Kafka源码解析之索引
索引结构
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-XNNYeyUG-1687105485417)(C:\Users\jimmy\AppData\Roaming\Typora\typora-user-images\image-20230618220841971.png)]](https://img-blog.csdnimg.cn/530b3d3e522947818ba0c4d885093f51.png)
Kafka有两种类型的索引:
- TimeIndex: 根据时间戳索引,可以通过时间查找偏移量所在位置,目录下以.timeindex结尾
- Index: 根据偏移量索引,.index结尾
构建索引时机
由log.index.interval.bytes 参数控制,默认4KB构建一条索引
为什么默认值是4kb呢?这里认为与基于磁盘的读写单位是 block(一般大小为 4KB)还有内存管理与分配的最小单位是4kb有关
def append(largestOffset: Long,largestTimestamp: Long,shallowOffsetOfMaxTimestamp: Long,records: MemoryRecords): Unit = {.....// 判断是否写入索引文件if (bytesSinceLastIndexEntry > indexIntervalBytes) {offsetIndex.append(largestOffset, physicalPosition)timeIndex.maybeAppend(maxTimestampSoFar, offsetOfMaxTimestampSoFar)bytesSinceLastIndexEntry = 0}bytesSinceLastIndexEntry += records.sizeInBytes}
}
在源码的LogSegment.append方法中,会对当前segement写入大小与上次构建索引时大小差值进行判断,如果超过log.index.interval.bytes,会构建timeIndex以及offsetIndex索引
AbstractIndex
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Ze80Lt2U-1687105485418)(C:\Users\jimmy\AppData\Roaming\Typora\typora-user-images\image-20230618222246953.png)]](https://img-blog.csdnimg.cn/8ff6ceabed9d47c7beca3bb160f43251.png)
AbstractIndexl类时TimeIndex以及OffsetIndex文件的父类,其中有一个很重要的成员变量 mmap:
protected var mmap: MappedByteBuffer = {val newlyCreated = file.createNewFile()val raf = if (writable) new RandomAccessFile(file, "rw") else new RandomAccessFile(file, "r")try {//提前进行文件的创建if(newlyCreated) {if(maxIndexSize < entrySize)throw new IllegalArgumentException("Invalid max index size: " + maxIndexSize)raf.setLength(roundDownToExactMultiple(maxIndexSize, entrySize))}/* memory-map the file */_length = raf.length()val idx = {if (writable)raf.getChannel.map(FileChannel.MapMode.READ_WRITE, 0, _length)elseraf.getChannel.map(FileChannel.MapMode.READ_ONLY, 0, _length)}/* set the position in the index for the next entry */if(newlyCreated)idx.position(0)else// if this is a pre-existing index, assume it is valid and set position to last entryidx.position(roundDownToExactMultiple(idx.limit(), entrySize))idx} finally {CoreUtils.swallow(raf.close(), AbstractIndex)}
}
这里用到了Memory Mapped Files即内存映射
mmap是一种内存映射文件的方法,即将一个文件或者其它对象映射到进程的地址空间,实现文件磁盘地址和进程虚拟地址空间中一段虚拟地址的一一对映关系。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-XyfKUiva-1687105485418)(C:\Users\jimmy\AppData\Roaming\Typora\typora-user-images\image-20230618222936451.png)]](https://img-blog.csdnimg.cn/72f6f630958b4f2180a3bc696d13cf64.png)
内存映射mmap参考文章:https://zhuanlan.zhihu.com/p/507907660
mmap同样是一种零拷贝的技术,常规的文件操作需要从磁盘到页缓存再到用户主存的两次数据拷贝。而mmap操控文件,只需要从磁盘到用户主存的一次数据拷贝过程,其实也是一种通过磁盘空间代替内存的操作,提供进程间共享内存及相互通信的方式。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-JdjQsreD-1687105485419)(C:\Users\jimmy\AppData\Roaming\Typora\typora-user-images\image-20230618235006202.png)]](https://img-blog.csdnimg.cn/7dec4aef620444eeaf962ce9dbdd11e2.png)
