yolov5训练自己的目标检测模型
1.克隆项目并配置环境
1.1克隆项目
进入GitHub下载yolov5源码 点此进入
选择分支v5.0,并下载源码
anaconda激活相应环境
activate pytorch
进入项目存放的地址
E:
cd yolov5-master
1.2 yolov5项目结构
├── data:主要是存放一些超参数的配置文件(这些文件(yaml文件)是用来配置训练集和测试集还有验证集的路径的,其中还包括目标检测的种类数和种类的名称);还有一些官方提供测试的图片。如果是训练自己的数据集的话,那么就需要修改其中的yaml文件。但是自己的数据集不建议放在这个路径下面,而是建议把数据集放到yolov5项目的同级目录下面。
├── models:里面主要是一些网络构建的配置文件和函数,其中包含了该项目的四个不同的版本,分别为是s、m、l、x。从名字就可以看出,这几个版本的大小。他们的检测测度分别都是从快到慢,但是精确度分别是从低到高。这就是所谓的鱼和熊掌不可兼得。如果训练自己的数据集的话,就需要修改这里面相对应的yaml文件来训练自己模型。
├── utils:存放的是工具类的函数,里面有loss函数,metrics函数,plots函数等等。
├── weights:放置训练好的权重参数。
├── detect.py:利用训练好的权重参数进行目标检测,可以进行图像、视频和摄像头的检测。
├── train.py:训练自己的数据集的函数。
├── test.py:测试训练的结果的函数。
├──requirements.txt:这是一个文本文件,里面写着使用yolov5项目的环境依赖包的一些版本,可以利用该文本导入相应版本的包。
1.3 安装相应的包
安装所需的包
pip install -r requirements.txt
安装过程报错

Could not build wheels for pycocotools, which is required to install pyproject.toml-based projects
解决方案如下:
https://blog.csdn.net/weixin_59997235/article/details/127891839
链接:https://pan.baidu.com/s/1bM2s7XfM3zteeaUIpbkjiA?pwd=xa7d
提取码:xa7d
将解压后的文件夹移入虚拟环境相应存放包的位置即可
2.数据集和预训练权重的准备
2.1使用labelimg进行标注
cmd命令行进入存放图片的文件夹并在此文件夹中打开labelimg
cd E:\VOC2077
E:
labelimg JPEGImages predefined_classes.txt
标注后保存为yolo要求的txt格式
2.2获得预训练权重
预训练权重下载
这里先选择5s作为预训练权重
3.训练自己的模型
3.1 修改配置文件
3.1.1 修改数据配置文件
修改data目录下的相应的yaml文件。找到目录下的voc.yaml文件,将该文件复制一份,将复制的文件重命名。这里修改为class.yaml。
# train and val data as 1) directory: path/images/, 2) file: path/images.txt, or 3) list: [path1/images/, path2/images/]
train: E:/yolov5-5.0/VOCdevkit/images/train # 16551 images
val: E:/yolov5-5.0/VOCdevkit/images/val # 4952 images# number of classes
nc: 2# class names
names: [ 'student', 'teacher' ]修改模型配置文件
由于该项目使用的是yolov5s.pt这个预训练权重,所以要使用models目录下的yolov5s.yaml文件中的相应参数(因为不同的预训练权重对应着不同的网络层数,所以用错预训练权重会报错)。和前面修改data目录下的yaml文件一样,将yolov5s.yaml文件复制一份,然后将其重命名,yolov5s-class.yaml。
打开yolov5s-class.yaml修改nc为识别的类别数量
# parameters
nc: 2 # number of classes
3.2进行训练
3.2.1 cpu训练
命令行执行
python train.py
对数据集进行训练
结果报错AttributeError: Can't get attribute 'SPPF' on <module 'models.common' from 'E:\\yolov5-5.0\\models\\common.py'>
解决方案:
在models文件夹中的common.py中添加
class SPPF(nn.Module):# Spatial Pyramid Pooling - Fast (SPPF) layer for YOLOv5 by Glenn Jocherdef __init__(self, c1, c2, k=5): # equivalent to SPP(k=(5, 9, 13))super().__init__()c_ = c1 // 2 # hidden channelsself.cv1 = Conv(c1, c_, 1, 1)self.cv2 = Conv(c_ * 4, c2, 1, 1)self.m = nn.MaxPool2d(kernel_size=k, stride=1, padding=k // 2)def forward(self, x):x = self.cv1(x)with warnings.catch_warnings():warnings.simplefilter('ignore') # suppress torch 1.9.0 max_pool2d() warningy1 = self.m(x)y2 = self.m(y1)return self.cv2(torch.cat([x, y1, y2, self.m(y2)], 1))
命令行再次执行
python train.py
还是有报错AssertionError: train: No labels in E:\yolov5-5.0\VOCdevkit\labels\train.cache. Can not train without labels. See https://github.com/ultralytics/yolov5/wiki/Train-Custom-Data
报错原因:
labels文件夹中存放的是xml格式的标注信息,修改为txt格式即可
3.2.2 gpu训练
python train.py --device 0
执行python train.py --device 0后报错OSError: [WinError 1455] 页面文件太小,无法完成操作。 Error loading "D:\Anaconda3\envs\pytorch-gpu\lib\site-packages\torch\lib\caffe2_detectron_ops_gpu.dll" or one of its dependencies.
