这篇论文发表在ICML 2020上,是一篇关于多标签学习的文章,文章提出了一种基于深度神经网络的新型框架,即深度流标签学习(DSLL),以有效地对带有新兴标签的实例进行分类。
1.Introduction
在传统的监督学习中,单个实例仅具有一个标签。而在许多实际任务中,一个实例自然可以与多个标签相关联。例如,一个文档可能涉及多个主题;一张图像可以包含几个人的脸。 有学者提出并研究了多标签学习来处理这一类的任务。对于给定的实例x∈Rd,要预测y∈{0,1}m,其中m是标签的数量,d是输入实例的维数。
现有的多标签学习研究集中于一组固定的标签,即所有标签都是一次给出的。但是,在现实世界中并不是这样。实际上,随着对数据的深入探索和理解,标签的数量逐渐增加。例如,当照片发布在Facebook或Twitter上时,正在浏览的用户将对照片进行连续且不同的标记,并且分类系统需要根据新标签准确更新。
在这篇论文中,作者提出了一个基于DNN的新颖框架,即深度流标签学习(DSLL),以有效地对新兴的新标签进行建模,可以从过去的标签和历史模型中探索和吸收知识,以理解和发展新的标签。
文章的总体结构如下。第2节总结了先前的相关工作;第三部分提出了问题并详细描述了所提出的模型;第四部分介绍了验证模型的实验结果。
2.Related work
2.1 Multi-label Learning
多标签学习一般有两种方法:(1)探索和利用标签间的相关性,(2)通过将原始的高维标记向量嵌入低维表示来减少标记空间。特别是深度神经网络(DNN)提供了一种学习标签相关性和同时嵌入的好方法,大大优于传统方法。
2.2 Streaming Label Learning
在2016年,流式标签学习(SLL)被提出,其目的是利用过去标签的知识。
(1)标签被表示为其他标签的线性组合,
(2)标签之间的关系(线性组合)可以由不同标签的分类器继承。
受这些假设的约束,SLL会根据过去标签和新标签之间的关系训练新标签的线性分类器。但是,跨标签的线性表示会限制SLL性能,并且忽略了过去标签分类器的训练知识。
2.3 Knowledge Distillation
知识蒸馏(KD)旨在将知识从现有的强大分类器(称为教师)转移到轻量级分类器(称为学生)。
通过一步一步地使用一个较大的已经训练好的网络去教导一个较小的网络确切地去做什么。通过尝试复制大网络在每一层的输出(不仅仅是最终的损失),小网络被训练以学习大网络的准确行为。
3. Deep Streaming Label Learning
这部分是文章的主体部分,主要介绍了DSLL算法的原理和组成部分。面对新出现的标签,传统的多标签学习面临以下困境:(1)整合过去的标签和新标签以重新训练新的多标签模型需要大量的计算资源;(2)独立学习新标签会忽略从过去的标签和历史模型中获得的知识。因此DSLL算法被提出以解决这些问题,DSLL的整体结构如图3.1所示。该框架由三个部分组成:
1)流式标签映射,用标签相关感知损失捕获新标签和过去标签之间的关系,其中硬为过去标签的ground truth,软为过去标签分类器(teacher)提供的预测;
2)流式特征蒸馏,将教师的知识转化为新标签分类器(学生),以教师中间层的输出作为提示引导学生的输出;
3)高年级学生网络,利用关系和知识最终建立新标签模型。红色虚线表示学习过程中的反向传播路径。

3.1 Streaming Label Mapping with Label-correlation Loss
这部分主要是得到之前label和新加入label最接近的mapping。在前人论文中证明了探索和开发标签之间的关系对提高MLL性能是重要的。其中训练的时候会加入Hard label(GT的label)进行联合训练。旨在使流标签映射在学习标签之间的关系时更加健壮。一方面,过去的hard label与新到标签保持着未被打破的关系,另一方面,在测试过程中,硬标签是未知的,仅依赖于过去标签分类器提供的软标签。其输出下面公式所示。
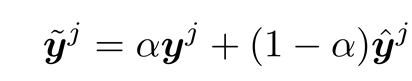
代码如下所示,上面是将已有的分类模型导入,下面的是给的一个示例代码,将标签进行映射。

在loss函数的选择上,这篇文章在常用的多标签损失函数MultiLabelSoftMarginLoss的基础上,提出了一个叫做correlation-aware loss的函数,定义如下(b一般取1):
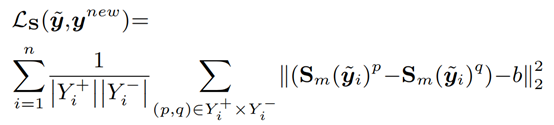
correlation-aware loss的代码实现如下:

