器出现了故障,则需要把这台服务器从负载均衡组里面摘掉。当故障服务器恢复服务的时候,再把服务器重新加入到负载均衡组里面进行处理。
四层负载均衡
以TCP的一个连接为最小单位,也就是以一个Socket连接的最小单位来进行转发,在一个Socket里面跑了多少个交易和负载均衡无关。
七层负载均衡
负载均衡设备可以按照协议识别每一笔交易,并以每个交易为最小单位进行转发。比如在一个HTTP 1.1的连接中可以包含多个Request/ Response,四层负载均衡一旦在确定第一个连接的分配后,就不能对后续的request /response进行后续处理了。而七层负载均衡处理能把每一个HTTP Request/Response分别进行处理。
DNS负载均衡
通过DNS协议实现,对于同一个域名,DNS可以同时提供多个IP地址对应,浏览器会选择第一个地址发出请求,而多个DNS地址在 Local DNS返回给客户端的时候会轮询返回,所以不同的用户得到的第一个地址是不一样的。因此,对一个域名提供多个地址可以实现负载均衡的效果。
另外一种DNS 负载均衡的方式是DNS服务器判断客户端Local DNS的源地址,根据不同的源地址返回不同的IP地址和域名对应。比如来源是网通,就返回网通的服务器地址,来源是电信,就返回电信的服务器地址。这样也能实现负载均衡的效果。
重定向负载均衡
一些协议比如HTTP是可以支持重定向的,负载均衡设备通过算法决定用户的请求应该去某台服务器的时候,就返回一个302重定向指令使用户重新发送一个请求到目的服务器,通过这样的方式实现负载均衡。
负载均衡服务
服务性能
性能的重要性:核心质量属性之一
正确、健壮、安全、高效、易维护。
如何提高效率
基本过程:
分析效率=>发现问题=>调整
基本方式:
离线 在线
效率的分析方法
1、静态分析
2、动态测试
3、在线监测
负载平衡
在大量处理结点组成d 集群系统中,系统在服务过程中,负载平衡是提高资源利用率,降低请求响应时间的有效手段。
负载平衡点
负载平衡点指作出负载平衡决策的位置,独立的负载均衡器上、服务节点自身、客户端,在大多数情况下负载平衡由单个节点完成
1、单点负载平衡
好处:
便于获得系统的全局状态,作出全局一致的决策;
能实现复杂的负载平衡算法,获得最优的效果;
便于支持多种平衡策略,适用于不同的应用环境。
不足:
负载平衡点可能成为性能瓶颈
影响系统的伸缩性
也可能单点失效
2、多点负载平衡
可以获得比较好的伸缩性,但一般仅能使用静态算法
存在两种类型的多点负载平衡:
①一种是多个节点独立地进行决策,其综合效果取决于单个节点的负载平衡效果与多个节点的叠加效果;
②另一种是多个节点并行地做出相同的决策,如根据请求的源地址(或目标地址)进行静态散列以确定服务节点,此时多个物理负载平衡点等价于单个逻辑负载平衡点。
当客户数量众多而又无法依赖高速硬件来完成负载分发时,多点负载平衡可能是必须的
负载平衡算法
根据决策时是否使用运行时刻的信息(如各节点的负载状况、请求的类型或内容)
1、静态算法
2、动态算法
Web层的负载平衡
特点:
单点负载平衡,既逻辑上只有一个负载 平衡点,物理上也只有一个负载平衡点
2)请求级负载平衡,即每次客户请求都需要经由负载平衡器进行请求分发
EJB层的负载平衡
很多情况下,Web容器与EJB容器位于同一个节点上,此时对于Web客户仅需要Web层负载平衡即可。
但是当Web容器与EJB容器分离时,特别对于独立客户而言,EJB负载平衡仍是必要的
一般仅使用静态负载平衡算法 。