在utils路径下找到datasets.py这个文件,将里面的第81行里面的参数nw改为0就可以了。
# 修改前
dataloader = loader(dataset,batch_size=batch_size,num_workers=nw,sampler=sampler,pin_memory=True,collate_fn=LoadImagesAndLabels.collate_fn4 if quad else LoadImagesAndLabels.collate_fn)
# 修改后
dataloader = loader(dataset,batch_size=batch_size,num_workers=0,sampler=sampler,pin_memory=True,collate_fn=LoadImagesAndLabels.collate_fn4 if quad else LoadImagesAndLabels.collate_fn)
3.3 查看训练结果
训练结果存放在E:\yolov5-5.0\runs\train的exp文件夹下
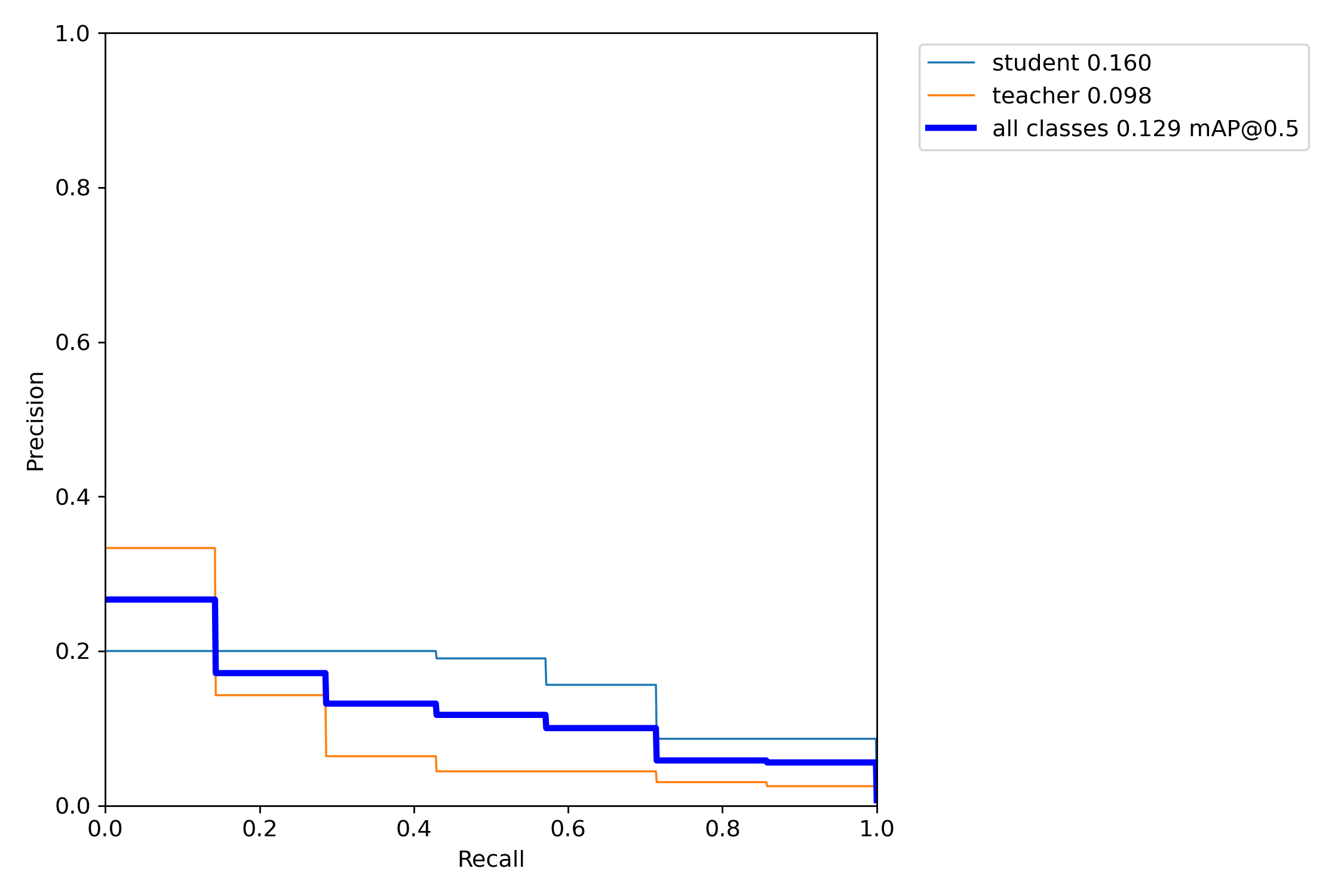
从pr曲线来看训练效果不是很好,可能是训练集数据比较少,而且老师和学生之间差别不大的原因
3.4 使用tensorbord查看参数
tensorboard --logdir=runs/train
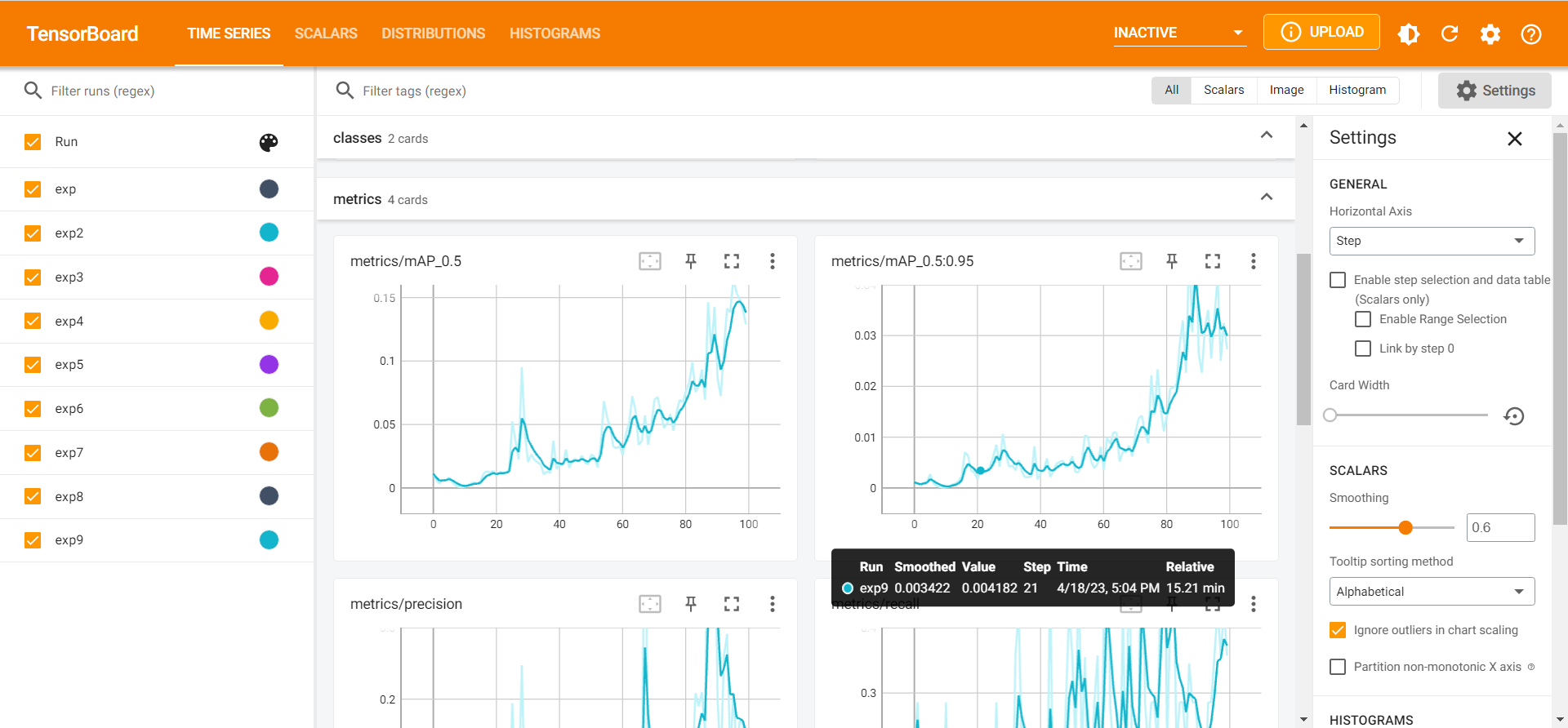
3.5 推理测试
等到数据训练好了以后,就会在主目录下产生一个runs文件夹,在run/train/exp/weights目录下会产生两个权重文件,一个是最后一轮的权重文件,一个是最好的权重文件,一会我们就要利用这个最好的权重文件来做推理测试。除此以外还会产生一些验证文件的图片等一些文件。
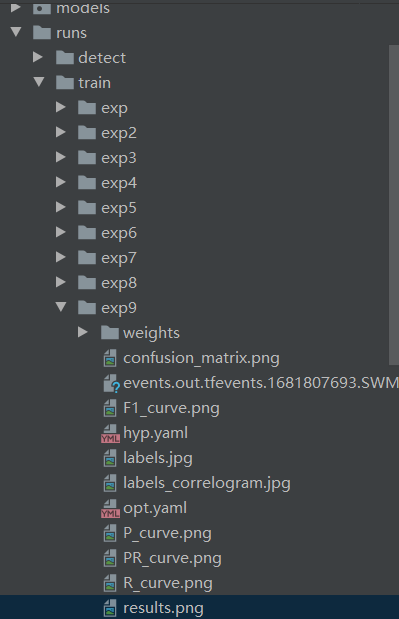