3.2 Streaming Feature Distillation
DSLL模型的第二个部分是一种基于提示的流式特征提取方法,它将过去标签分类器(教师)的知识转化为新标签分类器(学生)的知识。教师的中间层引导学生的隐含层来模仿它的输出。由于所选择的提示层可能比引导层有更多的输出,因此我们在引导层之后添加了一个由WAdapt参数化的自适应矩阵来匹配提示层的输出大小。结构如下所示。上面是教师层,下面是学生层,中间通过loss反向传播进行学习,以得到更小更好的模型。

这部分loss的公式如下所示,即提示层和引导层的均方差。
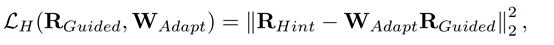
其中RHint和RGuided分别表示提示层在teacher中的输出和引导层在student中的输出。最后,引导层之前的学生参数将作为预先训练的参数保存,并在以后的训练中以缓慢的学习速度进行微调。流特征蒸馏优于从零开始的训练,因为预先训练的模型已经提取了大量的特征级知识。
这部分代码实现如下所示,loss函数直接使用pytorch的MSRLoss函数实现即可。

3.3 Learning from the Past
这部分是为了整合从过去的标签和历史分类器学习到的知识。高年级学生接收流标签映射和学生网络的输出作为输入,并生成对新标签的预测。在流标签映射后增加了一个隐含层作为非线性变换St,它可以将流标签映射的输出转换到更高的空间。总的来说,对高年级学生的训练可以看作是从实例xi到输出流标签映射到相应的新标签向量ynewi的过程。在学习阶段,通过最小化交叉熵损失,同时训练高年级学生的参数、变换St和学生(包括预先训练好的引导层)Loss如下:
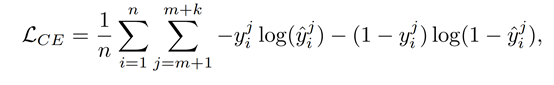
总体DSLL的代码实现如下所示,首先x输入蒸馏完成后的网络得到x_feature_kd,在流标签映射得到的y_mapping添加一个隐含层得到更高维的空间映射,最后综合两个部分输入到高年级学生网络中完成新标签的预测。

最后,运行了一下官方github的代码示例(可能有错误,关于gpu和cpu的选择,调试一下就可以改正了),得到结果如下所示。

4. 实验数据和结果
三个正常规模的数据集:Yeast、 MirFlickr和Delicious,两个大规模数据集:EURlex和 Wiki10。实验环境是64位的linux,内存为256GB,CPU是10核的Intel i7-6850K,显卡是4块Nvidia GTX 1080Ti。
与之前方法的对比结果如下所示,第一个图的评价指标是mirco-AUC,第二个图的评价指标是Ranking-loss,前者越大越好,后者越小越好。可以看出,DSLL模型基本好于其他模型。


其中micro-AUC是将多分类转换为多个二分类问题,然后将所有的二分类合并,变为统一的x轴和y轴,进行AUC的计算。与之相对的是marco-AUC,它是将所有的二分类的曲线进行平均得到最后结果。第二张图的评价指标Ranking loss的公式如下所示,它衡量了排序相反的比例,即不相关的标签排在相关标签之前。
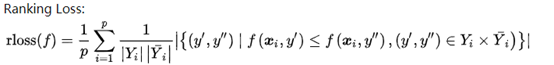
DSLL模型的自身对比结果如下所示。其中KD 代表knowledge distillation,即知识蒸馏,CE代表cross-entropy loss,LC代表label correlation-aware loss,St代表transformation layer。由Baseline开始,加上对应的结构,直到最后加上所有的结构的结果对比。可以看出,Ap值在上升,Coverage在下降。

Coverage公式如下所示,该评价指标用于考察在样本的类别标记排序序列中,覆盖所有相关标记所需的搜索深度情况,即越小越好。
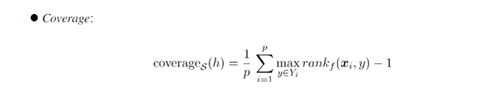
Ap公式如下所示,该评价指标用于考察在样本的类别标记排序序列中,排在相关标记之前的标记仍在相关标记的情况,即越大越好。
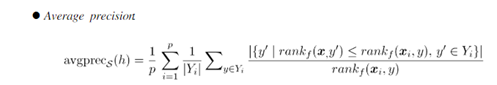
5.总结
本文提出了一个新颖的框架,即深度流标签学习(DSLL),以解决带有新标签的多标签学习问题。该多标签分类器包含三个部分:流式标签映射,流式特征蒸馏和高年级学生。DSLL从过去的标签及其分类器中提取知识,以有效地对新兴标签进行建模,而无需重新培训整个多标签分类器。