二分查找与页缓存
Kafka根据索引文件查找offset
private def indexSlotRangeFor(idx: ByteBuffer, target: Long, searchEntity: IndexSearchEntity): (Int, Int) = {// 判断index文件是否为空if(_entries == 0)return (-1, -1)def binarySearch(begin: Int, end: Int) : (Int, Int) = {// 二分查找开始var lo = beginvar hi = endwhile(lo < hi) {val mid = (lo + hi + 1) >>> 1//parseEntry方法在timeindex与index里有不同实现方式val found = parseEntry(idx, mid)val compareResult = compareIndexEntry(found, target, searchEntity)if(compareResult > 0)hi = mid - 1else if(compareResult < 0)lo = midelsereturn (mid, mid)}//如果lo等于最后一条,那么就返回-1(lo, if (lo == _entries - 1) -1 else lo + 1)}val firstHotEntry = Math.max(0, _entries - 1 - _warmEntries)// 冷热区判断if(compareIndexEntry(parseEntry(idx, firstHotEntry), target, searchEntity) < 0) {return binarySearch(firstHotEntry, _entries - 1)}// check if the target offset is smaller than the least offsetif(compareIndexEntry(parseEntry(idx, 0), target, searchEntity) > 0)return (-1, 0)binarySearch(0, firstHotEntry)
}
Kafka对二分搜索的优化
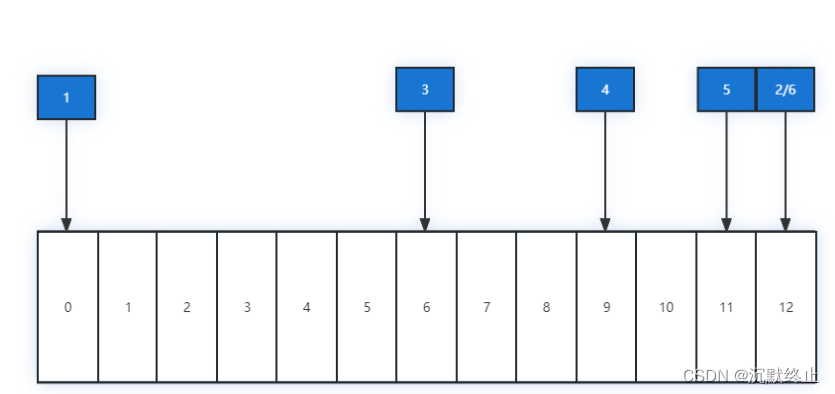
对正常的二分查找来说,假设索引的大小有13个页,我们需要查找的偏移量在页12上,那么我们会依次访问0->12->6->9->11->12这六个页
当生产者继续往分区中生产消息,超过4kb后,又写了一个新的索引项,这个时候索引访问的顺序是:0->13->7->10->11>12->13
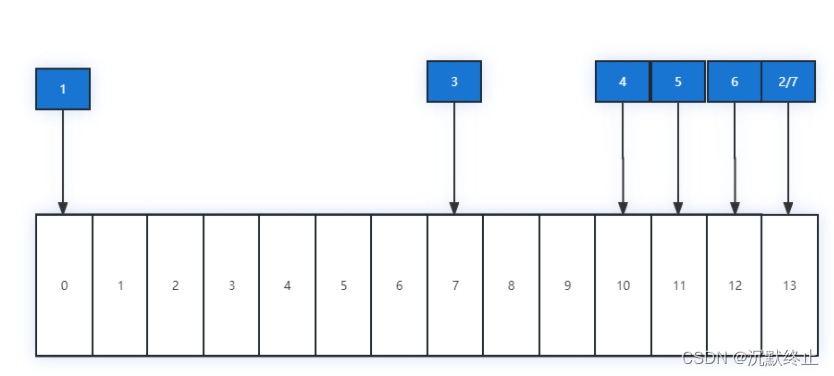
通过对上面mmap的研究可以知道,磁盘到用户主存的映射实际上依赖于页表,只是用户进程可以通过指针操作直接读写page cache,不再需要系统调用和内存拷贝。常用的页表置换算法基本是基于LRU的,当读取页7/10的时候,这两个页可能已经很长时间没有被访问到了,已经从LRU中移除了,这个时候再访问这两个页的时候就可能导致操作系统陷入缺页中断。
Here, we use a more cache-friendly lookup algorithm:
if (target > indexEntry[end - N]) // if the target is in the last N entries of the indexbinarySearch(end - N, end)
elsebinarySearch(begin, end - N)
这里Kafka做了一个优化,保证index文件的最后N个项分为热区,而剩余项则是冷区。这是因为在热区中的索引项可能因为更为频繁的访问,更有可能存在于页表中,可以增加搜索的效率。这里N的值是8192,官方给的解释是:
We set N (_warmEntries) to 8192, because
1. This number is small enough to guarantee all the pages of the "warm" section is touched in every warm-sectionlookup. So that, the entire warm section is really "warm".When doing warm-section lookup, following 3 entries are always touched: indexEntry(end), indexEntry(end-N),and indexEntry((end*2 -N)/2). If page size >= 4096, all the warm-section pages (3 or fewer) are touched, when wetouch those 3 entries. As of 2018, 4096 is the smallest page size for all the processors (x86-32, x86-64, MIPS,SPARC, Power, ARM etc.).
2. This number is large enough to guarantee most of the in-sync lookups are in the warm-section. With default Kafkasettings, 8KB index corresponds to about 4MB (offset index) or 2.7MB (time index) log messages.
warmEntries的个数:
protected def _warmEntries: Int = 8192 / entrySize
class OffsetIndex(_file: File, baseOffset: Long, maxIndexSize: Int = -1, writable: Boolean = true)extends AbstractIndex(_file, baseOffset, maxIndexSize, writable) {import OffsetIndex._override def entrySize = 8
这样的设计保证了几点:
1、8192的大小保证了三个索引项是在页表中的indexEntry(end), indexEntry(end-N), indexEntry((end*2 -N)/2)
//待续