文章目录
- 01:ODS层构建:需求分析
- 02:ODS层构建:创建项目环境
- 03:ODS层构建:代码导入
01:ODS层构建:需求分析
-
目标:掌握ODS层构建的实现需求
-
路径
- step1:目标
- step2:问题
- step3:需求
- step4:分析
-
实施
-
目标:将已经采集同步成功的101张表的数据加载到Hive的ODS层数据表中
-
问题
-
难点1:表太多,如何构建每张表?
-
101张表的数据已经存储在HDFS上
-
建表
-
方法1:手动开发每一张表建表语句,手动运行
-
方法2:通过程序自动化建表
-
拼接建表的SQL语句
create external table 数据库名称.表名 comment '表的注释' partitioned by ROW FORMAT SERDE'org.apache.hadoop.hive.serde2.avro.AvroSerDe' STORED AS INPUTFORMAT'org.apache.hadoop.hive.ql.io.avro.AvroContainerInputFormat' OUTPUTFORMAT'org.apache.hadoop.hive.ql.io.avro.AvroContainerOutputFormat' location '这张表在HDFS上的路径' TBLPROPERTIES ('这张表的Schema文件在HDFS上的路径')- 表名、表的注释、表在HDFS上的路径、Schema文件在HDFS上的路径
-
将SQL语句提交给Hive或者Spark来执行
-
-
-
申明分区
alter table 表名 add partition if not exists partition(key=value)
-
-
难点2:如果使用自动建表,如何获取每张表的字段信息?
-
Schema文件:每个Avro格式的数据表都对应一个Schema文件
-
统一存储在HDFS上
-
-
-
-
需求:加载Sqoop生成的Avro的Schema文件,实现自动化建表
-
分析
-
step1:代码中构建一个Hive/SparkSQL的连接
-
step2:创建ODS层数据库
create database if not exists one_make_ods; -
step3:创建ODS层全量表:44张表
create external table one_make_ods_test.ciss_base_areascomment '行政地理区域表'PARTITIONED BY (dt string)ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.avro.AvroSerDe' STORED AS INPUTFORMAT 'org.apache.hadoop.hive.ql.io.avro.AvroContainerInputFormat' OUTPUTFORMAT 'org.apache.hadoop.hive.ql.io.avro.AvroContainerOutputFormat'location '/data/dw/ods/one_make/full_imp/ciss4.ciss_base_areas'TBLPROPERTIES ('avro.schema.url'='hdfs://bigdata.maynor.cn:9000/data/dw/ods/one_make/avsc/CISS4_CISS_BASE_AREAS.avsc');-
读取全量表表名
- 动态获取表名:循环读取文件
-
获取表的信息:表的注释
- Oracle:表的信息
- 从Oracle中获取表的注释
-
获取表的文件:HDFS上AVRO文件的地址
/data/dw/ods/one_make/full_imp -
获取表的Schema:HDFS上的Avro文件的Schema文件地址
/data/dw/ods/one_make/avsc -
拼接建表字符串
-
方式一:直接相加:简单
str1 = "I " str2 = "like China" str3 = str1 + str2 -
方式二:通过列表拼接:复杂
-
-
执行建表SQL语句
-
-
step4:创建ODS层增量表:57张表
-
读取增量表表名
- 动态获取表名:循环读取文件
-
获取表的信息:表的注释
- Oracle:表的信息
- 从Oracle中获取表的注释
-
获取表的文件:HDFS上AVRO文件的地址
/data/dw/ods/one_make/incr_imp -
获取表的Schema:HDFS上的Avro文件的Schema文件地址
/data/dw/ods/one_make/avsc -
拼接建表字符串
-
执行建表SQL语句
-
-
-
小结
- 掌握ODS层构建的实现需求
02:ODS层构建:创建项目环境
-
目标:实现Pycharm中工程结构的构建
-
实施
-
安装Python3.7环境

- 项目使用的Python3.7的环境代码,所以需要在Windows中安装Python3.7,与原先的Python高版本不冲突,正常安装即可
-
创建Python工程

-
安装PyHive、Oracle库
-
step1:在Windows的用户家目录下创建pip.ini文件
-
例如:C:\Users\Frank\pip\pip.ini
-
内容:指定pip安装从阿里云下载
[global]index-url=http://mirrors.aliyun.com/pypi/simple/[install]trusted-host=mirrors.aliyun.com
-
-
step2:将文件添加到Windows的Path环境变量中
-
step3:进入项目环境目录
-
例如我的项目路径是:D:\PythonProject\OneMake_Spark\venv\Scripts