找到主目录下的detect.py文件,打开该文件,然后找到主函数的入口,这里面有模型的主要参数。模型的主要参数解析如下所示。
"""
--weights:权重的路径地址
--source:测试数据,可以是图片/视频路径,也可以是'0'(电脑自带摄像头),也可以是rtsp等视频流
--output:网络预测之后的图片/视频的保存路径
--img-size:网络输入图片大小
--conf-thres:置信度阈值
--iou-thres:做nms的iou阈值
--device:是用GPU还是CPU做推理
--view-img:是否展示预测之后的图片/视频,默认False
--save-txt:是否将预测的框坐标以txt文件形式保存,默认False
--classes:设置只保留某一部分类别,形如0或者0 2 3
--agnostic-nms:进行nms是否也去除不同类别之间的框,默认False
--augment:推理的时候进行多尺度,翻转等操作(TTA)推理
--update:如果为True,则对所有模型进行strip_optimizer操作,去除pt文件中的优化器等信息,默认为False
--project:推理的结果保存在runs/detect目录下
--name:结果保存的文件夹名称
"""
先将刚刚训练好的最好权重传到推理函数中
parser.add_argument('--weights', nargs='+', type=str, default='runs/train/exp9/weights/best.pt',help='model.pt path(s)')
对图片、视频或摄像头进行推理
图片:
parser.add_argument('--source', type=str, default='test/1.jpg', help='source')
视频:
parser.add_argument('--source', type=str, default='test/1.mp4', help='source')
摄像头
parser.add_argument('--source', type=str, default='0', help='source')
摄像头这里还需要再修改utils下的datasets.py,第279行
# 修改前:
# if 'youtube.com/' in url or 'youtu.be/' in url: # if source is YouTube video
# 修改后:if 'youtube.com/' in str(url) or 'youtu.be/' in str(url): # if source is YouTube video
修改完成后就可以直接测试结果
3.5.1 CPU推理测试
python detect.py
3.5.2 GPU推理测试
此处踩坑,这里我先把detect.py文件中的设置修改了,default改成了0,想让他默认调用GPU,但是执行python detect.py 就会报错AssertionError: CUDA unavailable, invalid device 1 requested,而我torch.cuda.is_available()的执行结果为true。
# 这里不要改
parser.add_argument('--device', default='', help='cudaexit() device, i.e. 0 or 0,1,2,3 or cpu')
使用python train.py --device 0在命令行中执行,才能调用GPU。这个莫名其妙的问题卡了很久。
参考:
- 目标检测—教你利用yolov5训练自己的目标检测模型
- AttributeError: Can’t get attribute ‘SPPF’ on <module ‘models.common’ from ‘C:\Users\Downloads\yolov5-pyqt5-master (1)\yolov5-pyqt5-master\models\common.py’> #5