-
将提供的sasl-0.2.1-cp37-cp37m-win_amd64.whl文件放入Scripts目录下
-
在CMD中执行以下命令,切换到Scripts目录下
#切换到D盘 D: #切换到项目环境的Scripts目录下 cd D:\PythonProject\OneMake_Spark\venv\Scripts
-
-
step4:CMD中依次执行以下安装命令
# 安装sasl包 -> 使用pycharm安装,会存在下载失败情况,因此提前下载好,对应python3.7版本 pip install sasl-0.2.1-cp37-cp37m-win_amd64.whl # 安装thrift包 pip install thrift # 安装thrift sasl包One pip install thrift-sasl # 安装python操作oracle包 pip install cx-Oracle # 安装python操作hive包,也可以操作sparksql pip install pyhive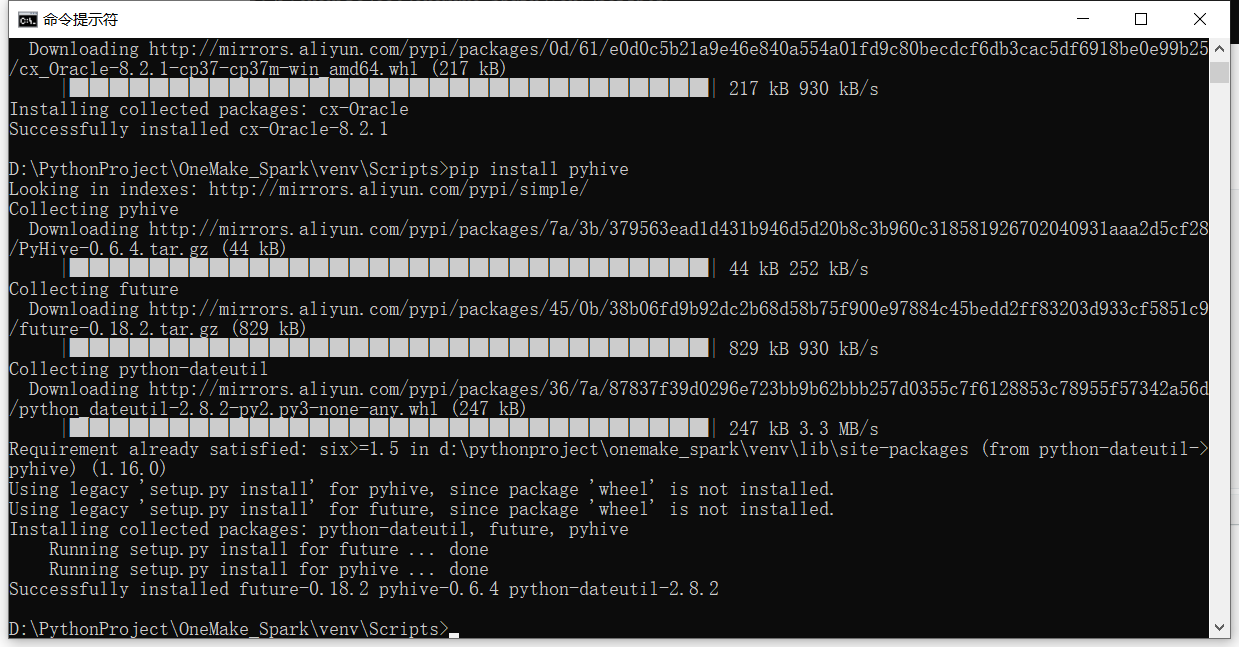
-
step5:验证安装结果

-
温馨提示:其实工作中你也可以通过Pycharm直接安装
-
-
-
小结
- 实现Pycharm中工程结构的构建
03:ODS层构建:代码导入
-
目标:实现Python项目代码的导入及配置
-
实施
-
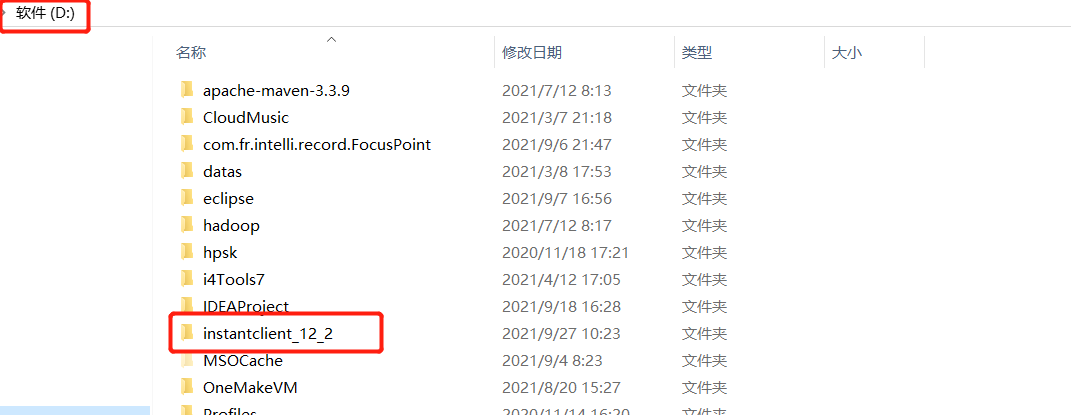
Oracle本地驱动目录:将提供的instantclient_12_2目录放入D盘的根目录下
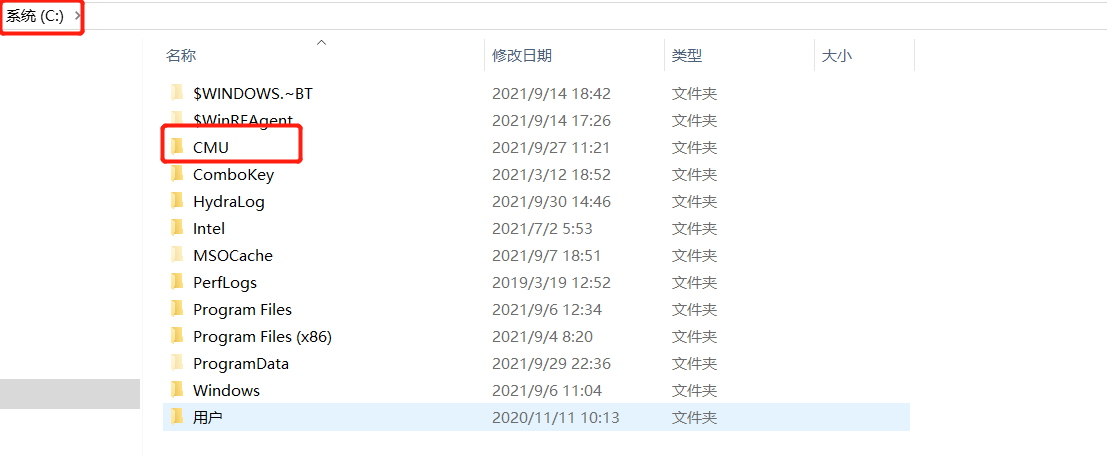
- PyHive本地连接配置:将提供的CMU目录放入C盘的根目录下
-
auto_create_hive_table包
-
创建路径包
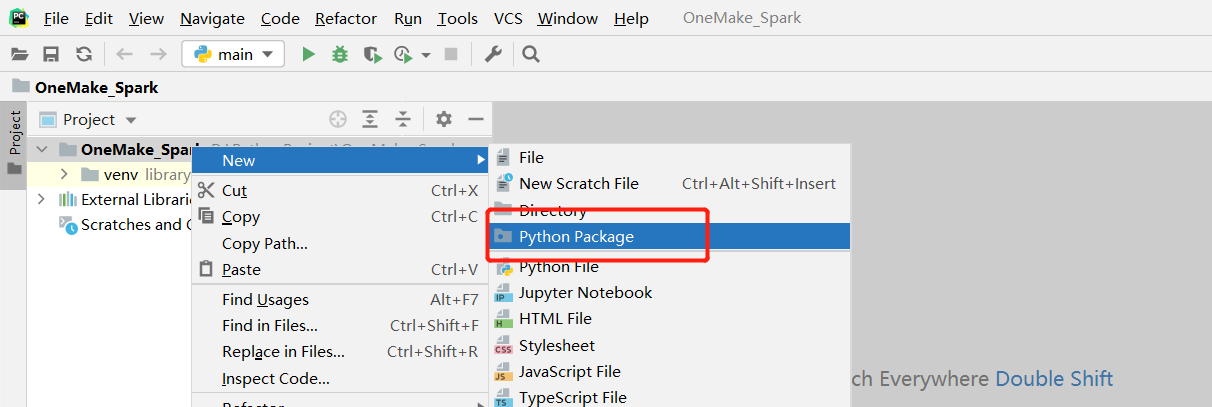
auto_create_hive_table.cn.maynor.datatohive
-
在datatohive的init文件中放入如下代码
from auto_create_hive_table.cn.maynor.datatohive import LoadData2DWD from auto_create_hive_table.cn.maynor.datatohive.CHiveTableFromOracleTable import CHiveTableFromOracleTable from auto_create_hive_table.cn.maynor.datatohive.CreateHiveTablePartition import CreateHiveTablePartition -
其他包的init都放入如下内容
#!/usr/bin/env python # @desc : __coding__ = "utf-8" __author__ = "maynor"- 将对应的代码文件放入对应的包或者目录中
-
-
-
-
step1:从提供的代码中复制config、log、resource这三个目录直接粘贴到auto_create_hive_table包下
-
step2:从提供的代码中复制entity、utils、EntranceApp.py这三个直接粘贴到maynor包下

-
step3:从提供的代码中复制fileformat等文件直接粘贴到datatohive包下

-
DW归档目录**:将提供的代码中的dw目录直接粘贴到项目中
-
-
小结
- 实现Python项目代码的导入及配置